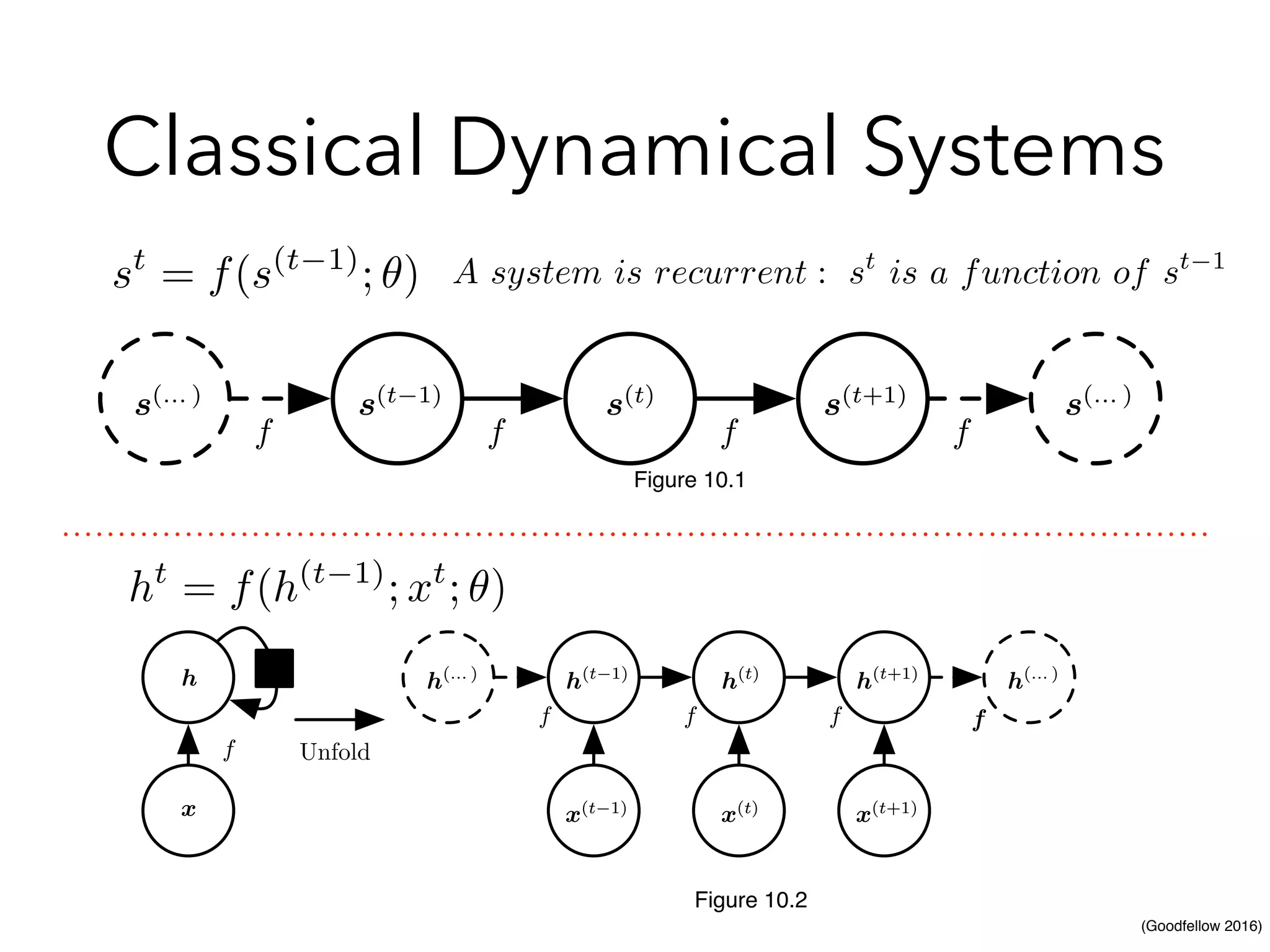
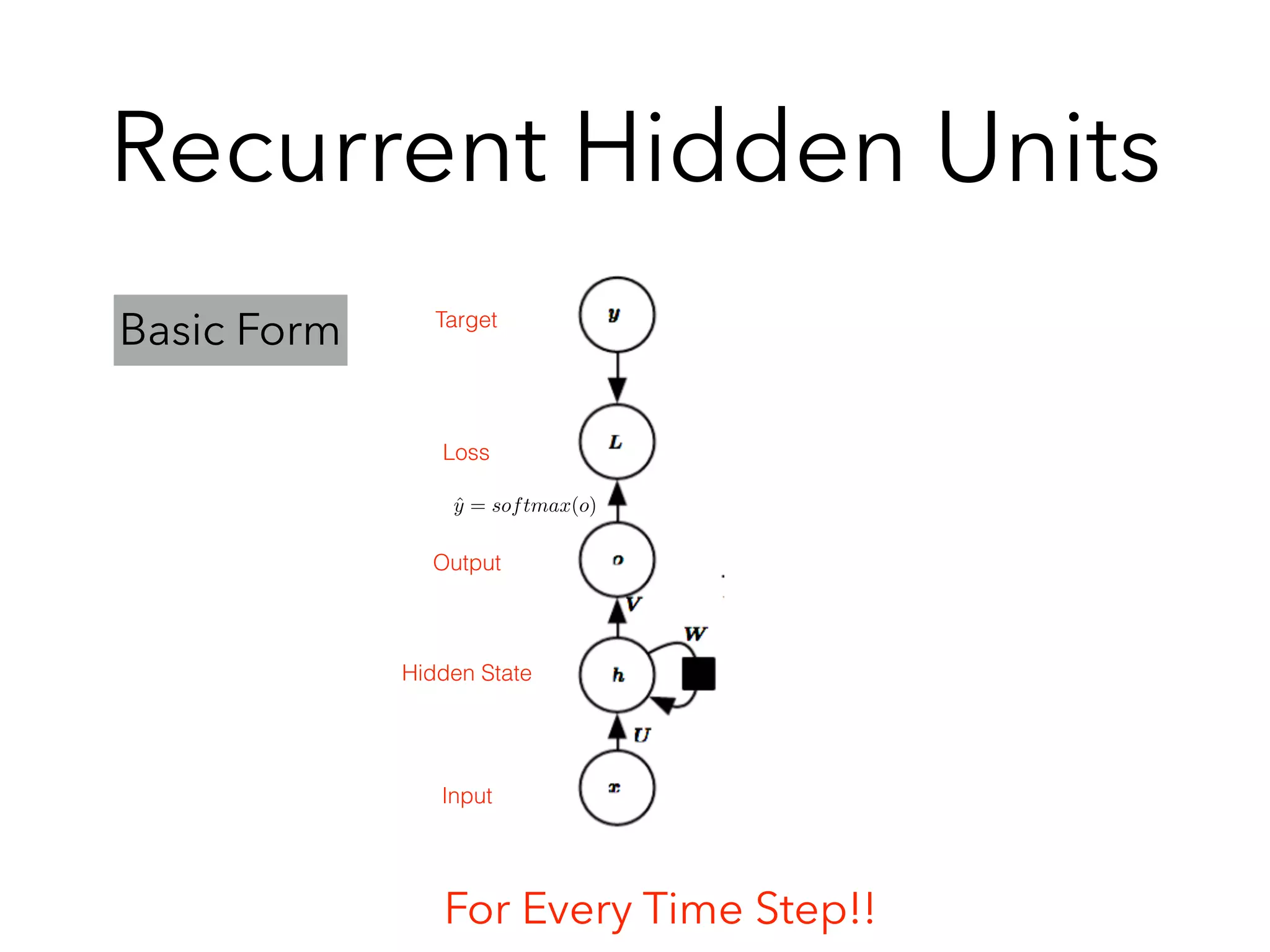
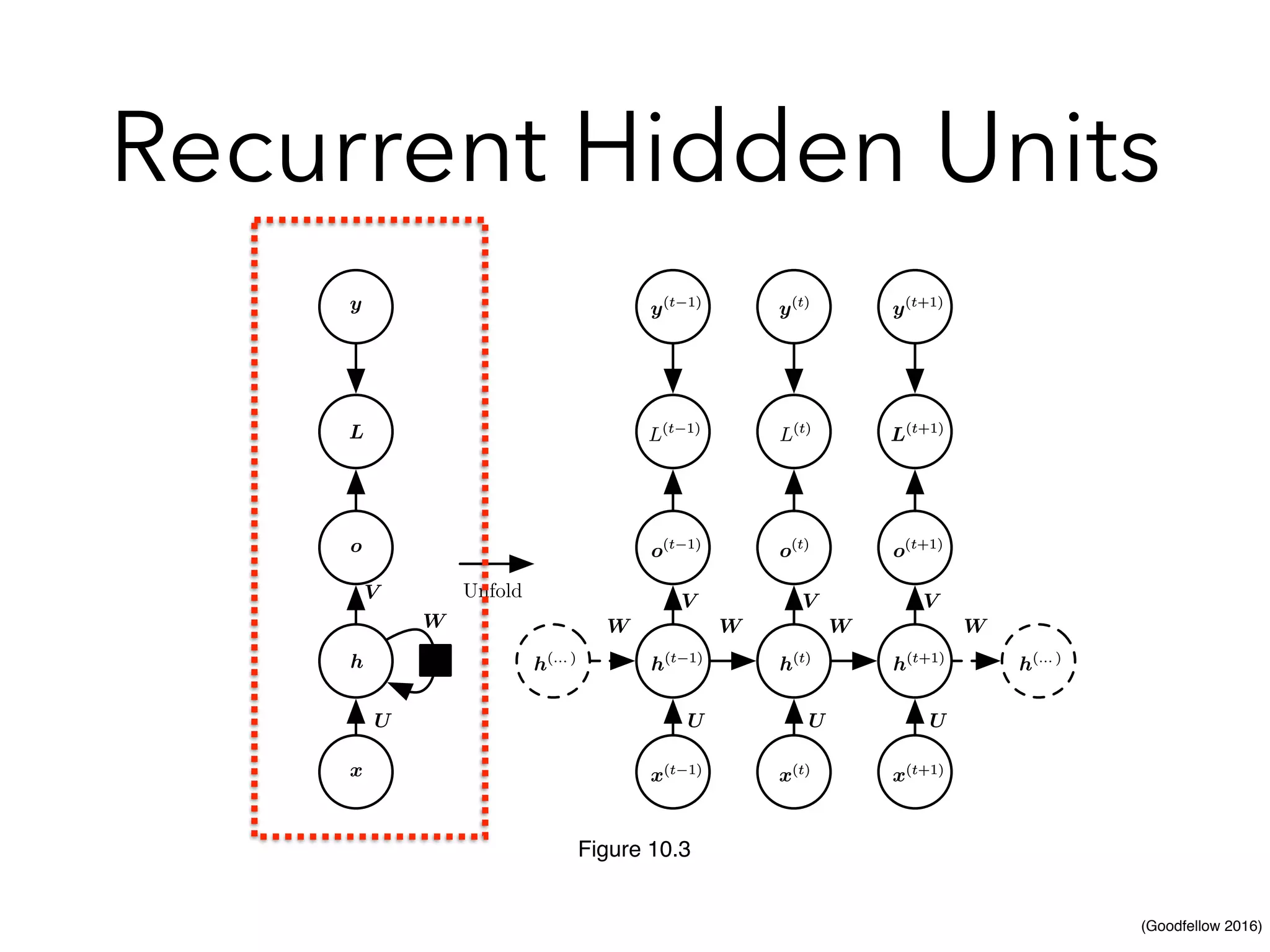
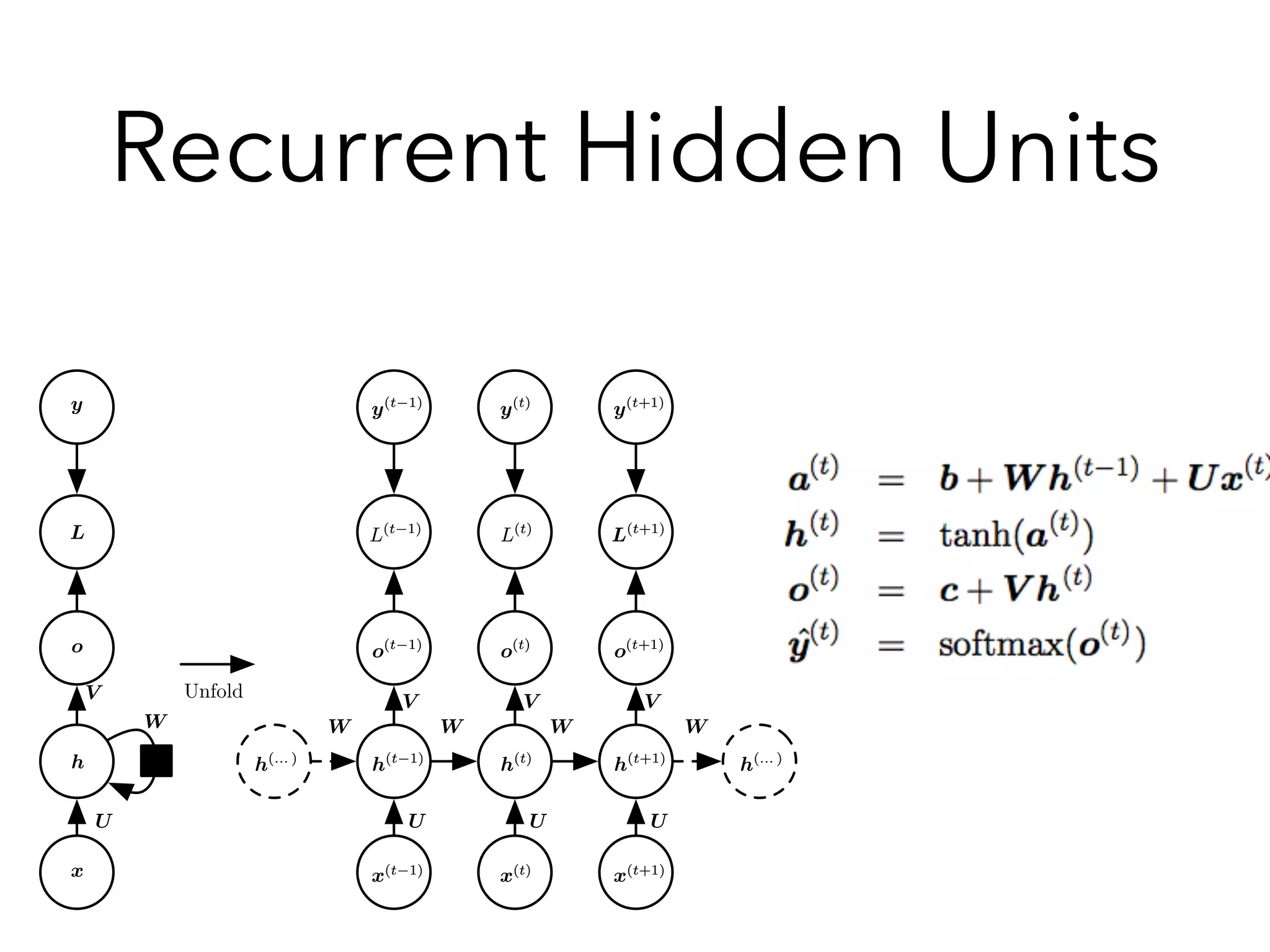
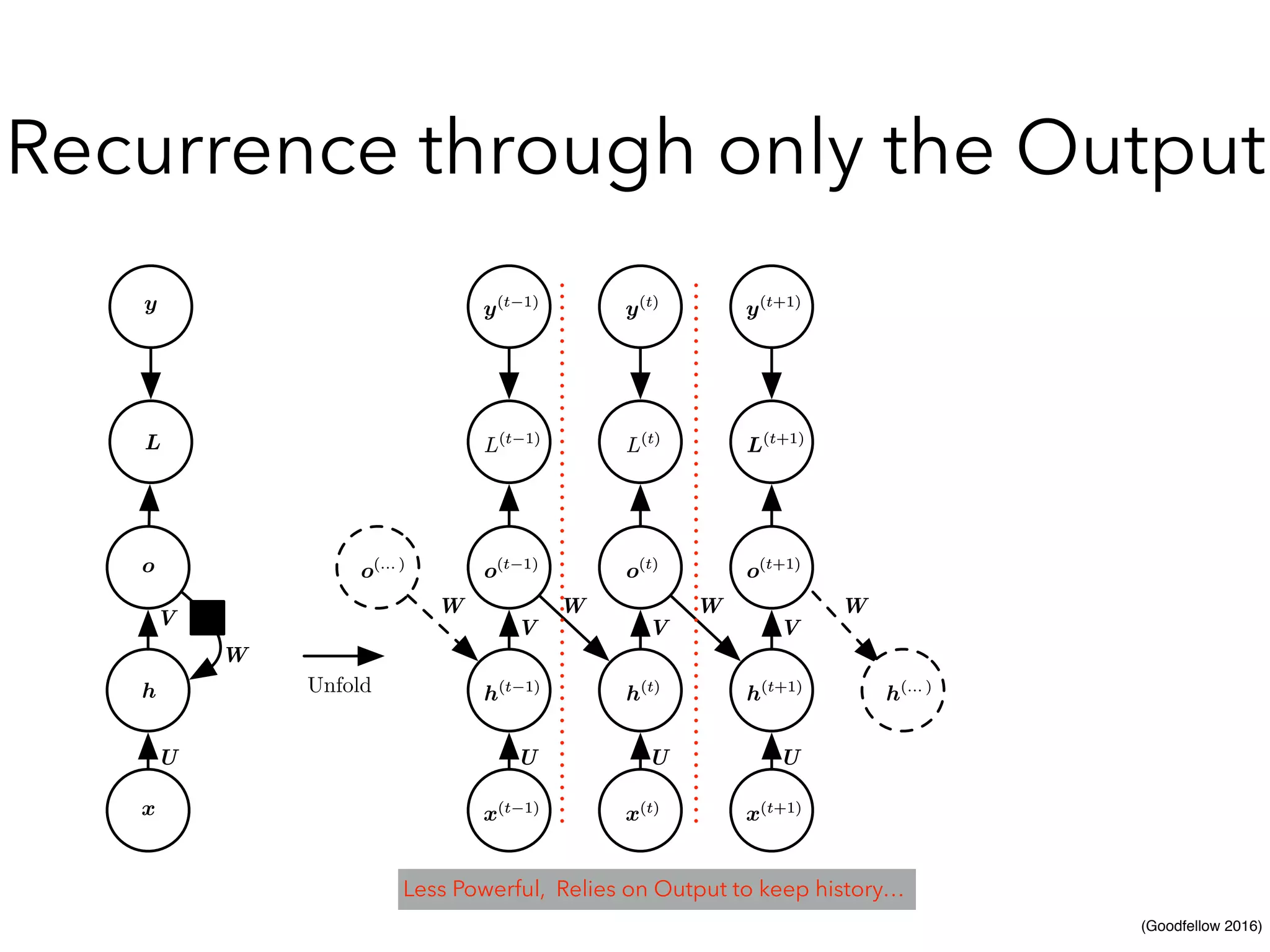
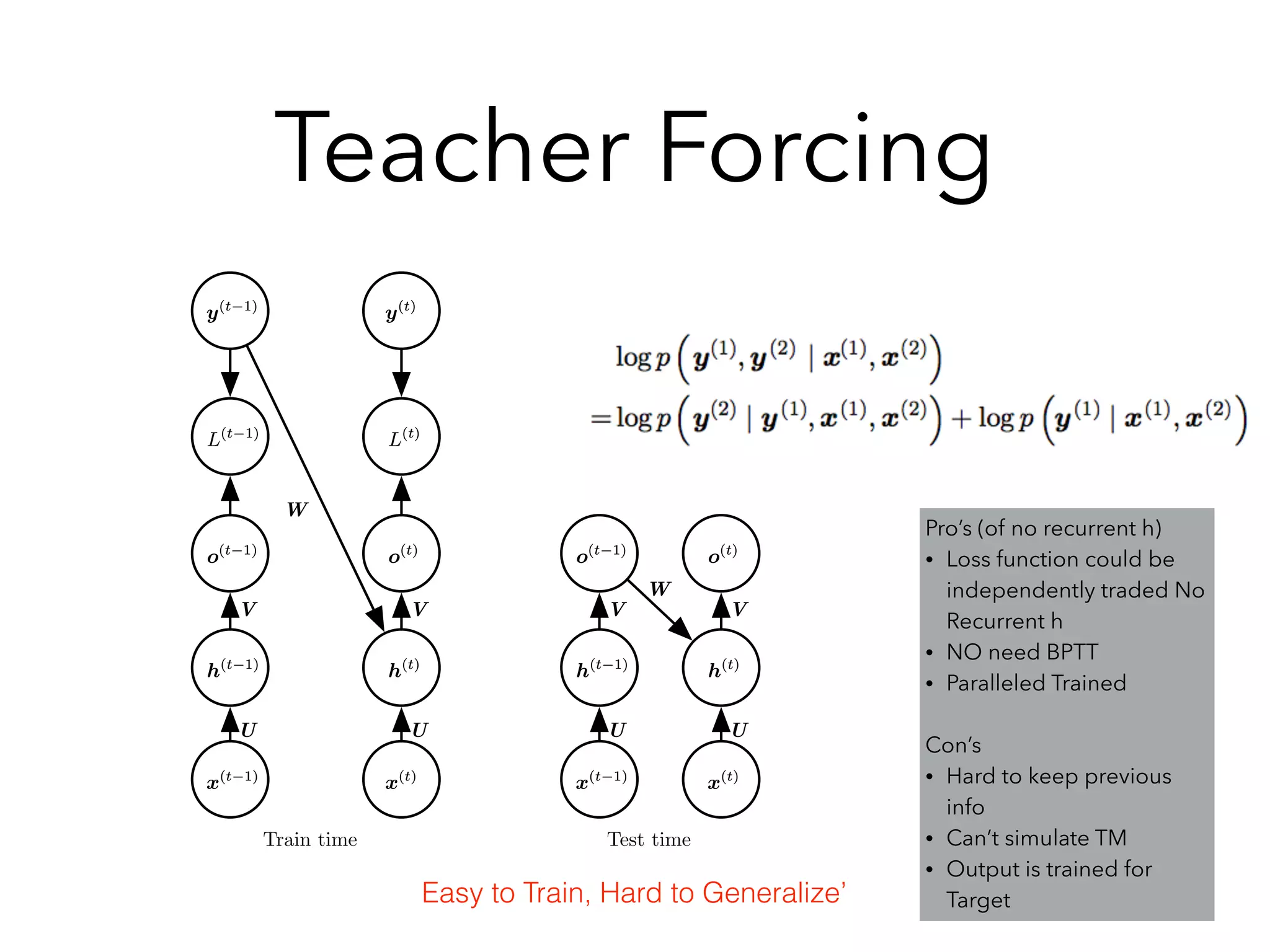
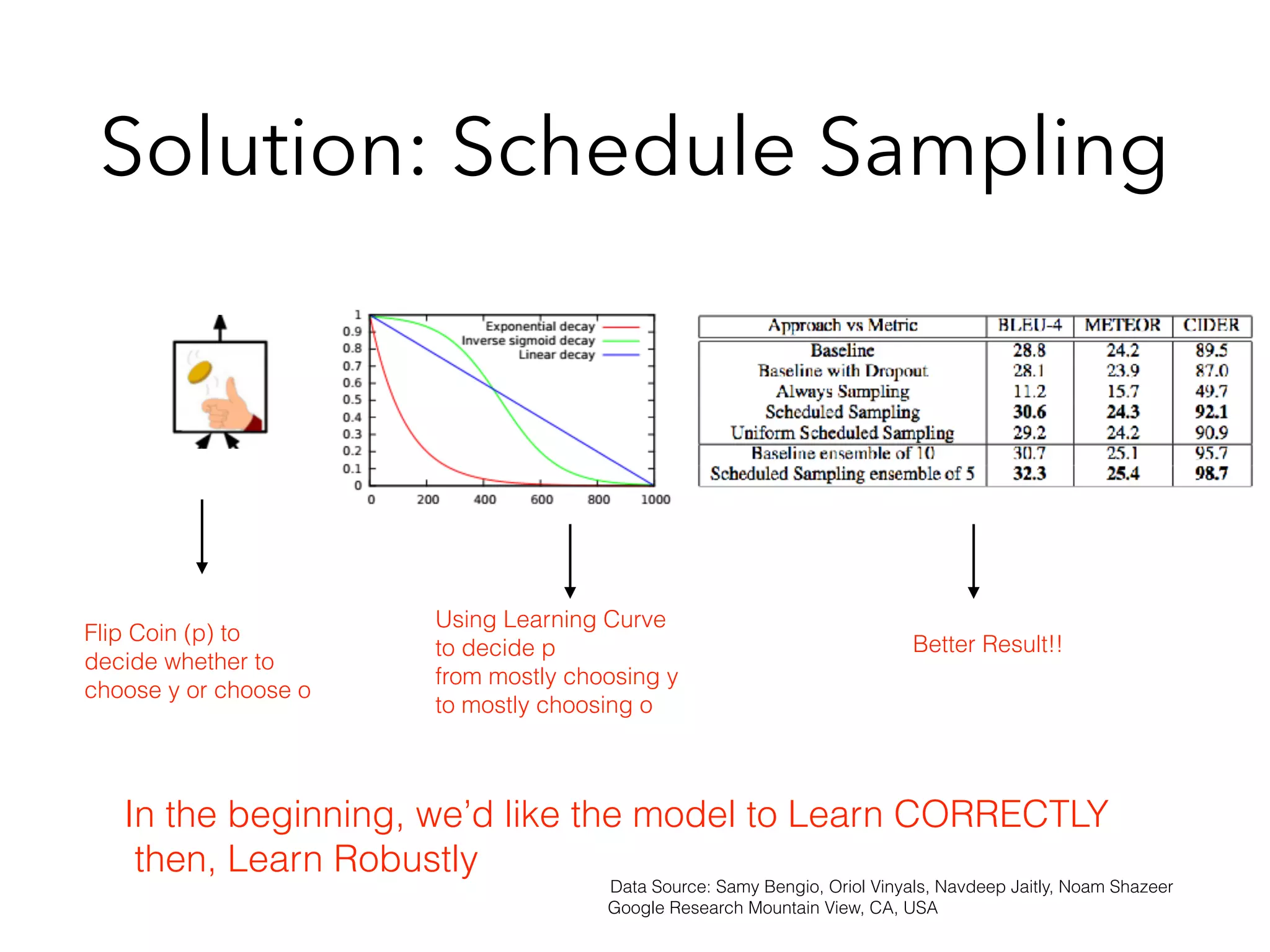
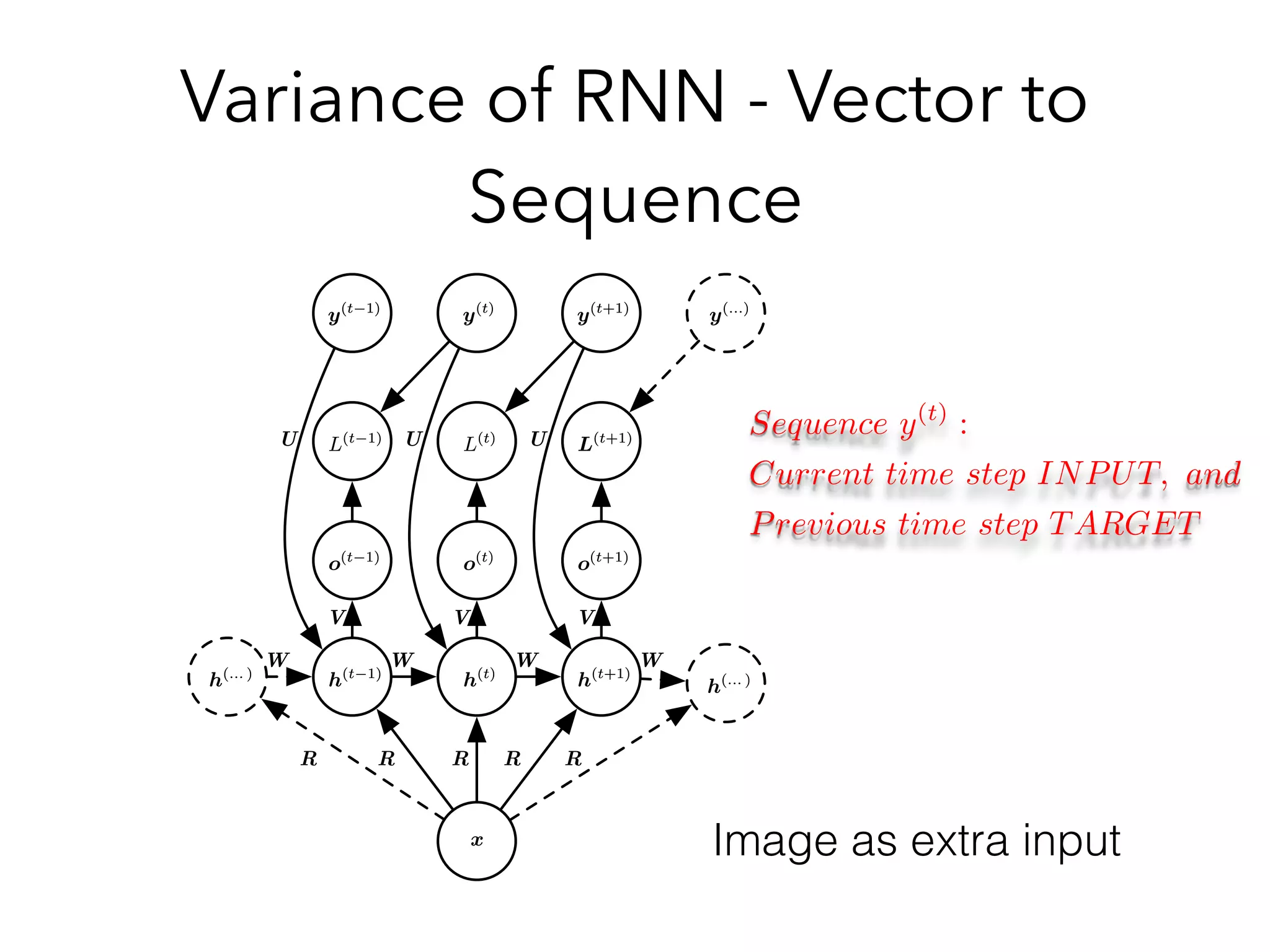
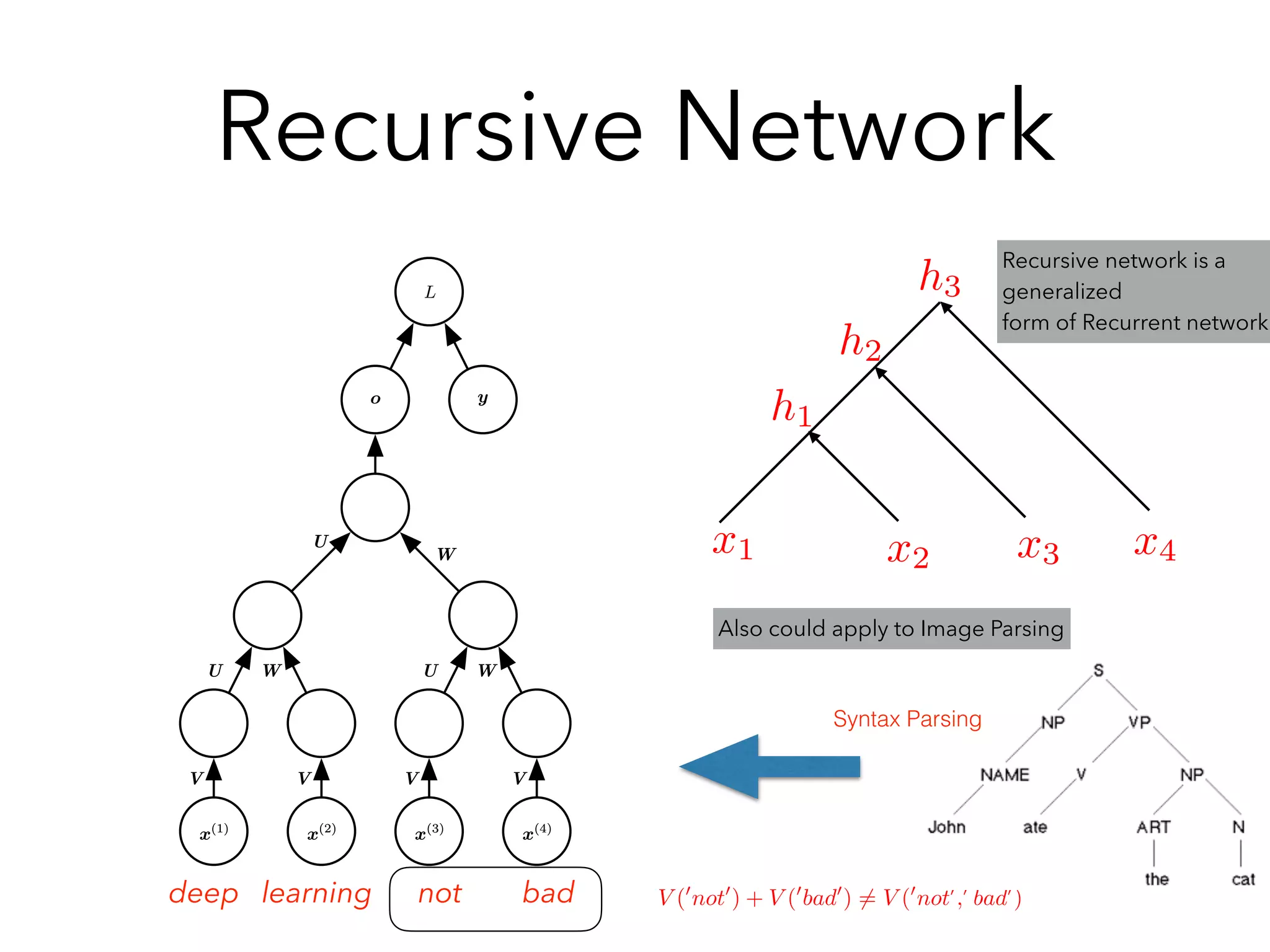
