10/30/2559 BE, 1,17PMSparkInternals/0-Introduction.md at thai · Aorjoa/SparkInternals
Page 2 of 3https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/0-Introduction.md
ภาษาจีน
ผู้เขียนไม่สามารถเขียนเอกสารได้เสร็จในขณะนี้ ครั้งล่าสุดที่ได้เขียนคือราว 3 ปีที่แล้วตอนที่กำลังเรียนคอร์ส Andrew Ng's ML อยู่ ซึ่งตอน
นั้นมีแรงบัลดาลใจที่จะทำ ตอนที่เขียนเอกสารนี้ผู้เขียนใช้เวลาเขียนเอกสารขึ้นมา 20 กว่าวันใช้ช่วงซัมเมอร์ เวลาส่วนใหญ่ที่ใช้ไปใช้กับการ
ดีบั๊ก, วาดแผนภาพ, และจัดวางไอเดียให้ถูกที่ถูกทาง. ผู้เขียนหวังเป็นอย่างยิ่งว่าเอกสารนี้จะช่วยผู้อ่านได้
เนื้อหา
เราจะเริ่มกันที่การสร้าง Spark Job และคุยกันถึงเรื่องว่ามันทำงานยังไง จากนั้นจึงจะอธิบายระบบที่เกี่ยวข้องและฟีเจอร์ของระบบที่ทำให้งาน
เราสามารถประมวลผลออกมาได้
1. Overview ภาพรวมของ Apache Spark
2. Job logical plan แผนเชิงตรรกะ : Logical plan (data dependency graph)
3. Job physical plan แผนเชิงกายภาย : Physical plan
4. Shuffle details กระบวนการสับเปลี่ยน (Shuffle)
5. Architecture กระบวนการประสานงานของโมดูลในระบบขณะประมวลผล
6. Cache and Checkpoint Cache และ Checkpoint
7. Broadcast ฟีเจอร์ Broadcast
8. Job Scheduling TODO
9. Fault-tolerance TODO
เอกสารนี้เขียนด้วยภาษา Markdown, สำหรับเวอร์ชัน PDF ภาษาจีนสามารถดาวน์โหลด ที่นี่.
ถ้าคุณใช้ Max OS X, เราขอแนะนำ MacDown แล้วใช้ธีมของ github จะทำให้อ่านได้สะดวก
ตัวอย่าง
บางตัวอย่างที่ผู้เขียนสร้างข้นเพื่อทดสอบระบบขณะที่เขียนจะอยู่ที่ SparkLearning/src/internals.
Acknowledgement
Note : ส่วนของกิตติกรรมประกาศจะไม่แปลครับ
I appreciate the help from the following in providing solutions and ideas for some detailed issues:
@Andrew-Xia Participated in the discussion of BlockManager's implemetation's impact on broadcast(rdd).
@CrazyJVM Participated in the discussion of BlockManager's implementation.
@ Participated in the discussion of BlockManager's implementation.
Thanks to the following for complementing the document:
Weibo Id Chapter Content Revision status
@OopsOutOfMemory Overview
Relation between workers and
executors and Summary on Spark
Executor Driver's Resouce
Management (in Chinese)
There's not yet a conclusion on this
subject since its implementation is
still changing, a link to the blog is
added
Thanks to the following for finding errors:
Weibo Id Chapter Error/Issue Revision status
@Joshuawangzj Overview
When multiple applications are
running, multiple Backend
process will be created
Corrected, but need to be confirmed. No
idea on how to control the number of
Backend processes
10/30/2559 BE, 1,18PMSparkInternals/1-Overview.md at thai · Aorjoa/SparkInternals
Page 3 of 7https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/1-Overview.md
import org.apache.spark.SparkContext._
/**
* Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers]
*/
object GroupByTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("GroupBy Test")
var numMappers = 100
var numKVPairs = 10000
var valSize = 1000
var numReducers = 36
val sc = new SparkContext(sparkConf)
val pairs1 = sc.parallelize(0 until numMappers, numMappers).flatMap { p =>
val ranGen = new Random
var arr1 = new Array[(Int, Array[Byte])](numKVPairs)
for (i <- 0 until numKVPairs) {
val byteArr = new Array[Byte](valSize)
ranGen.nextBytes(byteArr)
arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)
}
arr1
}.cache
// Enforce that everything has been calculated and in cache
println(">>>>>>")
println(pairs1.count)
println("<<<<<<")
println(pairs1.groupByKey(numReducers).count)
sc.stop()
}
}
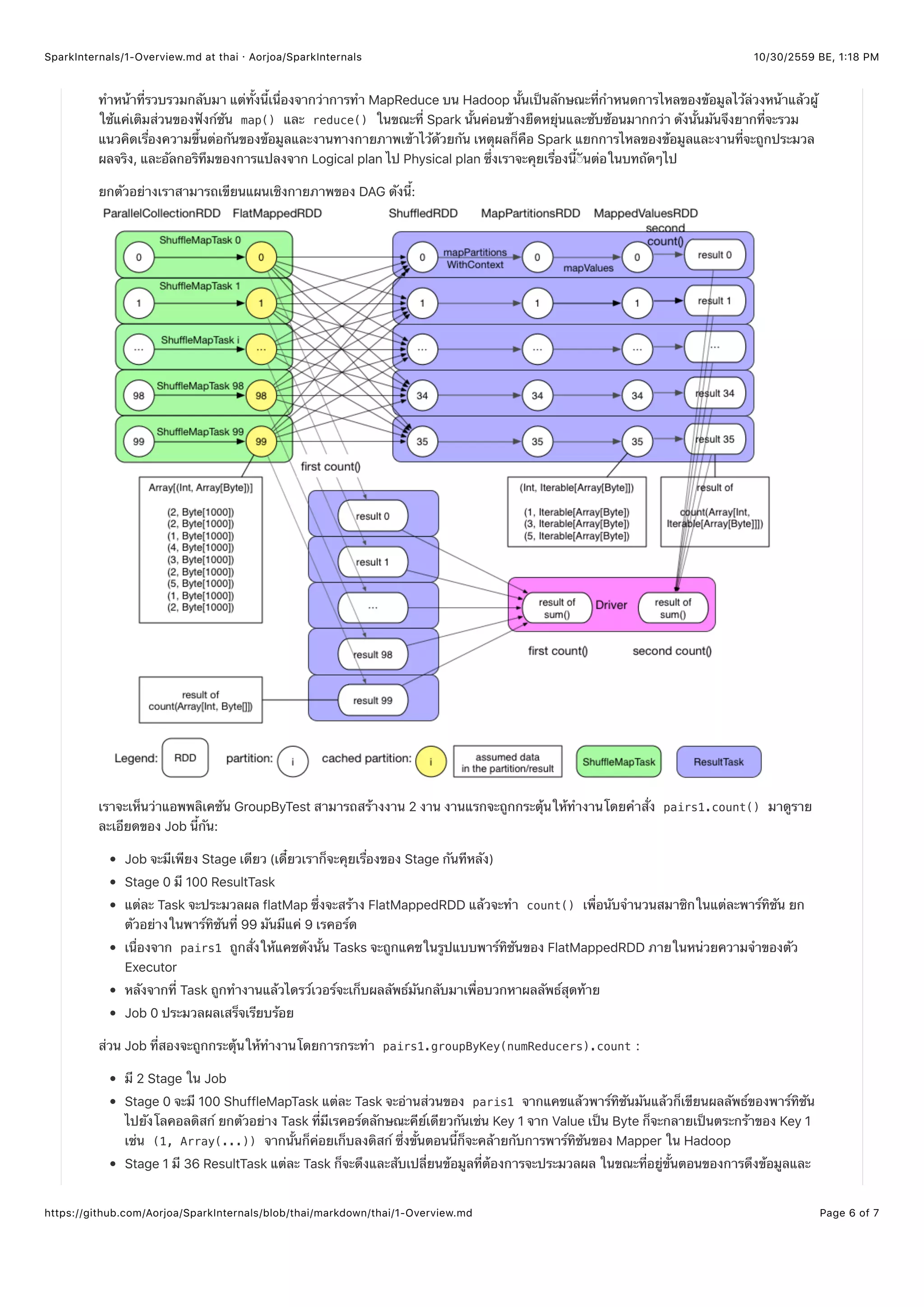
หลังจากที่อ่านโค้ดแล้วจะพบว่าโค้ดนี้มีแนวความคิดในการแปลงข้อมูลดังนี้
แอพพลิเคชันนี้ไม่ได้ซับซ้อนอะไรมาก เราจะประเมินขนาดของข้อมูลและผลลัพธ์ซึ่งแอพพลิเคชันก็จะมีการทำงานตามขั้นตอนดังนี้
8.
10/30/2559 BE, 1,18PMSparkInternals/1-Overview.md at thai · Aorjoa/SparkInternals
Page 4 of 7https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/1-Overview.md
1. สร้าง SparkConf เพื่อกำหนดการตั้งค่าของ Spark (ตัวอย่างกำหนดชื่อของแอพพลิเคชัน)
2. สร้างและกำหนดค่า numMappers=100, numKVPairs=10,000, valSize=1000, numReducers= 36
3. สร้าง SparkContext โดยใช้การตั้งค่าจาก SparkConf ขั้นตอนนี้สำคัญมากเพราะ SparkContext จะมี Object และ Actor ซึ่งจำเป็น
สำหรับการสร้างไดรว์เวอร์
4. สำหรับ Mapper แต่ละตัว arr1: Array[(Int, Byte[])] Array ชื่อ arr1 จะถูกสร้างขึ้นจำนวน numKVPairs ตัว, ภายใน Array
แต่ละตัวมีคู่ Key/Value ซึ่ง Key เป็นตัวเลข (ขนาด 4 ไบต์) และ Value เป็นไบต์ขนาดเท่ากับ valSize อยู่ ทำให้เราประเมินได้ว่า ขนาด
ของ arr1 = numKVPairs * (4 + valSize) = 10MB , ดังนั้นจะได้ว่า ขนาดของ pairs1 = numMappers * ขนาดของ arr1
1000MB ตัวนี้ใช้เป็นการประเมินการใช้พื้นที่จัดเก็บข้อมูลได้
5. Mapper แต่ละตัวจะถูกสั่งให้ Cache ตัว arr1 (ผ่านทาง pairs1) เพื่อเก็บมันไว้ในหน่วยความจำเผื่อกรณีที่มีการเรียกใช้ (ยังไม่ได้ทำ
นะแต่สั่งใว้)
6. จากนั้นจะมีการกระทำ count() เพื่อคำนวณหาขนาดของ arr1 สำหรับ Mapper ทุกๆตัวซึ่งผลลัพธ์จะเท่ากับ numMappers *
numKVPairs = 1,000,000 การกระทำในขั้นตอนนี้ทำให้เกิดการ Cahce ที่ตัว arr1 เกิดขึ้นจริงๆ (จากคำสั่ง pairs1.count()1
ตัวนี้จะมีสมาชิก 1,000,000 ตัว)
7. groupByKey ถูกสั่งให้ทำงานบน pairs1 ซึ่งเคยถูก Cache เก็บไว้แล้ว โดยจำนวนของ Reducer (หรือจำนวนพาร์ทิชัน) ถูกกำหนด
ในตัวแปร numReducers ในทางทฤษฏีแล้วถ้าค่า Hash ของ Key มีการกระจายอย่างเท่าเทียมกันแล้วจะได้ numMappers *
numKVPairs / numReducer 27,777 ก็คือแต่ละตัวของ Reducer จะมีคู่ (Int, Array[Byte]) 27,777 คู่อยู่ในแต่ละ Reducer ซึ่ง
จะมีขนาดเท่ากับ ขนาดของ pairs1 / numReducer = 27MB
8. Reducer จะรวบรวมเรคคอร์ดหรือคู่ Key/Value ที่มีค่า Key เหมือนกันเข้าไว้ด้วยกันกลายเป็น Key เดียวแล้วก็ List ของ Byte (Int,
List(Byte[], Byte[], ..., Byte[]))
9. ในขั้นตอนสุดท้ายการกระทำ count() จะนับหาผลรวมของจำนวนที่เกิดจากแต่ละ Reducer ซึ่งผ่านขั้นตอนการ groupByKey มาแล้ว
(ทำให้ค่าอาจจะไม่ได้ 1,000,000 พอดีเป๊ะเพราะว่ามันถูกจับกลุ่มค่าที่ Key เหมือนกันซึ่งเป็นการสุ่มค่ามาและค่าที่ได้จากการสุ่มอาจจะ
ตรงกันพอดีเข้าไว้ด้วยกันแล้ว) สุดท้ายแล้วการกระทำ count() จะรวมผลลัพธ์ที่ได้จากแต่ละ Reducer เข้าไว้ด้วยกันอีกทีเมื่อทำงาน
เสร็จแล้วก็จะได้จำนวนของ Key ที่ไม่ซ้ำกันใน paris1
แผนเชิงตรรกะ Logical Plan
ในความเป็นจริงแล้วกระบวนการประมวลผลของแอพพลิเคชันของ Spark นั้นซับซ้อนกว่าที่แผนภาพด้านบนอธิบายไว้ ถ้าจะว่าง่ายๆ แผนเชิง
ตรรกะ Logical Plan (หรือ data dependency graph - DAG) จะถูกสร้างแล้วแผนเชิงกายภาพ Physical Plan ก็จะถูกผลิตขึ้น (English : a
logical plan (or data dependency graph) will be created, then a physical plan (in the form of a DAG) will be generated
เป็นการเล่นคำประมาณว่า Logical plan มันถูกสร้างขึ้นมาจากของที่ยังไม่มีอะไร Physical plan ในรูปของ DAG จาก Logical pan นั่นแหละ
จะถูกผลิตขึ้น) หลังจากขั้นตอนการวางแผนทั้งหลายแหล่นี้แล้ว Task จะถูกผลิตแล้วก็ทำงาน เดี๋ยวเราลองมาดู Logical plan ของ
แอพพลิเคชันดีกว่า
ตัวนี้เรียกใช้ฟังก์ชัน RDD.toDebugString แล้วมันจะคืนค่า Logical Plan กลับมา:
MapPartitionsRDD[3] at groupByKey at GroupByTest.scala:51 (36 partitions)
ShuffledRDD[2] at groupByKey at GroupByTest.scala:51 (36 partitions)
FlatMappedRDD[1] at flatMap at GroupByTest.scala:38 (100 partitions)
ParallelCollectionRDD[0] at parallelize at GroupByTest.scala:38 (100 partitions)
วาดเป็นแผนภาพได้ตามนี้:
10/30/2559 BE, 1,19PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 14 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
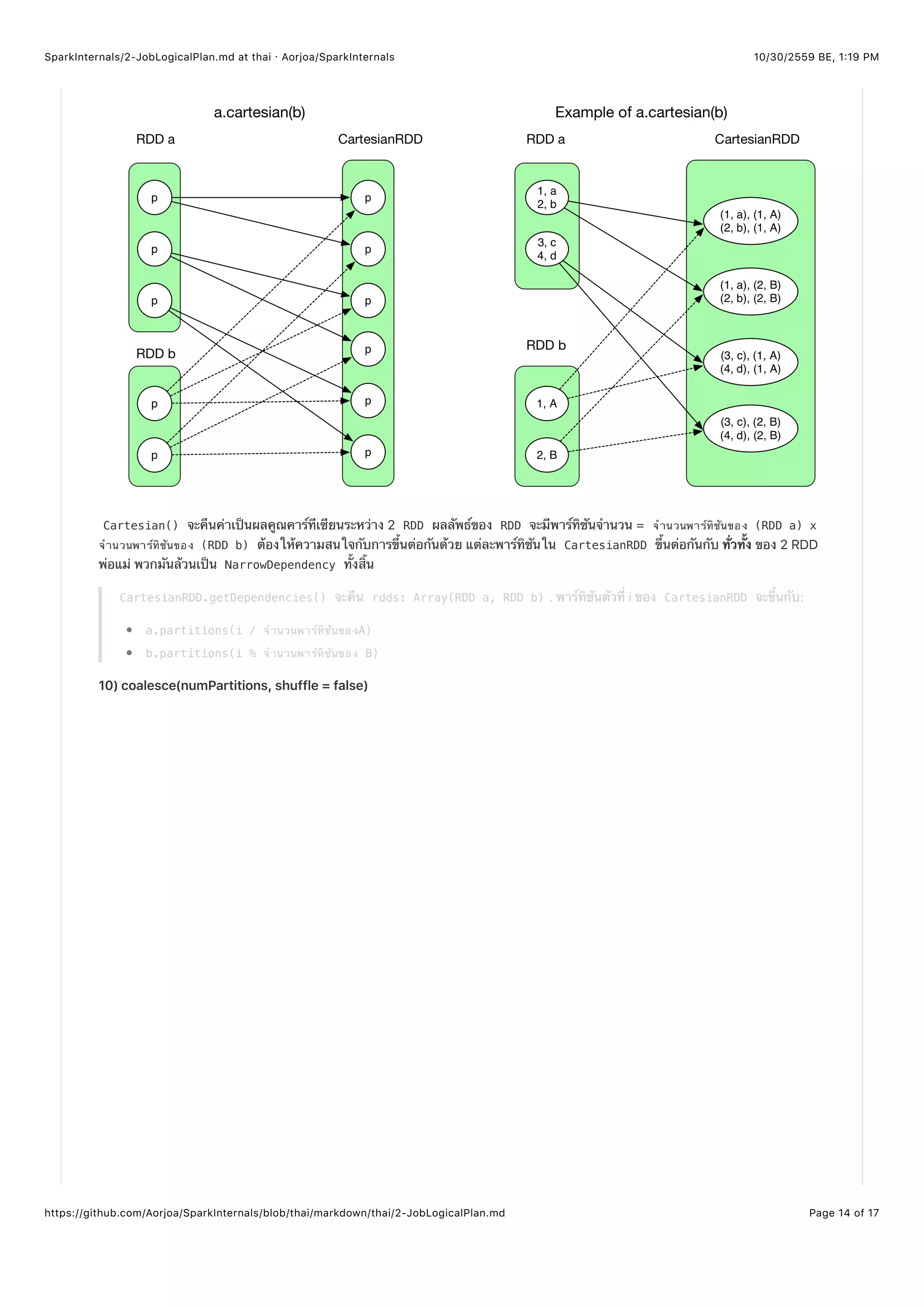
Cartesian() จะคืนค่าเป็นผลคูณคาร์ทีเซียนระหว่าง 2 RDD ผลลัพธ์ของ RDD จะมีพาร์ทิชันจำนวน = จํานวนพาร์ทิชันของ (RDD a) x
จํานวนพาร์ทิชันของ (RDD b) ต้องให้ความสนใจกับการขึ้นต่อกันด้วย แต่ละพาร์ทิชันใน CartesianRDD ขึ้นต่อกันกับ ทั่วทั้ง ของ 2 RDD
พ่อแม่ พวกมันล้วนเป็น NarrowDependency ทั้งสิ้น
CartesianRDD.getDependencies() จะคืน rdds: Array(RDD a, RDD b) . พาร์ทิชันตัวที่ i ของ CartesianRDD จะขึ้นกับ:
a.partitions(i / จํานวนพาร์ทิชันของA)
b.partitions(i % จํานวนพาร์ทิชันของ B)
10) coalesce(numPartitions, shuffle = false)
26.
10/30/2559 BE, 1,19PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 15 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
10/30/2559 BE, 1,21PMSparkInternals/3-JobPhysicalPlan.md at thai · Aorjoa/SparkInternals
Page 6 of 10https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/3-JobPhysicalPlan.md
ผลลัพธ์สุดท้ายออกมา กระบวนการเหล่านี้แสดงได้ตามแผนภาพด้านล่าง:
กระบวนการประมวลผลนี้ไม่สามารถใช้กับ Physical plan ของ Spark ได้ตรงๆเพราะ Physical plan ของ Hadoop MapReduce นั้นมันเป็น
กลไลง่ายๆและกำหนดไว้ตายตัวโดยที่ไม่มีการ Pipeline ด้วย
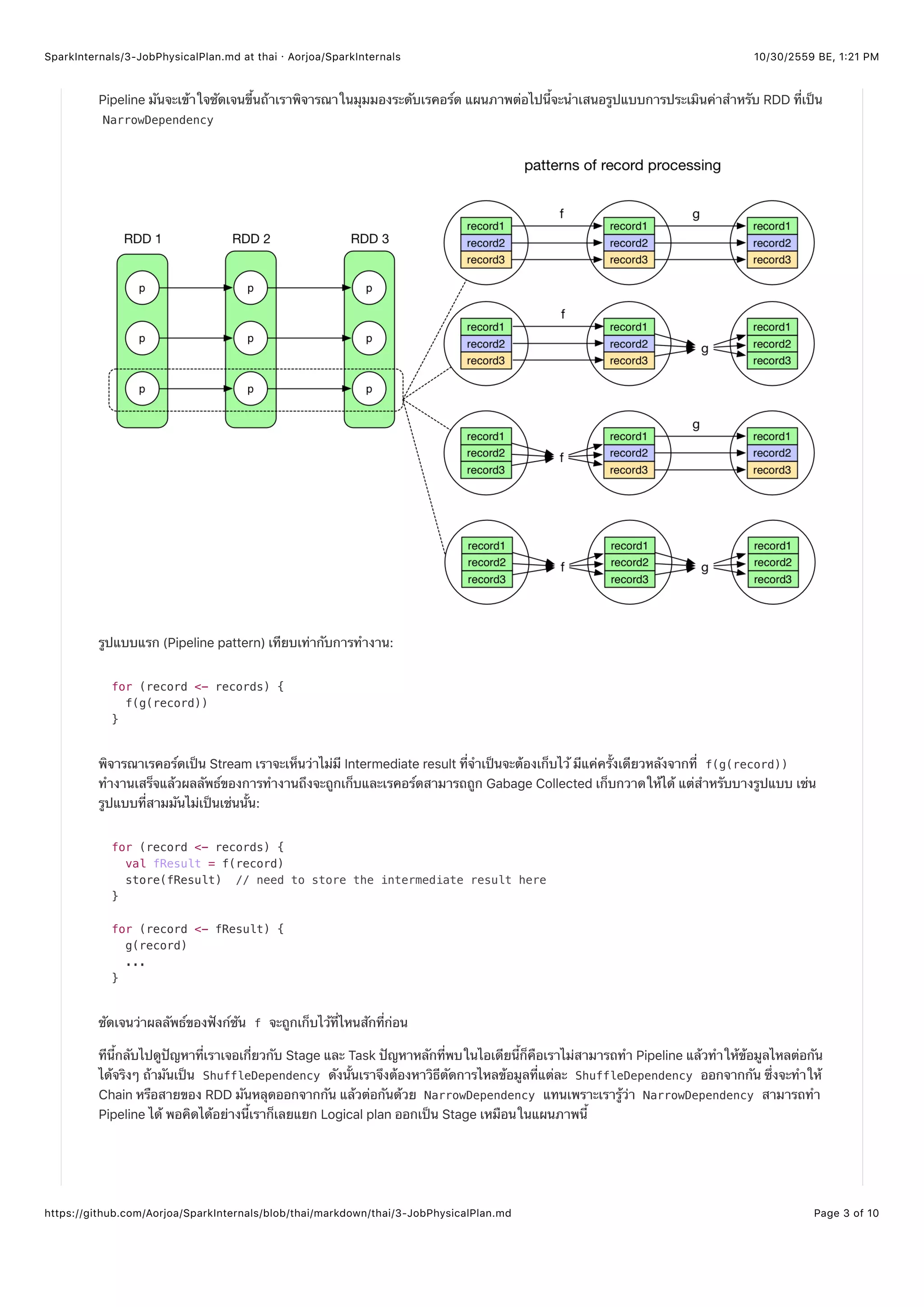
ไอเดียหลักของการทำ Pipeline ก็คือ ข้อมูลจะถูกประมวลผลจริงๆ ก็ต่อเมื่อมันต้องการจะใช้จริงๆในกระบวนการไหลของข้อมูล เราจะเริ่ม
จากผลลัพธ์สุดท้าย (ดังนั้นจึงทราบอย่างชัดเจนว่าการคำนวณไหนบ้างที่ต้องการจริงๆ) จากนั้นตรวจสอบย้อนกลับตาม Chain ของ RDD เพื่อ
หาว่า RDD และพาร์ทิชันไหนที่เราต้องการรู้ค่าเพื่อใช้ในการคำนวณจนได้ผลลัพธ์สุดท้ายออกมา กรณีที่เจอคือส่วนใหญ่เราจะตรวจสอบย้อน
กลับไปจนถึงพาร์ทิชันบางตัวของ RDD ที่อยู่ฝั่งซ้ายมือสุดและพวกบางพาร์ทิชันที่อยู่ซ้ายมือสุดนั่นแหละที่เราต้องการที่จะรู้ค่าเป็นอันดับแรก
สำหรับ Stage ที่ไม่มีพ่อแม่ ตัวมันจะเป็น RDD ที่อยู่ซ้ายสุดโดยตัวมันเองซึ่งเราสามารถรู้ค่าได้โดยตรงอยู่แล้ว (มันไม่มีการขึ้นต่อกัน) และ
แต่ละเรคอร์ดที่รู้ค่าแล้วสามารถ Stream ต่อไปยังกระบวนการคำนวณที่ตามมาภายหลังมัน (Pipelining) Chain การคำนวณอนุมาณได้ว่า
มาจากขั้นตอนสุดท้าย (เพราะไล่จาก RDD ตัวสุดท้ายมา RDD ฝั่งซ้ายมือสุด) แต่กลไกการประมวลผลจริง Stream ของเรคอร์ดนั้นดำเนินไป
ข้างหน้า (ทำจริงจากซ้ายไปขวา แต่ตอนเช็คไล่จากขวาไปซ้าย) เรคอร์ดหนึ่งๆจถูกทำทั้ง Chain การประมวลผลก่อนที่จะเริ่มประมวลผลเร
คอร์ดตัวอื่นต่อไป
สำหรับ Stage ที่มีพ่อแม่นั้นเราต้องประมวลผลที่ Stage พ่อแม่ของมันก่อนแล้วจึงดึงข้อมูลผ่านทาง Shuffle จากนั้นเมื่อพ่อแม่ประมวลผล
เสร็จหนึ่งครั้งแล้วมันจะกลายเป็นกรณีที่เหมือนกัน Stage ที่ไม่มีพ่อแม่ (จะได้ไม่ต้องคำนวณซ้ำๆ)
ในโค้ดแต่ละ RDD จะมีเมธอต getDependency() ประกาศการขึ้นต่อกันของข้อมูลของมัน, compute() เป็นเมธอตที่ดูแลการรับเร
คอร์ดมาจาก Upstream (จาก RDD พ่อแม่หรือแหล่งเก็บข้อมูล) และนำลอจิกไปใช้กับเรคอร์ดนั้นๆ เราจะเห็นบ่อยมากในโคดที่เกี่ยว
กับ RDD (ผู้แปล: ตัวนี้เคยเจอในโค้ดของ Spark ในส่วนที่เกี่ยวกับ RDD) firstParent[T].iterator(split,
context).map(f) ตัว firstParent บอกว่าเป็น RDD ตัวแรกที่ RDD มันขึ้นอยู่ด้วย, iterator() แสดงว่าเรคอร์ดจะถูกใช้
แบบหนึ่งต่อหนึ่ง, และ map(f) เรคอร์ดแต่ละตัวจะถูกนำประมวลผลตามลอจิกการคำนวณที่ถูกกำหนดไว้. สุดท้ายแล้วเมธอต
compute() ก็จะคืนค่าที่เป็น Iterator เพื่อใช้สำหรับการประมวลผลถัดไป
สรุปย่อๆดังนี้ : *การคำนวณทั่วทั้ง Chain จะถูกสร้างโดยการตรวจสอบย้อนกลับจาก RDD ตัวสุดท้าย แต่ละ ShuffleDependency จะเป็น
ตัวแยก Stage แต่ละส่วนออกจากกัน และในแต่ละ Stage นั้น RDD แต่ละตัวจะมีเมธอต compute() ที่จะเรียกการประมวลผลบน RDD พ่อ
แม่ parentRDD.itererator() แล้วรับ Stream เรคอร์ดจาก Upstream *
โปรดทราบว่าเมธอต compute() จะถูกจองไว้สำหรับการคำนวณลิจิกที่สร้างเอาท์พุทออกจากโดยใช้ RDD พ่อแม่ของมันเท่านั้น. RDD
จริงๆของพ่อแม่ที่ RDD มันขึ้นต่อจะถูกประกาศในเมธอต getDependency() และพาร์ทิชันจริงๆที่มันขึ้นต่อจะถูกประกาศไว้ในเมธอต
dependency.getParents()
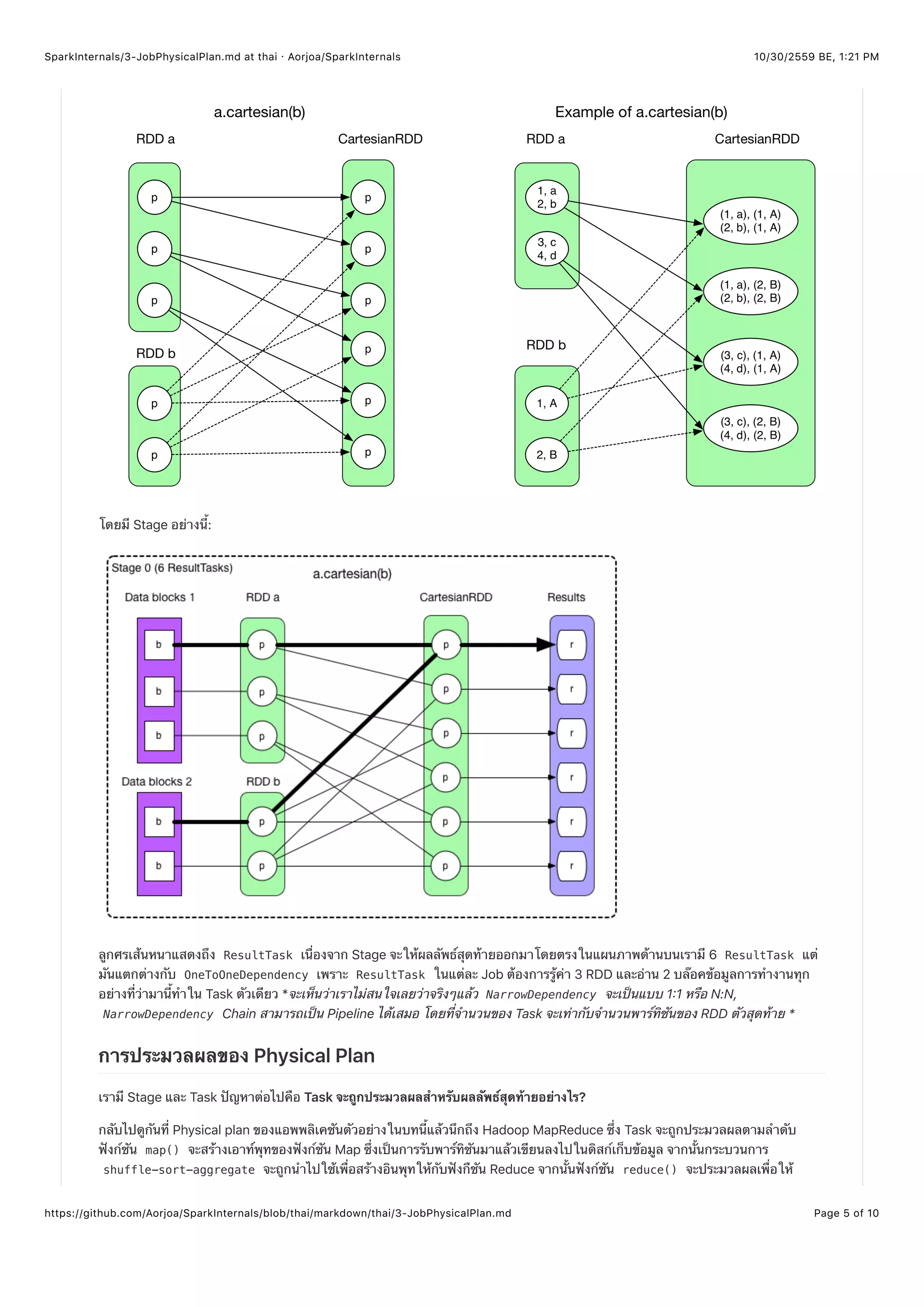
ลองดูผลคูณคาร์ทีเซียน CartesianRDD ในตัวอย่างนี้
// RDD x is the cartesian product of RDD a and RDD b
// RDD x = (RDD a).cartesian(RDD b)
// Defines how many partitions RDD x should have, what are the types for each partition
override def getPartitions: Array[Partition] = {
// create the cross product split
val array = new Array[Partition](rdd1.partitions.size * rdd2.partitions.size)
for (s1 <- rdd1.partitions; s2 <- rdd2.partitions) {
val idx = s1.index * numPartitionsInRdd2 + s2.index
array(idx) = new CartesianPartition(idx, rdd1, rdd2, s1.index, s2.index)
}
array
}
35.