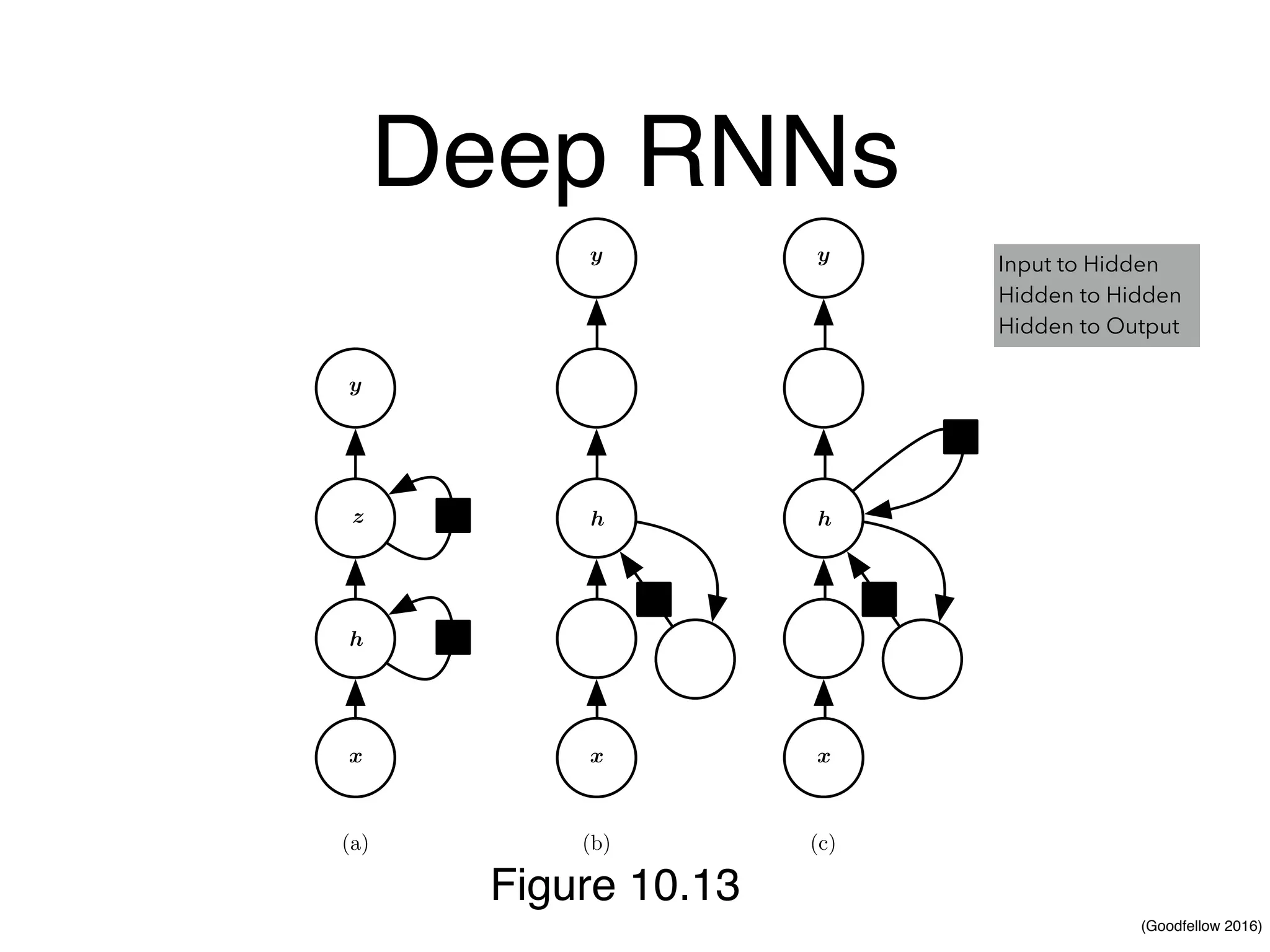
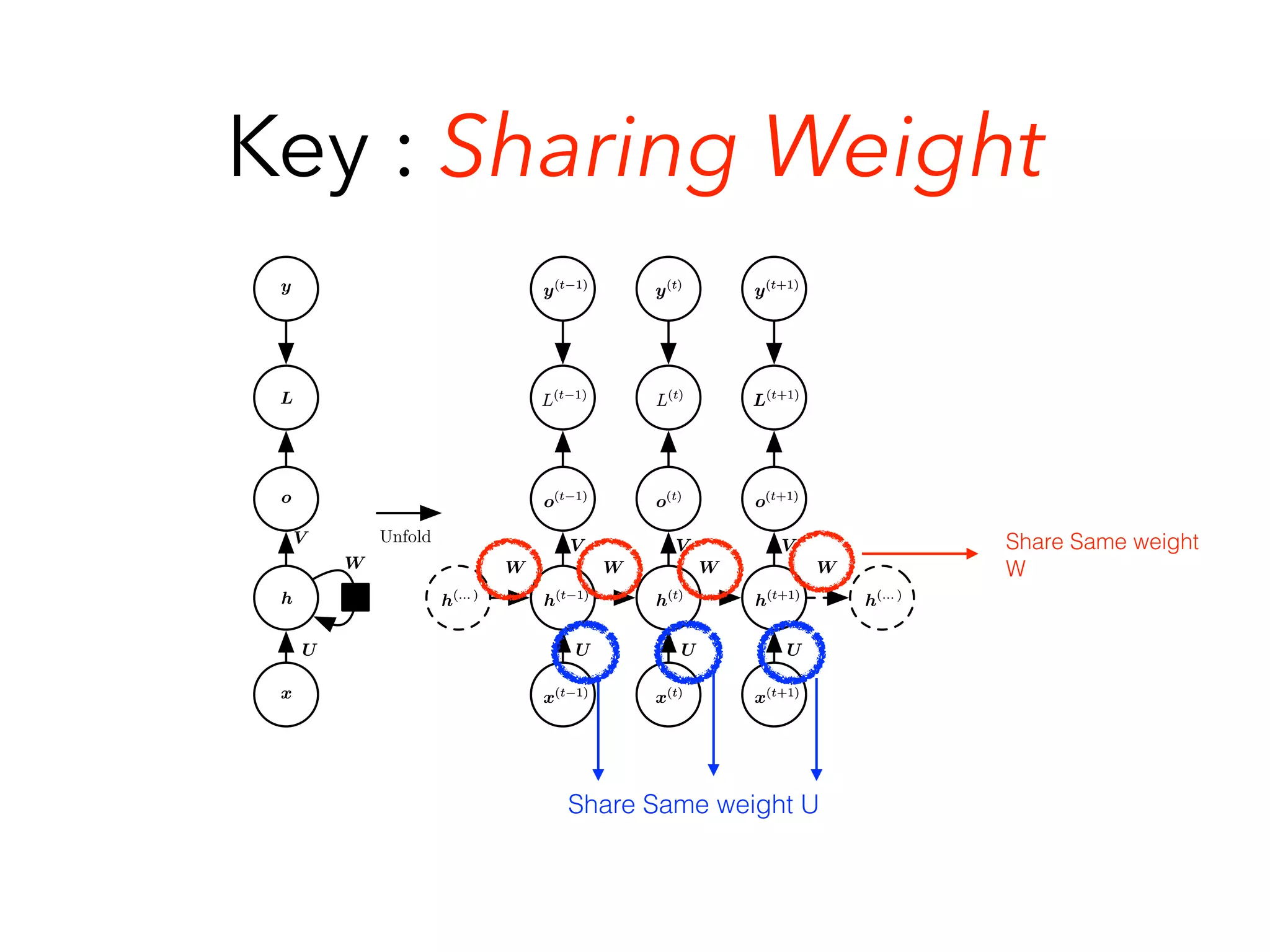
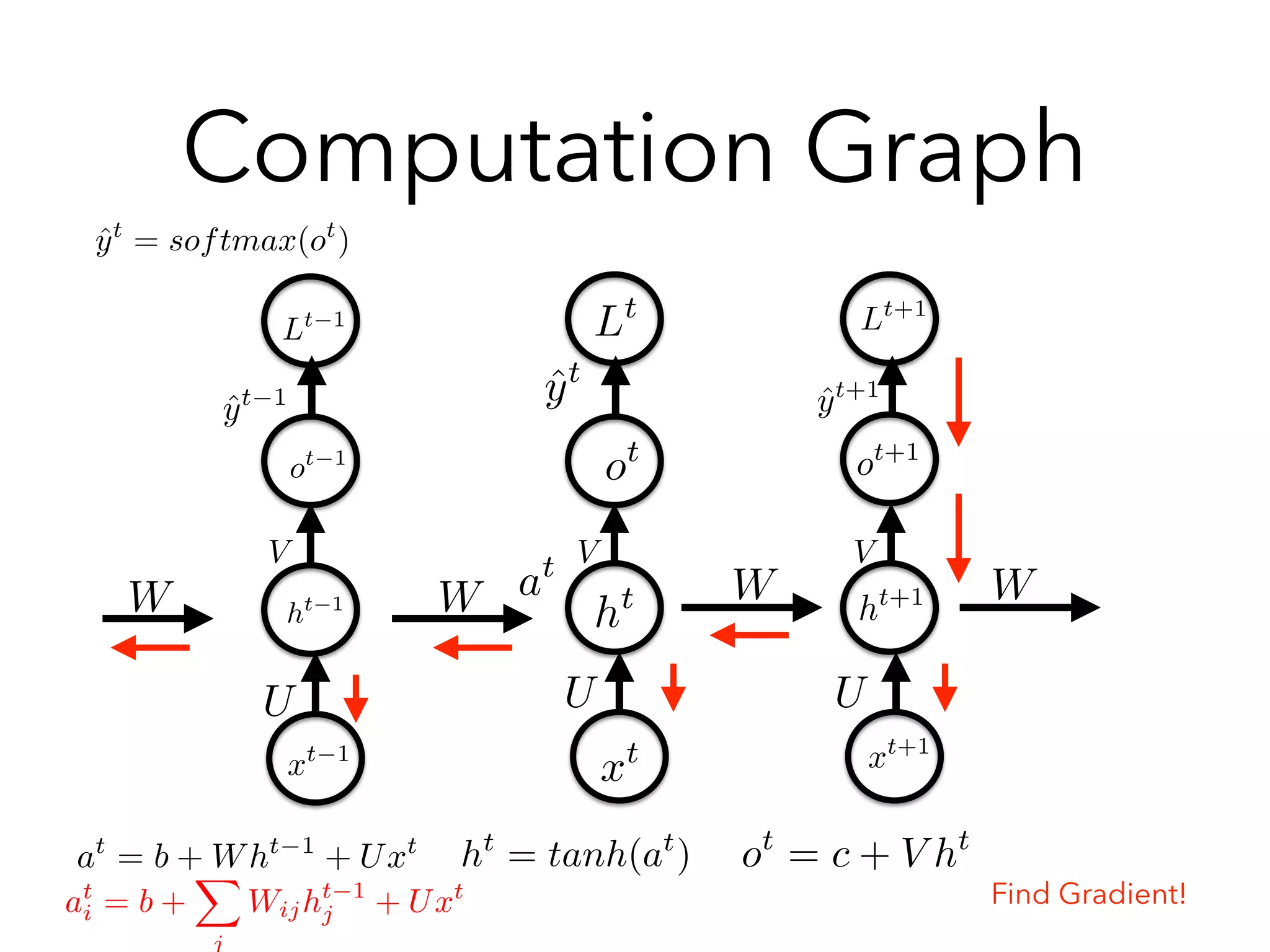
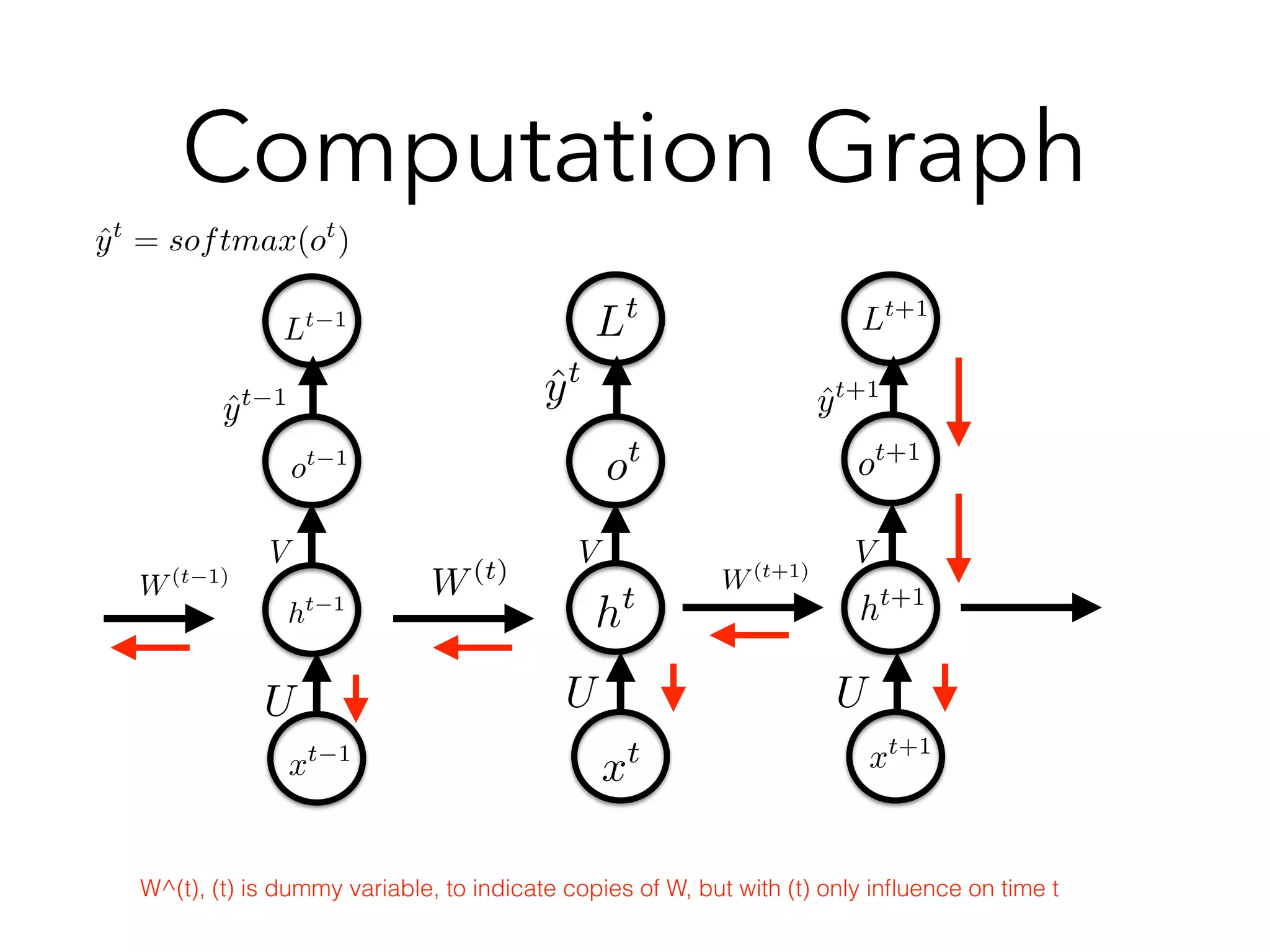
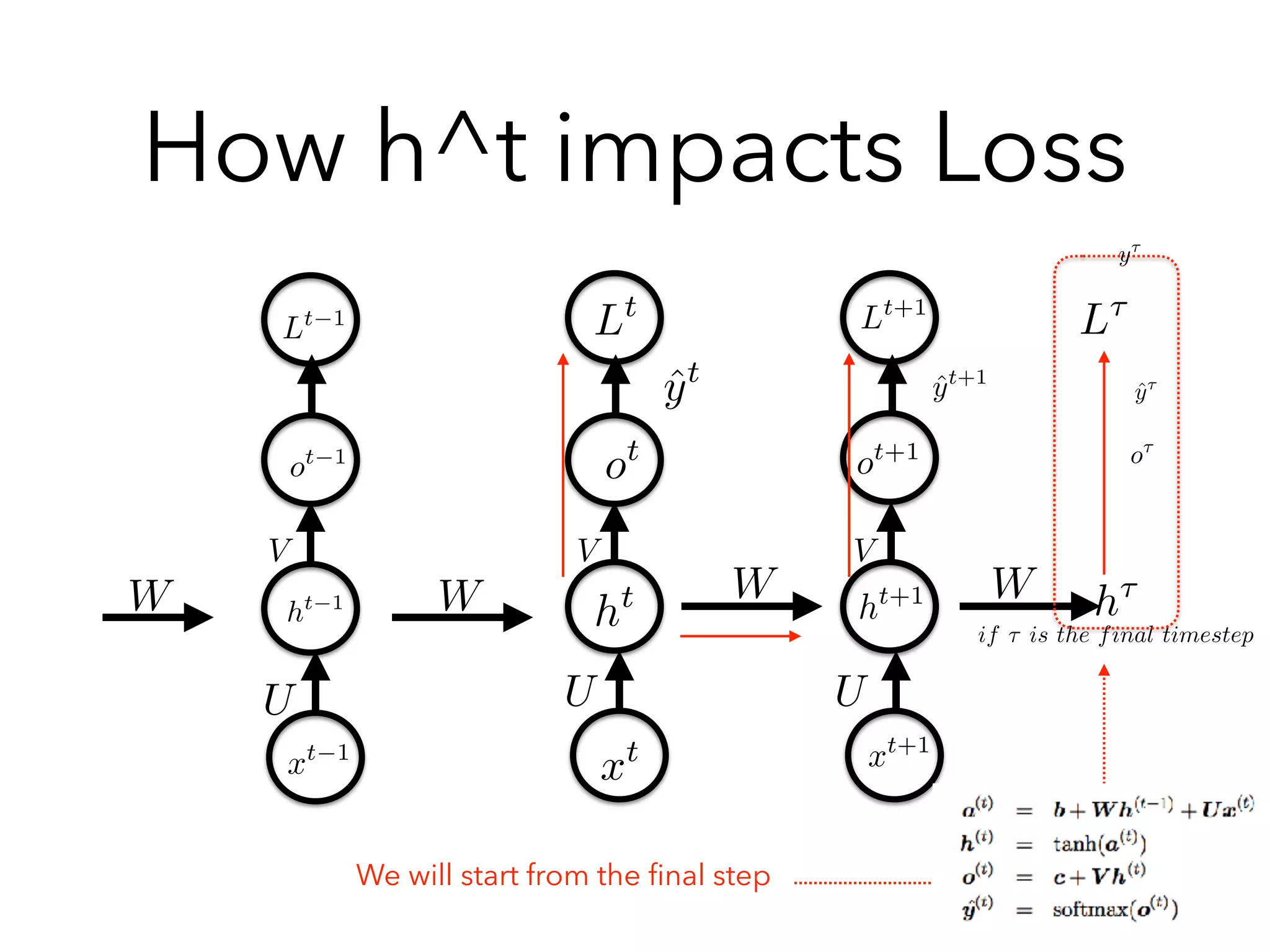
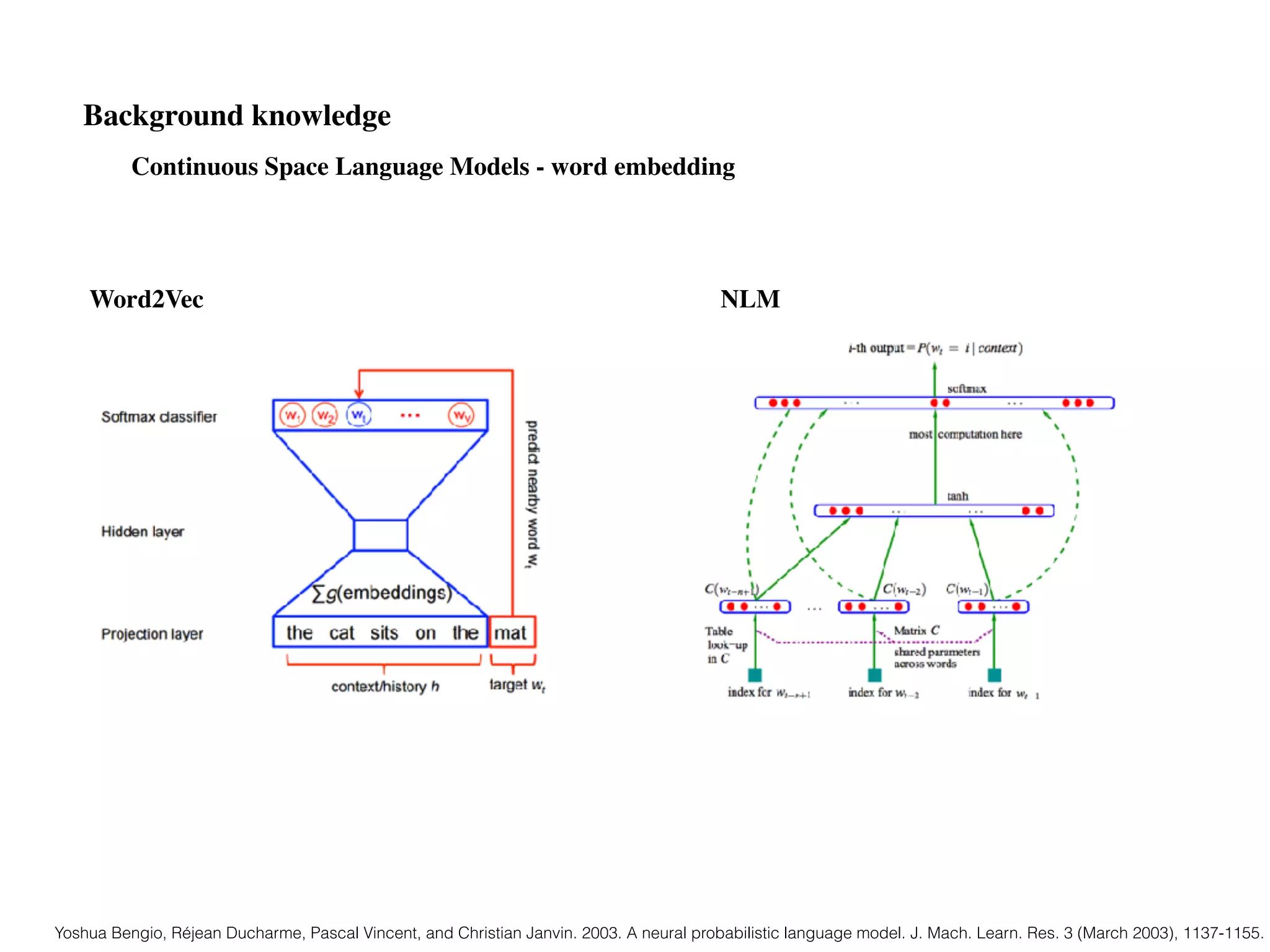
Chapter 10 discusses recurrent neural networks (RNNs), emphasizing their ability to process sequential data where order matters. It covers various types, applications, training methods like backpropagation through time (BPTT), and challenges such as exploding/vanishing gradients, introducing solutions like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs). The chapter also highlights practical applications of RNNs in image captioning, chatbots, and natural language processing.









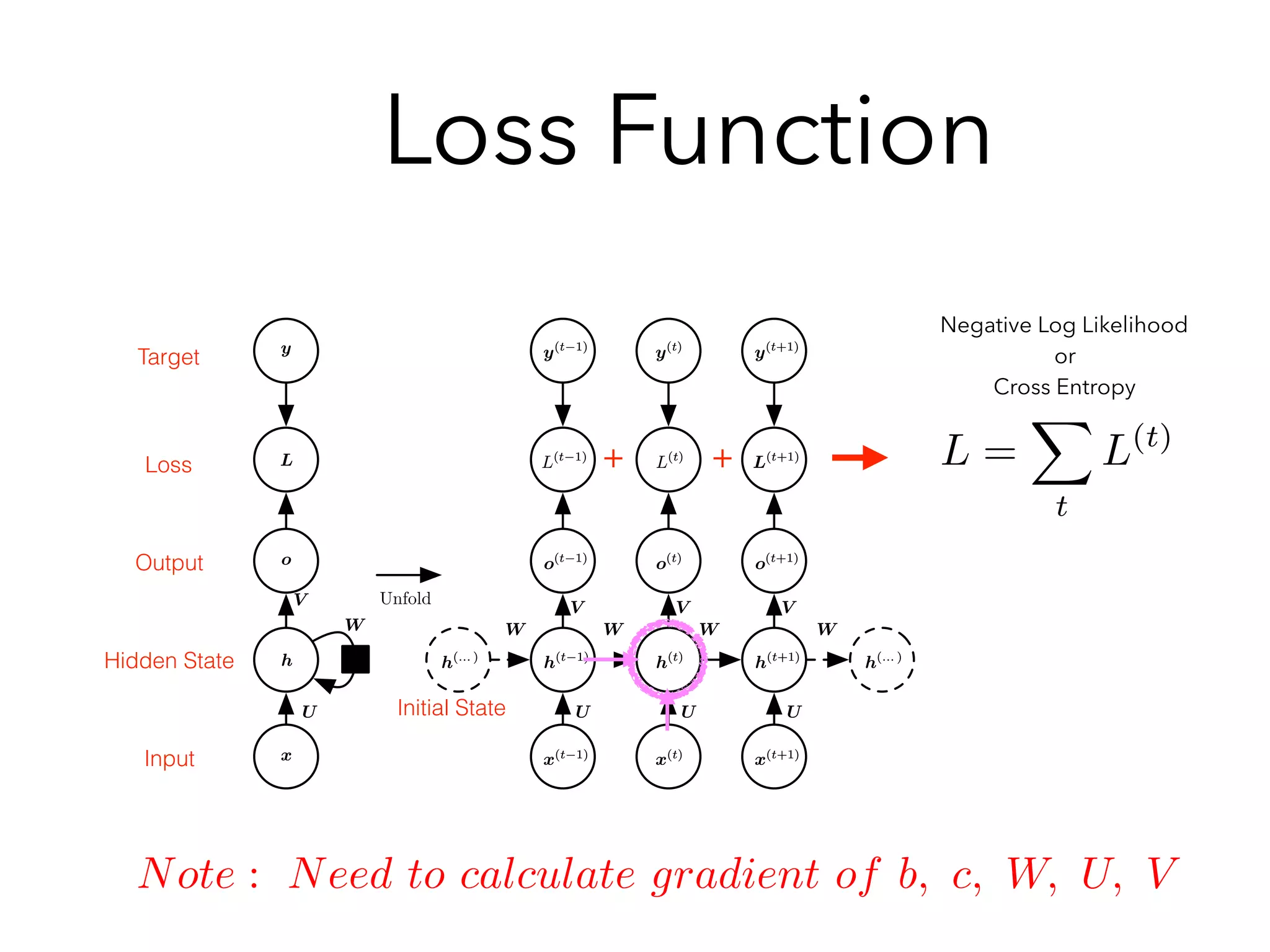



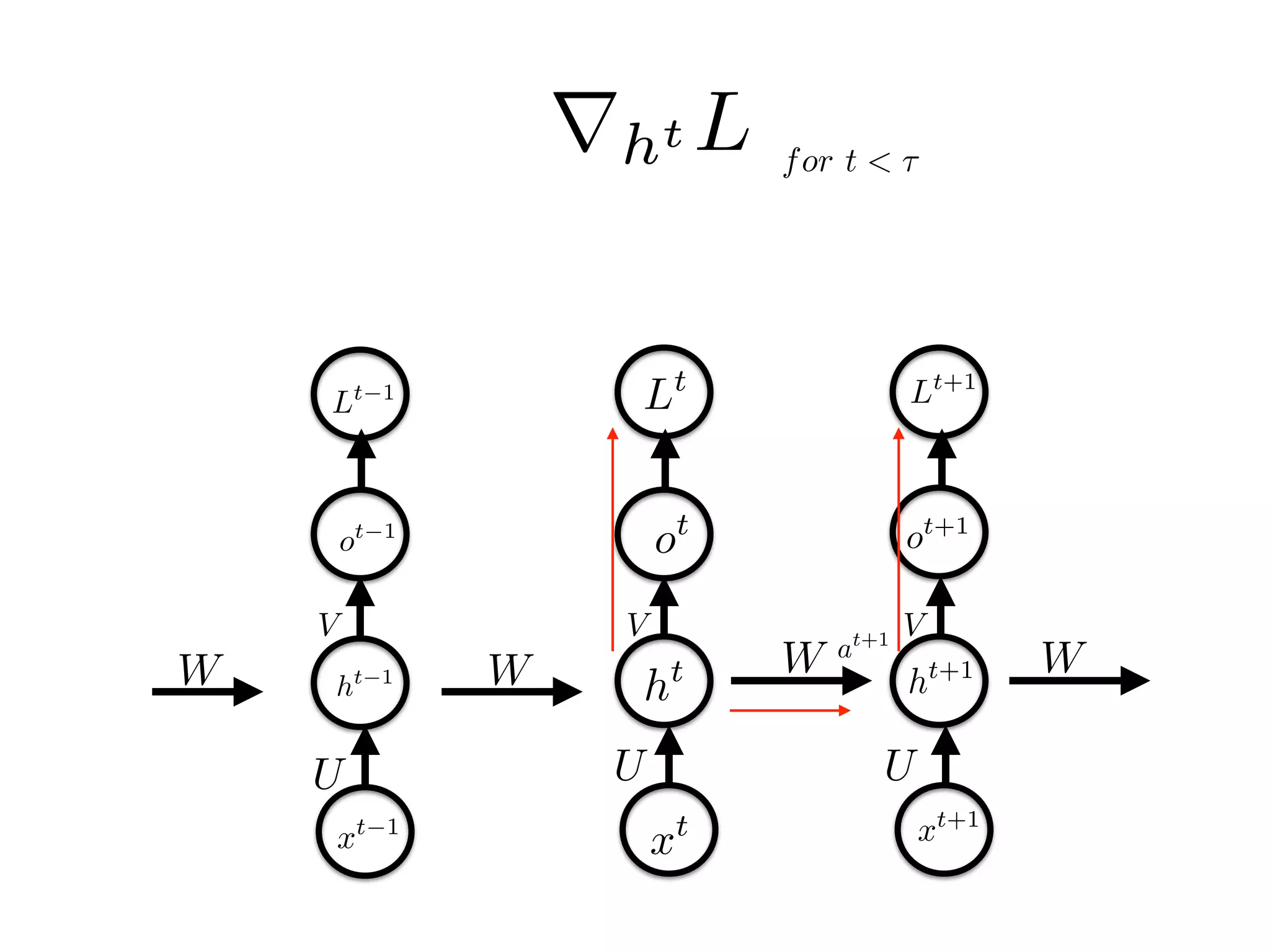
![rht L = (
@ht+1
@ht
)T @L
@ht+1
+ (
@ot
@ht
)T @L
@ot
= V T
rot Lt
=
2
6
6
6
6
4
W11, W21, ., ., Wj1, Wn1
W12, W22, ., ., Wj2, Wn2
., ., ., ., ., .
., ., ., ., ., .
W1n, W2n, ., ., Wjn, Wnn
3
7
7
7
7
5
2
6
6
6
6
6
6
4
1 tan(ht
1)2
0 0 . .
0 1 tan(ht
2)2
0 . .
.
0 0 . 1 tan(ht
j)2
.
.
.
3
7
7
7
7
7
7
5
2
6
6
6
6
6
6
6
6
4
@L
@ht+1
1
@L
@ht+1
2
.
@L
@ht+1
j
.
.
3
7
7
7
7
7
7
7
7
5
(
@ht+1
@ht
)T @L
@ht+1 = WT
diag(1 (ht+1
)2
)rht+1 L
for t < ⌧
rht L Note: different to the text book
To be verified!!!!!!!!!!!
Jacobian [
@ht+1
i
@ht
j
] =
@ht+1
i
@at+1
i
·
@at+1
i
@ht
j
= Wij
@ht+1
i
@at+1
i
= Wij(1 tanh2
(at+1
i )) = diag(1 tanh2
(at+1
))W
= diag(1 (ht+1
)2
)W
rht L = WT
rht+1 Ldiag(1 (ht+1
)2
) + V T
rot Lt
pls help to check eq. 10.21](https://image.slidesharecdn.com/chapter10170505l-170612022817/75/Deep-Learning-Recurrent-Neural-Network-Chapter-10-34-2048.jpg)