10/30/2559 BE, 1,21PMSparkInternals/3-JobPhysicalPlan.md at thai · Aorjoa/SparkInternals
Page 7 of 10https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/3-JobPhysicalPlan.md
// Defines the computation logic for each partition of RDD x (the result RDD)
override def compute(split: Partition, context: TaskContext) = {
val currSplit = split.asInstanceOf[CartesianPartition]
// s1 shows that a partition in RDD x depends on one partition in RDD a
// s2 shows that a partition in RDD x depends on one partition in RDD b
for (x <- rdd1.iterator(currSplit.s1, context);
y <- rdd2.iterator(currSplit.s2, context)) yield (x, y)
}
// Defines which are the dependent partitions and RDDs for partition i in RDD x
//
// RDD x depends on RDD a and RDD b, both in `NarrowDependency`
// For the first dependency, partition i in RDD x depends on the partition with
// index `i / numPartitionsInRDD2` in RDD a
// For the second dependency, partition i in RDD x depends on the partition with
// index `i % numPartitionsInRDD2` in RDD b
override def getDependencies: Seq[Dependency[_]] = List(
new NarrowDependency(rdd1) {
def getParents(id: Int): Seq[Int] = List(id / numPartitionsInRdd2)
},
new NarrowDependency(rdd2) {
def getParents(id: Int): Seq[Int] = List(id % numPartitionsInRdd2)
}
)
การสร้าง Job
จนถึงตอนนี้เรามีความรู้เรื่อง Logical plan และ Plysical plan แล้ว ทำอย่างไรและเมื่อไหร่ที่ Job จะถูกสร้าง? และจริงๆแล้ว Job มันคือ
อะไรกันแน่
ตารางด้านล่างแล้วถึงประเภทของ action() และคอลัมภ์ถัดมาคือเมธอต processPartition() มันใช้กำหนดว่าการประมวลผลกับเร
คอร์ดในแต่ละพาร์ทิชันจะทำอย่างไรเพื่อให้ได้ผลลัพธ์ คอลัมภ์ที่สามคือเมธอต resultHandler() จะเป็นตัวกำหนดว่าจะประมวลผลกับ
ผลลัพธ์บางส่วนที่ได้มาจากแต่ละพาร์ทิชันอย่างไรเพื่อให้ได้ผลลัพธ์สุดท้าย
Action finalRDD(records) => result compute(results)
reduce(func)
(record1, record2) => result, (result, record
i) => result
(result1, result 2) => result, (result, result i)
=> result
collect() Array[records] => result Array[result]
count() count(records) => result sum(result)
foreach(f) f(records) => result Array[result]
take(n) record (i<=n) => result Array[result]
first() record 1 => result Array[result]
takeSample() selected records => result Array[result]
takeOrdered(n,
[ordering])
TopN(records) => result TopN(results)
saveAsHadoopFile(path) records => write(records) null
countByKey() (K, V) => Map(K, count(K)) (Map, Map) => Map(K, count(K))
แต่ละครั้งที่มีการเรียก action() ในโปรแกรมไดรว์เวอร์ Job จะถูกสร้างขึ้น ยกตัวอย่าง เช่น foreach() การกระทำนี้จะเรียกใช้
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(f))) เพื่อส่ง Job ไปยัง DAGScheduler และถ้ามีการเรียก
action() อื่นๆอีกในโปรแกรมไดรว์เวอร์ระบบก็จะสร้า Job ใหม่และส่งเข้าไปใหม่อีกครั้ง ดังนั้นเราจึงจะมี Job ได้หลายตัวตาม
action() ที่เราเรียกใช้ในโปรแกรมไดรว์เวอร์ นี่คือเหตุผลที่ว่าทำไมไดรว์เวอร์ของ Spark ถูกเรียกว่าแอพพลิเคชันมากกว่าเรียกว่า Job
10/30/2559 BE, 1,24PMSparkInternals/6-CacheAndCheckpoint.md at thai · Aorjoa/SparkInternals
Page 1 of 9https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/6-CacheAndCheckpoint.md
This repository Pull requests Issues Gist
SparkInternals / markdown / thai / 6-CacheAndCheckpoint.md
Search
Aorjoa / SparkInternals
forked from JerryLead/SparkInternals
Code Pull requests 0 Projects 0 Wiki Pulse Graphs Settings
thaiBranch: Find file Copy path
1 contributor
1a5512d an hour agoAorjoa fixed some typo and polish some word
170 lines (104 sloc) 23.9 KB
cache และ checkpoint
cache (หรือ persist ) เป็นฟีเจอร์ที่สำคัญของ Spark ซึ่งไม่มีใน Hadoop ฟีเจอร์นี้ทำให้ Spark มีความเร็วมากกว่าเพราะสามารถใช้
เช็ตข้อมูลเดินซ้ำได้ เช่น Iterative algorithm ใน Machine Learning, การเรียกดูข้อมูลแบบมีปฏิสัมพันธ์ เป็นต้น ซึ่งแตกต่างกับ Hadoop
MapReduce Job เนื่องจาก Sark มี Logical/Physical pan ที่สามารถขยายงานออกกว้างดังนั้น Chain ของการคำนวณจึงจึงยาวมากและ
ใช้เวลาในการประมวลผล RDD นานมาก และหากเกิดข้อผิดพลาดในขณะที่ Task กำลังประมวลผลอยู่นั้นการประมวลผลทั้ง Chain ก็จะต้อง
เริ่มใหม่ ซึ่งส่วนนี้ถูกพิจารณาว่ามีข้อเสีย ดังนั้นจึงมี checkpoint กับ RDD เพื่อที่จะสามารถประมวลผลเริ่มต้นจาก checkpoint ได้
โดยที่ไม่ต้องเริ่มประมวลผลทั้ง Chain ใหม่
cache()
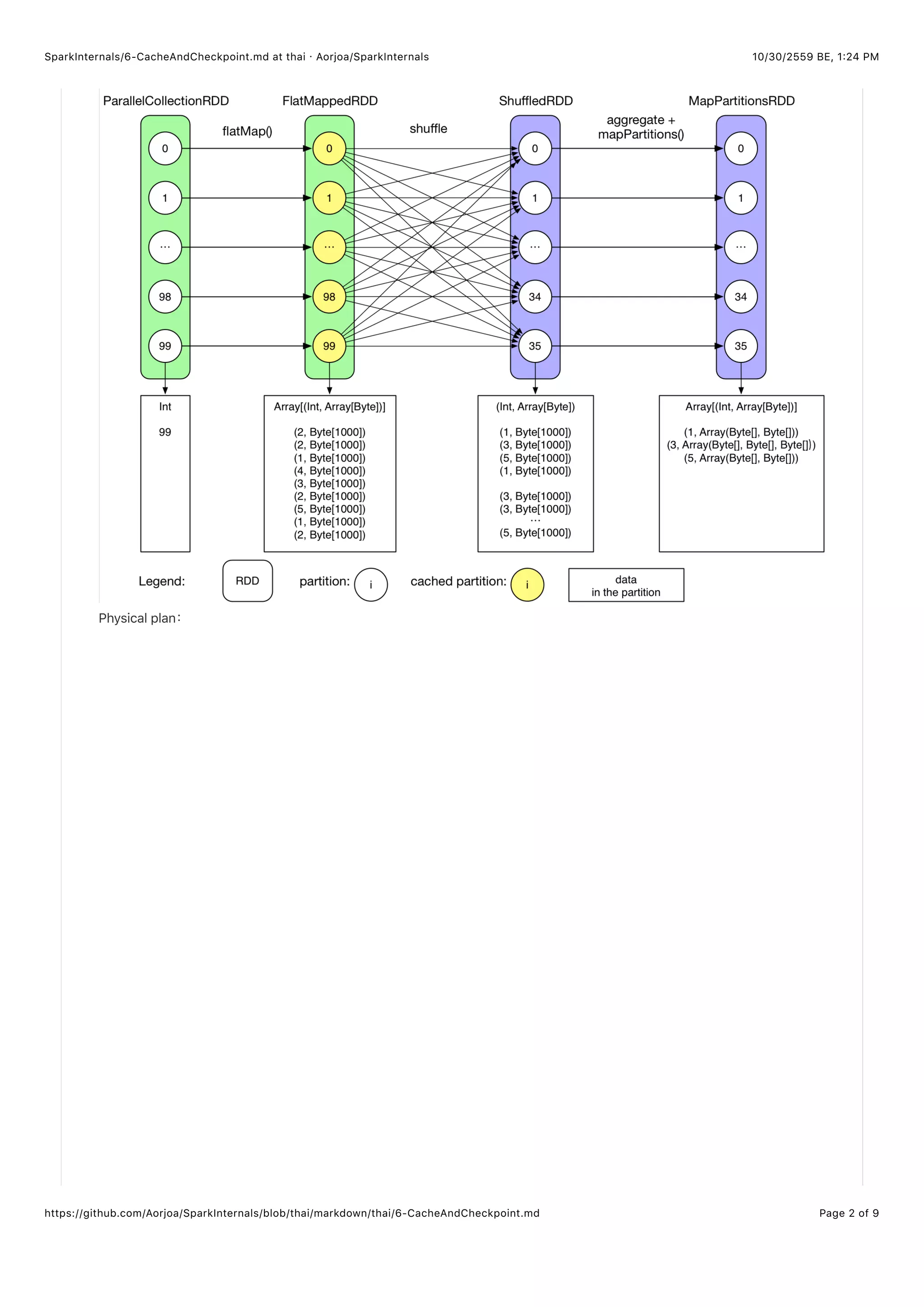
ลองกลับไปดูการทำ GroupByTest ในบทที่เป็นภาพรวม เราจะเห็นว่า FlatMappedRDD จะถูกแคชไว้ดังนั้น Job 1 (Job ถัดมา) สามารถ
เริ่มได้ที่ FlatMappedRDD นี้ได้เลย เนื่องจาก cache() ทำให้สามารถแบ่งปันข้อมูลกันใช้ระหว่าง Job ในแอพพลิเคชันเดียวกัน
Logical plan
Raw Blame History
0 7581Unwatch Star Fork
64.
10/30/2559 BE, 1,24PMSparkInternals/6-CacheAndCheckpoint.md at thai · Aorjoa/SparkInternals
Page 2 of 9https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/6-CacheAndCheckpoint.md
Physical plan


![10/30/2559 BE, 1,18 PMSparkInternals/1-Overview.md at thai · Aorjoa/SparkInternals
Page 2 of 7https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/1-Overview.md
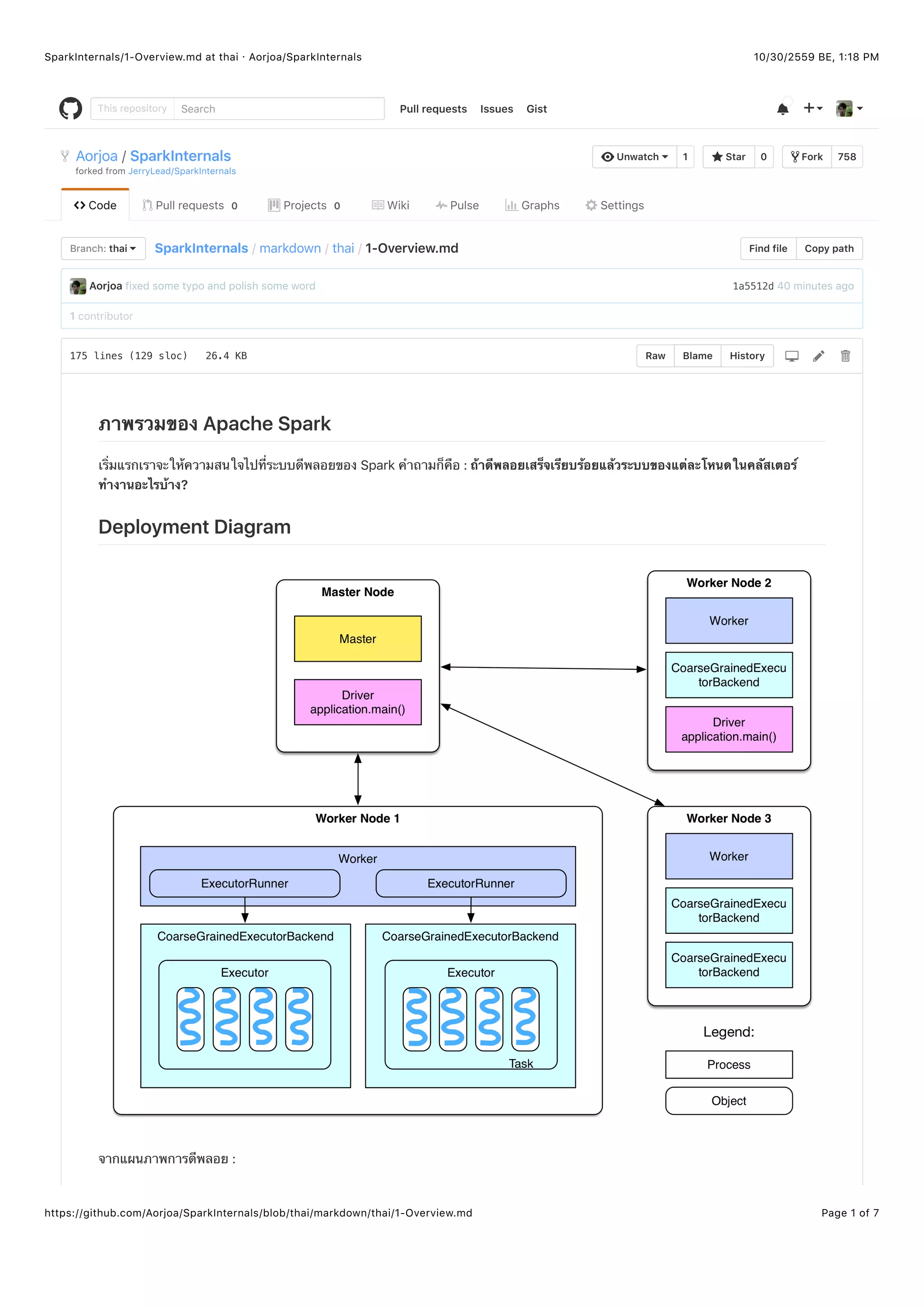
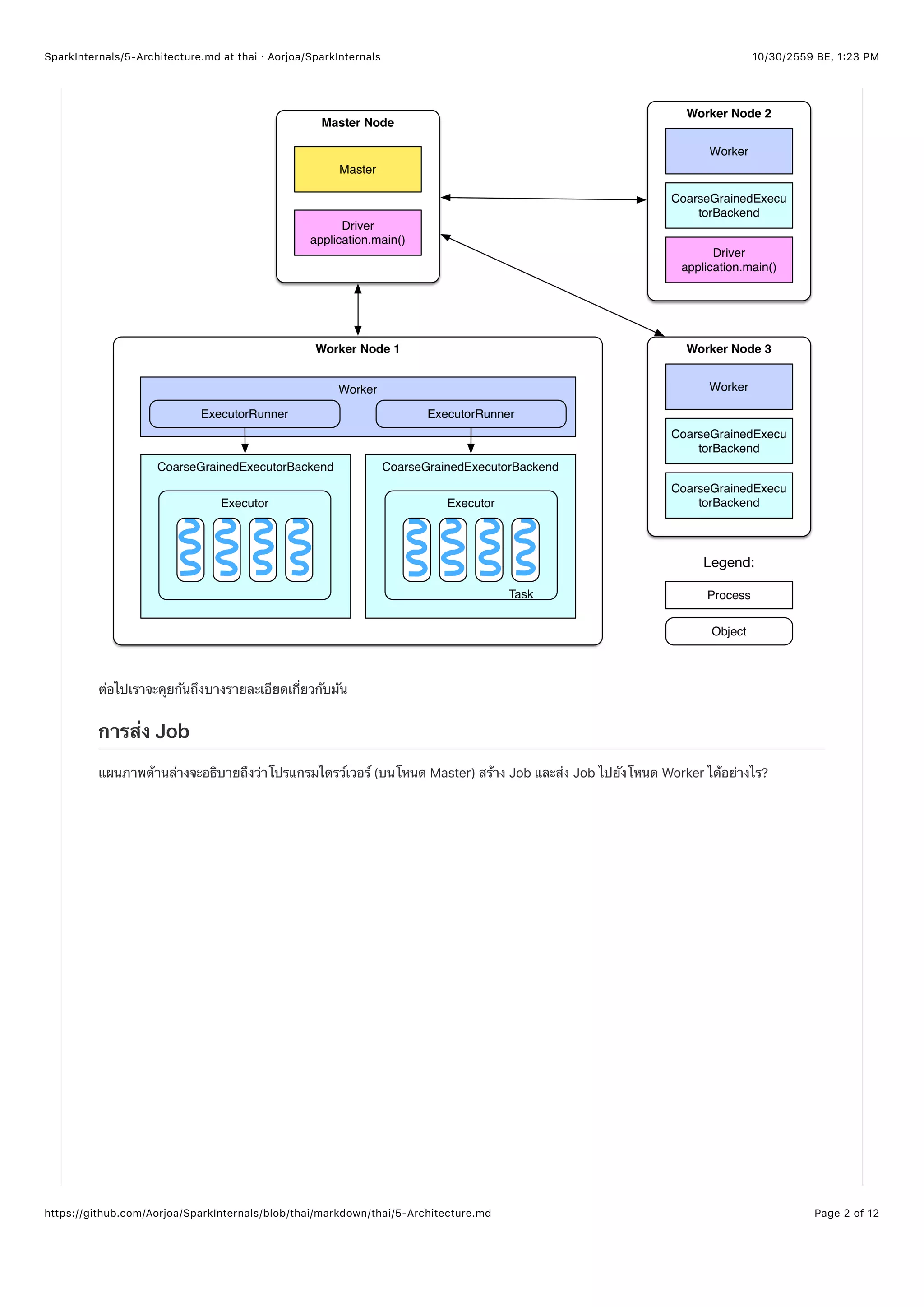
- โหนด Master และโหนด Worker ในคลัสเตอร์ มีหน้าที่เหมือนกับโหนด Master และ Slave ของ Hadoop
- โหนด Master จะมีโปรเซส Master ที่ทำงานอยู่เบื้องหลังเพื่อที่จะจัดการโหนด Worker ทุกตัว
- โหนด Worker จะมีโปรเซส Worker ทำงานอยู่เบื้องหลังซึ่งรับผิดชอบการติดต่อกับโหนด Master และจัดการกับ Executer ภายในตัว
โหนดของมันเอง
- Driver ในเอกสารที่เป็นทางการอธิบายว่า "The process running the main() function of the application and creating the
SparkContext" ไดรว์เวอร์คือโปรเซสที่กำลังทำงานฟังก์ชั่น main() ซึ่งเป็นฟังก์ชันที่เอาไว้เริ่มต้นการทำงานของแอพพลิเคชันของเราและ
สร้าง SparkContext ซึ่งจะเป็นสภาพแวดล้อมที่แอพพลิเคชันจะใช้ทำงานร่วมกัน และแอพพลิเคชันก็คือโปรแกรมของผู้ใช้ที่ต้องให้ประมวล
ผล บางทีเราจะเรียกว่าโปรแกรมไดรว์เวอร์ (Driver program) เช่น WordCount.scala เป็นต้น หากโปรแกรมไดรเวอร์กำลังทำงานอยู่บน
โหนด Master ยกตัวอย่าง
./bin/run-example SparkPi 10
จากโค้ดด้านบนแอพพลิเคชัน SparkPi สามารถเป็นโปรแกรมไดรว์เวอร์สำหรับโหนด Master ได้ ในกรณีของ YARN (ตัวจัดการคลัสเตอร์
ตัวหนึ่ง) ไดรว์เวอร์อาจจะถูกสั่งให้ทำงานที่โหนด Worker ได้ ซึ่งถ้าดูตามแผนภาพด้านบนมันเอาไปไว้ที่โหนด Worker 2 และถ้าโปรแกรม
ไดรเวอร์ถูกสร้างภายในเครื่องเรา เช่น การใช้ Eclipse หรือ IntelliJ บนเครื่องของเราเองตัวโปรแกรมไดรว์เวอร์ก็จะอยู่ในเครื่องเรา พูด
ง่ายๆคือไดรว์เวอร์มันเปลี่ยนที่อยู่ได้
val sc = new SparkContext("spark://master:7077", "AppName")
แม้เราจะชี้ตัว SparkContext ไปที่โหนด Master แล้วก็ตามแต่ถ้าโปรแกรมทำงานบนเครื่องเราตัวไดรว์เวอร์ก้ยังจะอยู่บนเครื่องเรา อย่างไร
ก็ดีวิธีนี้ไม่แนะนำให้ทำถ้าหากเน็ตเวิร์คอยู่คนละวงกับ Worker เนื่องจากจะทำใหการสื่อสารระหว่าง Driver กับ Executor ช้าลงอย่างมาก มี
ข้อควรรู้บางอย่างดังนี้
เราสามารถมี ExecutorBackend ได้ตั้งแต่ 1 ตัวหรือหลายตัวในแต่ละโหนด Worker และตัว ExecutorBackend หนึ่งตัวจะมี
Executor หนึ่งตัว แต่ละ Executor จะดูแล Thread pool และ Task ซึ่งเป็นงานย่อยๆ โดยที่แต่ละ Task จะทำงานบน Thread ตัวเดียว
แต่ละแอพพลิเคชันมีไดรว์เวอร์ได้แค่ตัวเดียวแต่สามารถมี Executor ได้หลายตัว, และ Task ทุกตัวที่อยู่ใน Executor เดียวกันจะเป็น
ของแอพพลิเคชันตัวเดียวกัน
ในโหมด Standalone, ExecutorBackend เป็นอินสแตนท์ของ CoarseGrainedExecutorBackend
คลัสเตอร์ของผู้เขียนมีแค่ CoarseGrainedExecutorBackend ตัวเดียวบนแต่ละโหนด Worker ผู้เขียนคิดว่าหากมีหลาย
แอพพลิเคชันรันอยู่มันก็จะมีหลาย CoarseGrainedExecutorBackend แต่ไม่ฟันธงนะ
อ่านเพิ่มในบล๊อค (ภาษาจีน) Summary on Spark Executor Driver Resource Scheduling เขียนโดย
@OopsOutOfMemory ถ้าอยากรู้เพิ่มเติมเกี่ยวกับ Worker และ Executor
โหนด Worker จะควบคุม CoarseGrainedExecutorBackend ผ่านทาง ExecutorRunner
หลังจากดูแผนภาพการดีพลอยแล้วเราจะมาทดลองสร้างตัวอย่างของ Spark job เพื่อดูว่า Spark job มันถูกสร้างและประมวลผลยังไง
ตัวอย่างของ Spark Job
ตัวอย่างนี้เป็นตัวอย่างการใช้งานแอพพลิเคชันที่ชื่อ GroupByTest ภายใต้แพ็กเกจที่ติดมากับ Spark ซึ่งเราจะสมมุติว่าแอพพลิเคชันนี้
ทำงานอยู่บนโหนด Master โดยมีคำสั่งดังนี้
/* Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers] */
bin/run-example GroupByTest 100 10000 1000 36
โค้ดที่อยู่ในแอพพลิเคชันมีดังนี้
package org.apache.spark.examples
import java.util.Random
import org.apache.spark.{SparkConf, SparkContext}](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-6-2048.jpg)
![10/30/2559 BE, 1,18 PMSparkInternals/1-Overview.md at thai · Aorjoa/SparkInternals
Page 3 of 7https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/1-Overview.md
import org.apache.spark.SparkContext._
/**
* Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers]
*/
object GroupByTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("GroupBy Test")
var numMappers = 100
var numKVPairs = 10000
var valSize = 1000
var numReducers = 36
val sc = new SparkContext(sparkConf)
val pairs1 = sc.parallelize(0 until numMappers, numMappers).flatMap { p =>
val ranGen = new Random
var arr1 = new Array[(Int, Array[Byte])](numKVPairs)
for (i <- 0 until numKVPairs) {
val byteArr = new Array[Byte](valSize)
ranGen.nextBytes(byteArr)
arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)
}
arr1
}.cache
// Enforce that everything has been calculated and in cache
println(">>>>>>")
println(pairs1.count)
println("<<<<<<")
println(pairs1.groupByKey(numReducers).count)
sc.stop()
}
}
หลังจากที่อ่านโค้ดแล้วจะพบว่าโค้ดนี้มีแนวความคิดในการแปลงข้อมูลดังนี้
แอพพลิเคชันนี้ไม่ได้ซับซ้อนอะไรมาก เราจะประเมินขนาดของข้อมูลและผลลัพธ์ซึ่งแอพพลิเคชันก็จะมีการทำงานตามขั้นตอนดังนี้](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-7-2048.jpg)
![10/30/2559 BE, 1,18 PMSparkInternals/1-Overview.md at thai · Aorjoa/SparkInternals
Page 4 of 7https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/1-Overview.md
1. สร้าง SparkConf เพื่อกำหนดการตั้งค่าของ Spark (ตัวอย่างกำหนดชื่อของแอพพลิเคชัน)
2. สร้างและกำหนดค่า numMappers=100, numKVPairs=10,000, valSize=1000, numReducers= 36
3. สร้าง SparkContext โดยใช้การตั้งค่าจาก SparkConf ขั้นตอนนี้สำคัญมากเพราะ SparkContext จะมี Object และ Actor ซึ่งจำเป็น
สำหรับการสร้างไดรว์เวอร์
4. สำหรับ Mapper แต่ละตัว arr1: Array[(Int, Byte[])] Array ชื่อ arr1 จะถูกสร้างขึ้นจำนวน numKVPairs ตัว, ภายใน Array
แต่ละตัวมีคู่ Key/Value ซึ่ง Key เป็นตัวเลข (ขนาด 4 ไบต์) และ Value เป็นไบต์ขนาดเท่ากับ valSize อยู่ ทำให้เราประเมินได้ว่า ขนาด
ของ arr1 = numKVPairs * (4 + valSize) = 10MB , ดังนั้นจะได้ว่า ขนาดของ pairs1 = numMappers * ขนาดของ arr1
1000MB ตัวนี้ใช้เป็นการประเมินการใช้พื้นที่จัดเก็บข้อมูลได้
5. Mapper แต่ละตัวจะถูกสั่งให้ Cache ตัว arr1 (ผ่านทาง pairs1) เพื่อเก็บมันไว้ในหน่วยความจำเผื่อกรณีที่มีการเรียกใช้ (ยังไม่ได้ทำ
นะแต่สั่งใว้)
6. จากนั้นจะมีการกระทำ count() เพื่อคำนวณหาขนาดของ arr1 สำหรับ Mapper ทุกๆตัวซึ่งผลลัพธ์จะเท่ากับ numMappers *
numKVPairs = 1,000,000 การกระทำในขั้นตอนนี้ทำให้เกิดการ Cahce ที่ตัว arr1 เกิดขึ้นจริงๆ (จากคำสั่ง pairs1.count()1
ตัวนี้จะมีสมาชิก 1,000,000 ตัว)
7. groupByKey ถูกสั่งให้ทำงานบน pairs1 ซึ่งเคยถูก Cache เก็บไว้แล้ว โดยจำนวนของ Reducer (หรือจำนวนพาร์ทิชัน) ถูกกำหนด
ในตัวแปร numReducers ในทางทฤษฏีแล้วถ้าค่า Hash ของ Key มีการกระจายอย่างเท่าเทียมกันแล้วจะได้ numMappers *
numKVPairs / numReducer 27,777 ก็คือแต่ละตัวของ Reducer จะมีคู่ (Int, Array[Byte]) 27,777 คู่อยู่ในแต่ละ Reducer ซึ่ง
จะมีขนาดเท่ากับ ขนาดของ pairs1 / numReducer = 27MB
8. Reducer จะรวบรวมเรคคอร์ดหรือคู่ Key/Value ที่มีค่า Key เหมือนกันเข้าไว้ด้วยกันกลายเป็น Key เดียวแล้วก็ List ของ Byte (Int,
List(Byte[], Byte[], ..., Byte[]))
9. ในขั้นตอนสุดท้ายการกระทำ count() จะนับหาผลรวมของจำนวนที่เกิดจากแต่ละ Reducer ซึ่งผ่านขั้นตอนการ groupByKey มาแล้ว
(ทำให้ค่าอาจจะไม่ได้ 1,000,000 พอดีเป๊ะเพราะว่ามันถูกจับกลุ่มค่าที่ Key เหมือนกันซึ่งเป็นการสุ่มค่ามาและค่าที่ได้จากการสุ่มอาจจะ
ตรงกันพอดีเข้าไว้ด้วยกันแล้ว) สุดท้ายแล้วการกระทำ count() จะรวมผลลัพธ์ที่ได้จากแต่ละ Reducer เข้าไว้ด้วยกันอีกทีเมื่อทำงาน
เสร็จแล้วก็จะได้จำนวนของ Key ที่ไม่ซ้ำกันใน paris1
แผนเชิงตรรกะ Logical Plan
ในความเป็นจริงแล้วกระบวนการประมวลผลของแอพพลิเคชันของ Spark นั้นซับซ้อนกว่าที่แผนภาพด้านบนอธิบายไว้ ถ้าจะว่าง่ายๆ แผนเชิง
ตรรกะ Logical Plan (หรือ data dependency graph - DAG) จะถูกสร้างแล้วแผนเชิงกายภาพ Physical Plan ก็จะถูกผลิตขึ้น (English : a
logical plan (or data dependency graph) will be created, then a physical plan (in the form of a DAG) will be generated
เป็นการเล่นคำประมาณว่า Logical plan มันถูกสร้างขึ้นมาจากของที่ยังไม่มีอะไร Physical plan ในรูปของ DAG จาก Logical pan นั่นแหละ
จะถูกผลิตขึ้น) หลังจากขั้นตอนการวางแผนทั้งหลายแหล่นี้แล้ว Task จะถูกผลิตแล้วก็ทำงาน เดี๋ยวเราลองมาดู Logical plan ของ
แอพพลิเคชันดีกว่า
ตัวนี้เรียกใช้ฟังก์ชัน RDD.toDebugString แล้วมันจะคืนค่า Logical Plan กลับมา:
MapPartitionsRDD[3] at groupByKey at GroupByTest.scala:51 (36 partitions)
ShuffledRDD[2] at groupByKey at GroupByTest.scala:51 (36 partitions)
FlatMappedRDD[1] at flatMap at GroupByTest.scala:38 (100 partitions)
ParallelCollectionRDD[0] at parallelize at GroupByTest.scala:38 (100 partitions)
วาดเป็นแผนภาพได้ตามนี้:](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-8-2048.jpg)
![10/30/2559 BE, 1,18 PMSparkInternals/1-Overview.md at thai · Aorjoa/SparkInternals
Page 5 of 7https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/1-Overview.md
ข้อควรทราบ data in the partition เป็นส่วนที่เอาไว้แสดงค่าว่าสุดท้ายแล้วแต่ละพาร์ทิชันมีค่ามีค่ายังไง แต่มันไม่ได้
หมายความว่าข้อมูลทุกตัวจะต้องอยู่ในหน่วยความจำในเวลาเดียวกัน
ดังนั้นเราขอสรุปดังนี้:
ผู้ใช้จะกำหนดค่าเริ่มต้นให้ข้อมูลมีค่าเป็น Array จาก 0 ถึง 99 จากคำสั่ง 0 until numMappers จะได้จำนวน 100 ตัว
parallelize() จะสร้าง ParallelCollectionRDD แต่ละพาร์ทิชันก็จะมีจำนวนเต็ม i
FlatMappedRDD จะถูกผลิตโดยการเรียกใช้ flatMap ซึ่งเป็นเมธอตการแปลงบน ParallelCollectionRDD จากขั้นตอนก่อนหน้า ซึ่งจะ
ให้ FlatMappedRDD ออกมาในลักษณะ Array[(Int, Array[Byte])]
หลังจากการกระทำ count() ระบบก็จะทำการนับสมาชิกที่อยู่ในแต่ละพาร์ทิชันของใครของมัน เมื่อนับเสร็จแล้วผลลัพธ์ก็จะถูกส่งกลับไป
รวมที่ไดรว์เวอร์เพื่อที่จะได้ผลลัพธ์สุดท้ายออกมา
เนื่องจาก FlatMappedRDD ถูกเรียกคำสั่ง Cache เพื่อแคชข้อมูลไว้ในหน่วยความจำ จึงใช้สีเหลืองให้รู้ว่ามีความแตกต่างกันอยู่นะ
groupByKey() จะผลิต 2 RDD (ShuffledRDD และ MapPartitionsRDD) เราจะคุยเรื่องนี้กันในบทถัดไป
บ่อยครั้งที่เราจะเห็น ShuffleRDD เกิดขึ้นเพราะงานต้องการการสับเปลี่ยน ลักษณะความสัมพันธ์ของตัว ShuffleRDD กับ RDD ที่ให้
กำเนิดมันจะเป็นลักษณะเดียวกันกับ เอาท์พุทของ Mapper ที่สัมพันธ์กับ Input ของ Reducer ใน Hadoop
MapPartitionRDD เก็บผลลัพธ์ของ groupByKey() เอาไว้
ค่า Value ของ MapPartitionRDD ( Array[Byte] ) จำถูกแปลงเป็น Iterable
ตัวการกระทำ count() ก็จะทำเหมือนกับที่อธิบายไว้ด้านบน
เราจะเห็นได้ว่าแผนเชิงตรรกะอธิบายการไหลของข้อมูลในแอพพลิเคชัน: การแปลง (Transformation) จะถูกนำไปใช้กับข้อมูล, RDD
ระหว่างทาง (Intermediate RDD) และความขึ้นต่อกันของพวก RDD เหล่านั้น
แผนเชิงกายภาพ Physical Plan
ในจุดนี้เราจะชี้ให้เห็นว่าแผนเชิงตรรกะ Logical plan นั้นเกี่ยวข้องกับการขึ้นต่อกันของข้อมูลแต่มันไม่ใช่งานจริงหรือ Task ที่เกิดการ
ประมวลผลในระบบ ซึ่งจุดนี้ก็เป็นอีกหนึ่งจุดหลักที่ทำให้ Spark ต่างกับ Hadoop, ใน Hadoop ผู้ใช้จะจัดการกับงานที่กระทำในระดับ
กายภาพ (Physical task) โดยตรง: Mapper tasks จะถูกนำไปใช้สำหรับดำเนินการ (Operations) บนพาร์ทิชัน จากนั้น Reduce task จะ](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-9-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 1 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
This repository Pull requests Issues Gist
SparkInternals / markdown / thai / 2-JobLogicalPlan.md
Search
Aorjoa / SparkInternals
forked from JerryLead/SparkInternals
Code Pull requests 0 Projects 0 Wiki Pulse Graphs Settings
thaiBranch: Find file Copy path
1 contributor
1a5512d 42 minutes agoAorjoa fixed some typo and polish some word
290 lines (182 sloc) 42.5 KB
Job Logical Plan
ตัวย่างการสร้าง Logical plan
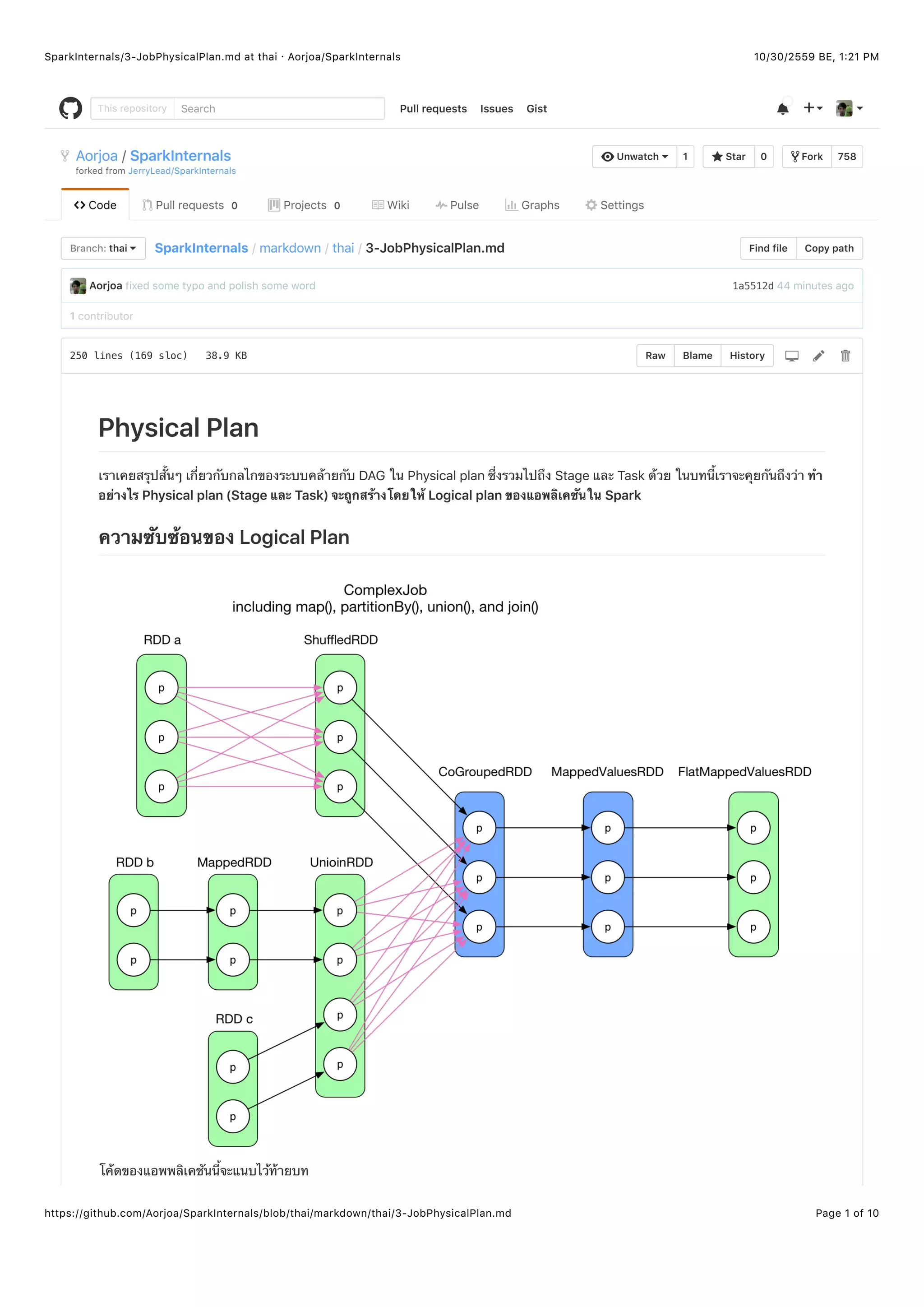
แผนภาพด้านบนอธิบายให้เห็นว่าขั้นตอนของแผนมีอยู่ 4 ขั้นตอนเพื่อให้ได้ผลลัพธ์สุดท้ายออกมา
1. เริ่มต้นสร้าง RDD จากแหล่งไหนก็ได้ (in-memory data, ไฟล์บนเครื่อง, HDFS, HBase, etc). (ข้อควรทราบ parallelize() มี
ความหมายเดียวกับ createRDD() ที่เคยกล่าวถึงในบนที่แล้ว)
2. ซีรีย์ของ transformation operations หรือการกระทำการแปลงบน RDD แสดงโดย transformation() แต่ละ
transformation() จะสร้าง RDD[T] ตั้งแต่ 1 ตัวขึ้นไป โดยที่ T สามารถเป็นตัวแปรประเภทไหนของ Scala ก็ได้ (ถ้าเขียนใน
Scala)
ข้อควรทราบ สำหรับคู่ Key/Value ลักษณะ RDD[(K, V)] นั้นจะจัดการง่ายกว่าถ้า K เป็นตัวแปรประเภทพื้นฐาน เช่น Int ,
Double , String เป็นต้น แต่มันไม่สามารถทำได้ถ้ามันเป็นตัวแปรชนิด Collection เช่น Array หรือ List เพราะ
กำหนดการพาร์ทิชันได้ยากในขั้นตอนการสร้างพาร์ทิชันฟังก์ชันของตัวแปรที่เป็นพวก Collection
3. Action operation แสดงโดย action() จะเรียกใช้ที่ RDD ตัวสุดท้าย จากนั้นในแต่ละพาร์ทิชันก็จะสร้างผลลัพธ์ออกมา
4. ผลลัพธ์เหล่านี้จะถูกส่งไปที่ไดรว์เวอร์จากนั้น f(List[Result]) จะคำนวณผลลัพธ์สุดท้ายที่จะถูกส่งกลับไปบอกไคลเอนท์ ตัวอย่าง
เช่น count() จะเกิด 2 ขั้นตอนคำ action() และ sum()
Raw Blame History
0 7581Unwatch Star Fork](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-12-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 2 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
RDD สามารถที่จะแคชและเก็บไว้ในหน่วยความจำหรือดิสก์โดยเรียกใช้ cache() , persist() หรือ checkpoint() จำนวนพาร์
ทิชันโดยปกติถูกกำหนดโดยผู้ใช้ ความสัมพธ์ของการพาร์ทิชันระหว่าง 2 RDD ไม่สามารถเป็นแบบ 1 to 1 ได้ และในตัวอย่างด้านบน
เราจะเห็นว่าไม่ใช้แค่ความสัมพันธ์แบบ 1 to 1 แต่เป็น Many to Many ด้วย
แผนเชิงตรรกะ Logical Plan
ตอนที่เขียนโค้ดของ Spark คุณก็จะต้องมีแผนภาพการขึ้นต่อกันอยู่ในหัวแล้ว (เหมือนตัวอย่างที่อยู่ข้างบน) แต่ไอ้แผนที่วางไว้มันจะเป็นจริงก็
ต่อเมื่อ RDD ถูกทำงานจริง (มีคำสั่งmี่เป็นการกระทำ Action)
เพื่อที่จะให้เข้าใจชัดเจนยิ่งขึ้นเราจะคุยกันในเรื่องของ
จะสร้าง RDD ได้ยังไง ? RDD แบบไหนถึงจะประมวลผล ?
จะสร้างความสัมพันธ์ของการขึ้นต่อกันของ RDD ได้อย่างไร ?
1. จะสร้าง RDD ได้ยังไง ? RDD แบบไหนถึงจะประมวลผล ?
คำสั่งพวก transformation() โดยปกติจะคืนค่าเป็น RDD แต่เนื่องจาก transformation() นั้นมีการแปลงที่ซับซ้อนทำให้มี
sub- transformation() หรือการแปลงย่อยๆเกิดขึ้นนั่นทำให้เกิด RDD หลายตัวขึ้นได้จึงเป็นเหตุผลที่ว่าทำไม RDD ถึงมีเยอะขึ้นได้ ซึ่ง
ในความเป็นจริงแล้วมันเยอะมากกว่าที่เราคิดซะอีก
Logical plan นั้นเป็นสิ่งจำเป็นสำหรับ Computing chain ทุกๆ RDD จะมี compute() ซึ่งจะรับเรคอร์ดข้อมูลจาก RDD ก่อนหน้าหรือ
จากแหล่งข้อมูลมา จากนั้นจะแปลงตาม transformation() ที่กำหนดแล้วให้ผลลัพธ์ส่งออกมาเป็นเรคอร์ดที่ถูกประมวลผลแล้ว
คำถามต่อมาคือแล้ว RDD อะไรที่ถูกประมวลผล? คำตอบก็ขึ้นอยู่กับว่าประมวลผลด้วยตรรกะอะไร transformation() และเป็น RDD อะไรที่
รับไปประมวลผลได้
เราสามารถเรียนรู้เกี่ยวกับความหมาบของแต่ละ transformation() ได้บนเว็บของ Spark ส่วนรายละเอียดที่แสดงในตารางด้านล่างนี้
ยกมาเพื่อเพิ่มรายละเอียด เมื่อ iterator(split) หมายถึง สำหรับทุกๆเรคอร์ดในพาร์ทิชัน ช่องที่ว่างในตารางเป็นเพราะความซับซ้อน
ของ transformation() ทำให้ได้ RDD หลายตัวออกมา เดี๋ยวจะได้แสดงต่อไปเร็วๆนี้
Transformation Generated RDDs Compute()
map(func) MappedRDD iterator(split).map(f)
filter(func) FilteredRDD iterator(split).filter(f)
flatMap(func) FlatMappedRDD iterator(split).flatMap(f)
mapPartitions(func) MapPartitionsRDD f(iterator(split))
mapPartitionsWithIndex(func) MapPartitionsRDD f(split.index, iterator(split))
sample(withReplacement,
fraction, seed)
PartitionwiseSampledRDD
PoissonSampler.sample(iterator(split))
BernoulliSampler.sample(iterator(split))
pipe(command, [envVars]) PipedRDD
union(otherDataset)
intersection(otherDataset)
distinct([numTasks]))
groupByKey([numTasks])
reduceByKey(func,
[numTasks])
sortByKey([ascending],
[numTasks])
join(otherDataset, [numTasks])
cogroup(otherDataset,](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-13-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 3 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
[numTasks])
cartesian(otherDataset)
coalesce(numPartitions)
repartition(numPartitions)
2. จะสร้างความสัมพันธ์ของการขึ้นต่อกันของ RDD ได้อย่างไร ?
เราอยากจะชี้ให้เห็นถึงสิ่งต่อไปนี้:
การขึ้นต่อกันของ RDD, RDD x สามารถขึ้นต่อ RDD พ่อแม่ได้ 1 หรือหลายตัว ?
มีพาร์ทิชันอยู่เท่าไหร่ใน RDD x ?
อะไรที่เป็นความสัมพันธ์ระหว่างพาร์ทิชันของ RDD x กับพวกพ่อแม่ของมัน? 1 พาร์ทิชันขึ้นกับ 1 หรือหลายพาร์ทิชันกันแน่ ?