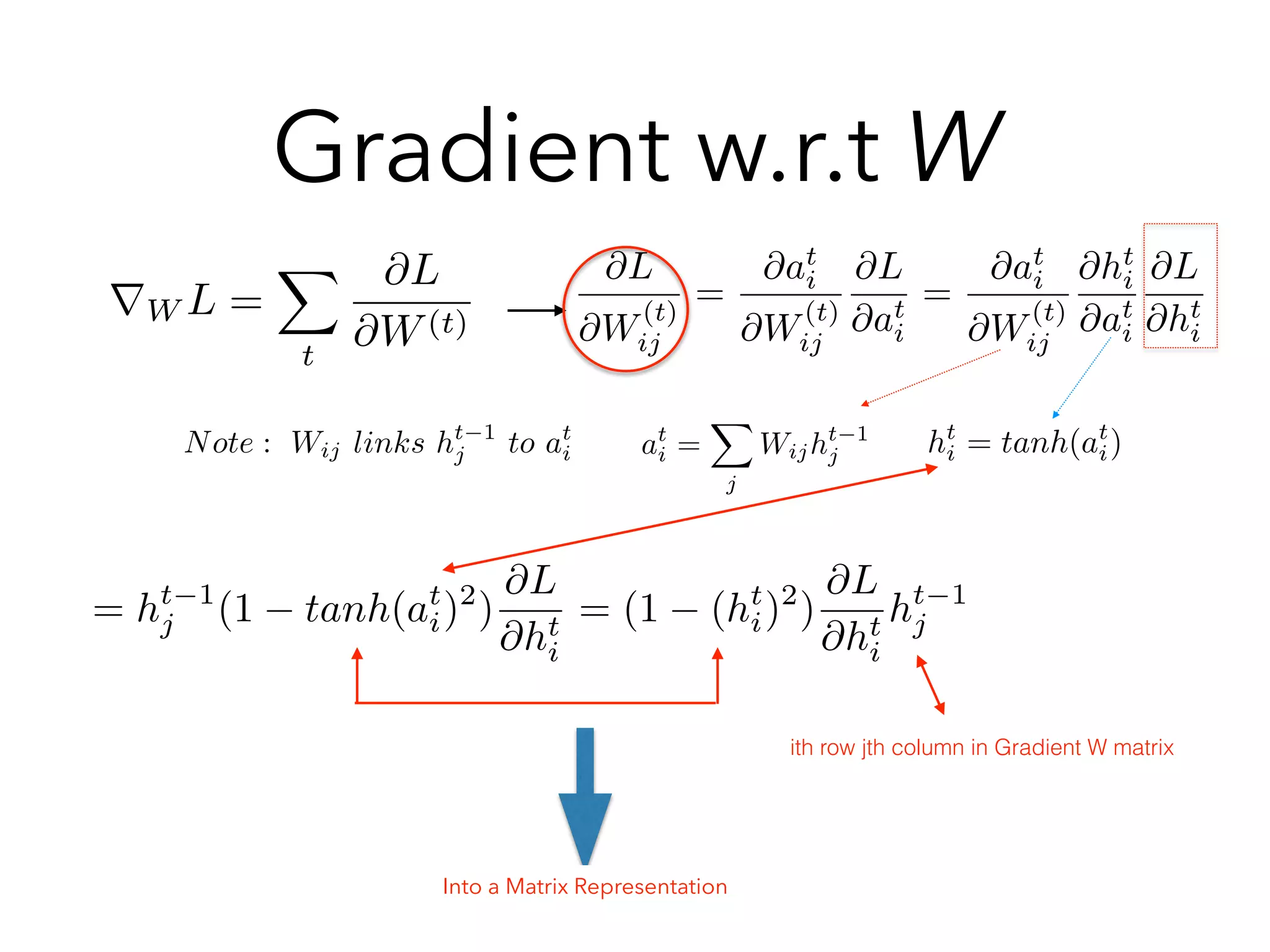



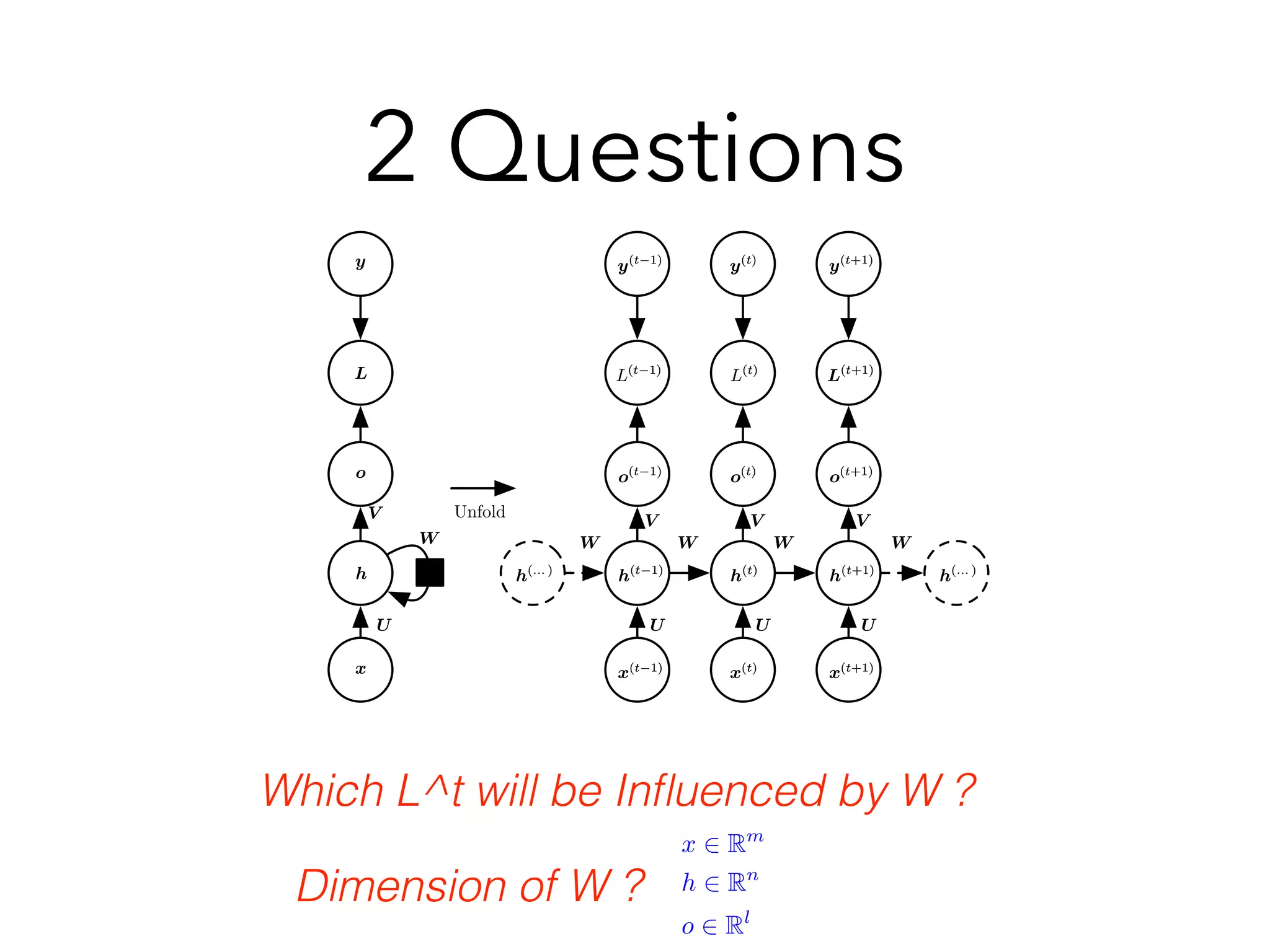
![Why Vanishing?
CS 224d Richard Soucher
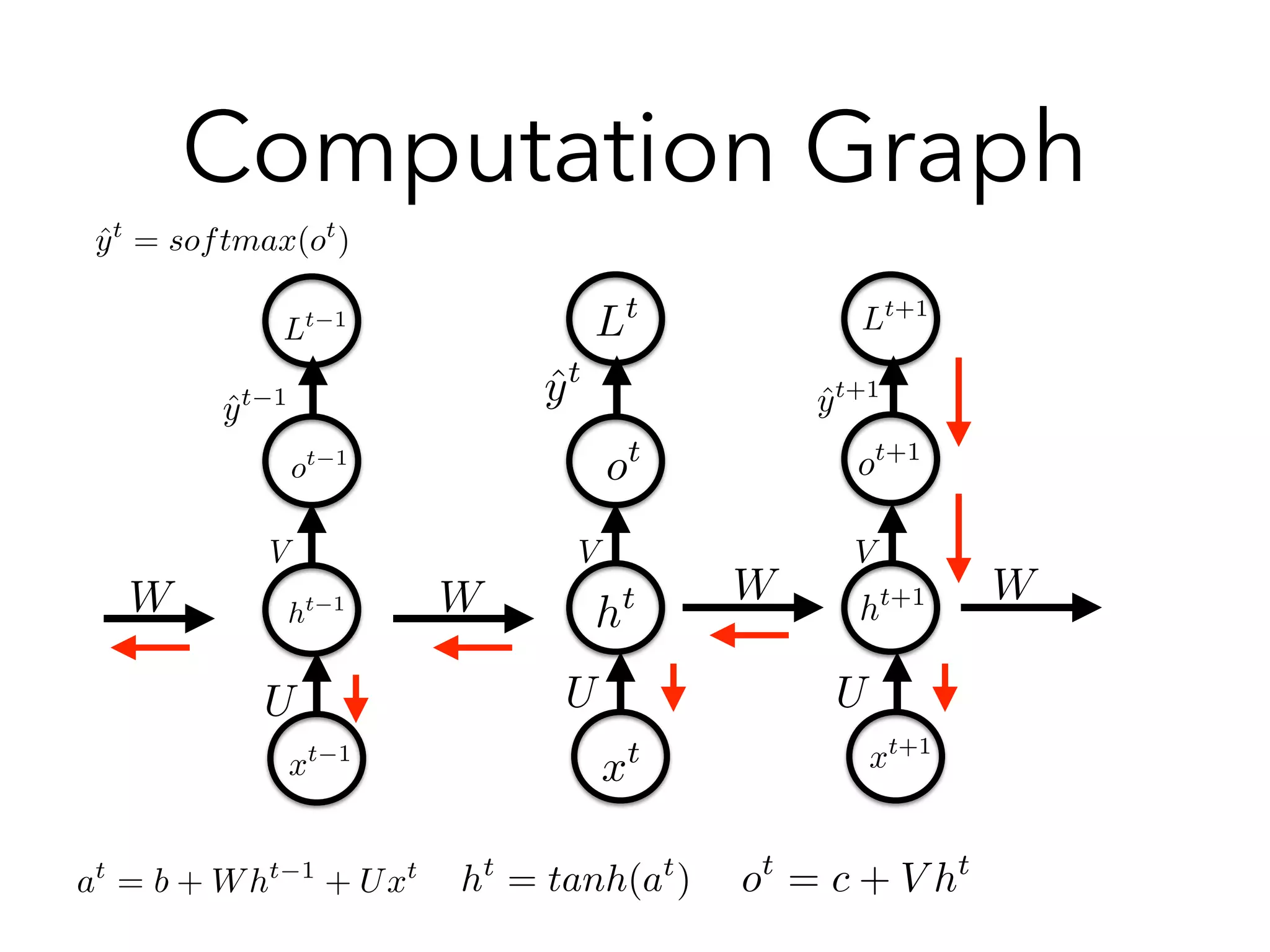
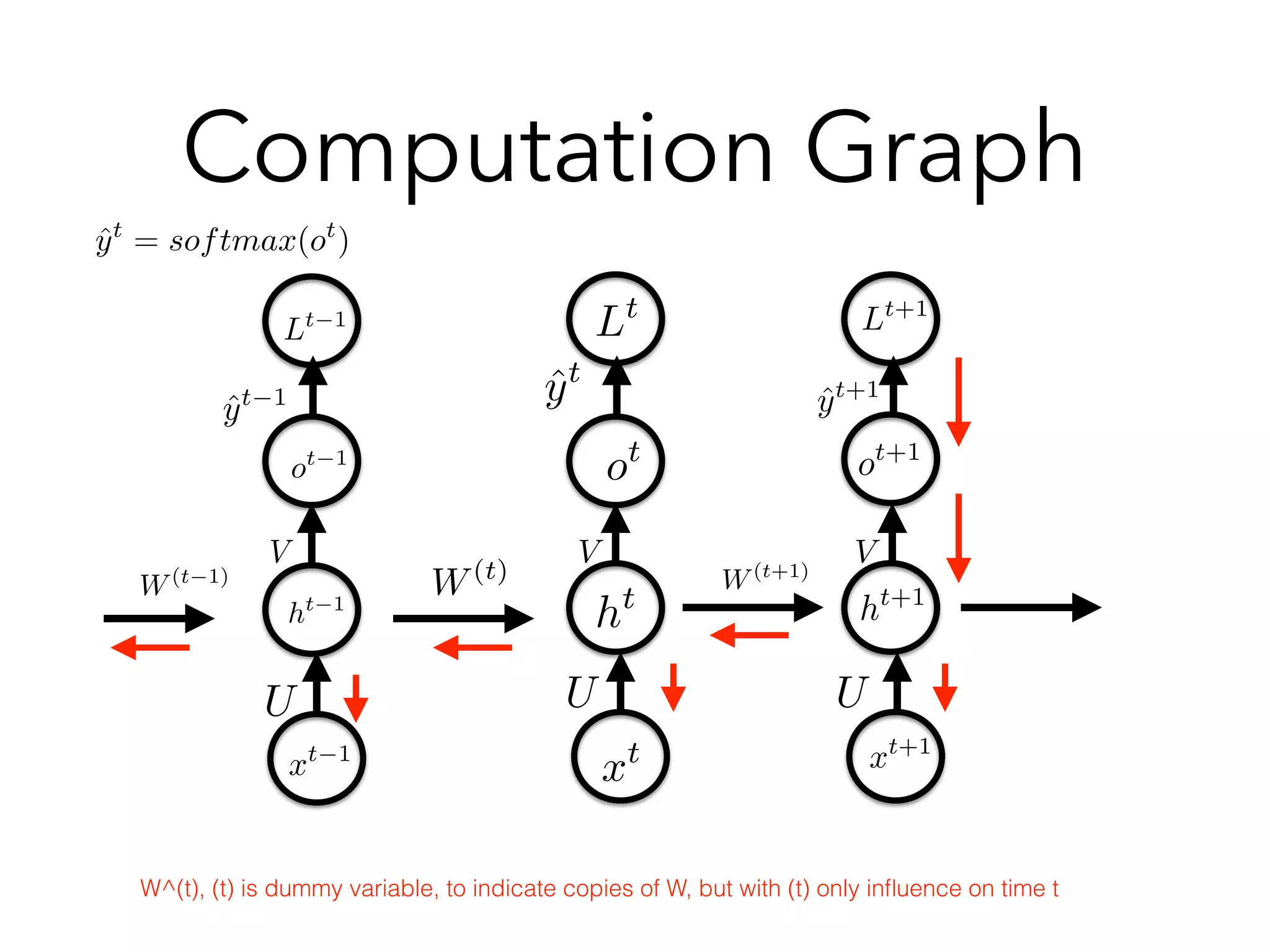
Jacobian Matrix
@Lt
@W
=
tX
k=1
@Lt
@ˆyt
@ˆyt
@ht
@ht
@hk
@hk
@W
@ht
@hk
= ⇧t
j=k+1
@hj
@hj 1
from step k to step t
@L
@W
=
tX
k=1
@Lt
@W
note :
@ht+1
i
@at+1
k
= 0, if k 6= iJacobian [
@ht+1
i
@ht
j
] =
X
k
@ht+1
i
@at+1
k
·
@at+1
k
@ht
j
=
@ht+1
i
@at+1
i
Wij
= (1 tanh2
(at+1
i ))Wij = diag(1 tanh2
(at+1
))W
= diag(1 (ht+1
)2
)W](https://image.slidesharecdn.com/chapter10170505l-170612022817/75/Deep-Learning-Recurrent-Neural-Network-Chapter-10-46-2048.jpg)
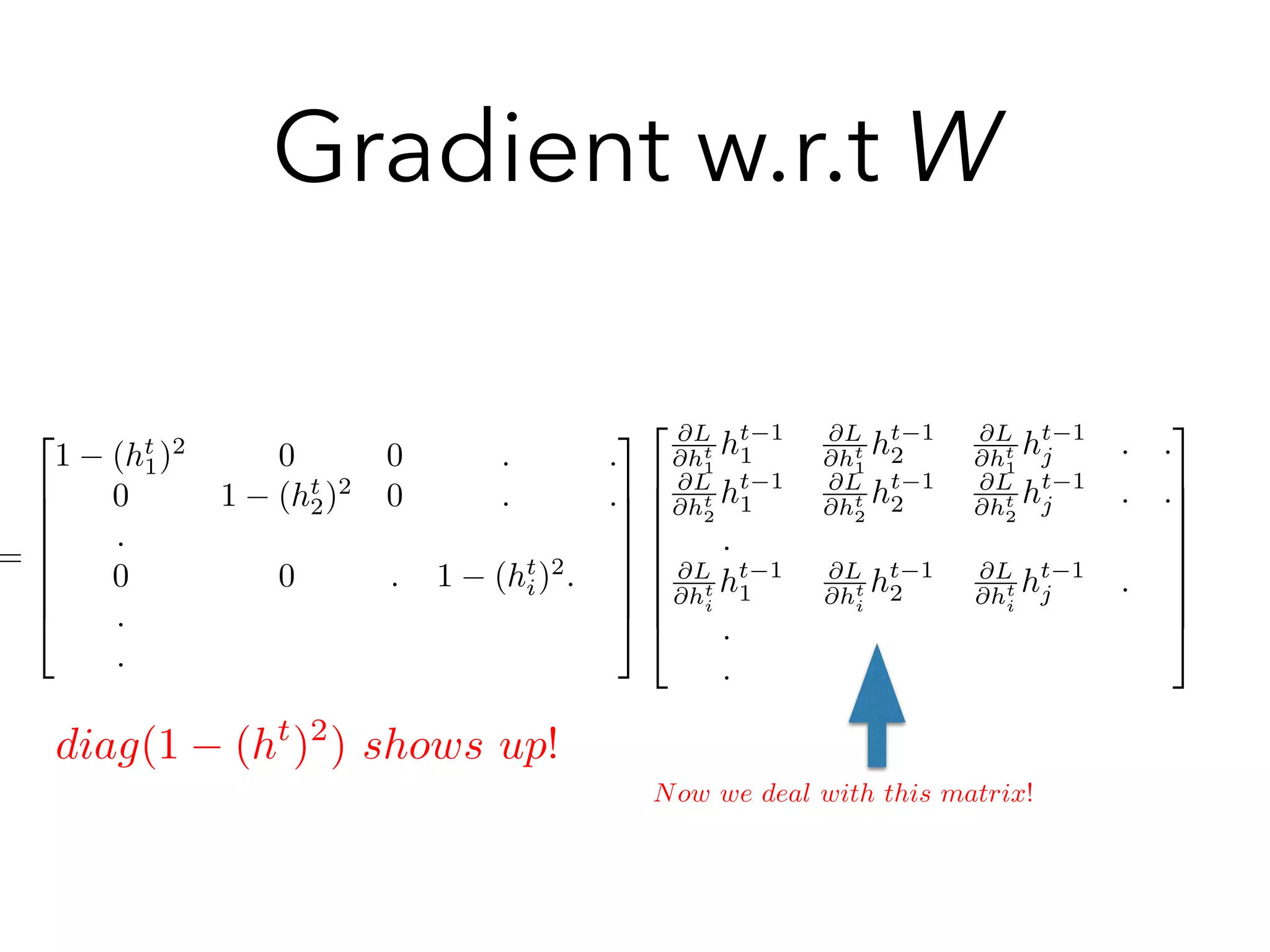
![@ht
@hk
= ⇧t
j=k+1
@hj
@hj 1
= ⇧t
j=k+1(diag[f0
(aj
)]W)
k
@hj
@hj 1
k kdiag[f0
(aj)]kkWT
k h W
k
@ht
@hk
k = k⇧t
j=k+1
@hj
@hj 1
k ( h W )t k
CS 224d Richard Soucher
eg: t=200, k=5, both beta =0.9,
then almost 0
when both equals to 1.1,
17 digits.
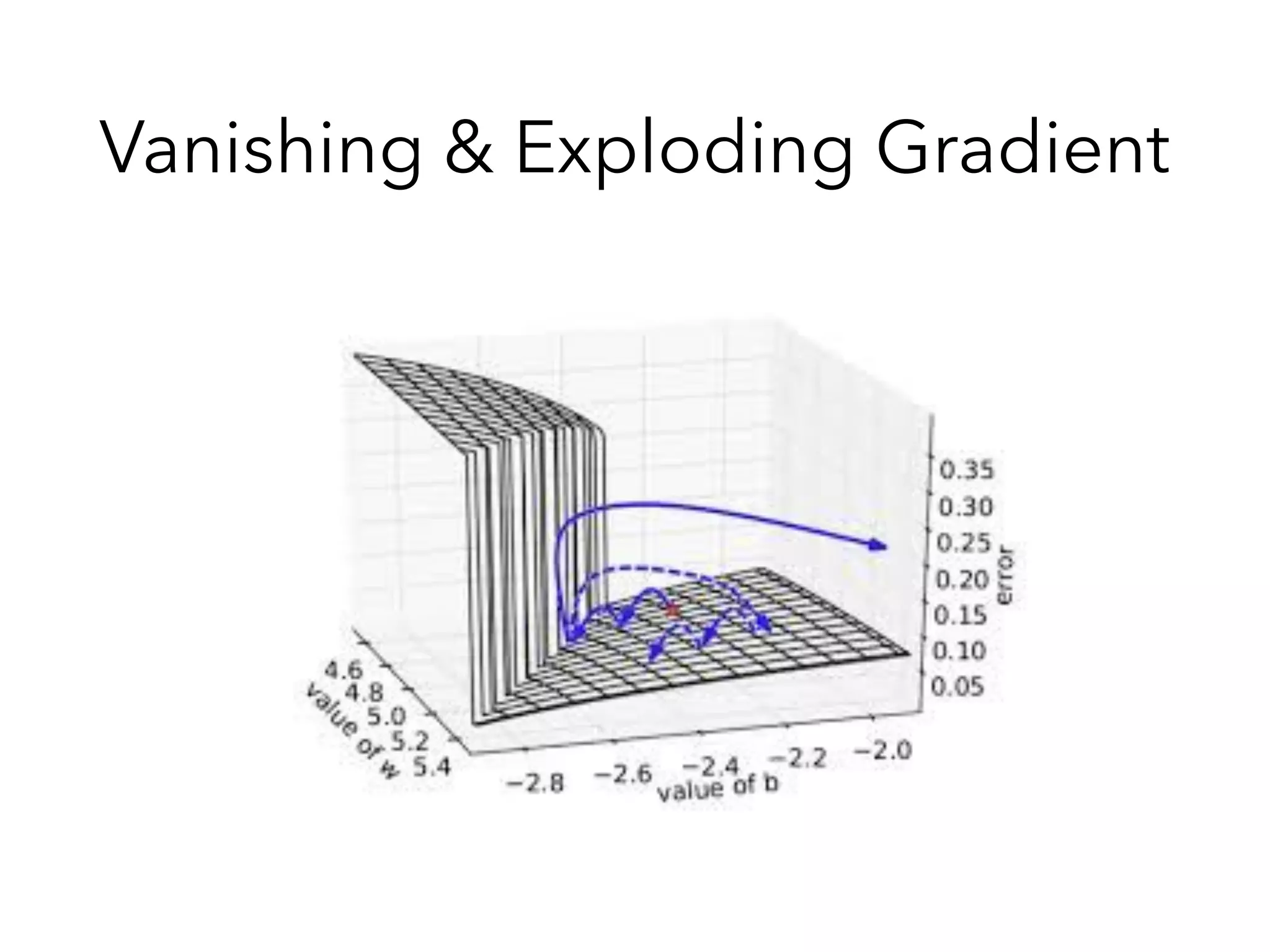
The Gradient Could be Exploded or Vanished!!!
Note: Vanishing/Exploding Gradient Not only happens in RNN, but also in Deep Feed Forward Network !
Why Vanishing?](https://image.slidesharecdn.com/chapter10170505l-170612022817/75/Deep-Learning-Recurrent-Neural-Network-Chapter-10-47-2048.jpg)



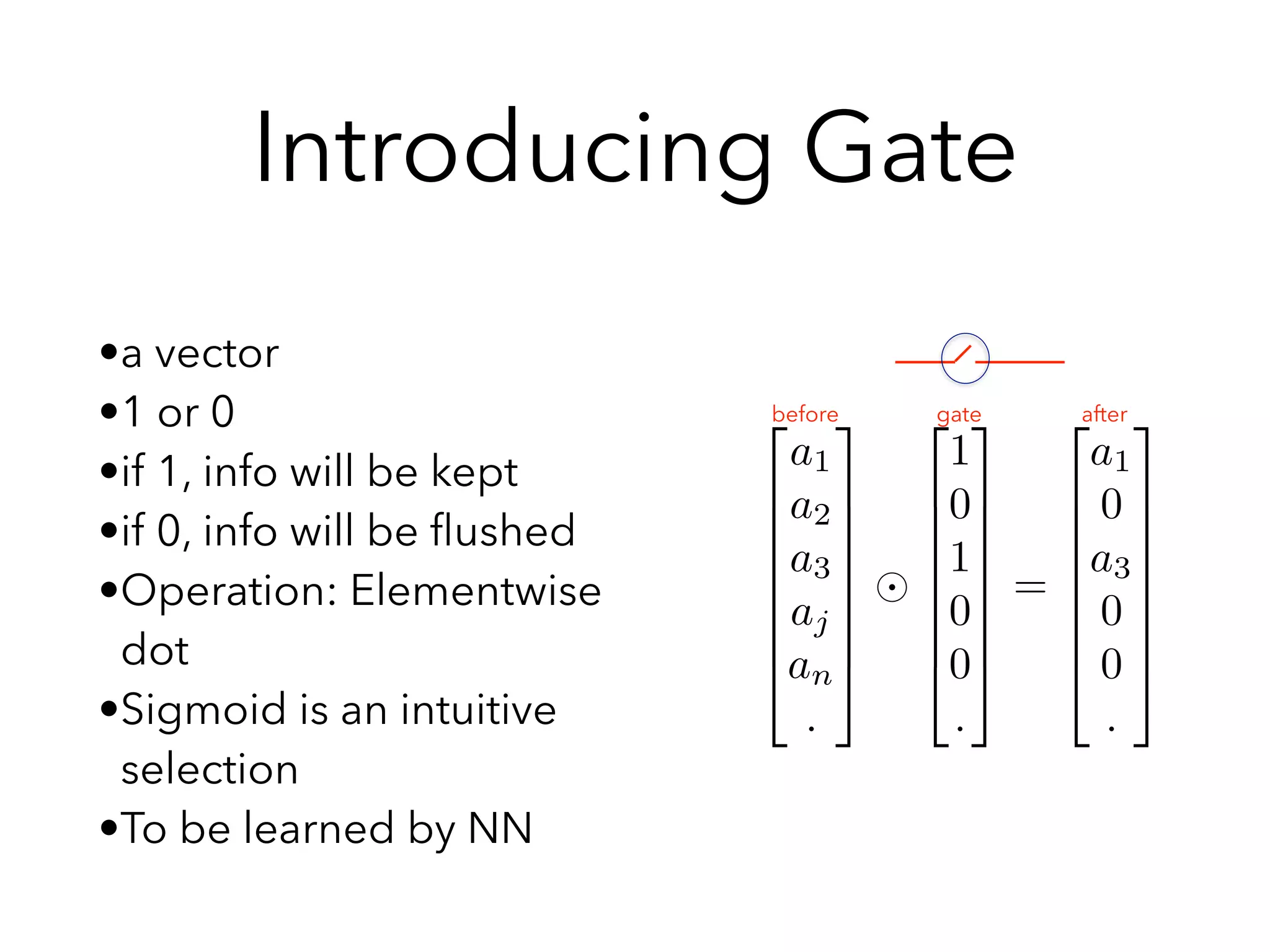
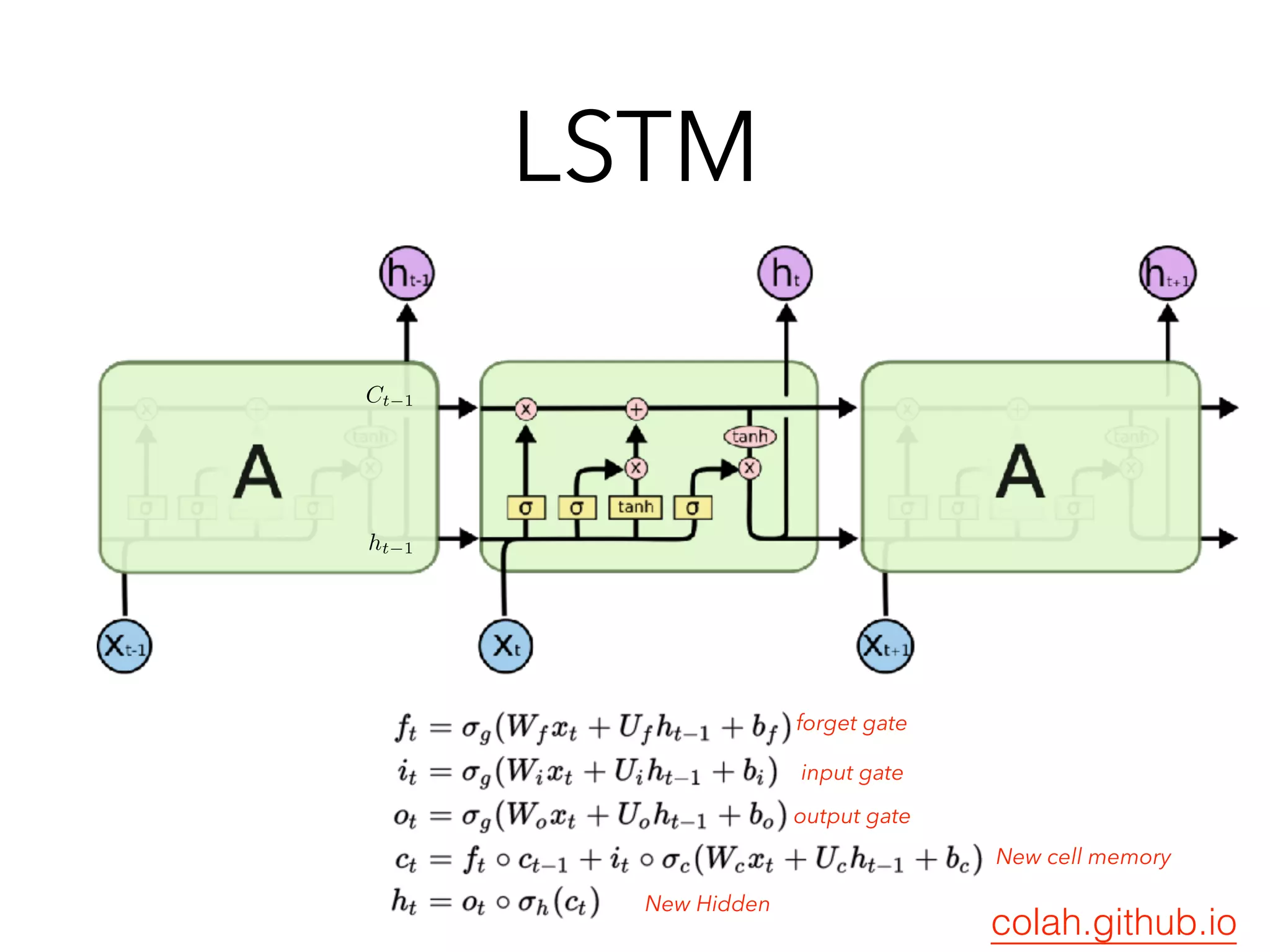

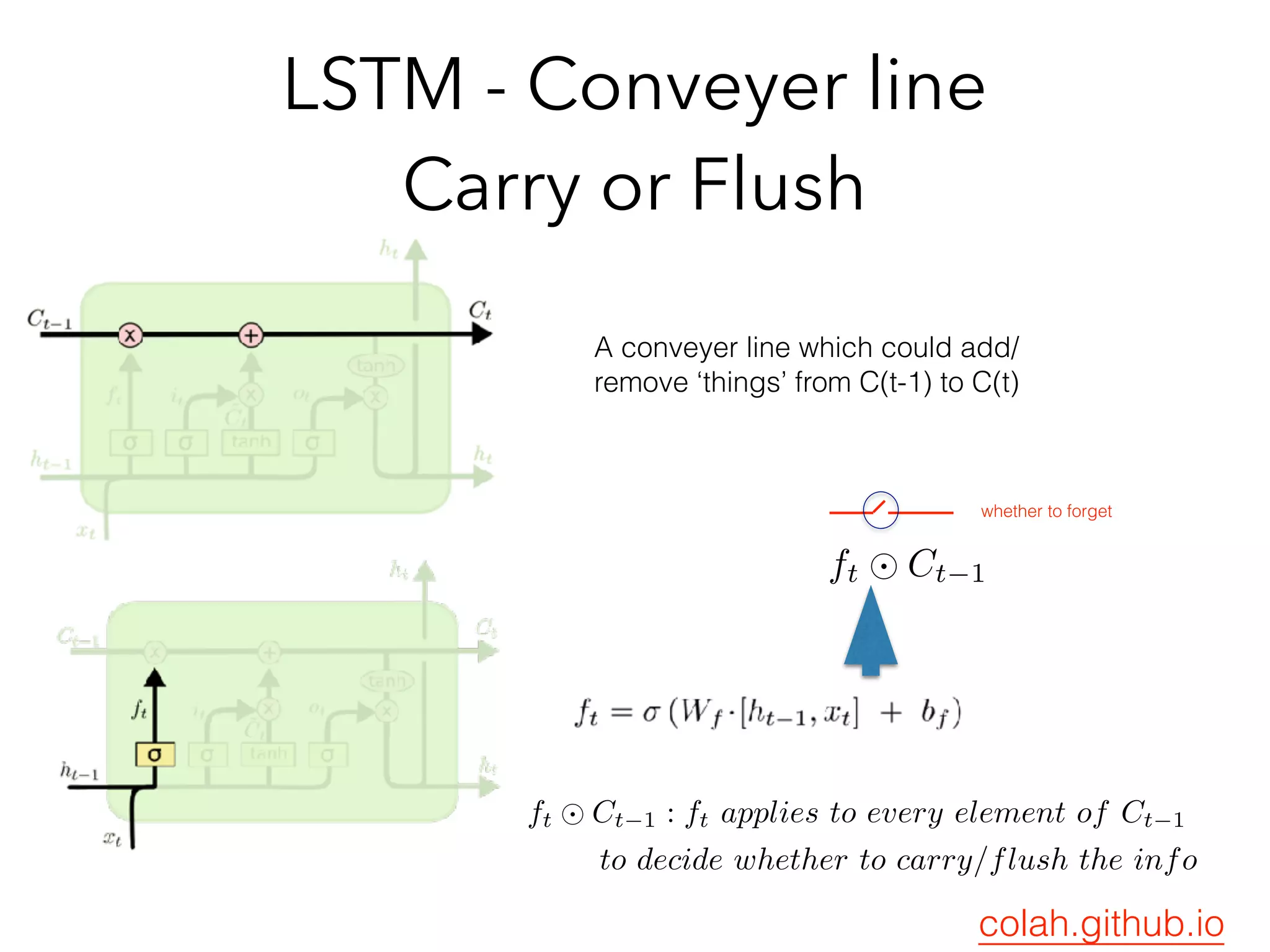


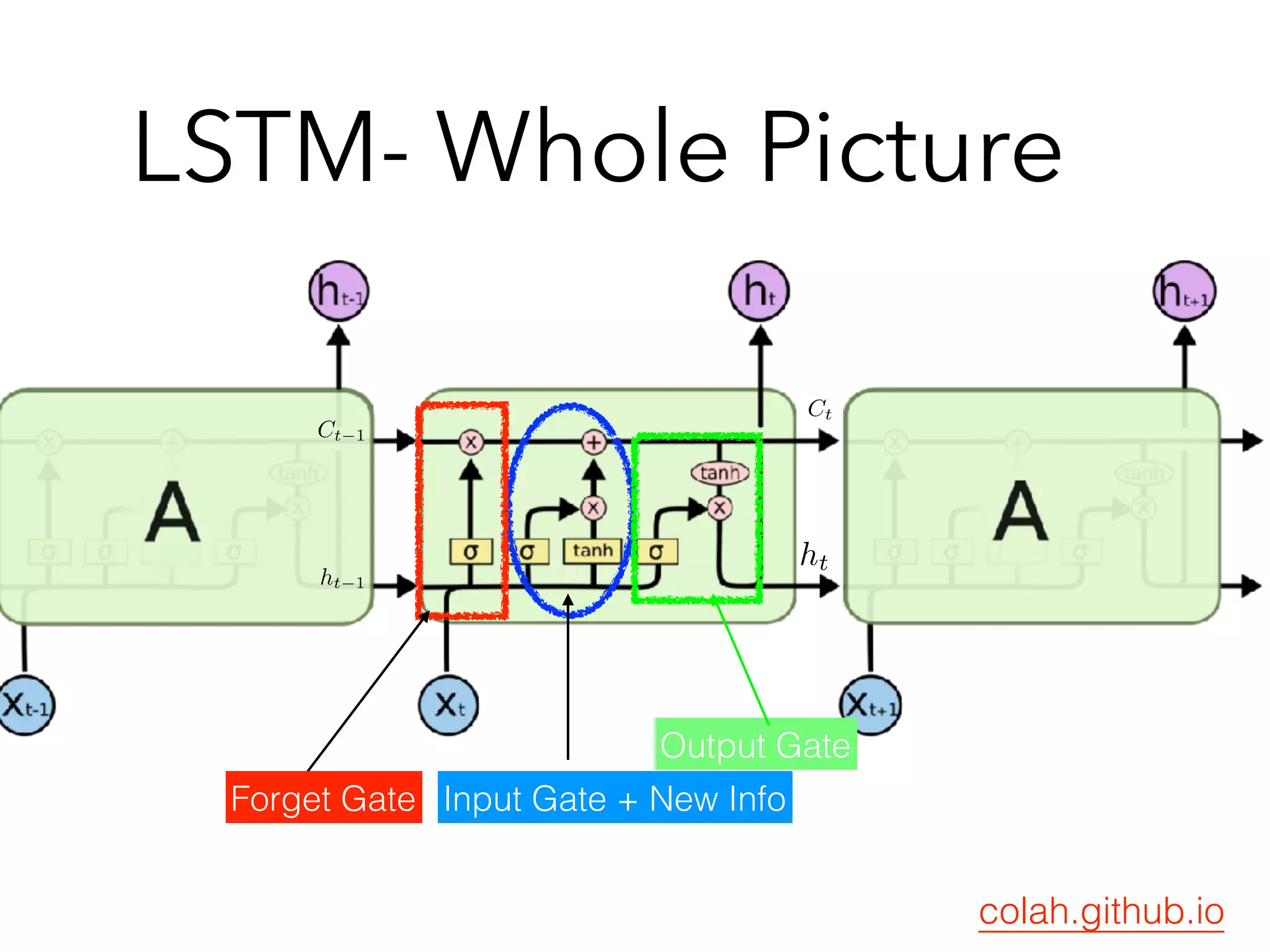


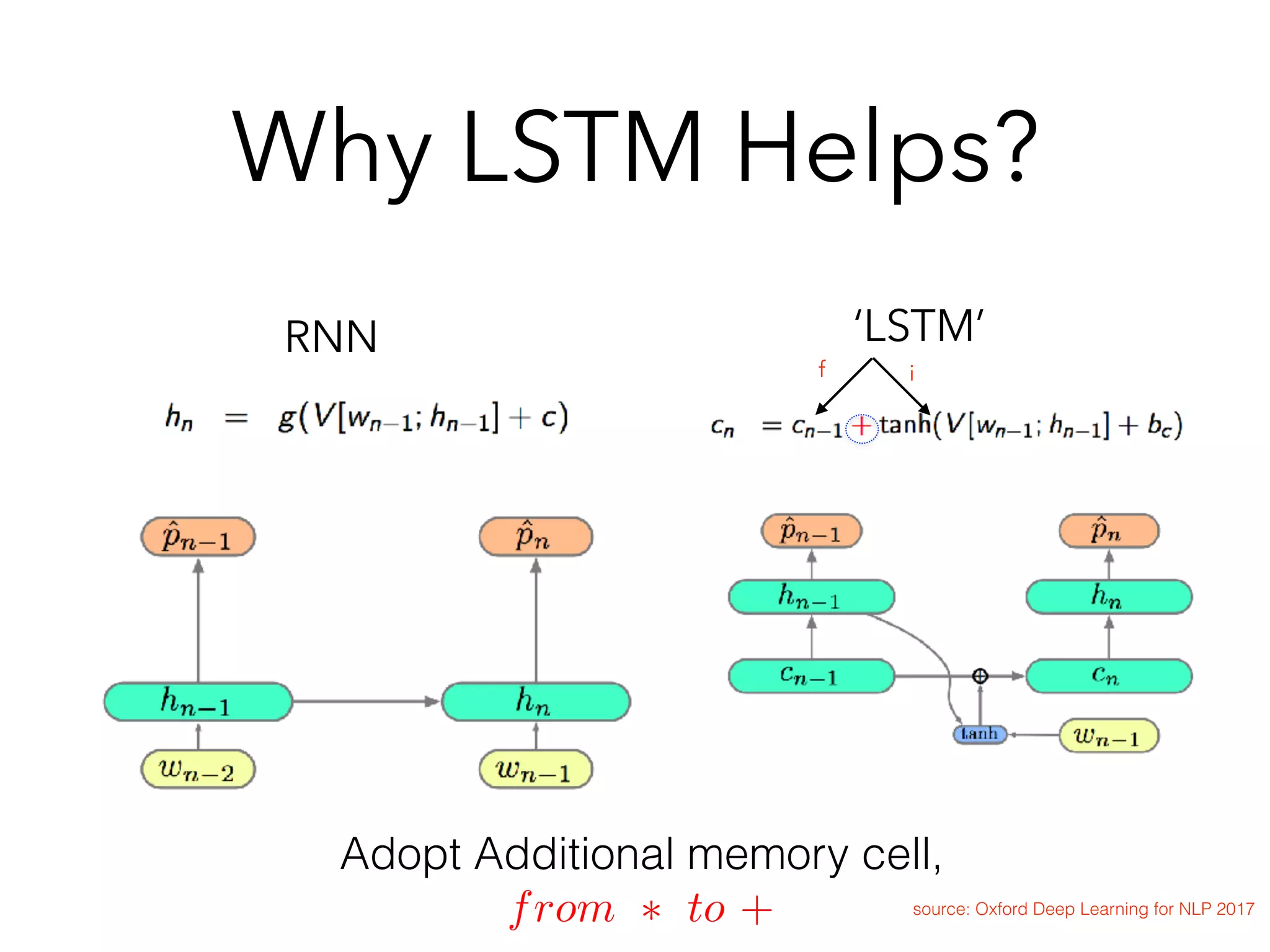


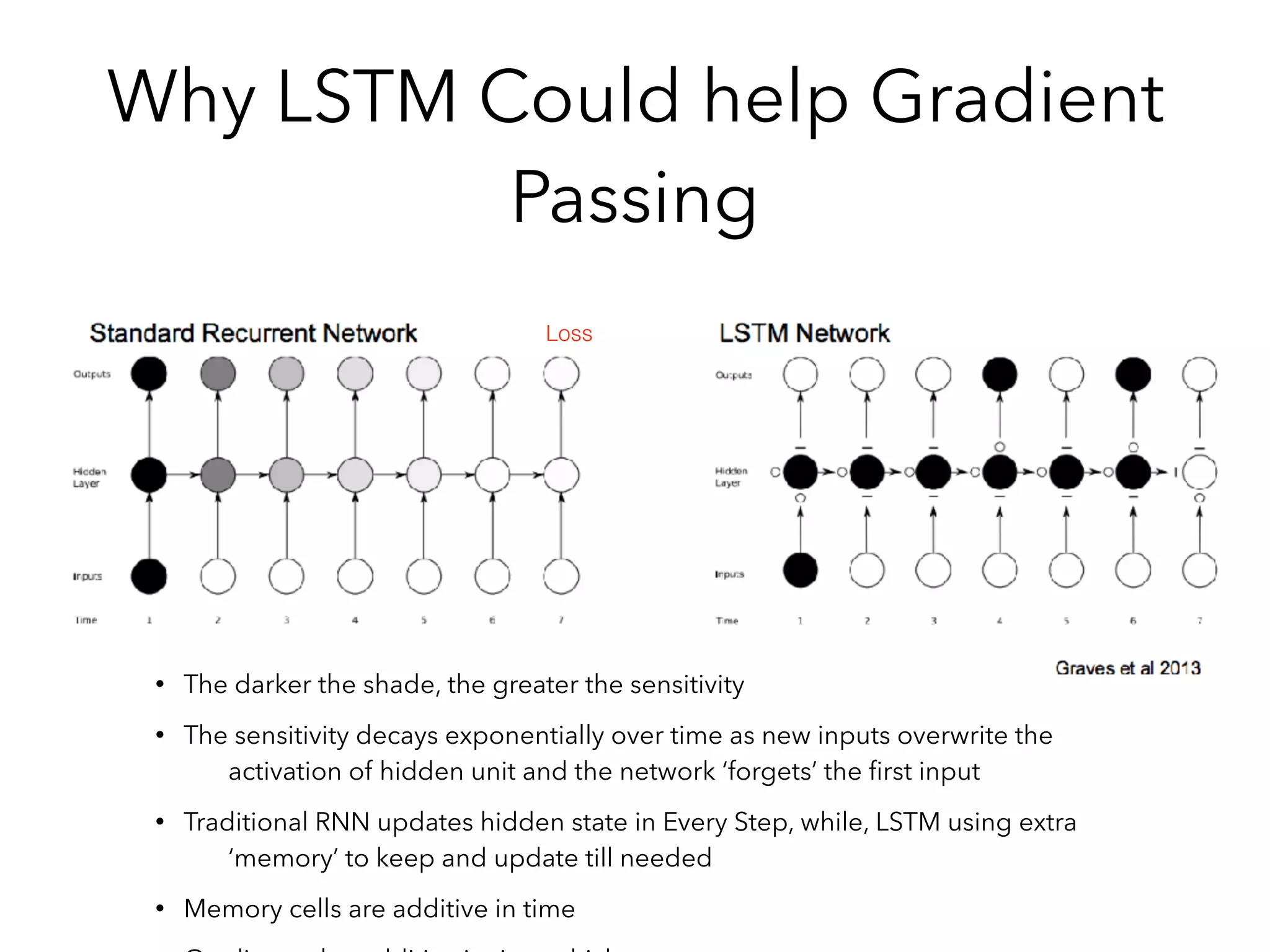
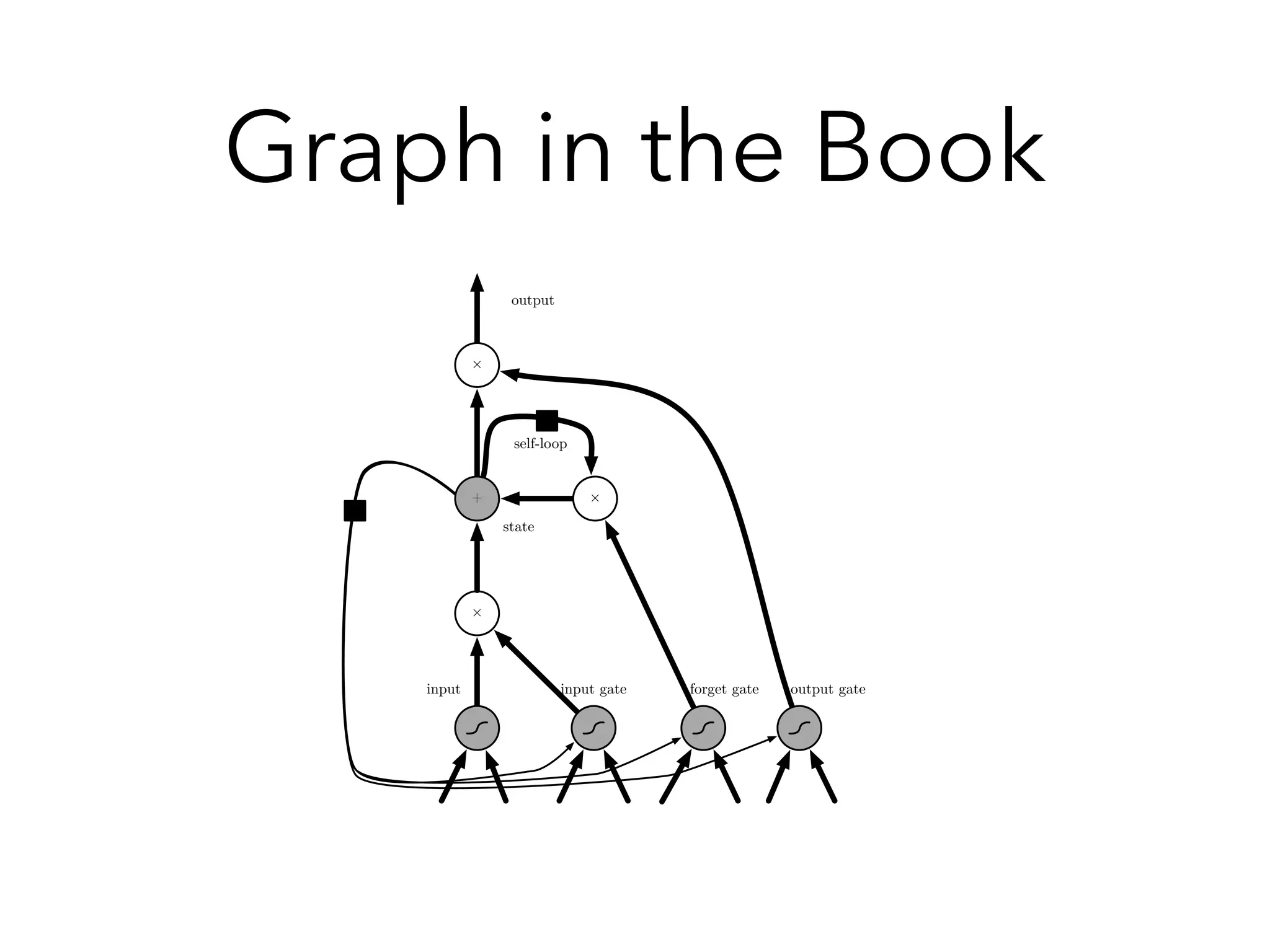

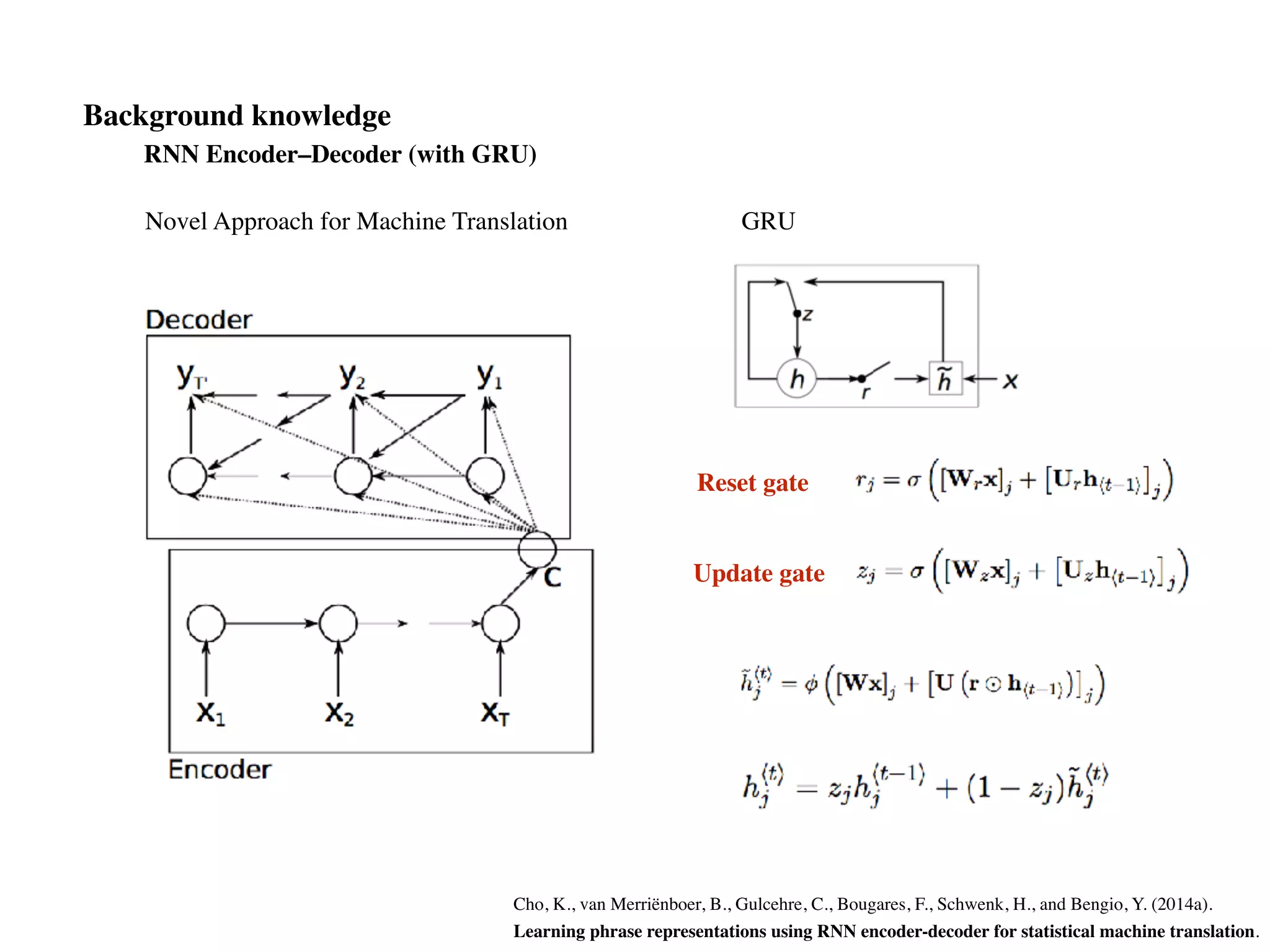
![Variation : GRU
(Parameter reduction)
ht
= (1 zt
) • ht 1
+ zt
• ˜ht
LSTM is good but seems redundant?