คำถามแรกนั้นจิ๊บจ้อยมาก ยกตัวอย่างเช่น x = rdda.transformation(rddb) , e.g., val x = a.join(b) หมายความว่า RDD x
ขึ้นต่อ RDD a และ RDD b (แหงหล่ะเพราะ x เกิดจากการรวมกันของ a และ b นิ)
สำหรับคำถามที่สอง อย่างที่ได้บอกไว้ก่อนหน้านี้แล้วว่าจำนวนของพาร์ทิชันนั้นถูกกำหนดโดยผู้ใช้ ค่าเริ่มต้นของมันก็คือมันจะเอาจำนวนพาร์
ทิชันที่มากที่สุดของพ่อแม่มันมา) max(numPartitions[parent RDD 1], ..., numPartitions[parent RDD n])
คำถามสุดท้ายซับซ้อนขึ้นมาหน่อย เราต้องรู้ความหมายของการแปลง transformation() ซะก่อน เนื่องจาก
transformation() แต่ละตัวมีการขึ้นต่อกันที่แตกต่างกันออกไป ยกตัวอย่าง map() เป็น 1[1 ในขณะที่ groupByKey() ก่อให้เกิด
ShuffledRDD ซึ่งในแต่ละพาร์ทิชันก็จะขึ้นต่อทุกพาร์ทิชันที่เป็นพ่อแม่ของมัน นอกจากนี้บาง transformation() ยังซับซ้อนขึ้นไปกว่านี้
อีก
ใน Spark จะมีการขึ้นต่อกันอยู่ 2 แบบ ซึ่งกำหนดในรูปของพาร์ทิชันของพ่อแม่:
NarrowDependency (OneToOneDependency, RangeDependency)
แต่ละพาร์ทิชันของ RDD ลูกจะขึ้นอยู่กับพาร์ทิชันของแม่ไม่กี่ตัว เช่น พาร์ทิชันของลูกขึ้นต่อ ทั่วทั้ง พาร์ทิชันของพ่อแม่ (full
dependency)
ShuffleDependency (หรือ Wide dependency, กล่าวถึงในเปเปอร์ของ Matei)
พาร์ทิชันลูกหลายส่วนขึ้นกับพาร์ทิชันพ่อแม่ เช่นในกรณีที่แต่ละพาร์ทิชันของลูกขึ้นกับ บางส่วน ขอวพาร์ทิชันพ่อแม่ (partial
dependency)
ยกตัวอย่าง map จะทำให้เกิด Narrow dependency ขณะที่ join จะทำให้เกิด Wide dependency (เว้นแต่ว่าในกรณีของพ่อแม่ที่เอา
มา join กันทั้งคู่เป็น Hash-partitioned)
ในอีกนัยหนึ่งแต่ละพาร์ทิชันของลูกสามารถขึ้นต่อพาร์ทิชันพ่อแม่ตัวเดียว หรือขึ้นต่อบางพาร์ทิชันของพ่อแม่เท่านั้น
ข้อควรรู้:
สำหรับ NarrowDependency จะรู้ว่าพาร์ทิชันลูกต้องการพาร์ทิชันพ่อแม่หนึ่งหรือหลายตัวมันขึ้นอยู่กับฟังก์ชัน
getParents(partition i) ใน RDD ตัวลูก (รายละเอียดเดี๋ยวจะตามมาทีหลัง)
ShuffleDependency คล้ายกัย Shuffle dependency ใน MapReduce [ผู้แปล:น่าจะหมายถึงเปเปอร์ของ Google] ตัว Mapper
จะทำพาร์ทิชันเอาท์พุท, จากนั้นแต่ละ Reducer จะดึงพาร์ทิชันที่มันจำเป็นต้องใช้จากพาร์ทิชันที่เป็นเอาท์พุทจาก Mapper ผ่านทาง
http.fetch)
ความขึ้นต่อกันทั้งสองแสดงได้ตามแผนภาพข้างล่าง.](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-14-2048.jpg)

![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 5 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
code1 of iter.f() เป็นลักษณะของการวนเรคอร์ดทำฟังก์ชัน f
int[] array = {1, 2, 3, 4, 5}
for(int i = 0; i < array.length; i++)
f(array[i])
code2 of f(iter) เป็นลักษณะการส่งข้อมูลทั้งหมดไปให้ฟังก์ชัน f ทำงานเลย
int[] array = {1, 2, 3, 4, 5}
f(array)
3. ภาพอธิบายประเภทการขึ้นต่อกันของการคำนวณ
1) union(otherRDD)
union() เป็นการรวมกัยง่ายๆ ระหว่างสอง RDD เข้าไว้ด้วยกันโดยไม่เปลี่ยนพาร์ทิชันของข้อมูล RangeDependency (1[1) ยังคงรักษา
ขอบของ RDD ดั้งเดิมไว้เพื่อที่จะยังคงความง่ายในการเข้าถึงพาร์ทิชันจาก RDD ที่ถูกสร้างจากฟังก์ชัน union()](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-16-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 6 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
2) groupByKey(numPartitions) [เปลี่ยนใน Spark 1.3]
เราเคยคุยกันถึงการขึ้นต่อกันของ groupByKey มาก่อนหน้านี้แล้ว ตอนนี้เราจะมาทำให้มันชัดเจนขึ้น
groupByKey() จะรวมเรคอร์ดที่มีค่า Key ตรงกันเข้าไว้ด้วยกันโดยใช้วิธีสับเปลี่ยนหรือ Shuffle ฟังก์ชัน compute() ใน
ShuffledRDD จะดึงข้อมูลที่จำเป็นสำหรับพาร์ทิชันของมัน จากนั้นทำคำสั่ง mapPartition() (เหมือน OneToOneDependency ),
MapPartitionsRDD จะถูกผลิตจาก aggregate() สุดท้ายแล้วชนิดข้อมูลของ Value คือ ArrayBuffer จะถูก Cast เป็น Iterable
groupByKey() จะไม่มีการ Combine เพื่อรวมผลลัพธ์ในฝั่งของ Map เพราะการรวมกันมาจากฝั่งนั้นไม้่ได้ทำให้จำนวนข้อมูลที่
Shuffle ลดลงแถมยังต้องการให้ฝั่ง Map เพิ่มข้อมูลลงใน Hash table ทำให้เกิด Object ที่เก่าแล้วเกิดขึ้นในระบบมากขึ้น
ArrayBuffer จะถูกใช้เป็นหลัก ส่วน CompactBuffer มันเป็นบัฟเฟอร์แบบเพิ่มได้อย่างเดียวซึ่งคล้ายกับ ArrayBuffer แต่จะใช้
หน่วยความจำได้มีประสิทธิภาพมากกว่าสำหรับบัฟเฟอร์ขนาดเล็ก (ตในส่วนนี้โค้ดมันอธีบายว่า ArrayBuffer ต้องสร้าง Object ของ
Array ซึ่งเสียโอเวอร์เฮดราว 80-100 ไบต์
3) reduceyByKey(func, numPartitions) [เปลี่ยนแปลงในรุ่น 1.3]](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-17-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 8 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
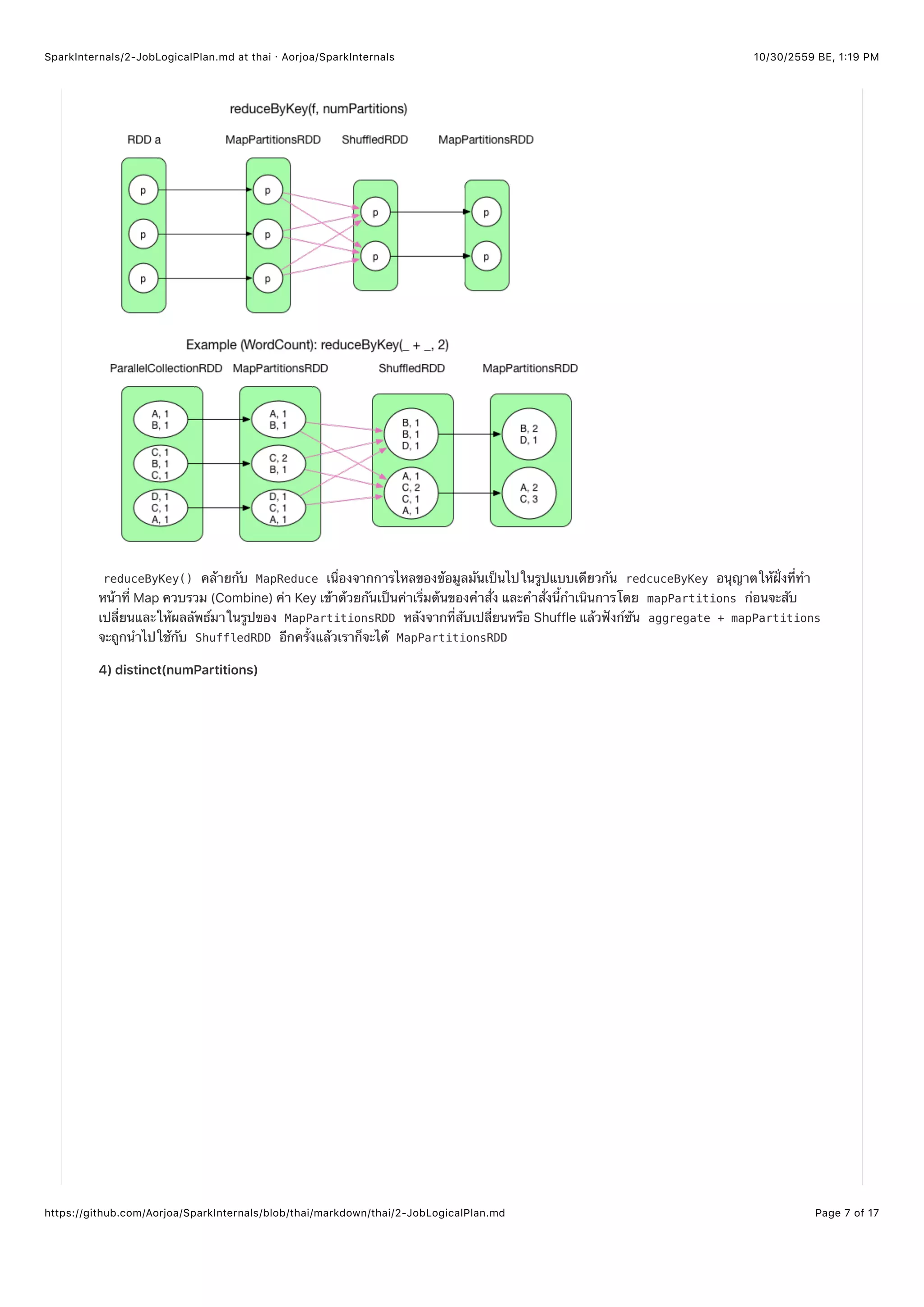
distinct() สร้างขึ้นมาเพื่อที่จะลดความซ้ำซ้อนกันของเรคอร์ดใน RDD เนื่องจากเรคอร์ดที่ซ้ำกันสามารถเกิดได้ในพาร์ทิชันที่ต่างกัน
กลไกการ Shuffle จำเป็นต้องใช้ในการลดความซ้ำซ้อนนี้โดยการใช้ฟังก์ชัน aggregate() อย่างไรก็ตามกลไก Shuffle ต้องการ RDD
ในลักษณะ RDD[(K, V)] ซึ่งถ้าเรคอร์ดมีแค่ค่า Key เช่น RDD[Int] ก็จะต้องทำให้มันอยู่ในรูปของ <K, null> โดยการ map()
( MappedRDD ) หลังจากนั้น reduceByKey() จะถูกใช้ในบาง Shuffle (mapSideCombine->reduce->MapPartitionsRDD) ท้ายสุด
แล้วจะมีแค่ค่า Key ทีถูกยิบไปจากคุ่ โดยใช้ map() ( MappedRDD ). ReduceByKey() RDDs จะใช้สีน้ำเงิน (ดูรูปจะเข้าใจมากขึ้น)
5) cogroup(otherRDD, numPartitions)](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-19-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 10 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
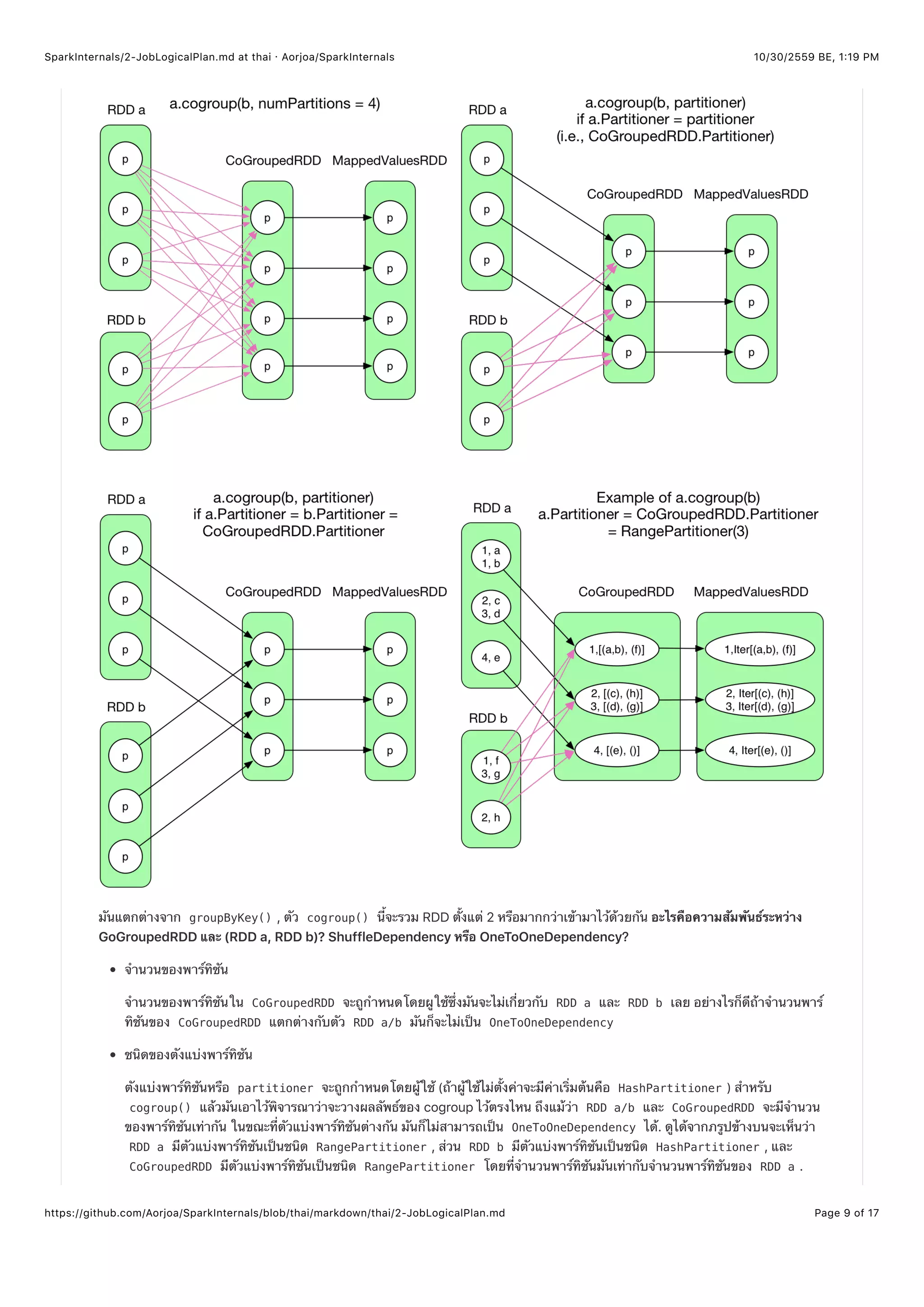
หากสังเกตจะพบได้อย่างชัดเจนว่าเรคอร์ดในแต่ละพาร์ทิชันของ RDD a สามารถส่งไปที่พาร์ทิชันของ CoGroupedRDD ได้เลย แต่
สำหรับ RDD b จำถูกแบ่งออกจากกัน (เช่นกรณีพาร์ทิชันแรกของ RDD b ถูกแบ่งออกจากกัน) แล้วสับเปลี่ยนไปไว้ในพาร์ทิชันที่ถูก
ต้องของ CoGroupedRDD
โดยสรุปแล้ว OneToOneDependency จะเกิดขึ้นก็ต่อเมื่อชนิดของตัวแบ่งพาร์ทิชันและจำนวนพาร์ทิชันของ 2 RDD และ CoGroupedRDD
เท่ากัน ไม่อย่างนั้นแล้วมันจะต้องเกิดกระบวนการ ShuffleDependency ขึ้น สำหรับรายละเอียดเชิงลึกหาอ่านได้ที่โค้ดในส่วนของ
CoGroupedRDD.getDependencies()
Spark มีวิธีจัดการกับความจริงเกี่ยวกับ CoGroupedRDD ที่พาร์ทิชันมีการขึ้นต่อกันบนหลายพาร์ทิชันของพ่อแม่ได้อย่างไร
อันดับแรกเลย CoGroupedRDD จะวาง RDD ที่จำเป็นให้อยู่ในรูปของ rdds: Array[RDD]
จากนั้น,
Foreach rdd = rdds(i):
if CoGroupedRDD and rdds(i) are OneToOneDependency
Dependecy[i] = new OneToOneDependency(rdd)
else
Dependecy[i] = new ShuffleDependency(rdd)
สุดท้ายแล้วจำคืน deps: Array[Dependency] ออกมา ซึ่งเป็น Array ของการขึ้นต่อกัน Dependency ที่เกี่ยวข้องกับแต่และ RDD พ่อ
แม่
Dependency.getParents(partition id) คืนค่า partitions: List[Int] ออกมาซึ่งคือพาร์ทิชันที่จำเป็นเพื่อสร้างพาร์ทิชันไอดีนี้
( partition id ) ใน Dependency ที่กำหนดให้
getPartitions() เอาไว้บอกว่ามีพาร์ทิชันใน RDD อลู่เท่าไหร่และบอกว่าแต่ละพาร์ทิชัน serialized ไว้อย่างไร
6) intersection(otherRDD)](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-21-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 11 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
intersection() ตั้งใจให้กระจายสมาชิกทุกตัวของ RDD a และ b . ตัว RDD[T] จะถูก Map ให้อยู่ในรูป RDD[(T, null)] (T เป็น
ชนิดของตัวแปร ไม่สามารถเป็น Collection เช่นพวก Array, List ได้) จากนั้น a.cogroup(b) (แสดงด้วยสำน้ำเงิน). filter() เอา
เฉพาะ [iter(groupA()), iter(groupB())] ไม่มีตัวไหนเป็นค่าว่าง ( FilteredRDD ) สุดท้ายแล้วมีแค่ keys() ที่จะถูกเก็บไว้
( MappedRDD )
7)join(otherRDD, numPartitions)](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-22-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 12 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
join() รับ RDD[(K, V)] มา 2 ตัว, คล้ายๆกับการ join ใน SQL. และคล้ายกับคำสั่ง intersection() , มันใช้ cogroup()
ก่อนจากนั้นให้ผลลัพธ์เป็น MappedValuesRDD ชนิดของพวกมันคือ RDD[(K, (Iterable[V1], Iterable[V2]))] จากนั้นหาผลคูณ](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-23-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 13 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
คาร์ทีเซียน Cartesian product ระหว่างสอง Iterable , ขั้นตอนสุดท้ายเรียกใช้ฟังก์ชัน flatMap() .
นี่เป็นตัอย่างสองตัวอย่างของ join กรณีแรก, RDD 1 กับ RDD 2 ใช้ RangePartitioner ส่วน CoGroupedRDD ใช้
HashPartitioner ซึ่งแตกต่างกับ RDD 1/2 ดังนั้นมันจึงมีการเรียกใช้ ShuffleDependency . ในกรณีที่สอง, RDD 1 ใช้ตัวแบ่งพาร์
ทิชันบน Key ชนิด HashPartitioner จากนั้นได้รับ 3 พาร์ทิชันซึ่งเหมือนกับใน CoGroupedRDD แป๊ะเลย ดังนั้นมันเลยเป็น
OneToOneDependency นอกจากนั้นแล้วถ้า RDD 2 ก็ถูกแบ่งโดนตัวแบ่งแบบเดียวกันคือ HashPartitioner(3) แล้วจะไม่เกิด
ShuffleDependency ขึ้น ดังนั้นการ join ประเภทนี้สามารถเรียก hashjoin()
8) sortByKey(ascending, numPartitions)
sortByKey() จะเรียงลำดับเรคอร์ดของ RDD[(K, V)] โดยใช้ค่า Key จากน้อยไปมาก ascending ถูกกำหนดใช้โดยตัวแปร
Boolean เป็นจริง ถ้ามากไปน้อยเป็นเท็จ. ผลลัพธ์จากขั้นนี้จะเป็น ShuffledRDD ซึ่งมีตัวแบ่งชนิด rangePartitioner ตัวแบ่งชนิดของ
พาร์ทิชันจะเป็นตัวกำหนดขอบเขตของแต่ละพาร์ทิชัน เช่น พาร์ทิชันแรกจะมีแค่เรคอร์ด Key เป็น char A to char B และพาร์ทิชันที่สองมี
เฉพาะ char C ถึง char D ในแต่ละพาร์ทิชันเรคอร์ดจะเรียงลำดับตาม Key สุดท้ายแล้วจะได้เรคร์ดมาในรูปของ MapPartitionsRDD
ตามลำดับ
sortByKey() ใช้ Array ในการเก็บเรคอร์ดของแต่ละพาร์ทิชันจากนั้นค่อยเรียงลำดับ
9) cartesian(otherRDD)](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-24-2048.jpg)
![10/30/2559 BE, 1,19 PMSparkInternals/2-JobLogicalPlan.md at thai · Aorjoa/SparkInternals
Page 16 of 17https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/2-JobLogicalPlan.md
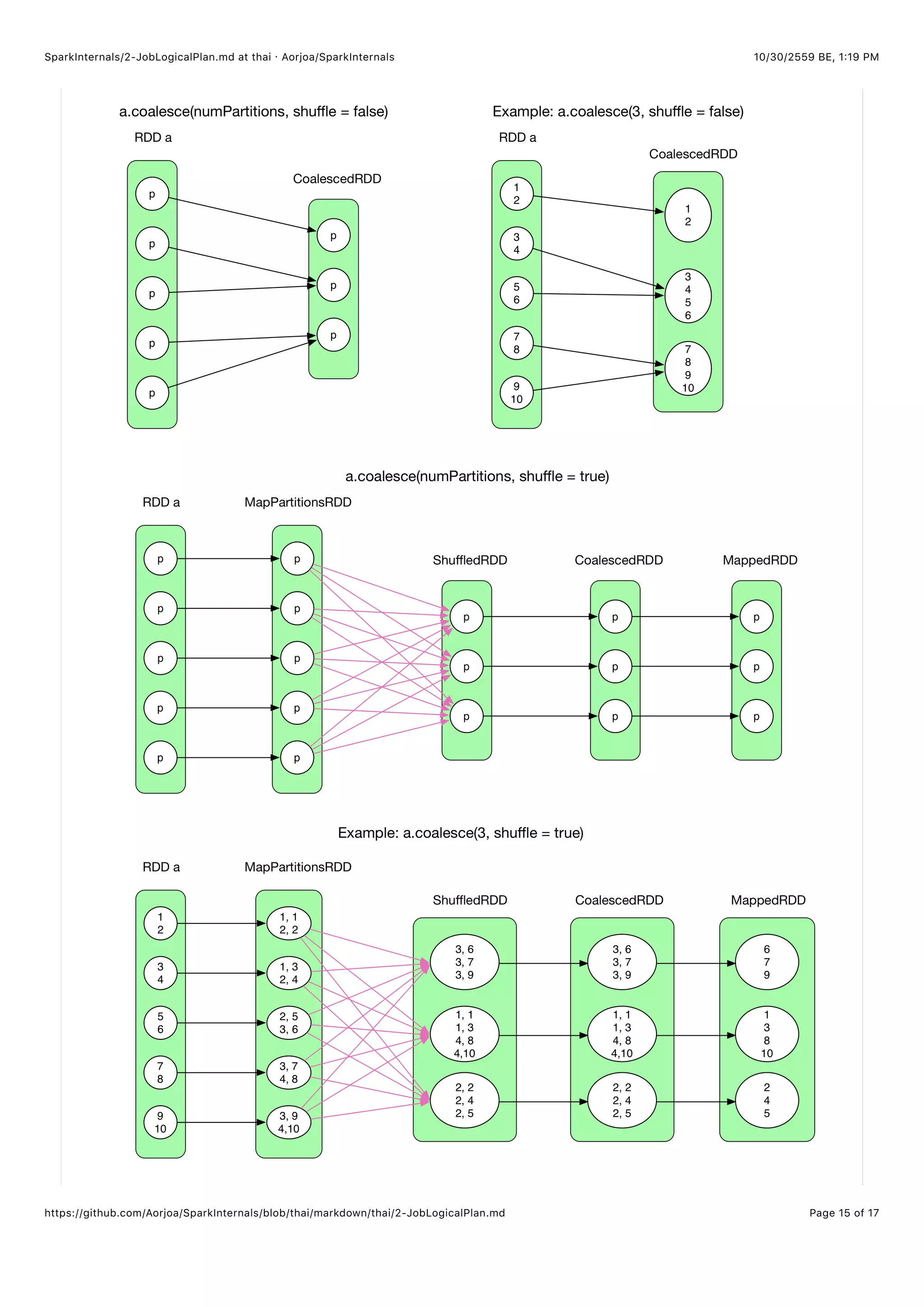
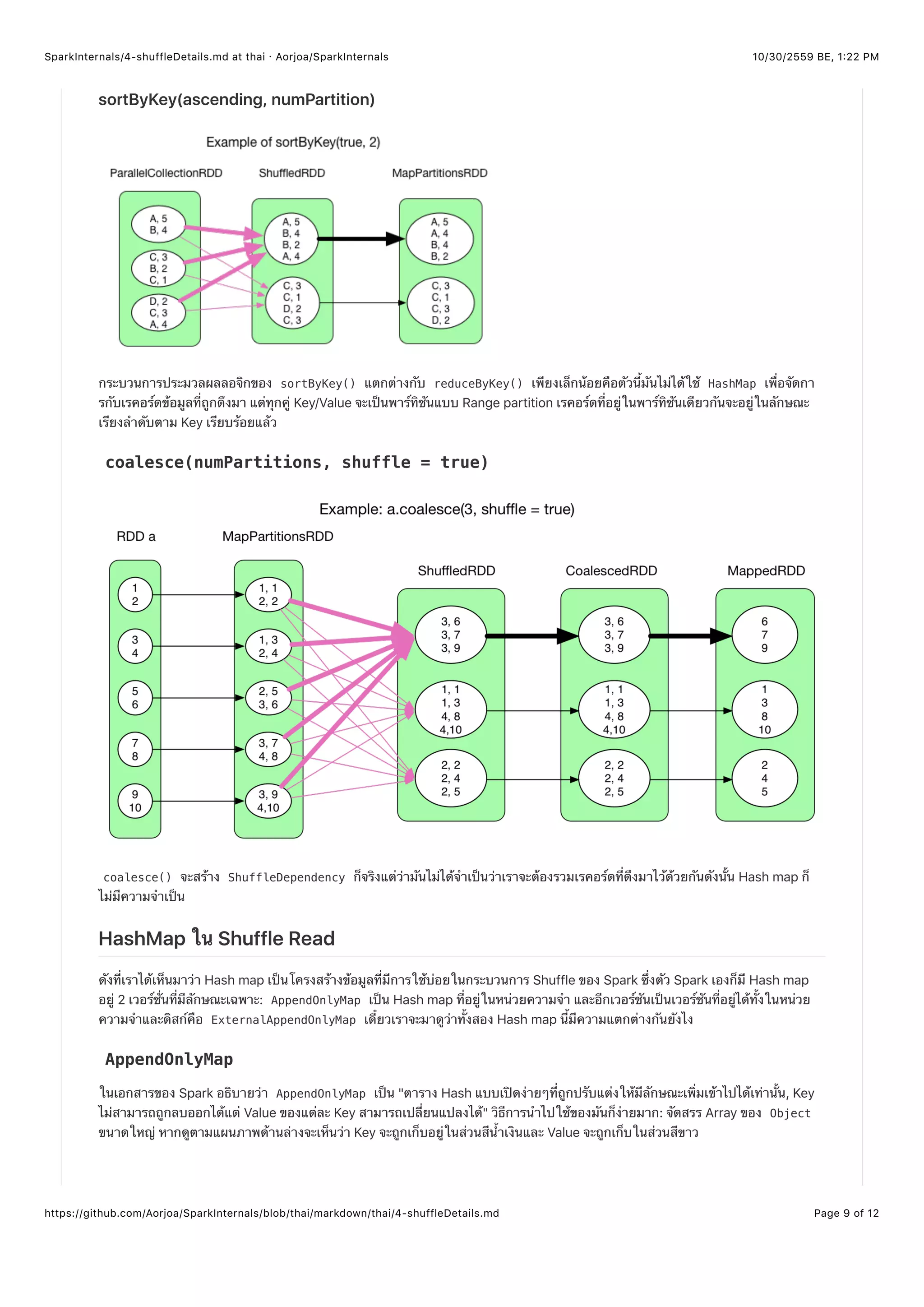
coalesce() สามารถใช้ปรับปรุงการแบ่งพาร์ทิชัน อย่างเช่น ลดจำนวนของพาร์ทิชันจาก 5 เป็น 3 หรือเพิ่มจำนวนจาก 5 เป็น 10 แต่ต้อง
ขอแจ้งให้ทราบว่าถ้า shuffle = false เราไม่สามารถที่จะเพิ่มจำนวนของพาร์ทิชันได้ เนื่องจากมันจะถูกบังคับให้ Shuffle ซึ่งเราไม่
อยากให้มันเกิดขึ้นเพราะมันไม่มีความหมายอะไรเลยกับงาน
เพื่อทำความเข้าใจ coalesce() เราจำเป็นต้องรู้จักกับ ความสัมพันธ์ระหว่างพาร์ทิชันของ CoalescedRDD กับพาร์ทิชันพ่อแม่
coalesce(shuffle = false) ในกรณีที่ Shuffle ถูกปิดใช้งาน สิ่งที่เราต้องทำก็แค่จัดกลุ่มบางพาร์ทิชันของพ่อแม่ และในความ
เป็นจริงแล้วมันมีตัวแปรหลายตัวที่จะถูกนำมาพิจารณา เช่น จำนวนเรคอร์ดในพาร์ทิชัน, Locality และบาลานซ์ เป็นต้น ซึ่ง Spark ค่อน
ข้างจะมีขั้นตอนวิธีที่ซับซ้อนในการทำ (เดี๋ยวเราจะคุยกันถึงเรื่องนี้) ยกตัวอย่าง a.coalesce(3, shuffle = false) โดยทั่วไป
แล้วจะเป็น NarrowDependency ของ N[1.
coalesce(shuffle = true) ถ้าหากเปิดใช้งาน Shuffle ฟังก์ชัน coalesce จะแบ่งทุกๆเรคอร์ดของ RDD ออกจากกันแบบง่าย
เป็น N ส่วนซึ่งสามารถใช้ทริกคล้ายๆกับ Round-robin ทำได้:
สำหรับแต่ละพาร์ทิชันทุกๆเรคอร์ดที่อยู่ในนั้นจะได้รับ Key ซึ่งจะเป็นเลขที่เพิ่มขึ้นในแต่ละเรคอร์ด (จำนวนที่นับเพิ่มเรื่อย)
hash(key) ทำให้เกิดรูปแบบเดียวกันคือกระจายตัวอยู่ทุกๆพาร์ทิชันอย่างสม่ำเสมอ
ในตัวอย่างที่สอง สมาชิกทุกๆตัวใน RDD a จะถูกรวมโดยค่า Key ที่เพิ่มขึ้นเรื่อยๆ ค่า Key ของสมาชิกตัวแรกในพาร์ทิชันคือ (new
Random(index)).nextInt(numPartitions) เมื่อ index คืออินเด็กซ์ของพาร์ทิชันและ numPartitions คือจำนวนของพาร์ทิชั
นใน CoalescedRDD ค่าคีย์ต่อมาจะเพิ่มขึ้นทีละ 1 หลังจาก Shuffle แล้วเรคอร์ดใน ShffledRDD จะมีรูปแบบการจะจายเหมือนกัน
ความสัมพันธ์ระหว่าง ShuffledRDD และ CoalescedRDD จะถูกกำหนดโดยความซับข้อนของขั้นตอนวิธี ในตอนสุดท้าย Key เหล่า
นั้นจะถูกลบออก ( MappedRDD ).