Do we need so many gates ?
Do we need Hidden State AND Cell Memory to remember ?
zt
is a gate
˜ht
= tanh(Wxt
+ Uht 1
+ b)
vs.
˜ht
= tanh(Wxt
+ U(rt
• ht 1
) + b) rt
is a gate
More previous state info or More new Info ? Z^t will decide
zt
= (Wz[xt
; ht 1
] + bz) rt
= (Wr[xt
; ht 1
] + br)
can’t forget](https://image.slidesharecdn.com/chapter10170505l-170612022817/75/Deep-Learning-Recurrent-Neural-Network-Chapter-10-66-2048.jpg)



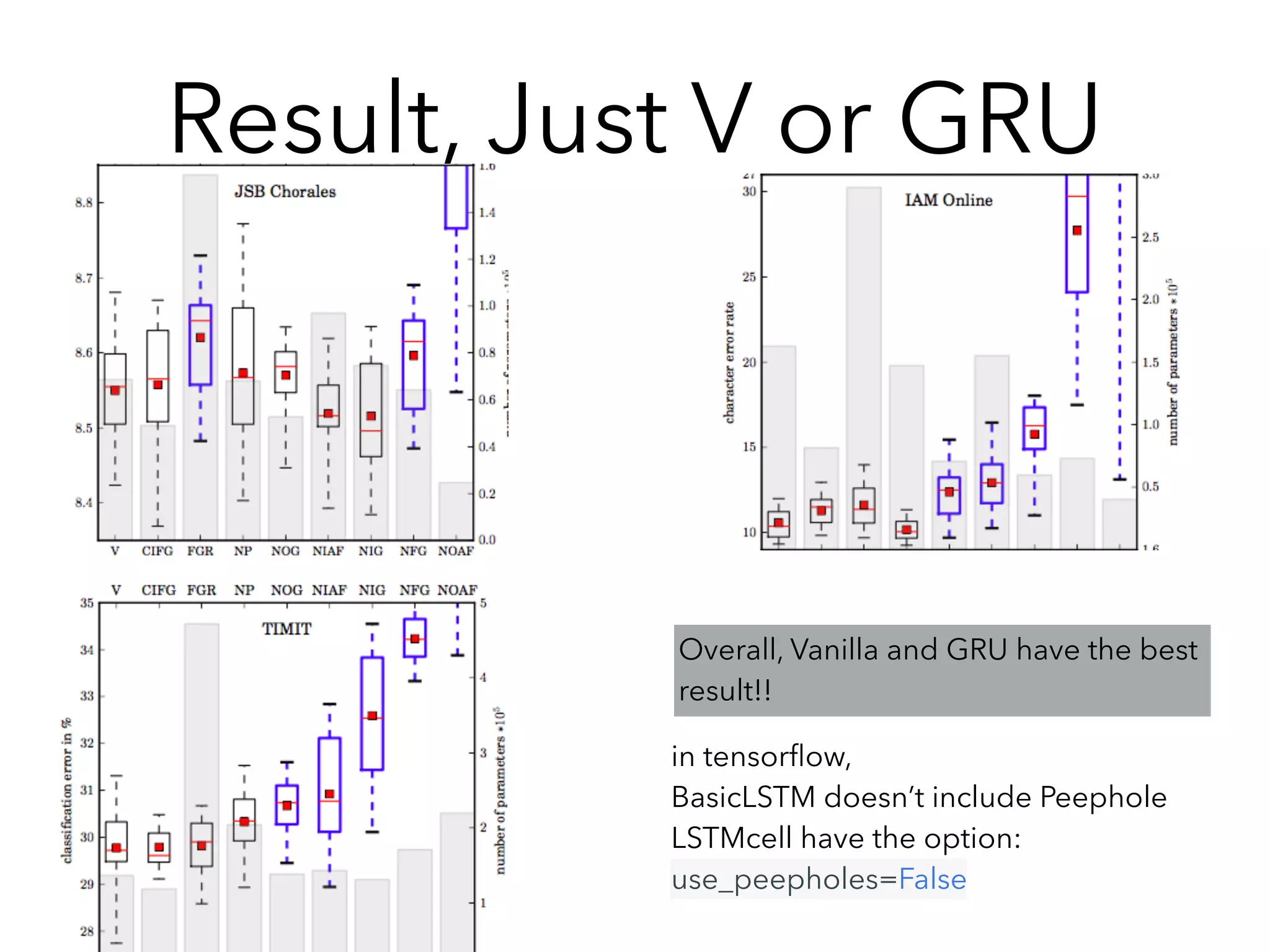



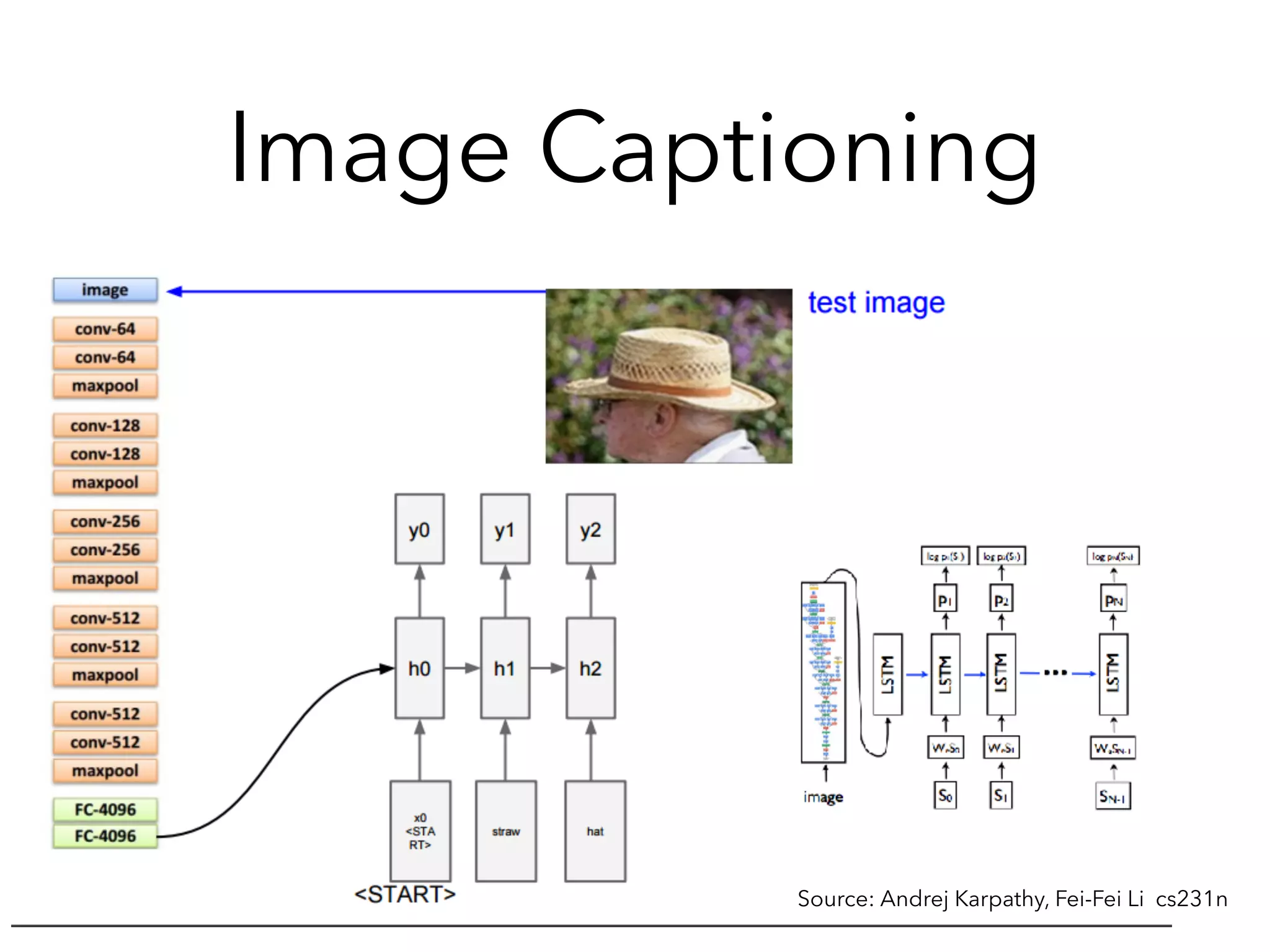
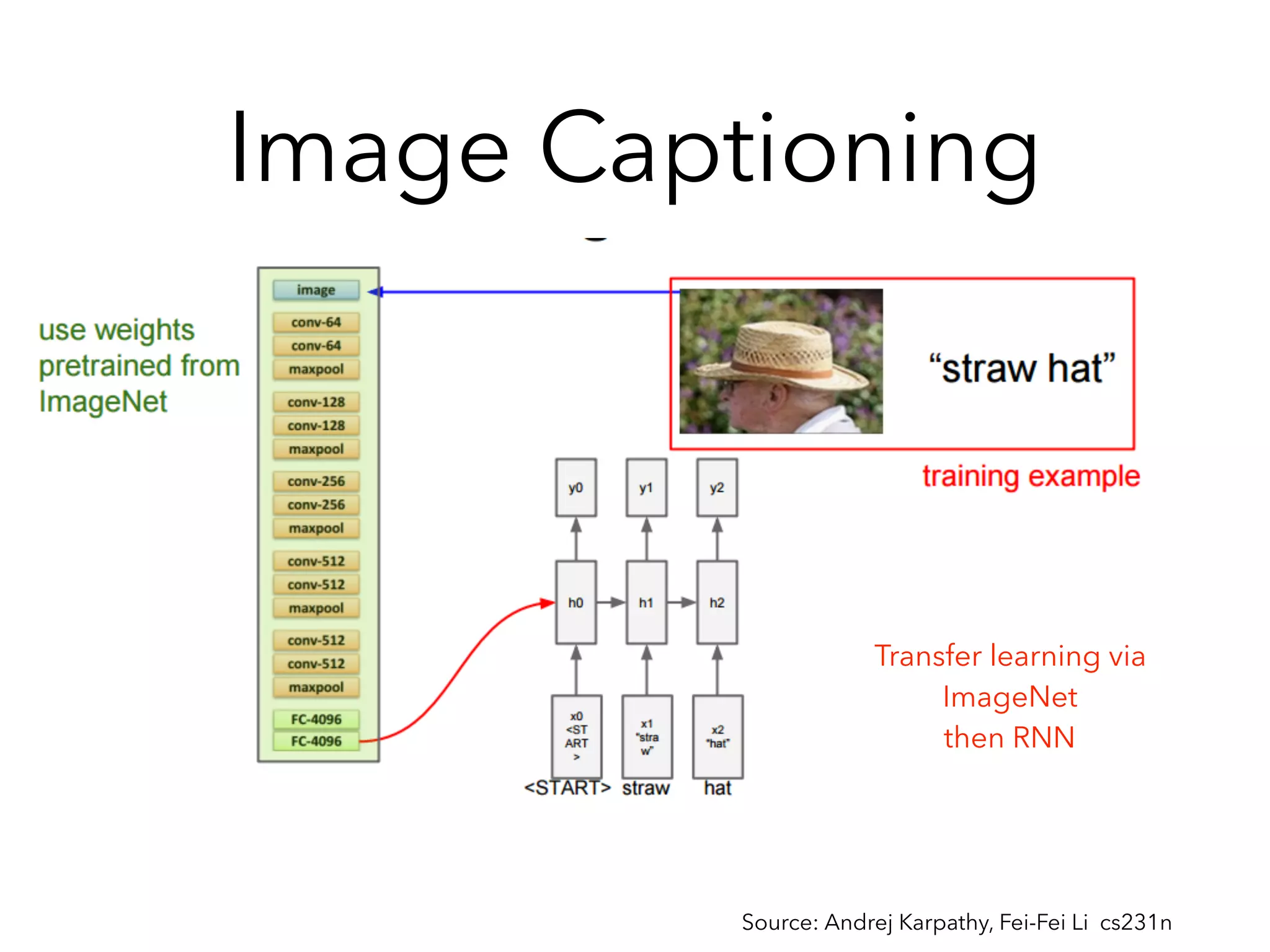





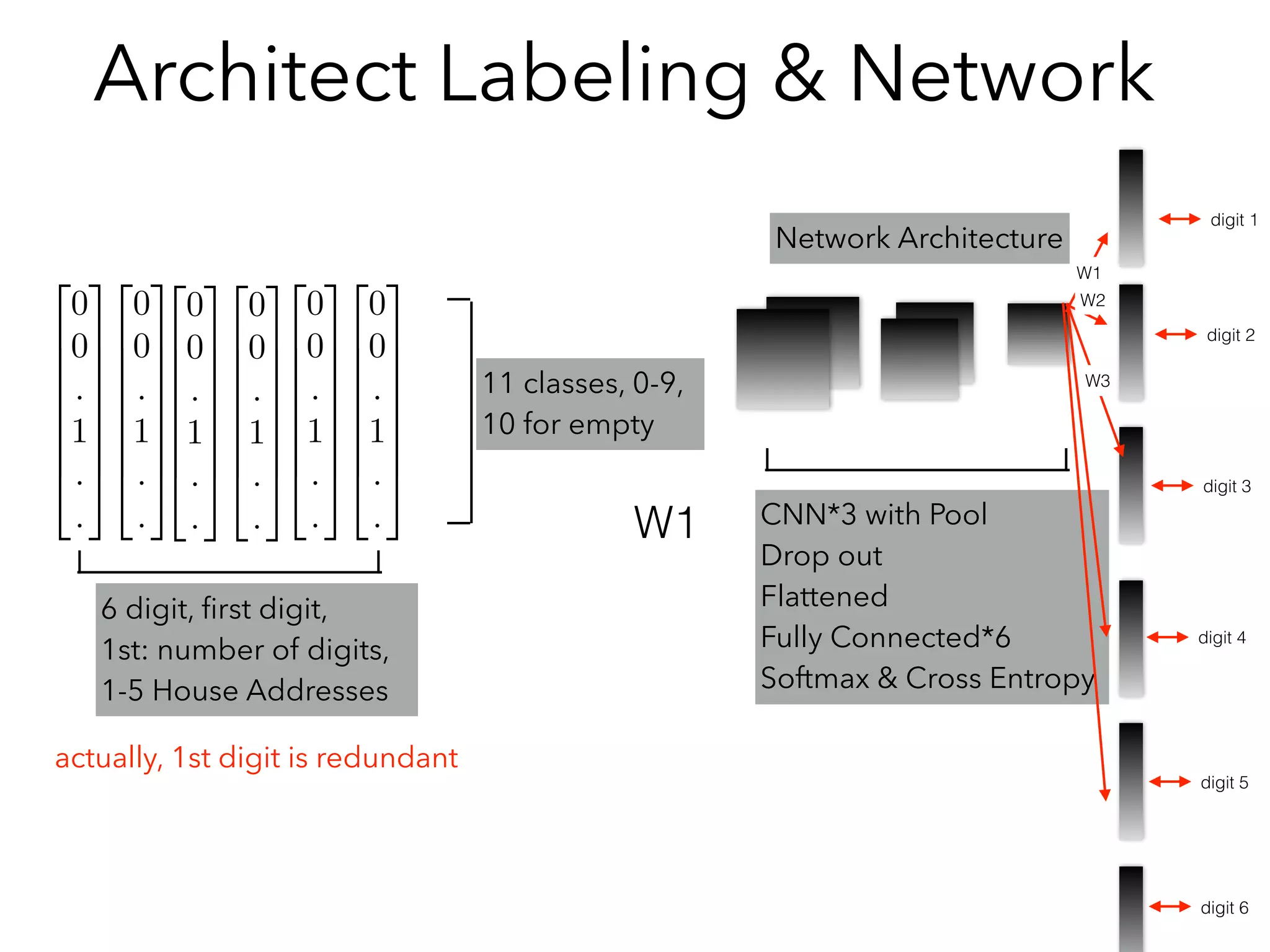
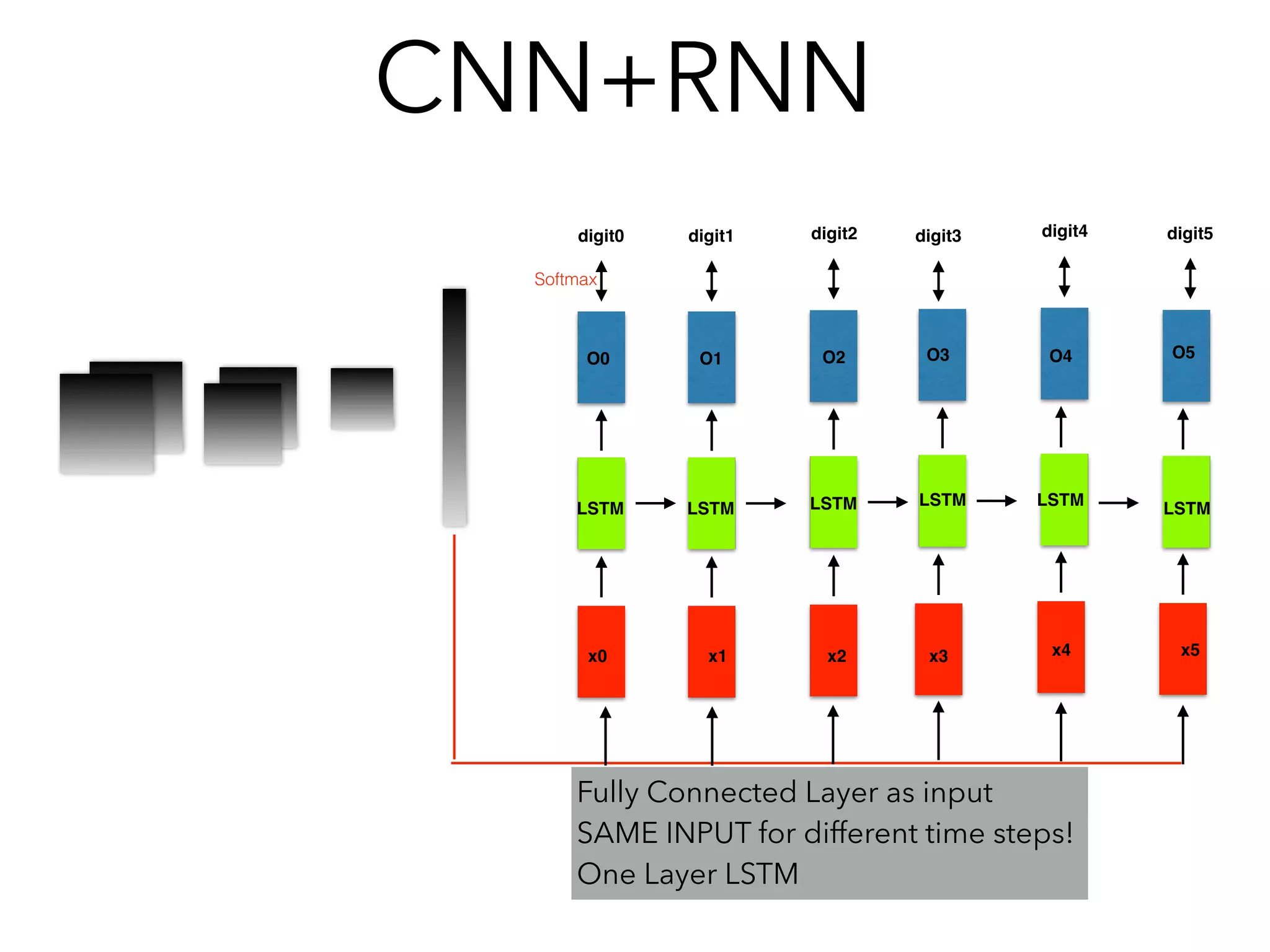
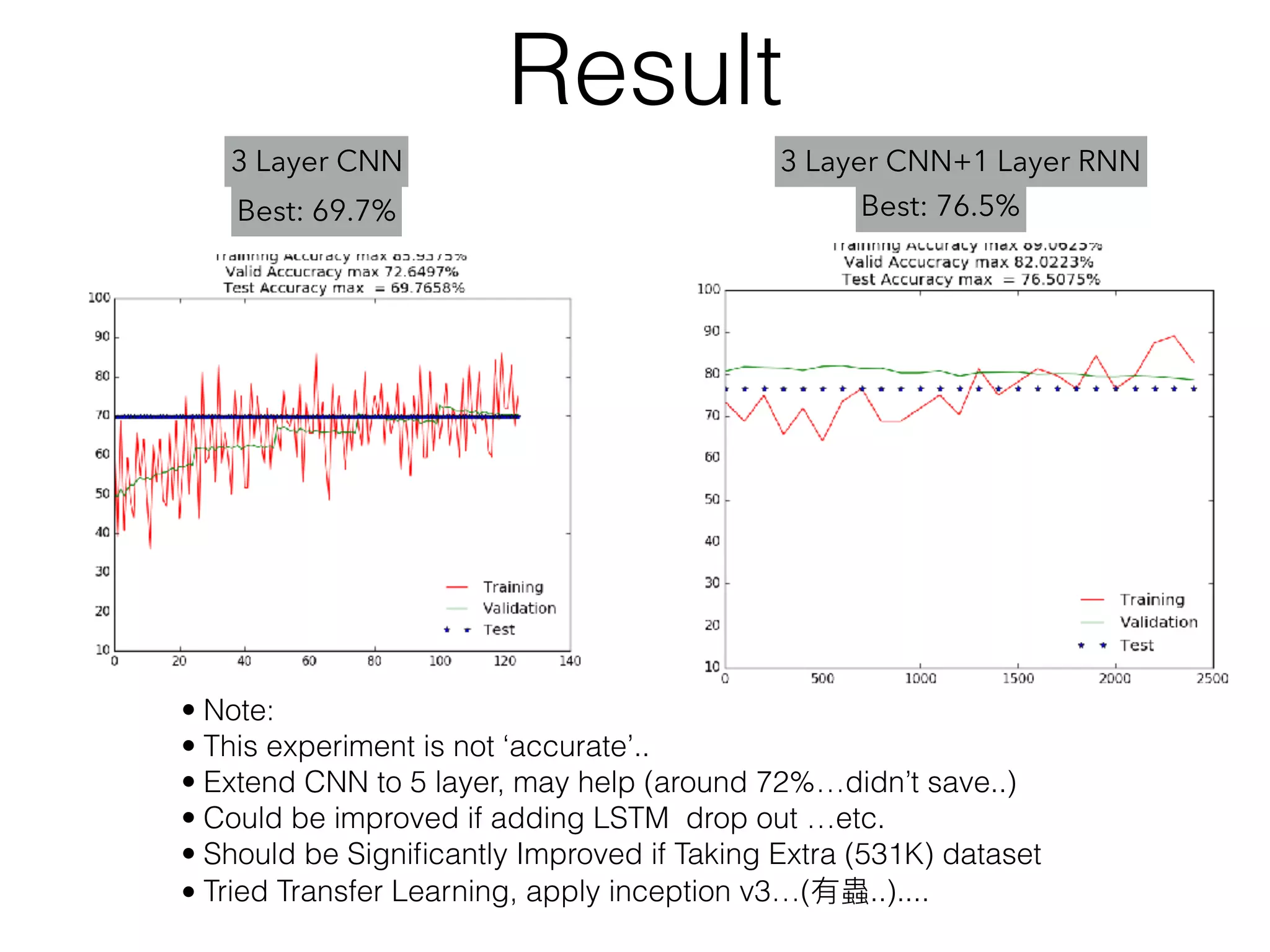