11) repartition(numPartitions)
มีความหมายเท่ากับ coalesce(numPartitions, shuffle = true)
Primitive transformation()
combineByKey()
ก่อนหน้านี้เราได้เห็น Logical plan ซึ่งบางตัวมีลักษณะคล้ายกันมาก เหตุผลก็คือขึ้นอยู่กับการนำไปใช้งานตามความเหมาะสมฃ
อย่างที่เรารู้ RDD ที่อยู่ฝั่งซ้ายมือของ ShuffleDependency จะเป็น RDD[(K, V)] , ในขณะที่ทางฝั่งขวามือทุกเรคอร์ดที่มี Key เดียวกัน
จะถูกรวมเข้าด้วยกัน จากนั้นจะดำเนินการอย่างไรต่อก็ขึ้นอยู่กับว่าผู้ใช้สั่งอะไรโดยที่มันก็จะทำกับเรคอร์ดที่ถูกรวบรวมไว้แล้วนั่นแหละ
ในความเป็นจริงแล้ว transformation() หลายตัว เช่น groupByKey() , reduceBykey() , ยกเว้น aggregate() ขณะที่มีการ
คำนวณเชิงตรรกะ ดูเหมือนกับว่า aggregate() และ compute() มันทำงานในเวลาเดียวกัน Spark มี combineByKey() เพื่อใช้การ
ดำเนินการ aggregate() + compute()
และนี่ก็คือก็คำนิยามของ combineByKey()
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)]
มี 3 พารามิเตอร์สำคัญที่เราต้องพูดถึงก็คือ:
createCombiner , ซึ่งจะเปลี่ยนจาก V ไปเป็น C (เช่น การสร้าง List ที่มีสมาชิกแค่ตัวเดียว)
mergeValue , เพื่อรวม V เข้าใน C (เช่น การเพิ่มข้อมูลเข้าไปที่ท้าย List)
mergeCombiners , เพื่อจะรวมรวม C เป็นค่าเดียว
รายละเอียด:
เมื่อมีบางค่า Key/Value เป็นเรคอร์ด (K, V) ถูกสั่งให้ทำ combineByKey() , createCombiner จะเอาเรคอร์ดแรกออกมเพื่อเริ่มต้น
ตัวรวบรวม Combiner ชนิด C (เช่น C = V).](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-27-2048.jpg)

![10/30/2559 BE, 1,21 PMSparkInternals/3-JobPhysicalPlan.md at thai · Aorjoa/SparkInternals
Page 6 of 10https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/3-JobPhysicalPlan.md
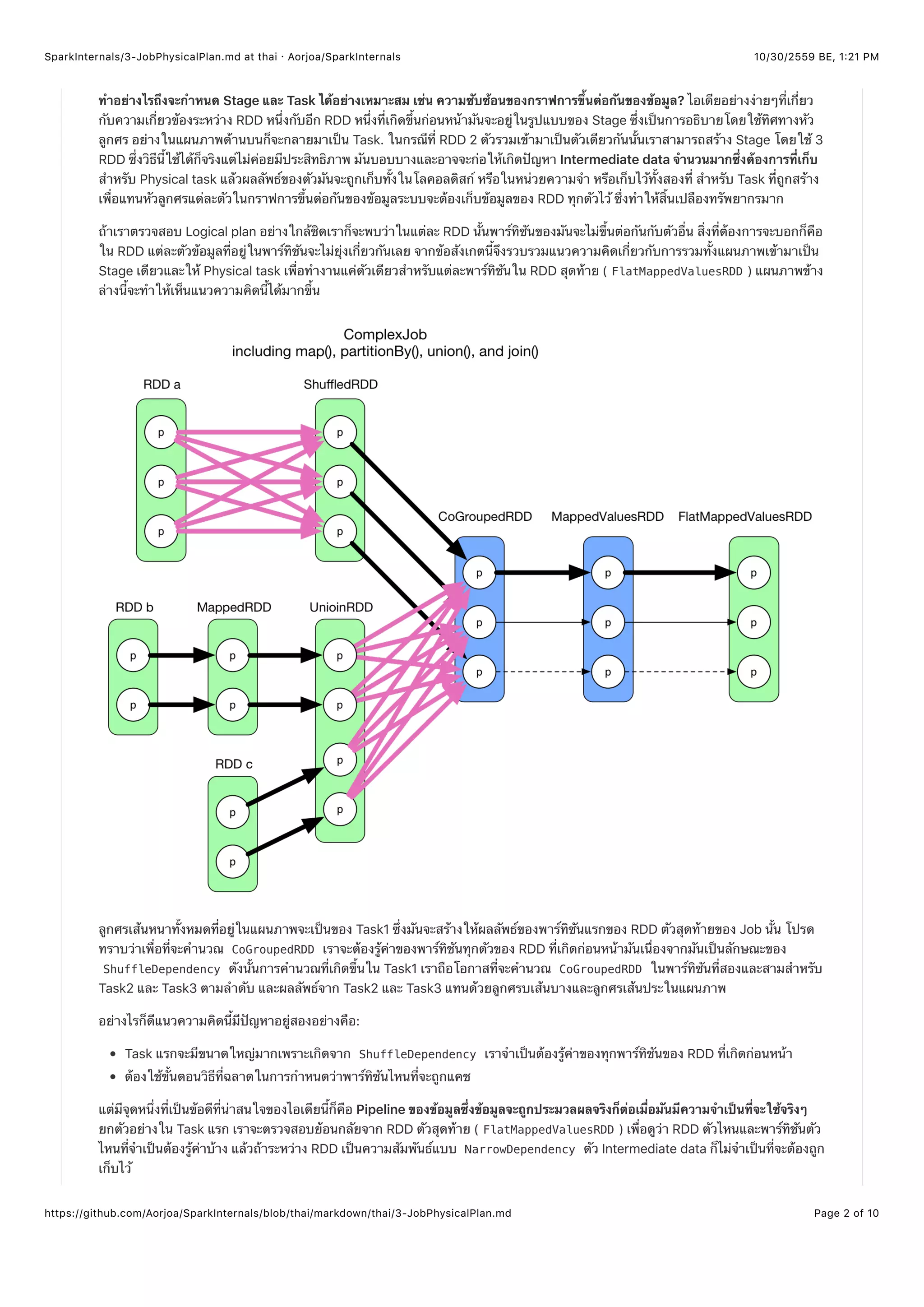
ผลลัพธ์สุดท้ายออกมา กระบวนการเหล่านี้แสดงได้ตามแผนภาพด้านล่าง:
กระบวนการประมวลผลนี้ไม่สามารถใช้กับ Physical plan ของ Spark ได้ตรงๆเพราะ Physical plan ของ Hadoop MapReduce นั้นมันเป็น
กลไลง่ายๆและกำหนดไว้ตายตัวโดยที่ไม่มีการ Pipeline ด้วย
ไอเดียหลักของการทำ Pipeline ก็คือ ข้อมูลจะถูกประมวลผลจริงๆ ก็ต่อเมื่อมันต้องการจะใช้จริงๆในกระบวนการไหลของข้อมูล เราจะเริ่ม
จากผลลัพธ์สุดท้าย (ดังนั้นจึงทราบอย่างชัดเจนว่าการคำนวณไหนบ้างที่ต้องการจริงๆ) จากนั้นตรวจสอบย้อนกลับตาม Chain ของ RDD เพื่อ
หาว่า RDD และพาร์ทิชันไหนที่เราต้องการรู้ค่าเพื่อใช้ในการคำนวณจนได้ผลลัพธ์สุดท้ายออกมา กรณีที่เจอคือส่วนใหญ่เราจะตรวจสอบย้อน
กลับไปจนถึงพาร์ทิชันบางตัวของ RDD ที่อยู่ฝั่งซ้ายมือสุดและพวกบางพาร์ทิชันที่อยู่ซ้ายมือสุดนั่นแหละที่เราต้องการที่จะรู้ค่าเป็นอันดับแรก
สำหรับ Stage ที่ไม่มีพ่อแม่ ตัวมันจะเป็น RDD ที่อยู่ซ้ายสุดโดยตัวมันเองซึ่งเราสามารถรู้ค่าได้โดยตรงอยู่แล้ว (มันไม่มีการขึ้นต่อกัน) และ
แต่ละเรคอร์ดที่รู้ค่าแล้วสามารถ Stream ต่อไปยังกระบวนการคำนวณที่ตามมาภายหลังมัน (Pipelining) Chain การคำนวณอนุมาณได้ว่า
มาจากขั้นตอนสุดท้าย (เพราะไล่จาก RDD ตัวสุดท้ายมา RDD ฝั่งซ้ายมือสุด) แต่กลไกการประมวลผลจริง Stream ของเรคอร์ดนั้นดำเนินไป
ข้างหน้า (ทำจริงจากซ้ายไปขวา แต่ตอนเช็คไล่จากขวาไปซ้าย) เรคอร์ดหนึ่งๆจถูกทำทั้ง Chain การประมวลผลก่อนที่จะเริ่มประมวลผลเร
คอร์ดตัวอื่นต่อไป
สำหรับ Stage ที่มีพ่อแม่นั้นเราต้องประมวลผลที่ Stage พ่อแม่ของมันก่อนแล้วจึงดึงข้อมูลผ่านทาง Shuffle จากนั้นเมื่อพ่อแม่ประมวลผล
เสร็จหนึ่งครั้งแล้วมันจะกลายเป็นกรณีที่เหมือนกัน Stage ที่ไม่มีพ่อแม่ (จะได้ไม่ต้องคำนวณซ้ำๆ)
ในโค้ดแต่ละ RDD จะมีเมธอต getDependency() ประกาศการขึ้นต่อกันของข้อมูลของมัน, compute() เป็นเมธอตที่ดูแลการรับเร
คอร์ดมาจาก Upstream (จาก RDD พ่อแม่หรือแหล่งเก็บข้อมูล) และนำลอจิกไปใช้กับเรคอร์ดนั้นๆ เราจะเห็นบ่อยมากในโคดที่เกี่ยว
กับ RDD (ผู้แปล: ตัวนี้เคยเจอในโค้ดของ Spark ในส่วนที่เกี่ยวกับ RDD) firstParent[T].iterator(split,
context).map(f) ตัว firstParent บอกว่าเป็น RDD ตัวแรกที่ RDD มันขึ้นอยู่ด้วย, iterator() แสดงว่าเรคอร์ดจะถูกใช้
แบบหนึ่งต่อหนึ่ง, และ map(f) เรคอร์ดแต่ละตัวจะถูกนำประมวลผลตามลอจิกการคำนวณที่ถูกกำหนดไว้. สุดท้ายแล้วเมธอต
compute() ก็จะคืนค่าที่เป็น Iterator เพื่อใช้สำหรับการประมวลผลถัดไป
สรุปย่อๆดังนี้ : *การคำนวณทั่วทั้ง Chain จะถูกสร้างโดยการตรวจสอบย้อนกลับจาก RDD ตัวสุดท้าย แต่ละ ShuffleDependency จะเป็น
ตัวแยก Stage แต่ละส่วนออกจากกัน และในแต่ละ Stage นั้น RDD แต่ละตัวจะมีเมธอต compute() ที่จะเรียกการประมวลผลบน RDD พ่อ
แม่ parentRDD.itererator() แล้วรับ Stream เรคอร์ดจาก Upstream *
โปรดทราบว่าเมธอต compute() จะถูกจองไว้สำหรับการคำนวณลิจิกที่สร้างเอาท์พุทออกจากโดยใช้ RDD พ่อแม่ของมันเท่านั้น. RDD
จริงๆของพ่อแม่ที่ RDD มันขึ้นต่อจะถูกประกาศในเมธอต getDependency() และพาร์ทิชันจริงๆที่มันขึ้นต่อจะถูกประกาศไว้ในเมธอต
dependency.getParents()
ลองดูผลคูณคาร์ทีเซียน CartesianRDD ในตัวอย่างนี้
// RDD x is the cartesian product of RDD a and RDD b
// RDD x = (RDD a).cartesian(RDD b)
// Defines how many partitions RDD x should have, what are the types for each partition
override def getPartitions: Array[Partition] = {
// create the cross product split
val array = new Array[Partition](rdd1.partitions.size * rdd2.partitions.size)
for (s1 <- rdd1.partitions; s2 <- rdd2.partitions) {
val idx = s1.index * numPartitionsInRdd2 + s2.index
array(idx) = new CartesianPartition(idx, rdd1, rdd2, s1.index, s2.index)
}
array
}](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-34-2048.jpg)
![10/30/2559 BE, 1,21 PMSparkInternals/3-JobPhysicalPlan.md at thai · Aorjoa/SparkInternals
Page 7 of 10https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/3-JobPhysicalPlan.md
// Defines the computation logic for each partition of RDD x (the result RDD)
override def compute(split: Partition, context: TaskContext) = {
val currSplit = split.asInstanceOf[CartesianPartition]
// s1 shows that a partition in RDD x depends on one partition in RDD a
// s2 shows that a partition in RDD x depends on one partition in RDD b
for (x <- rdd1.iterator(currSplit.s1, context);
y <- rdd2.iterator(currSplit.s2, context)) yield (x, y)
}
// Defines which are the dependent partitions and RDDs for partition i in RDD x
//
// RDD x depends on RDD a and RDD b, both in `NarrowDependency`
// For the first dependency, partition i in RDD x depends on the partition with
// index `i / numPartitionsInRDD2` in RDD a
// For the second dependency, partition i in RDD x depends on the partition with
// index `i % numPartitionsInRDD2` in RDD b
override def getDependencies: Seq[Dependency[_]] = List(
new NarrowDependency(rdd1) {
def getParents(id: Int): Seq[Int] = List(id / numPartitionsInRdd2)
},
new NarrowDependency(rdd2) {
def getParents(id: Int): Seq[Int] = List(id % numPartitionsInRdd2)
}
)
การสร้าง Job
จนถึงตอนนี้เรามีความรู้เรื่อง Logical plan และ Plysical plan แล้ว ทำอย่างไรและเมื่อไหร่ที่ Job จะถูกสร้าง? และจริงๆแล้ว Job มันคือ
อะไรกันแน่
ตารางด้านล่างแล้วถึงประเภทของ action() และคอลัมภ์ถัดมาคือเมธอต processPartition() มันใช้กำหนดว่าการประมวลผลกับเร
คอร์ดในแต่ละพาร์ทิชันจะทำอย่างไรเพื่อให้ได้ผลลัพธ์ คอลัมภ์ที่สามคือเมธอต resultHandler() จะเป็นตัวกำหนดว่าจะประมวลผลกับ
ผลลัพธ์บางส่วนที่ได้มาจากแต่ละพาร์ทิชันอย่างไรเพื่อให้ได้ผลลัพธ์สุดท้าย
Action finalRDD(records) => result compute(results)
reduce(func)
(record1, record2) => result, (result, record
i) => result
(result1, result 2) => result, (result, result i)
=> result
collect() Array[records] => result Array[result]
count() count(records) => result sum(result)
foreach(f) f(records) => result Array[result]
take(n) record (i<=n) => result Array[result]
first() record 1 => result Array[result]
takeSample() selected records => result Array[result]
takeOrdered(n,
[ordering])
TopN(records) => result TopN(results)
saveAsHadoopFile(path) records => write(records) null
countByKey() (K, V) => Map(K, count(K)) (Map, Map) => Map(K, count(K))
แต่ละครั้งที่มีการเรียก action() ในโปรแกรมไดรว์เวอร์ Job จะถูกสร้างขึ้น ยกตัวอย่าง เช่น foreach() การกระทำนี้จะเรียกใช้
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(f))) เพื่อส่ง Job ไปยัง DAGScheduler และถ้ามีการเรียก
action() อื่นๆอีกในโปรแกรมไดรว์เวอร์ระบบก็จะสร้า Job ใหม่และส่งเข้าไปใหม่อีกครั้ง ดังนั้นเราจึงจะมี Job ได้หลายตัวตาม
action() ที่เราเรียกใช้ในโปรแกรมไดรว์เวอร์ นี่คือเหตุผลที่ว่าทำไมไดรว์เวอร์ของ Spark ถูกเรียกว่าแอพพลิเคชันมากกว่าเรียกว่า Job](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-35-2048.jpg)
 เอาไว้สำหรับเก็บผลลัพธ์ตามจำนวนของพาร์ทิชัน
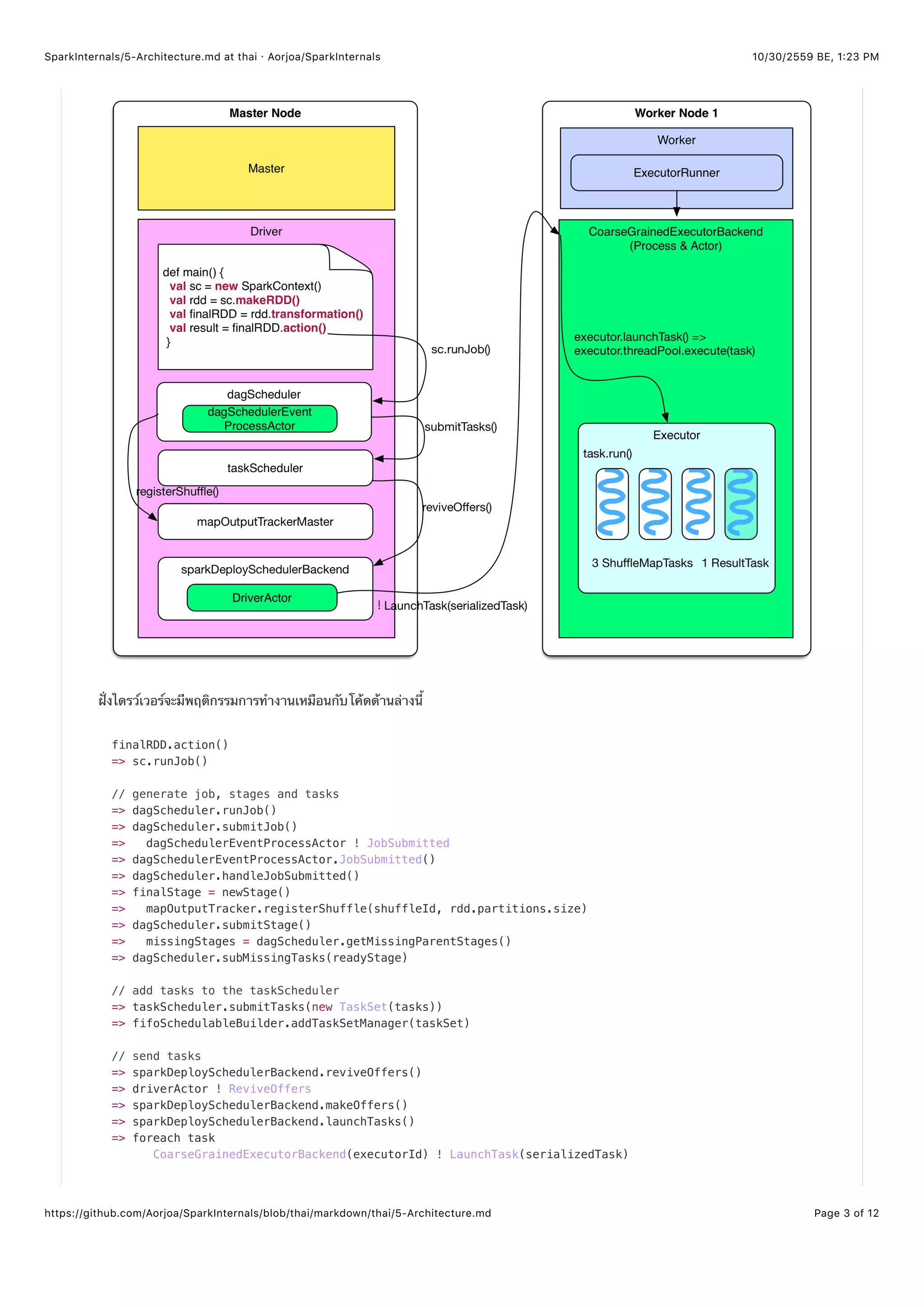
3. สุดท้ายแล้ว runJob(rdd, cleanedFunc, partitions, allowLocal, resultHandler) ใน DAGScheduler จะถูกเรียก
เพื่อส่ง Job, cleanedFunc เป็นลักษณะ Closure-cleaned ของฟังก์ชัน processPartition . ในกรณีนี้ฟังก์ชันสามารถที่จะ
Serialized ได้และสามารถส่งไปยังโหนด Worker ตัวอื่นได้ด้วย
4. DAGScheduler มีเมธอต runJob() ที่เรียกใช้ submitJob(rdd, func, partitions, allowLocal, resultHandler)
เพื่อส่ง Job ไปทำการประมวลผล
5. submitJob() รับค่า jobId , หลังจากนั้นจะห่อหรือ Warp ด้วยฟังก์ชันอีกทีหนึ่งแล้วถึงจะส่งข้อความ JobSubmitted ไปหา
DAGSchedulerEventProcessActor . เมื่อ DAGSchedulerEventProcessActor ได้รับข้อความแล้ว Actor ก็จะเรียกใช้
dagScheduler.handleJobSubmitted() เพื่อจัดการกับ Job ที่ถูกส่งเข้ามาแล้ว นี่เป็นตัวอย่างของ Event-driven programming
แบบหนึ่ง
6. handleJobSubmitted() อันดับแรกเลยจะเรียก finalStage = newStage() เพื่อสร้าง Stage แล้วจากนั้นก็จะ
submitStage(finalStage) . ถ้า finalStage มีพ่อแม่ ตัว Stage พ่อแม่จะต้องถูกประมวลผลก่อนเป็นอันดับแรกในกรณีนี้
finalStage นั้นจริงๆแล้วถูกส่งโดย submitWaitingStages() .
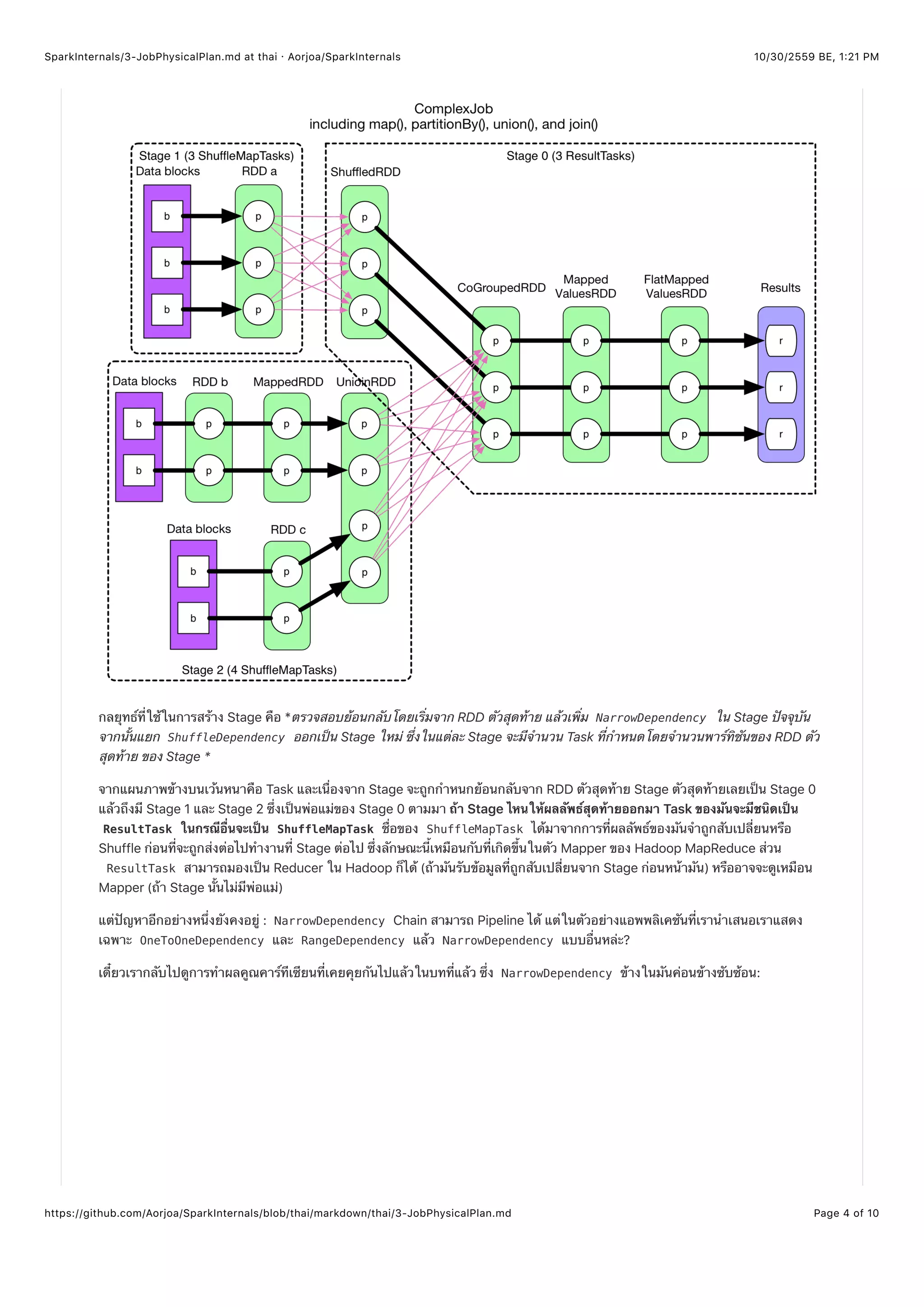
newStage() แบ่ง RDD Chain ใน Stage อย่างไร ?
เมธอต newStage() จะเรียกใช้ getParentStages() ของ RDD ตัวสุดท้ายเมื่อมีการสร้าง Stage ขึ้นมาใหม่ ( new
Stage(...) )
getParentStages() จะเริ่มไล่จาก RDD ตัวสุดท้ายจากนั้นตรวจสอบย้อนกลับโดยใช้ Logical plan และมันจะเพิ่ม RDD ลงใน
Stage ปัจจุบันถ้าหาก Stage นั้นเป็น NarrowDependency จนกระทั่งมันเจอว่ามี ShuffleDependency ระหว่าง RDD มันจะให้
RDD ตัวมันเองอยู่ฝั่งทางขวา (RDD หลังจากกระบวนการ Shuffle) จากนั้นก็จบ Stage ปัจจุบัน ทำแบบนี้ไล่ไปเรื่อยๆโดยเริ่มจาก RDD
ที่อยู่ทางซ้ายมือของ RDD ที่มีการ Shuffle เพื่อสร้าง Stage อื่นขึ้นมาใหม่ (ดูรูปการแบ่ง Stage อาจจะเข้าใจมากขึ้น)
เมื่อ ShuffleMapStage ถูกสร้างขึ้น RDD ตัวสุดท้ายของมันก็จะถูกลงทะเบียนหรือ Register
MapOutputTrackerMaster.registerShuffle(shuffleDep.shuffleId, rdd.partitions.size) . นี่เป็นสิ่งที่สำคัญ
เนื่องจากว่ากระบวนการ Shuffle จำเป็นต้องรู้ว่าเอาท์พุทจาก MapOuputTrackerMaster
ตอนนี้มาดูว่า submitStage(stage) ส่ง Stage และ Task ได้อย่างไร:
1. getMissingParentStages(stage) จะถูกเรียกเพื่อกำหนด missingParentStages ของ Stage ปัจจุบัน ถ้า Stage พ่อแม่ทุกตัว
ของมันถูกประมวลผลไปแล้วตัว missingParentStages จะมีค่าว่างเปล่า
2. ถ้า missingParentStages ไม่ว่างเปล่าจะทำการวนส่ง Stage ที่หายไปเหล่านั้นซ้ำและ Stage ปะจุบันจะถูกแทรกเข้าไปใน
waitingStages และเมื่อ Stage พ่อแม่ทำงานเรียบร้อยแล้ว Stage ที่อยู่ใน waitingStages จะถูกทำงาน
3. ถ้า missingParentStages ว่างเปล่าและเรารู้ว่า Stage สามารถถูกประมวลผลในขณะนี้ แล้ว submitMissingTasks(stage,
jobId) จะถูกเรียกให้สร้างและส่ง Task จริงๆ และถ้า Stage เป็น ShuffleMapStage แล้วเราจะจัดสรร ShuffleMapTask จำนวน
มากเท่ากับจำนวนของพาร์ทิชันใน RDD ตัวสุดท้าย ในกรณีที่เป็น ResultStage , ResultTask จะถูกจัดสรรแทน. Task ใน Stage
จะฟอร์ม TaskSet ขึ้นมา จากนั้นขั้นตอนสุดท้าย taskScheduler.submitTasks(taskSet) จำถูกเรียกและส่งเซ็ตของ Task
ทั้งหมดไป
4. ชนิดของ taskScheduler คือ TaskSchedulerImpl . ใน submitTasks() แต่ละ taskSet จะได้รับการ Wrap ในตัวแปร
manager ซึ่งเป็นตัวแปรของชนิด TaskSetManager แล้วจึงส่งมันไปทำ
schedulableBuilder.addTaskSetManager(manager) . schedulableBuilder สามารถเป็น FIFOSchedulableBuilder
หรือ FairSchedulableBuilder , ขึ้นอยู่กับว่าการตั้งค่ากำหนดไว้ว่าอย่างไร จากนั้นขั้นตอนสุดท้ายของ submitTasks() คือแจ้ง
backend.reviveOffers() เพื่อให้ Task ทำงาน. ชนิดของ Backend คือ SchedulerBackend . ถ้าแอพพลิเคชันทำงานอยู่บน
คลัสเตอร์มันจะเป็น Backend แบบ SparkDeploySchedulerBackend แทน
5. SparkDeploySchedulerBackend เป็น Sub-Class ของ CoarseGrainedSchedulerBackend , backend.reviveOffers()](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-36-2048.jpg)
![10/30/2559 BE, 1,21 PMSparkInternals/3-JobPhysicalPlan.md at thai · Aorjoa/SparkInternals
Page 9 of 10https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/3-JobPhysicalPlan.md
จริงๆจะส่งข้อความ ReviveOffers ไปหา DriverActor . SparkDeploySchedulerBackend จะเปิด DriverActor ในขั้น
ตอนเริ่มทำงาน. เมื่อ DriverActor ได้รับข้อความ ReviveOffers แล้วมันจะเรียก
launchTasks(scheduler.resourceOffers(Seq(new WorkerOffer(executorId, executorHost(executorId),
freeCores(executorId))))) เพื่อเปิดให้ Task ทำงาน จากนั้น scheduler.resourceOffers() ได้รับ TaskSetManager ที่
เรียงลำดับแล้วจากตัวจัดการงาน FIFO หรือ Fair และจะรวบรวมข้อมูลอื่นๆที่เกี่ยวกับ Task จาก
TaskSchedulerImpl.resourceOffer() . ซึ่งข้อมูลเหล่านั้นจัดเก็บอยู่ใน TaskDescription ในขั้นตอนนี้ตำแหน่งที่ตั้งของ
ข้อมูลหรือ Data locality ก็จะถูกพิจารณาด้วย
6. launchTasks() อยู่ใน DriverActor จะ Serialize แต่ละ Task ถ้าขนาดของ Serialize ไม่เกินลิมิตของ akkaFrameSize จานั้น
Task จะถูกส่งครั้งสุดท้ายไปยัง Executor เพื่อประมวลผล: executorActor(task.executorId) ! LaunchTask(new
SerializableBuffer(serializedTask)) .
การพูดคุย
จนกระทั่งถึงตอนนี้เราคุยกันถึง:
โปรแกรมไดร์เวอร์ Trigger Job ได้อย่างไร?
จะสร้าง Physical plan จาก Logical plan ได้อย่างไร?
อะไรคือการ Pipelining ใน Spark และจำนำมันไปใช้ได้อย่างไร?
โค้ดจริงๆที่สร้าง Job และส่ง Job เข้าสู่ระบบ
อย่างไรก็ตามก็ยังมีหัวข้อที่ไม่ได้ลงรายละเอียดคือ:
กระบวนการ Shuffle
การประมวลผลของ Task และตำแหน่งที่มันถูกประมวลผล
ในหัวข้อถัดไปเราจะถกเถียงกันถึงการะบวนการ Shuffle ใน Spark
ในความเห็นของผู้แต่งแล้วการแปลงจาก Logical plan ไปยัง Physical plan นั้นเป็นผลงานชิ้นเอกอย่างแท้จริง สิ่งที่เป็นนามธรร เช่น การขึ้น
ต่อกัน, Stage และ Task ทั้งหมดนี้ถูกกำหนดไว้อย่างดีสำหรับลอจิคของขั้นตอนวิธีก็ชัดเจนมาก
โค้ดจากตัวอย่างของ Job
package internals
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.HashPartitioner
object complexJob {
def main(args: Array[String]) {
val sc = new SparkContext("local", "ComplexJob test")
val data1 = Array[(Int, Char)](
(1, 'a'), (2, 'b'),
(3, 'c'), (4, 'd'),
(5, 'e'), (3, 'f'),
(2, 'g'), (1, 'h'))
val rangePairs1 = sc.parallelize(data1, 3)
val hashPairs1 = rangePairs1.partitionBy(new HashPartitioner(3))
val data2 = Array[(Int, String)]((1, "A"), (2, "B"),
(3, "C"), (4, "D"))
val pairs2 = sc.parallelize(data2, 2)
val rangePairs2 = pairs2.map(x => (x._1, x._2.charAt(0)))](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-37-2048.jpg)
, (2, 'Y'))
val rangePairs3 = sc.parallelize(data3, 2)
val rangePairs = rangePairs2.union(rangePairs3)
val result = hashPairs1.join(rangePairs)
result.foreachWith(i => i)((x, i) => println("[result " + i + "] " + x))
println(result.toDebugString)
}
}
Contact GitHub API Training Shop Blog About© 2016 GitHub, Inc. Terms Privacy Security Status Help](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-38-2048.jpg)



![10/30/2559 BE, 1,22 PMSparkInternals/4-shuffleDetails.md at thai · Aorjoa/SparkInternals
Page 8 of 12https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/4-shuffleDetails.md
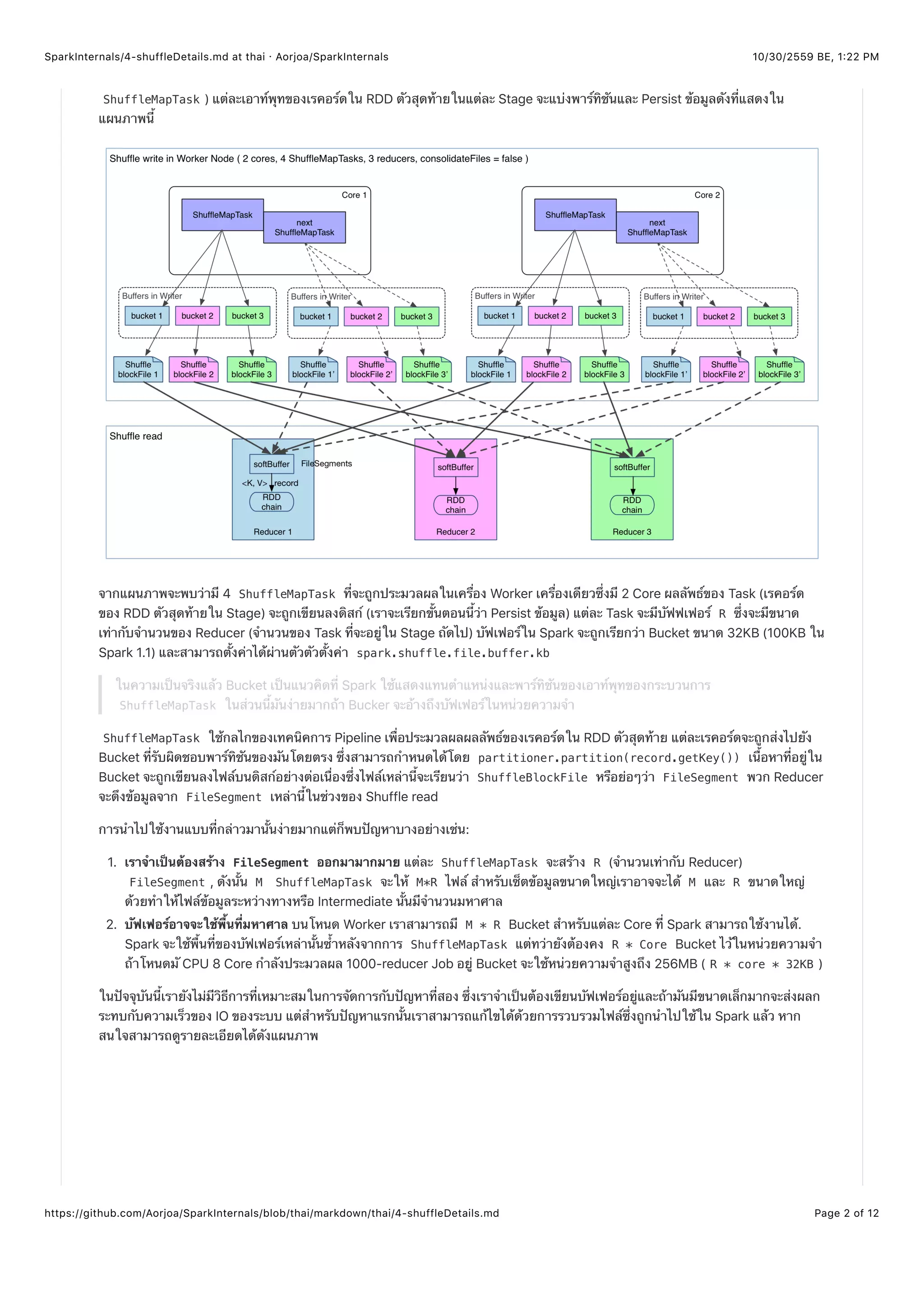
สามารถเป็นได้ทั้ง 0, 1 หรือหลาย ShuffleDependency สำหรับส่วนของ CoGroupedRDD แต่ในกระบวนการ Shuffle เราไม้ได้สร้าง
Hash map สำหรับ Shuffle dependency แต่ละตัวแต่จะใช่ Hash map แค่ตัวเดียวกับ Shuffle dependency ทุกตัว ซึ่งแตกต่างการ
reduceByKey ที่ Hash map จำถูกสร้างในเมธอต compute() ของ RDD มากกว่า mapPartitionWithContext()
Task ของการประมวลผลของ RDD จะจัดสรรให้มี Array[ArrayBuffer] ซึ่ง Array ตัวนี้จะมีจำนวนของ ArrayBuffer ที่ว่างเปล่า
เท่ากับจำนวนของ RDD อินพุท ยกตัวอย่างของแผนภาพด้านบนเรามี ArrayBffer อยู่ 2 ตัวในแต่ละ Task ซึ่งเท่ากับจำนวน RDD อินพุทที่
เข้ามา เมื่อคู่ Key/Value มาจาก RDD a มันจะเพิ่มเข้าไปใน ArrayBuffer ตัวแรกถ้าคู่ Key/Value มาจาก RDD b มันจะเพิ่มเข้าไปใน
ArrayBuffer ตัวที่สองจากนั้นจะเรียก mapValues() ให้ทำการแปลงจาก Values .ห้เป็นชนิดที่ถูกต้อง: (ArrayBuffer,
ArrayBuffer) => (Iterable[V], Iterable[W]) .
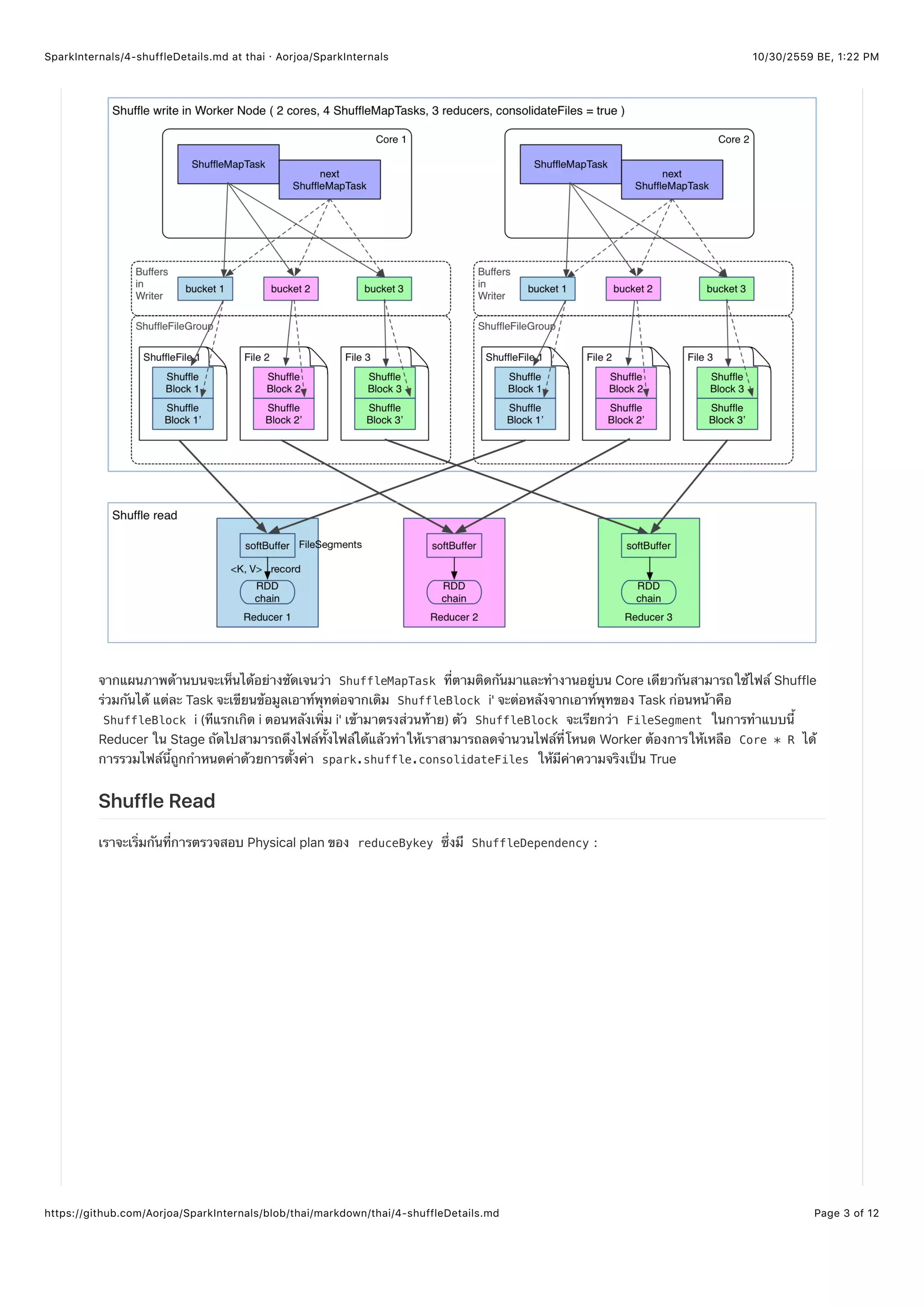
intersection(otherRDD) and join(otherRDD, numPartitions)
การดำเนินการของสองตัวนี้ใช้ cogroup ดังนั้นแล้วกระบวนการ Shuffle มันก็จะเป็นแบบ cogroup ด้วย](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-46-2048.jpg)
![10/30/2559 BE, 1,22 PMSparkInternals/4-shuffleDetails.md at thai · Aorjoa/SparkInternals
Page 10 of 12https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/4-shuffleDetails.md
เมื่อมีการ put(K,V) เกิดขึ้นเราจะหาช่องของ Array ได้โดย hash(K) ถ้าตำแหน่งช่องที่ได้มามีข้อมูลอยู่แล้วจะใช้วิธี Quandratic
probing เพื่อหาช่องวางไหม่ (ดูคำอธิบายในย่อหน้าถัดไป) ยกตัวอย่างในแผนภาพด้านบน K6 การ Probing ครั้งที่สามจึงจะพบช่อองว่าง
ซึ่งเป็นช่องที่หลังจาก K4 จากนั้น Value จะถูกแทรกเพิ่มหลังจากที่ Key แทรกเข้าไปแล้ว เมื่อ get(K6) เราก็จะใช้เทคนิคเดียวกันนี้เข้าถึง
แล้วดึง V6 ซึ่งเป็น Value ในช่องถัดจาก Key ออกมาจากนั้นคำนวณค่า Value ใหม่แล้วก็เขียนกลับไปในตำแหน่งเดิมของ V6
(Quandratic probing เป็นวิธีการหาช่องว่างของตาราง Hash ในกรณีที่ไม่สามารถหาช่องว่างจาก hash(K) โดยตรงได้จะเอา hash(K)
บวกเลขกําลังสองของจํานวนครั้งที่เกิดซ้ํา เช่น hash(K) + 1*1 ยังไม่ว่างก็ไปหา hash(K) + 2*2 ถ้ายังไม่ว่างอีก hash(K) + 3*3
การวนซ้ำบน AppendOnlyMap จะเป็นแค่การแสกน Array
ถ้า 70% ของ Array ถูกจัดสรรให้ใช้ไปแล้วมันจะมีการขยายเพิ่มเป็น 2 เท่าทำให้ Key จะถูกคำนวณ Hash ใหม่และตำแหน่งก็จะ
เปลี่ยนแปลงไป
AppendOnlyMap มีเมธอต destructiveSortedIterator(): Iterator[(K, V)] ซึ่งคืนค่าคู่ Key/Value ที่เรียงตามลำดับแล้ว ใน
ขั้นตอนการทำงานของมันจะเริ่มจากการที่กระชับคู่ Key/Value ไปให้อยู่ในลักษณะ Array ที่ค่าคู่ Key/Value อยู่ในช่องเดียวกัน (แผนภาพ
ด้านบนมันอยู่คนละช่อง) แล้วจากนั้นใช้ Array.sort() ซึ่งเป็นการเรียกให้เกิดการเรียงตามลำดับของข้อมูลใน Array แต่การดำเนินการ
นี้จะทำลายโครงสร้างของข้อมูล
ExternalAppendOnlyMap](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-48-2048.jpg)
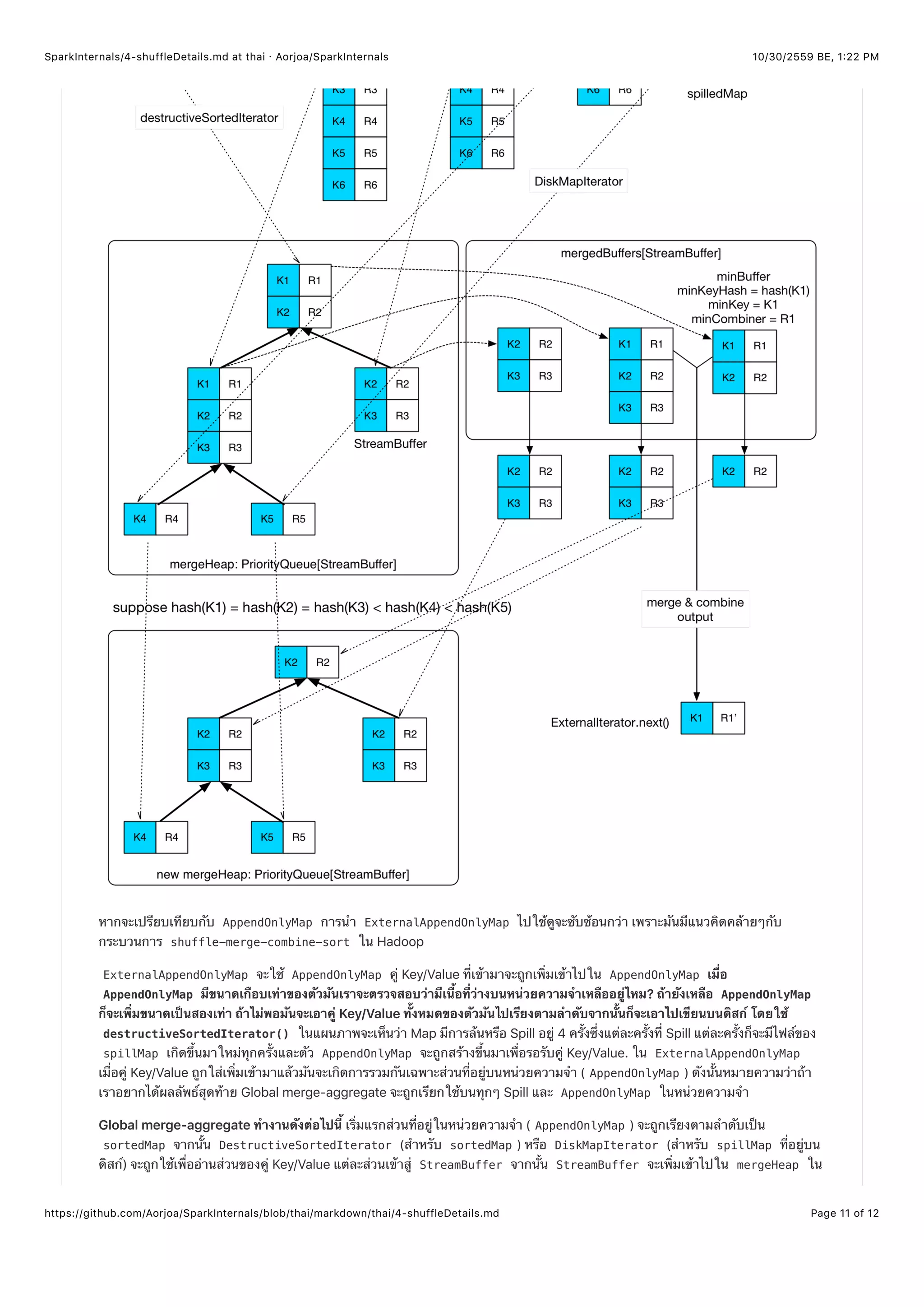
![10/30/2559 BE, 1,22 PMSparkInternals/4-shuffleDetails.md at thai · Aorjoa/SparkInternals
Page 12 of 12https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/4-shuffleDetails.md
แต่ละ StreamBuffer ทุกเรคอร์ดจะมี hash(key) เดียวกัน สมมติว่าในตัวอย่างเรามี hash(K1) == hash(K2) == hash(K3) <
hash(K4) < hash(K5) เราจะเห็นว่ามี 3 เรคอร์ดแรกของ Map ที่ Spill แรกมี hash(key) เดียวกันจึงอ่านเข้าสู่ StreamBuffer ตัว
เดียวกัน ขั้นตอนการรวมกันของมันก็ไม่ยาก: เอา StreamBuffer ที่มีค่า hash(key) จากนั้นก็เก็บเข้าใน
ArrayBuffer[StreamBuffer] ( mergedBuffer ) สำหรับผลการรวม StreamBuffer ตัวแรกที่ถูกเพิ่มเข้าไปเรียกว่า minBuffer
ซึ่ง Key ของมันจะเรียกว่า minKey การรวมหรือ Merge หนึ่งครั้งจะรวบรวมทุกๆคู่ Key/Value ที่มี Key เป็น minKey ใน
mergedBuffer จากนั้นก็ให้ผลลัพธ์ออกมา เมื่อการดำเนินการ Merge ใน mergedBuffer เสร็จแล้วคู่ Key/Value ที่เหลืออยู่จะคืนค่า
กลับไปยัง mergeHeap และทำ StreamBuffer ให้ว่าง จากนั้นจะอ่านเข้ามาแทนใหม่จากในหน่วยความจำหรือ Spill ที่อยู่บนดิสก์
ยังมีอีก 3 ประเด็นที่จะต้องพูดคุยกัน:
การตรวจสอบหน่วยความจำว่าว่างหรือเปล่านั้นใน Hadoop จะกำหนดไว้ที่ 70% ของหน่วยความจำของ Reducer สำหรับ Shuffle-
sort และก็คล้ายๆกันกับใน Spark จะตั้งค่า spark.shuffle.memoryFraction * spark.shuffle.safetyFraction (ค่าเริ่ม
ต้น 0.3 * 0.8) สำหรับ ExternalAppendOnlyMap ซึ่งดูเหมือนว่า Spark สงวนหน่วยความจำเอาไว้ และยิ่งไปกว่านั้นคือ 24% ของ
หน่วยความจำจะถูกใช้งานร่วมกันในทุก Reducer ที่อยู่ใน Executor เดียวกัน ตัว Executor เองก็มีการถือครอง
ShuffleMemoryMap: HashMap[threadId, occupiedMemory] เอาไว้อยู่เพื่อตรวจสอบการใช้งานหน่วยความจำของ
ExternalAppendOnlyMap ในแต่ละ Reducer ก่อนที่ AppendOnlyMap จะขยายขนาดขึ้นจะต้องตรวจสอบดูก่อนว่าขนาดหลังจากที่
ขยายแล้วเป็นเท่าไหร่โดยใช้ข้อมูลจาก ShuffleMemoryrMap ซึ่งต้องมีที่ว่างมากพอถึงจะขยายได้ ดังนั้นโปรดทราบว่า 1000 เรเค
อร์ดแรกมันจะไม่มีการกระตุ้นให้มีการตรวจสอบ Spill
AppendOnlyMap เป็นขนาดโดยประมาณ เพราะถ้าหากเราต้องการทราบค่าที่แน่นอนของ AppendOnlyMap เราก็ต้องคำนวณหา
ขนาดในทุกๆตัวที่มีการอ้างถึงในขณะที่มีการขยายตัวมันไปด้วยแต่มันใช้เวลามาก Spark จึงเลือกใช้วิธีประมาณค่าซึ่งความซับซ้อน
ของขั้นตอนวิธีเป็น O(1) ในความหลักของมันคืออยากรู้ว่าขนาดของ Map เปลี่ยนไปอย่างไรหลังจากการเพิ่มเข้าและรวบรวมกันของเร
คอร์ดจำนวนหนึ่งเพื่อประมาณการขนาดของทั้งโครงสร้าง รายละเอียดอยู่ใน SizeTrackingAppendOnlyMap และ
SizeEstimator
กระบวนการ Spill จำเหมือนกับ Shuffle write คือ Spark จะสร้างบัฟเฟอร์เมื่อมีการ Spill เรเคอร์ดไปยังดิสก์ ขนาดของมันคือค่าที่ตั้ง
ค่าใน spark.shuffle.file.buffer.kb โดยค่าเริ่มต้นคือ 32KB เนื่องจาก Serializer ก็ได้จัดสรรบัฟเฟอร์สำหรับทำ Job ไว้ด้วย
ดังนั้นปัญหาก็จะเกิดขึ้นเมื่อเราลอง Spill เรคอร์ดจำนวนมากมหาศาลในเวลาเดียวกัน ทำให้ Spark จำกัดจำนวนเรคอร์ดที่สามารถ
Spill ได้ในเวลาเดียวกันนี้ในตัวตั้งค่า spark.shuffle.spill.batchSize ซึ่งขนาดเริ่มต้นเป็น 10000 ตัว
การพูดคุย
อย่างที่เราเห็นในบทนี้คือ Spark มีแนวทางจัดการปัญหาที่ยืดหยุ่นมากในกระบวนการ Shuffle เมื่อเทียบกับที่ Hadoop ใช้คือการกำหนด
ตายตัวลงไปเลยว่าต้อง shuffle-combine-merge-reduce ใน Spark เป็นไปได้ที่จะผสมผสานกันระหว่างกลยุทธ์ที่หลากหลายใน
กระบวนการ Shuffle โดยใช้โครงสร้างข้อมูลที่แตกต่างกันไปเพื่อที่จะให้กระบวนการ Shuffle ที่เหมาะสมบนพื้นฐานของการแปลงข้อมูล
ดังนั้นเราจึงได้มีการพูดคุยกันถึงกระบวนการ Shuffle ใน Spark ที่ปราศจากการเรียงลำดับพร้อมกับทำอย่างไรกระบวนการนึ้ถึงจะควบรวม
กับ Chain การประมวลผลของ RDD จริงๆ อีกทั้งเราคุยกันถึงเรื่องเกี่ยวกับปัญหาของหน่วยความจำและดิสก์ รวมถึงเปรียบเทียบในบางแง่
มุมกับ Hadoop ในบทถัดไปเราจะอธิบายถึงกระบวนการการที่ Job ถูกประมวลผลจากแง่มุมของการสื่อสารกันระหว่างโปรเซส Inter-
process communication. ปัญหาของตำแหน่งข้อมูลก็ได้กล่าวถึงในบทนี้ด้วยเช่นกัน
เพิ่มเติมในบทนี้คือมีบล๊อคที่น่าสนใจมากๆ (เขียนในภาษาจีน) โดย Jerry Shao, Deep Dive into Spark's shuffle implementation.
Contact GitHub API Training Shop Blog About© 2016 GitHub, Inc. Terms Privacy Security Status Help](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-50-2048.jpg)

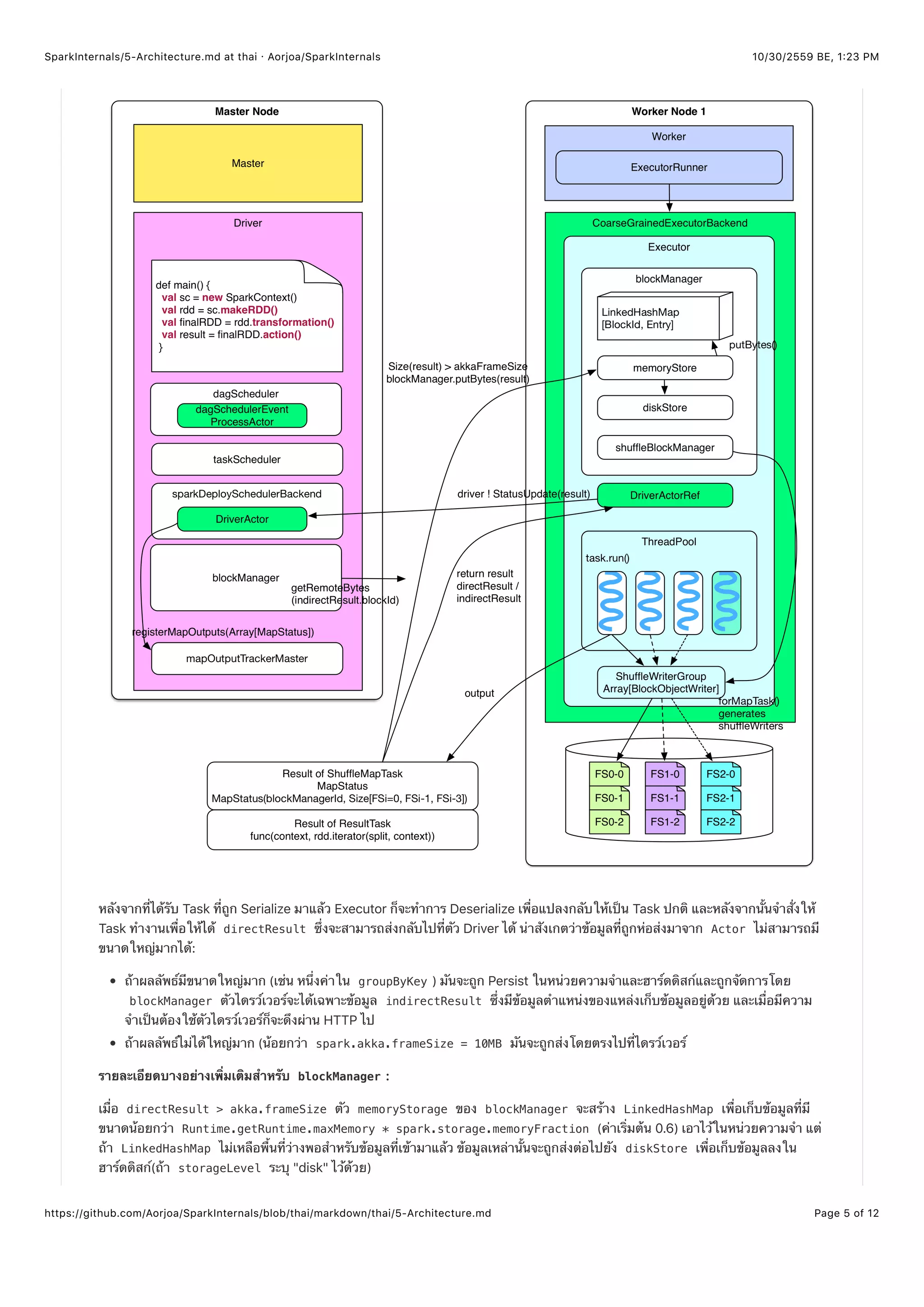
![10/30/2559 BE, 1,23 PMSparkInternals/5-Architecture.md at thai · Aorjoa/SparkInternals
Page 6 of 12https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/5-Architecture.md
In TaskRunner.run()
// deserialize task, run it and then send the result to
=> coarseGrainedExecutorBackend.statusUpdate()
=> task = ser.deserialize(serializedTask)
=> value = task.run(taskId)
=> directResult = new DirectTaskResult(ser.serialize(value))
=> if( directResult.size() > akkaFrameSize() )
indirectResult = blockManager.putBytes(taskId, directResult, MEMORY+DISK+SER)
else
return directResult
=> coarseGrainedExecutorBackend.statusUpdate(result)
=> driver ! StatusUpdate(executorId, taskId, result)
ผลลัพธ์ที่ได้มาจากการทำงานของ ShuffleMapTask และ ResultTask นั้นแตกต่างกัน
ShuffleMapTask จะสร้าง MapStatus ซึ่งประกอบไปด้ว 2 ส่วนคือ:
BlockManagerId ของ BlockManager ของ Task: (executorId + host, port, nettyPort
ขนาดของแต่ละเอาท์พุทของ Task ( FileSegment )
ResultTask จะสร้างผลลัพธ์ของการประมวลผลโดยการเจาะจงฟังก์ชันในแต่ละพาร์ทิชัน เช่น ฟังก์ชันของ count() เป็นฟังก์ชัน
ง่ายๆเพื่อนับค่าจำนวนของเรคอร์ดในพาร์ทิชันหนึ่งๆ เนื่องจากว่า ShuffleMapTask ต้องการใช้ FileSegment สำหรับเขียนข้อมูล
ลงดิสก์ แลเยมีความต้องการใช้ OutputStream ซึ่งเป็นตัวเขียนข้อมูลออก ตัวเขียนข้อมูลเหล่านี้ถูกสร้างและจัดการโดย
blockManager ของ shuffleBlockManager
In task.run(taskId)
// if the task is ShuffleMapTask
=> shuffleMapTask.runTask(context)
=> shuffleWriterGroup = shuffleBlockManager.forMapTask(shuffleId, partitionId, numOutputSplits)
=> shuffleWriterGroup.writers(bucketId).write(rdd.iterator(split, context))
=> return MapStatus(blockManager.blockManagerId, Array[compressedSize(fileSegment)])
//If the task is ResultTask
=> return func(context, rdd.iterator(split, context))
ซีรีย์ของการดำเนินการข้างบนจะทำงานหลังจากที่ไดรว์เวอร์ได้รับผลลัพธของ Task มาแล้ว
TaskScheduler จะได้รับแจ้งว่า Task นั้นเสร็จเรียบร้อยแล้วผลลัพธ์ของมันจะถูกประมวลผล:
ถ้ามันเป็น indirectResult , BlockManager.getRemotedBytes() จะถูกร้องขอเพื่อดึงข้อมูลจากผลลัพธ์จริงๆ
ถ้ามันเป็น ResultTask , ResultHandler() จะร้องขอฝั่งไดรว์เวอร์ให้เกิดการคำนวณบนผลลัพธ์ (เช่น count() จะใช้ sum
ดำเนินการกับทุกๆ ResultTask )
ถ้ามันเป็น MapStatus ของ ShuffleMapTask แล้ว MapStatus จำสามารถเพิ่มเข้าใน MapStatuses ของ
MapOutputTrackerMaster ซึ่งทำให้ง่ายกว่าในการเรียกข้อมูลในขณะที่ Reduce shuffle
ถ้า Task ที่รับมาบนไดรว์เวอร์เป็น Task สุดท้ายของ Stage แล้ว Stage ต่อไปจะถูกส่งไปทำงาน แต่ถ้า Stage นั้นเป็น Stage สุดท้าย
แล้ว dagScheduler จะแจ้งว่า Job ประมวลผลเสร็จแล้ว
After driver receives StatusUpdate(result)
=> taskScheduler.statusUpdate(taskId, state, result.value)
=> taskResultGetter.enqueueSuccessfulTask(taskSet, tid, result)
=> if result is IndirectResult
serializedTaskResult = blockManager.getRemoteBytes(IndirectResult.blockId)
=> scheduler.handleSuccessfulTask(taskSetManager, tid, result)
=> taskSetManager.handleSuccessfulTask(tid, taskResult)
=> dagScheduler.taskEnded(result.value, result.accumUpdates)
=> dagSchedulerEventProcessActor ! CompletionEvent(result, accumUpdates)
=> dagScheduler.handleTaskCompletion(completion)
=> Accumulators.add(event.accumUpdates)
// If the finished task is ResultTask](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-56-2048.jpg)
![10/30/2559 BE, 1,23 PMSparkInternals/5-Architecture.md at thai · Aorjoa/SparkInternals
Page 7 of 12https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/5-Architecture.md
=> if (job.numFinished == job.numPartitions)
listenerBus.post(SparkListenerJobEnd(job.jobId, JobSucceeded))
=> job.listener.taskSucceeded(outputId, result)
=> jobWaiter.taskSucceeded(index, result)
=> resultHandler(index, result)
// If the finished task is ShuffleMapTask
=> stage.addOutputLoc(smt.partitionId, status)
=> if (all tasks in current stage have finished)
mapOutputTrackerMaster.registerMapOutputs(shuffleId, Array[MapStatus])
mapStatuses.put(shuffleId, Array[MapStatus]() ++ statuses)
=> submitStage(stage)
Shuffle read
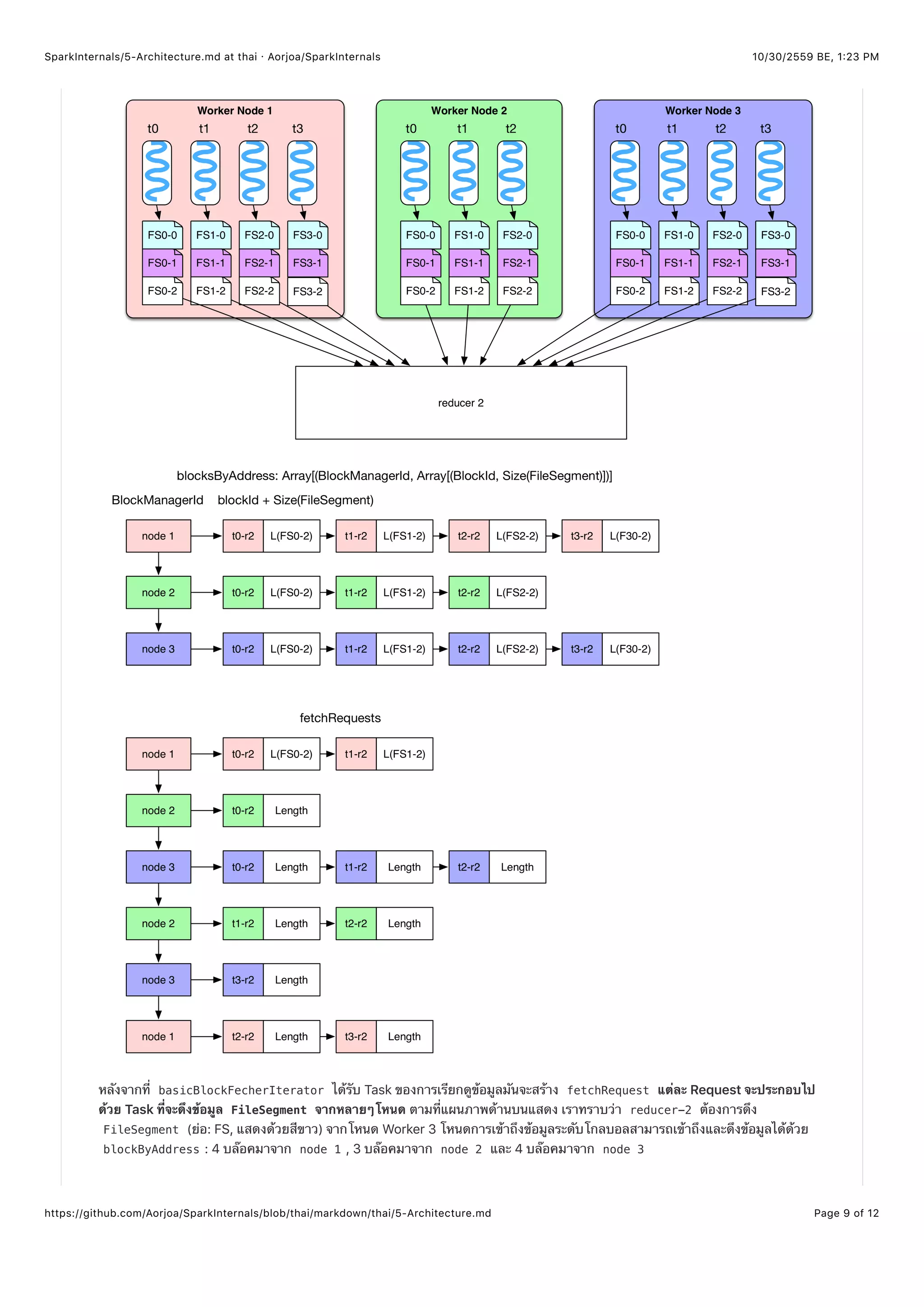
ในย่อหน้าก่อนหน้านี้เราได้คุยกันถึงการทำ Task ว่าถูกประมวลผลและมีกระบวนการที่จะได้ผลลัพธ์มาอย่างไร ในตอนนี้เราจะคุยกันเรื่องว่า
ทำอย่างไร Reducer (Task ที่ต้องการ Shuffle) จึงจะได้รับข้อมูลอินพุท ส่วนของ Shuffle read ในท้ายบทนี้ก็ได้มีการคุยถึงกระบวนการของ
Reducer ที่ทำกับข้อมูลอินพุทมาบ้างแล้ว
ทำอย่างไร Reducer ถึงจะรู้ว่าข้อมูลที่ต้องไปดึงอยู่ตรงไหน?
Reducer ต้องการทราบว่าโหนดในที่ FileSegment ถูกสร้างโดย ShuffleMapTask ของ Stage พ่อแม่ ประเภทของข้อมูลที่จะส่งไป
ไดรว์เวอร์คือ mapOutputTrackerMaster เมื่อ ShuffleMapTasl ทำงานเสร็จข้อมูลจะถูกเก็บใน mapStatuses:
HashMp[stageId,Array[MapStatus]] หากให้ stageId เราก็จะได้ Array[MapStatus] ออกมาซึ่งในนั้นมีข้อมูลที่เกี่ยวกับ
FileSegment ทีี่สร้างจาก ShuffleMapTask บรรจุอยู่ Array(taskId) จะมีข้อมูลตำแหน่ง ( blockManagerId ) และขนาดของ
แต่ละ FileSegment เก็บอยู่
เมื่อ Reducer ต้องการดึงข้อมูลอินพุท มันจะเริ่มจากการร้องขอ blockStoreShuffleFetcher เพื่อขอข้อมูลตำแหน่งของ](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-57-2048.jpg)
![10/30/2559 BE, 1,23 PMSparkInternals/5-Architecture.md at thai · Aorjoa/SparkInternals
Page 8 of 12https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/5-Architecture.md
FileSegment ต่อมา blockStoreShuffleFetcher จะเรียก MapOutputTrackerWorker บนโหนด Worker เพื่อทำงาน ตัว
MapOutputTrackerWorker ใช้ mapOutputTrackerMasterActorRef เพื่อสื่อสารกับ mapOutputTrackerMasterActor ตาม
ลำดับเพื่อรับ MapStatus กระบวนการ blockStoreShuffleFetcher จะประมวลผล MapStatus แล้วจะพบว่าที่ Reducer ต้องไปดึง
ข้อมูลของ FileSegment จากนั้นจะเก็บข้อมูลนี้ไว้ใน blocksByAddress . blockStoreShuffleFetcher จะเป็นตัวบอกให้
basicBlockFetcherIterator เป็นตัวดึงข้อมูล FileSegment
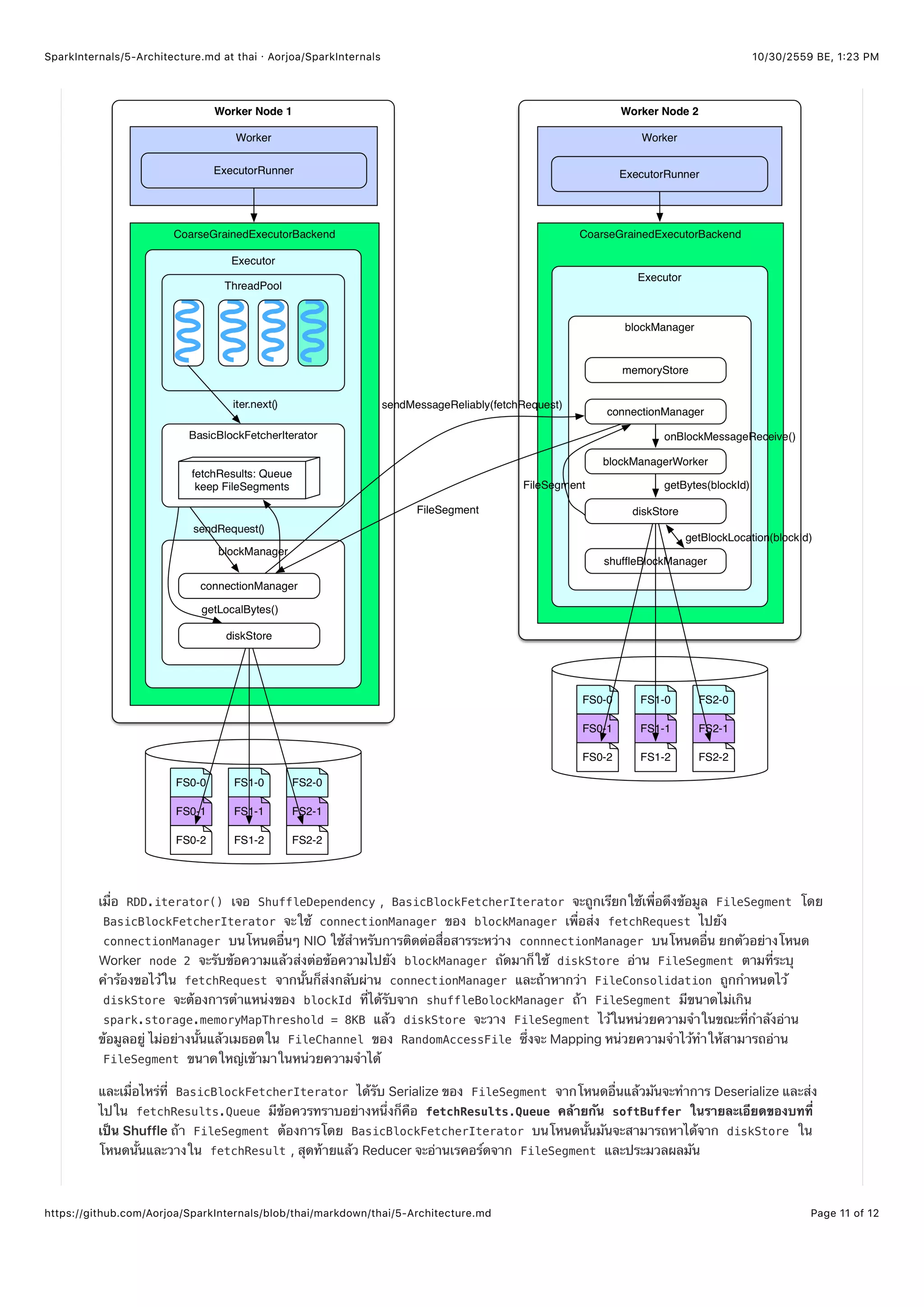
rdd.iterator()
=> rdd(e.g., ShuffledRDD/CoGroupedRDD).compute()
=> SparkEnv.get.shuffleFetcher.fetch(shuffledId, split.index, context, ser)
=> blockStoreShuffleFetcher.fetch(shuffleId, reduceId, context, serializer)
=> statuses = MapOutputTrackerWorker.getServerStatuses(shuffleId, reduceId)
=> blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = compute(statuses)
=> basicBlockFetcherIterator = blockManager.getMultiple(blocksByAddress, serializer)
=> itr = basicBlockFetcherIterator.flatMap(unpackBlock)](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-58-2048.jpg)


![10/30/2559 BE, 1,24 PMSparkInternals/6-CacheAndCheckpoint.md at thai · Aorjoa/SparkInternals
Page 4 of 9https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/6-CacheAndCheckpoint.md
แผนภาพด้านดนสามารถแสดงได้ในโค้ดนี้:
rdd.iterator()
=> SparkEnv.get.cacheManager.getOrCompute(thisRDD, split, context, storageLevel)
=> key = RDDBlockId(rdd.id, split.index)
=> blockManager.get(key)
=> computedValues = rdd.computeOrReadCheckpoint(split, context)
if (isCheckpointed) firstParent[T].iterator(split, context)
else compute(split, context)
=> elements = new ArrayBuffer[Any]
=> elements ++= computedValues
=> updatedBlocks = blockManager.put(key, elements, tellMaster = true)
เมื่อ rdd.iterator() ถูกเรียกใช้เพื่อประมวลผลในบางพาร์ทิชันของ rdd แล้ว blockId จะถูกใช้เพื่อกำหนดว่าพาร์ทิชันไหนจะถูก
แคช เมื่อ blockId มีชนิดเป็น RDDBlockId ซึ่งจะแตกต่างกับชนิดของข้อมูลอื่นที่อยู่ใน memoryStore เช่น result ของ Task จาก
นั้นพาร์ทิชันใน blockManager จะถูกเช็คว่ามีการ Checkpoint แล้ว ถ้าเป็นเช่นนั้นแล้วเราก็จะสามารถพูดได้ว่า Task ถูกทำงานเรียบร้อย
แล้วไม่ได้ต้องการทำการประมวลผลบนพาร์ทิชันนี้อีก elements ที่มีชนิด ArrayBuffer จะหยิบทุกเรคอร์ดของพาร์ทิชันมาจาก
Checkpoint ถ้าไม่เป็นเช่นนั้นแล้วาร์ทิชันจะถูกประมวลผลก่อน แล้วทุกเรคอร์ดของมันจะถูกเก็บลงใน elements สุดท้ายแล้ว elements](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-66-2048.jpg)
![10/30/2559 BE, 1,24 PMSparkInternals/6-CacheAndCheckpoint.md at thai · Aorjoa/SparkInternals
Page 5 of 9https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/6-CacheAndCheckpoint.md
จะถูกส่งไปให้ blockManager เพื่อทำการแคช
blockManager จะเก็บ elements (partition) ลงใน LinkedHashMap[BlockId, Entry] ที่อยู่ใน memoryStore ถ้าขนาดของ
พาร์ทิชันใหญ่กว่าขนาดของ memoryStore จะจุได้ (60% ของขนาด Heap) จะคืนค่าว่าไม่สามารถที่จะถือข้อมูลนี้ไว้ได้ ถ้าขนาดไม่เกินมัน
จะทิ้งบางพาร์ทิชันของ RDD ที่เคยแคชไว้แล้วเพื่อที่จะทำให้มีที่ว่างพอสำหรับพาร์ทิชันใหม่ที่จะเข้ามา และถ้าพื้นที่มีมากพอพาร์ทิชันที่เข้ามา
ใหม่จะถูกเก็บลลงใน LinkedHashMap แต่ถ้ายังไม่พออีกระบบจะส่งกลับไปบอกว่าพื้นที่ว่างไม่พออีกครั้ง ข้อควรรู้สำหรับพาร์ทิชันเดิมที่ขึ้น
กับ RDD ของพาร์ทิชันใหม่จะไม่ถูกทิ้ง ในอุดมคติแล้ว "first cached, first dropped"
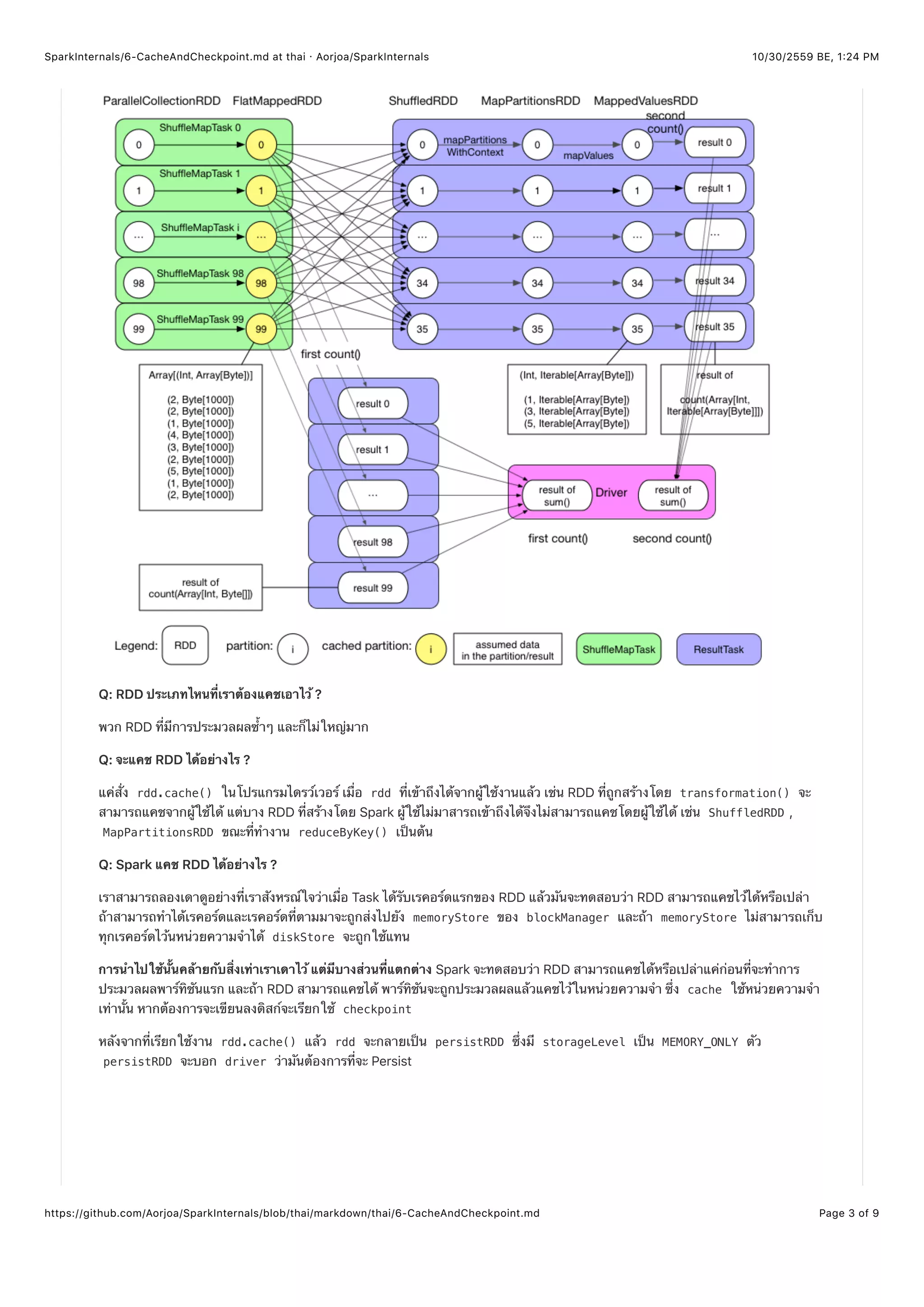
Q: จะอ่าน RDD ที่แคชไว้ยังไง ?
เมื่อ RDD ที่ถูกแคชไว้แล้วต้องการที่จะประมวลผลใหม่อีกรอบ (ใน Job ถัดไป), Task จะอ่าน blockManager โดยตรงจาก
memoryStore , เฉพาะตอนที่อยู่ระหว่างการประมวลผลของบางพาร์ทิชันของ RDD (โดยการเรียก rdd.iterator() ) blockManager
จะถูกเรียกถามว่ามีแคชของพาร์ทิชันหรือยัง ถ้ามีแล้วและอยู่ในโหนดโลคอลของมันเอง blockManager.getLocal() จะถูกเรียกเพื่ออ่าน
ข้อมูลจาก memoryStore แต่ถ้าพาร์ทิชันถูกแคชบนโหนดอื่น blockManager.getRemote() จะถูกเรียก ดังแสดงด้านล่าง:](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-67-2048.jpg)
![10/30/2559 BE, 1,24 PMSparkInternals/6-CacheAndCheckpoint.md at thai · Aorjoa/SparkInternals
Page 7 of 9https://github.com/Aorjoa/SparkInternals/blob/thai/markdown/thai/6-CacheAndCheckpoint.md
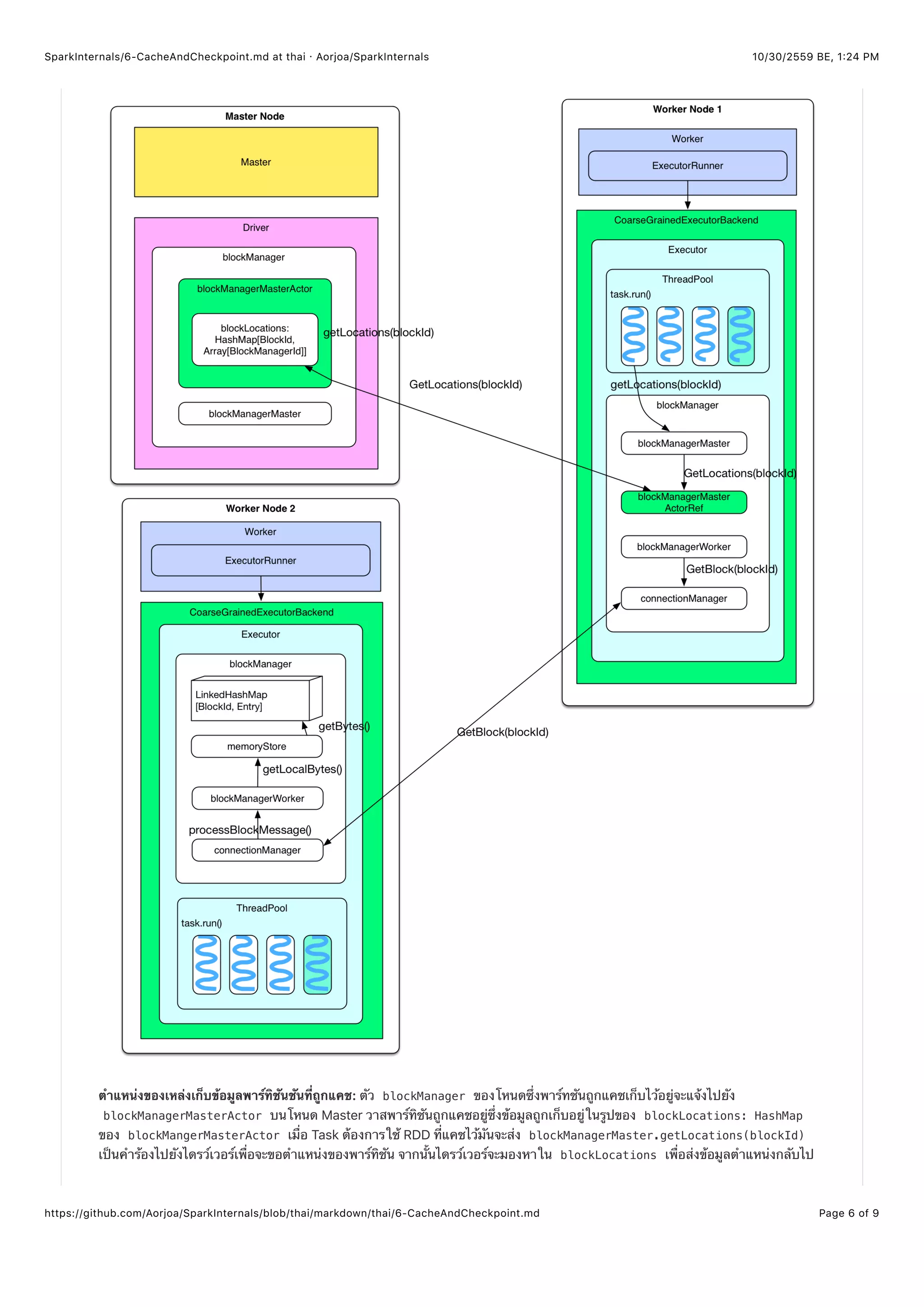
การพาร์ทิชันที่ถูกแคชไว้บนโหนดอื่น: เมื่อ Task ได้รัยข้อมูลตำแหน่งของพาร์ทิชันที่ถูกแคชไว้แล้วว่าอยู่ตำแหน่งใดจากนั้นจะส่ง
getBlock(blockId) เพื่อร้องขอไปยังโหนดปลายทางผ่าน connectionManager โหนดปลายทางก็จะรับและส่งกลับพาร์ทิชันที่ถูกแคช
ไว้แล้วจาก memoryStore ของ blockManager บนตัวมันเอง
Checkpoint
Q: RDD ประเภทไหนที่ต้องการใช้ Checkpoint ?
การประมวลผล Task ใช้เวลานาน
Chain ของการประมวลผลเป็นสายยาว
ขึ้นต่อหลาย RDD
ในความเป็นจริงแล้วการบันทึกข้อมูลเอาท์พุทจาก ShuffleMapTask บนโหนดโลคอลก็เป็นการ checkpoint แต่นั่นเป็นการใช้สำหรับ
ข้อมูลที่เป็นข้อมูลเอาท์พุทของพาร์ทิชัน
Q: เมื่อไหร่ที่จะ Checkpoint ?
อย่างที่ได้พูดถึงข้างบนว่าทุกครั้งที่พาร์ทิชันที่ถูกประมวลผลแล้วต้องการที่จะแคชมันจะแคชลงไปในหน่วยความจำ แต่สำหรับ
checkpoint() มันไม่ได้เป็นอย่างนั้น เพราะ Checkpoint ใช้วิธีรอจนกระทั่ง Job นั้นทำงานเสร็จก่อนถึงจะสร้าง Job ใหม่เพื่อมา
Checkpoint RDD ที่ต้องการ Checkpoint จะมีการประมวลผลของงานใหม่อีกครั้ง ดังนั้นจึงแนะนำให้สั่ง rdd.cache() เพื่อแคชข้อมูล
เอาไว้ก่อนที่จะสั่ง rdd.checkpoint() ในกรณีนี้งานที่ Job ที่สองจะไม่ประมวลผลซ้ำแต่จะหยิบจากที่เคยแคชไว้มาใช้ ซึ่งในความจริง
Spark มีเมธอต rdd.persist(StorageLevel.DISK_ONLY) ให้ใช้เป็นลักษณะของการแคชลงไปบนดิสก์ (แทนหน่วยความจำ) แต่ชนิด
ของ persist() และ checkpoint() มีความแตกต่างกัน เราจะคุยเรื่องนี้กันทีหลัง
Q: นำ Checkpoint ไปใช้ได้อย่างไร ?
นี่คือขั้นตอนการนำไปใช้
RDD จะเป็น: [ เริ่มกำหนดค่า --> ทำเครื่องหมายว่าจะ Checkpoint --> ทำการ Checkpoint --> Checkpoint เสร็จ ]. ในขั้นตอนสุดท้าย
RDD ก็จะถูก Checkpoint แล้ว
เริ่มกำหนดค่า
ในฝั่งของไดรว์เวอร์หลังจากที่ rdd.checkpoint() ถูกเรียกแล้ว RDD จะถูกจัดการโดย RDDCheckpointData ผู้ใช้สามารถตั้งค่าแหล่ง
เก็บข้อมูลชี้ไปที่ตำแหน่งที่ต้องให้เก็บไว้ได้ เช่น บน HDFS
ทำเครื่องหมายว่าจะ Checkpoint
หลังจากที่เริ่มกำหนดค่า RDDCheckpointData จะทำเครื่องหมาย RDD เป็น MarkedForCheckpoint
ทำการ Checkpoint
เมื่อ Job ประมวลผลเสร็จแล้ว finalRdd.doCheckpoint() จะถูกเรียกใช้ finalRdd จำสแกน Chain ของการประมวลผลย้อนกลับไป
และเมื่อพบ RDD ที่ต้องการ Checkpoint แล้ว RDD จะถูกทำเครื่องหมาย CheckpointingInProgress จากนั้นจะตั้งค่าไฟล์ (สำหรับ
เขียนไปยัง HDFS) เช่น core-site.xml จะถูก Broadcast ไปยัง blockManager ของโหนด Worker อื่นๆ จากนั้น Job จะถูกเรียกเพื่อทำ
Checkpoint ให้สำเร็จ
rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf))
Checkpoint เสร็จ
หลังจากที่ Job ทำงาน Checkpoint เสร็จแล้วมันจะลบความขึ้นต่อกันของ RDD และตั้งค่า RDD ไปยัง Checkpoint จากนั้น เพื่มการขึ้นต่อ
กันเสริมเข้าไปและตั้งค่าให้ RDD พ่อแม่มันเป็น CheckpointRDD ตัว CheckpointRDD จะถูกใช้ในอนาคตเพื่อที่จะอ่านไฟล์ Checkpoint
บนระบบไฟล์แล้วสร้างพาร์ทิชันของ RDD
อะไรคือสิ่งที่น่าสนใจ:
RDD สองตัวถูก Checkpoint บนโปรแกรมไดรว์เวอร์ แต่มีแค่ result (ในโค้ดด่านล่าง) เท่านั้นที่ Checkpoint ได้สำเร็จ ไม่แน่ใจว่าเป็น
Bug หรือเพราะว่า RDD มันตามน้ำหรือจงใจให้เกิด Checkpoint กันแน่](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-69-2048.jpg)
, (2, 'b'), (3, 'c'),
(4, 'd'), (5, 'e'), (3, 'f'), (2, 'g'), (1, 'h'))
val pairs1 = sc.parallelize(data1, 3)
val data2 = Array[(Int, Char)]((1, 'A'), (2, 'B'), (3, 'C'), (4, 'D'))
val pairs2 = sc.parallelize(data2, 2)
pairs2.checkpoint
val result = pairs1.join(pairs2)
result.checkpoint
Q: จะอ่าน RDD ที่ถูก Checkpoint ไว้อย่างไร ?
runJob() จะเรียกใช้ finalRDD.partitions() เพื่อกำหนดว่าจะมี Task เกิดขึ้นเท่าไหร่. rdd.partitions() จะตรวจสอบว่าถ้า
RDD ถูก Checkpoint ผ่าน RDDCheckpointData ซึ่งจัดการ RDD ที่ถูก Checkpoint แล้ว, ถ้าใช่จะคืนค่าพาร์ทิชันของ RDD
( Array[Partition] ). เมื่อ rdd.iterator() ถูกเรียกใช้เพื่อประมวลผลพาร์ทิชันของ RDD, computeOrReadCheckpoint(split:
Partition) ก็จะถูกเรียกด้วยเพื่อตรวจสอบว่า RDD ถูก Checkpoint แล้ว ถ้าใช่ iterator() ของ RDD พ่อแม่จะถูกเรียก (รูจักกันใน
ชื่อ CheckpointRDD.iterator() จะถูกเรียก) CheckpointRdd จะอ่านไฟล์บนระบบไฟล์เพื่อที่จะสร้างพาร์ทิชันของ RDD นั่นเป็นเคล็ด
ลับที่ว่าทำไม CheckpointRDD พ่อแม่จึงถูกเพิ่มเข้าไปใน RDD ที่ถูก Checkpoint ไว้แล้ว
Q: ข้อแตกต่างระหว่าง cache และ checkpoint ?
นี่คือคำตอบที่มาจาก Tathagata Das:
มันมีความแตกต่างกันอย่างมากระหว่าง cache และ checkpoint เนื่องจากแคชนั้นจะสร้าง RDD และเก็บไว้ในหน่วยความจำ (และ/หรือ
ดิสก์) แต่ Lineage (Chain ของการกระมวลผล) ของ RDD (มันคือลำดับของการดำเนินการบน RDD) จะถูกจำไว้ ดังนั้นถ้าโหนดล้มเหลวไป
และทำให้บางส่วนของแคชหายไปมันสามารถที่จะคำนวณใหม่ได้ แต่อย่างไรก็ดี Checkpoint จะบันทึกข้อมูลของ RDD ลงเป็นไฟล์ใน
HDFS และจะลืม Lineage อย่างสมบูรณ์ ซึ่งอนุญาตให้ Lineage ซึ่งมีสายยาวถูกตัดและข้อมูลจะถูกบันทึกไว้ใน HDFS ซึ่งมีกลไกการทำ
สำเนาข้อมูลเพื่อป้องกันการล้มเหลวตามธรรมชาติของมันอยู่แล้ว
นอกจากนี้ rdd.persist(StorageLevel.DISK_ONLY) ก็มีความแตกต่างจาก Checkpoint ลองนึกถึงว่าในอดีตเราเคย Persist พาร์ทิชั
นของ RDD ไปยังดิสก์แต่ว่าพาร์ทิชันของมันถูกจัดการโดย blockManager ซึ่งเมื่อโปรแกรมไดรว์เวอร์ทำงานเสร็จแล้ว มันหมายความว่า
CoarseGrainedExecutorBackend ก็จะหยุดการทำงาน blockManager ก็จะหยุดตามไปด้วย ทำให้ RDD ที่แคชไว้บนดิสก์ถูกทิ้งไป
(ไฟล์ที่ถูกใช้โดย blockManager จะถูกลบทิ้ง) แต่ Checkpoint สามารถ Persist RDD ไว้บน HDFS หรือโลคอลไดเรกทอรี่ ถ้าหากเราไม่
ลบมือเองมันก็จะอยู่ไปในที่เก็บแบบนั้นไปเรื่อยๆ ซึ่งสามารถเรียกใช้โดยโปรแกรมไดรว์เวอร์อื่นถัดไปได้
การพูดคุย
เมื่อครั้งที่ Hadoop MapReduce ประมวลผล Job มันจะ Persist ข้อมูล (เขียนลงไปใน HDFS) ตอนท้ายของการประมวลผล Task ทุกๆ
Task และทุกๆ Job เมื่อมีการประมวลผล Task จะสลับไปมาระหว่างหน่วยความจำและดิสก์. ปัญหาของ Hadoop ก็คือ Task ต้องการที่จำ
ประมวลผลใหม่เมื่อมี Error เกิดขึ้น เช่น Shuffle ที่หยุดเมื่อ Error จะทำให้ข้อมูลที่ถูก Persist ลงบนดิสก์มีแค่ครึ่งเดียวทำให้เมื่อมีการ
Shuffle ใหม่ก็ต้อง Persist ข้อมูลใหม่อีกครั้ง ซึ่ง Spark ได้เรียบในข้อนี้เนื่องจากหากเกิดการผิดพลาดขึ้นจะมีการอ่านข้อมูลจาก
Checkpoint แต่ก็มีข้อเสียคือ Checkpoint ต้องการการประมวลผล Job ถึงสองครั้ง
Example
package internals
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object groupByKeyTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("GroupByKey").setMaster("local")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/Users/xulijie/Documents/data/checkpoint")](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-70-2048.jpg)
, (2, 'b'),
(3, 'c'), (4, 'd'),
(5, 'e'), (3, 'f'),
(2, 'g'), (1, 'h')
)
val pairs = sc.parallelize(data, 3)
pairs.checkpoint
pairs.count
val result = pairs.groupByKey(2)
result.foreachWith(i => i)((x, i) => println("[PartitionIndex " + i + "] " + x))
println(result.toDebugString)
}
}
Contact GitHub API Training Shop Blog About© 2016 GitHub, Inc. Terms Privacy Security Status Help](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-71-2048.jpg)

 จะถูกจัดสรรบนโลคอลโหนดเพื่อใช้
เก็บข้อมูลที่ถูกดึงมา แล้ว TorrentBlock จะห่อบล๊อคข้อมูลไว้. ลำดับของการดึงข้อมูลนั้นจะเป็นแบบสุ่ม ยกตัวอย่าง เช่น ถ้ามี 5 บล๊อคมัน
อาจจะเป็น 3-1-2-4-5 ก็ได้ แล้วจากนั้น Executor จะเริ่มดึงบล๊อคข้อมูลทีละตัว: blockManager บนโลคอล => connectionManager
บนโลคอล => cutor ของเครื่องอื่น => ข้อมูล. การดึงบล๊อคข้อมูลแต่ละครั้งจะถูกเก็บใว้ใต้ Block manager และ blockManagerMaster
ของไดรว์เวอร์จะแจ้งว่าบล๊อคข้อมูลถูกดึงสำเร็จแล้ว อย่างที่คิดไว้เลยก็คือขั้นตอนนี้เป็นขั้นตอนที่สำคัญเพราะว่าในตอนนี้ทุกๆโหนดใน
คลัสเตอร์จะรู้ว่ามีแหล่งข้อมูลที่ใหม่สำหรับบล๊อคข้อมูล ถ้าโหนดอื่นต้องการดึงบล๊อคข้อมูลเดียวกันนี้มันจะสุ่มว่าจะเลือกดึงจากที่ไหน ถ้า
บล๊อคข้อมูลที่จะถูกดึงมีจำนวนมากการกระจายด้วยวิธีนี้จะช่วยให้กลไกการ Broadcast เร็วขึ้น ถ้าจะให้เห็นภาพมากขึ้นลองอ่านเรื่อง
BitTorrent บน wikipedia.
เมื่อบล๊อคข้อมูลทุกบล๊อคถูกดึงมาไว้ที่โหนดโลคอลแล้ว Array[Byte] ที่มีขนาดใหญ่จะถูกจัดสรรเพื่อสร้างข้อมูลที่ Broadcast มาขึ้นมา
ใหม่จากบล๊อคข้อมูลย่อยๆถูกถูกดึงมา สุดท้ายแล้ว Array นี้ก็จะถูก Deserialize และเก็บอยู่ภายใต้ Block manager ของโหนดโลคอล
โปรดทราบว่าเมืื่อเรามีตัวแปร Broadcast ใน Block manager บนโหนดโลคอลแล้วเราสามารถลบบล๊อคของข้อมูลที่ถูกดึงมาได้อย่าง
ปลอดภัย (ซึ่งก็ถูกเก็บอยู่ใน Block manager บนโหนดโลคอลเช่นเดียวกัน)
คำถามอักอย่างหนึ่งก็คือ: แล้วเกี่ยวกับการ Broadcast RDD หล่ะ? จริงๆแล้วไม่มีอะไรแย่ๆเกิดขึ้นหรอก RDD จะถูกทราบค่าในแต่ละ
Executor ดังนั้นแต่ละโหนดจะมีสำเนาผลลัพธ์ของมันเอง
การพูดคุย
การใช้ตัวแปร Broadcast แบ่งกันข้อมูลเป็นคุณสมบัติที่มีประโยชน์ ใน Hadoop เราจะมี DistributedCache ซึ่งถูกใช้งานในหลายๆ
สถานการณ์ เช่น พารามิเตอร์ของ -libjars จะถูกส่งไปยังทุกโหนดโดยการใช้ DistributedCache อย่างไรก็ดี Hadoop จะ
Broadcast ข้อมูลโดยการอัพโหลดไปยัง HDFS ก่อนและไม่มีกลไกในการแบ่งปันข้อมูลระหว่าง Task ในโหนดเดียวกัน ถ้าบางโหนด
ต้องการประมวลผลโดยใช้ 4 Mapper ใน Job เดียวกันแล้วตัวแปร Broadcast จำต้องถูกเก็บ 4 ครั้งในโหนดนั้น (หนึ่งสำเนาต่อไดเรกทอรี
ที่ Mapper ทำงาน) ข้อดีของวิธีการนี้คือไม่เกิดคอขวดของระบบเนื่องจาก HDFS นั้นมีการตัดส่วนของข้อมูลออกเป็นบล๊อคและกระจายตัวทั่ว
ทั้งตลัสเตอร์อยู่แล้ว
สำรับ Spark นั้น Broadcast จะใส่ใจเกี่ยวกับการส่งข้อมูลไปทุกโหนดและปล่อยให้ Task ในโหนดเดียวกันนั้นมีการแบ่งปันข้อมูลกัน ใน
Spark มี Blog manager ที่จะช่วยแก้ไขปัญหาเรื่องการแบ่งปันข้อมูลระว่าง Task ในโหนดเดียวกัน การเก็บข้อมูลไว้ใน Block manager บน
โหนดโลคอลโดยการใช้ระดับการเก็บข้อมูลแบบหน่วยความจำ + ดิสก์ จะรับร้องได้ว่าทุก Task บนโหนดสามารถที่จะเข้าถึงหน่วยความจำที่
แบ่งปันกันนี้ได้ ซึ่งการทำแบบนี้สามารถช่วยเลี่ยงการเก็บข้อมูลที่มีความซ้ำซ้อน Spark มีการดำเนินการ Broadcast อยู่ 2 วิธีก็คือ
HttpBroadcast ซึ่งมีคอขวดอยู่กับโหนดไดรว์เวอร์ และ TorrentBroadcast ซึ่งเป็นการแก้ปัญหาโดยใช้วิธีการของ BitTorrent ที่จะ
ช้าในตอนแรกแต่เมื่อได้มัการดึงข้อมูลไปกระจายตาม Executor ตัวอื่นๆแล้วก็จะเร็วขึ้นและกระบวนการสร้างใหม่ของข้อมูลจากบล๊อคข้อมูล
ต้องการพื้นที่บนหน่วยความจำเพิ่มมากขึ้น
จริงๆแล้ว Spark มีการทดลองใช้ทางเลือกอื่นคือ TreeBroadcast ในรายละเอียดเชิงเทคนิคดูได้ที่: Performance and Scalability of
Broadcast in Spark.
ในความคิดเห็นของผู้เขียนคุณสมบัติ Broadcast นี้สามารถดำเนินการโดยใช้โปรโตคอลแบบ Multicast ได้ แต่เนื่องจาก Multicast มา
จากพื้นฐานของ UDP ดังนั้นเราจึงต้องการกลไกที่มีความน่าเชื่อถือในระดับแอพพลิเคชันเลเยอร์](https://image.slidesharecdn.com/sparkinternalsbook-161030145725/75/Spark-Internal-74-2048.jpg)













































![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)