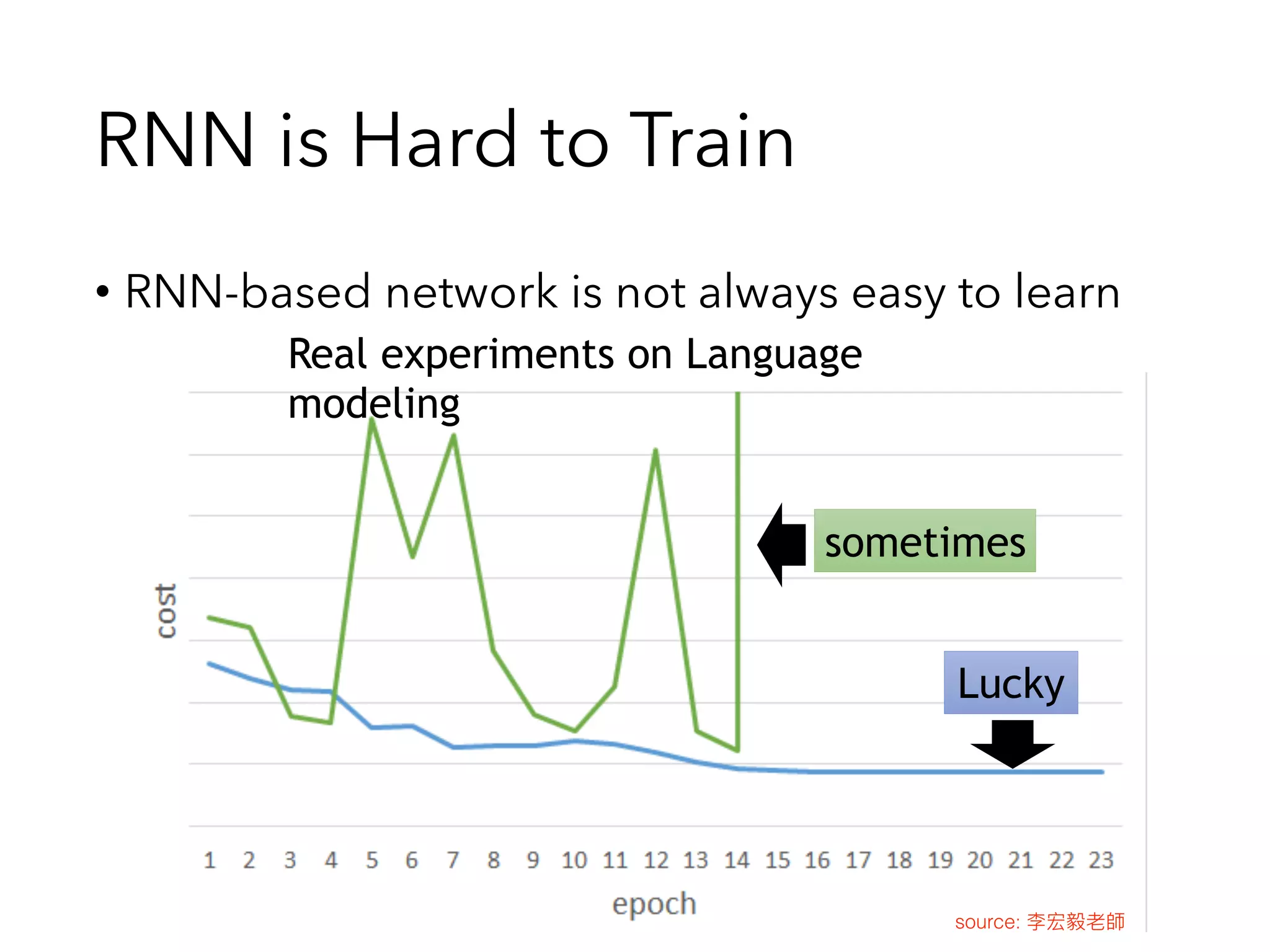
![Some Experience(tensorflow)
• Input: [Batch, Time_steps, Input_length]
• If for a Image: Time_steps = Height, Input Length= Width
• Tf.unstack (input, 1) = list [[Batch, Input_length],[Batch,
Input_length], ……
• Experience Using CNN+RNN for SVHN:
• Image - CNN - Flatten Feature Vectors (No go to Softmax)
• [Feature Vector, Feature Vector, Feature Vector…]as Inputs
Time_step1
Time_step2
a list of time step
Feature Vector*6](https://image.slidesharecdn.com/chapter10170505l-170612022817/75/Deep-Learning-Recurrent-Neural-Network-Chapter-10-84-2048.jpg)



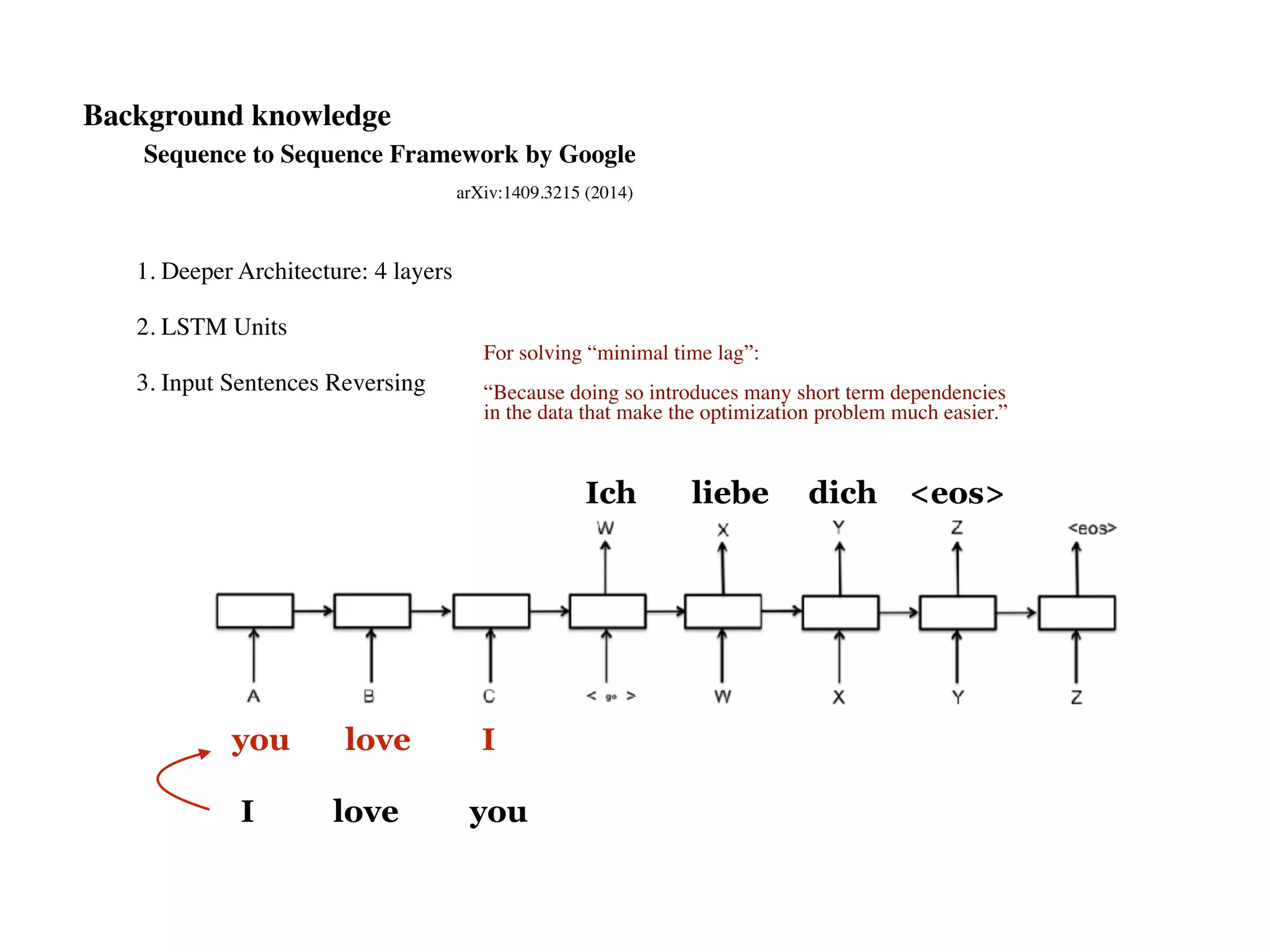
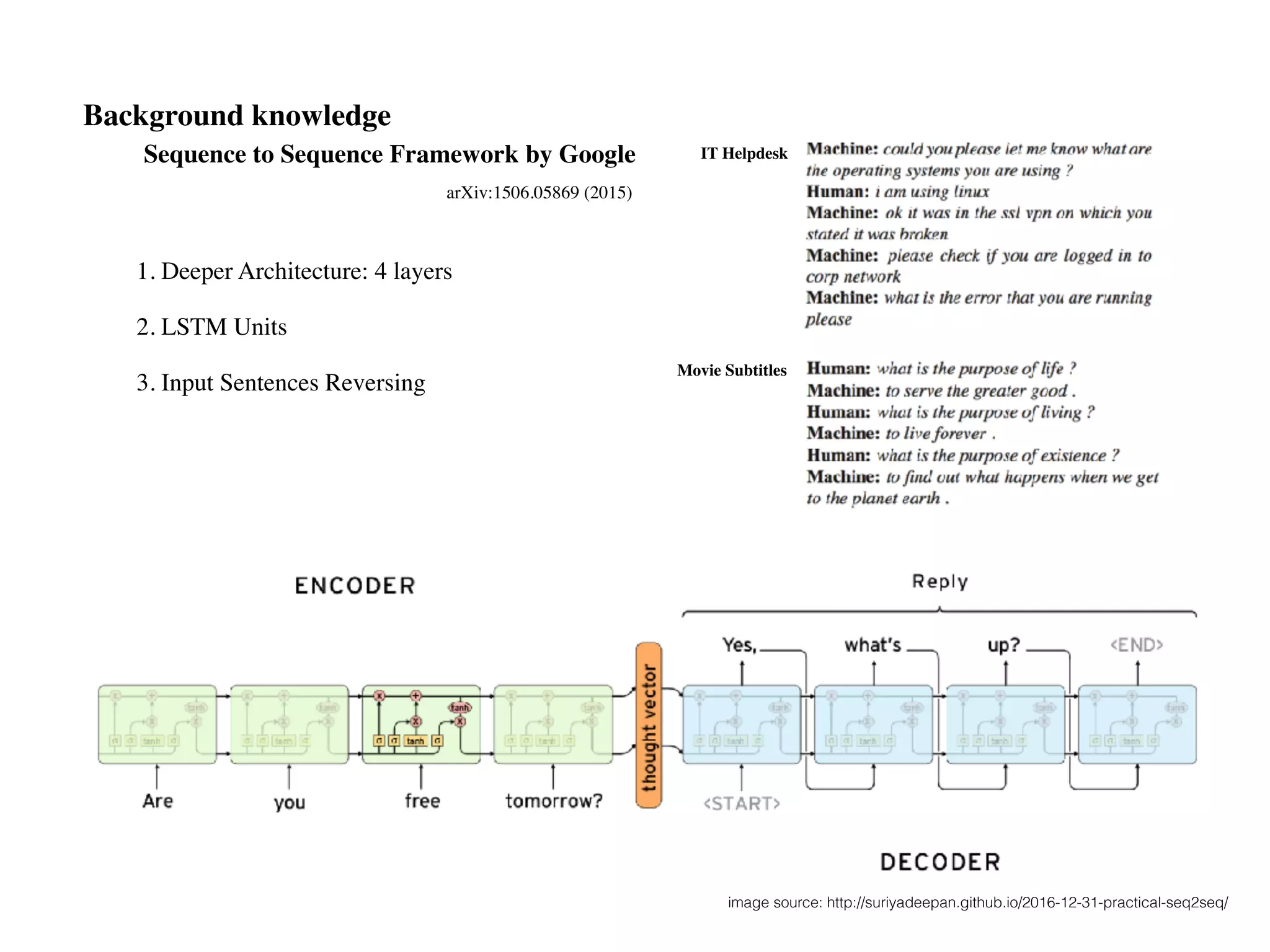
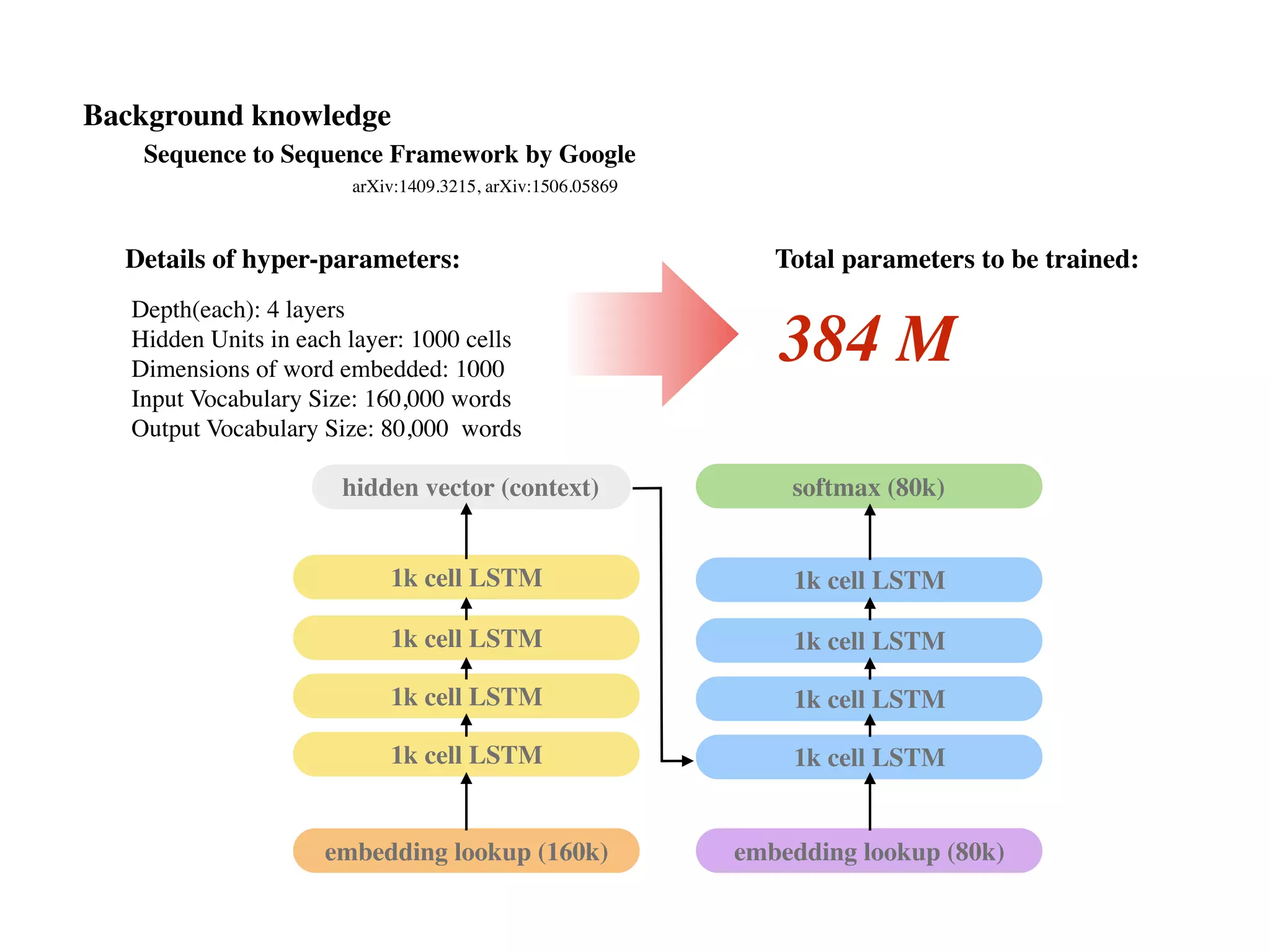
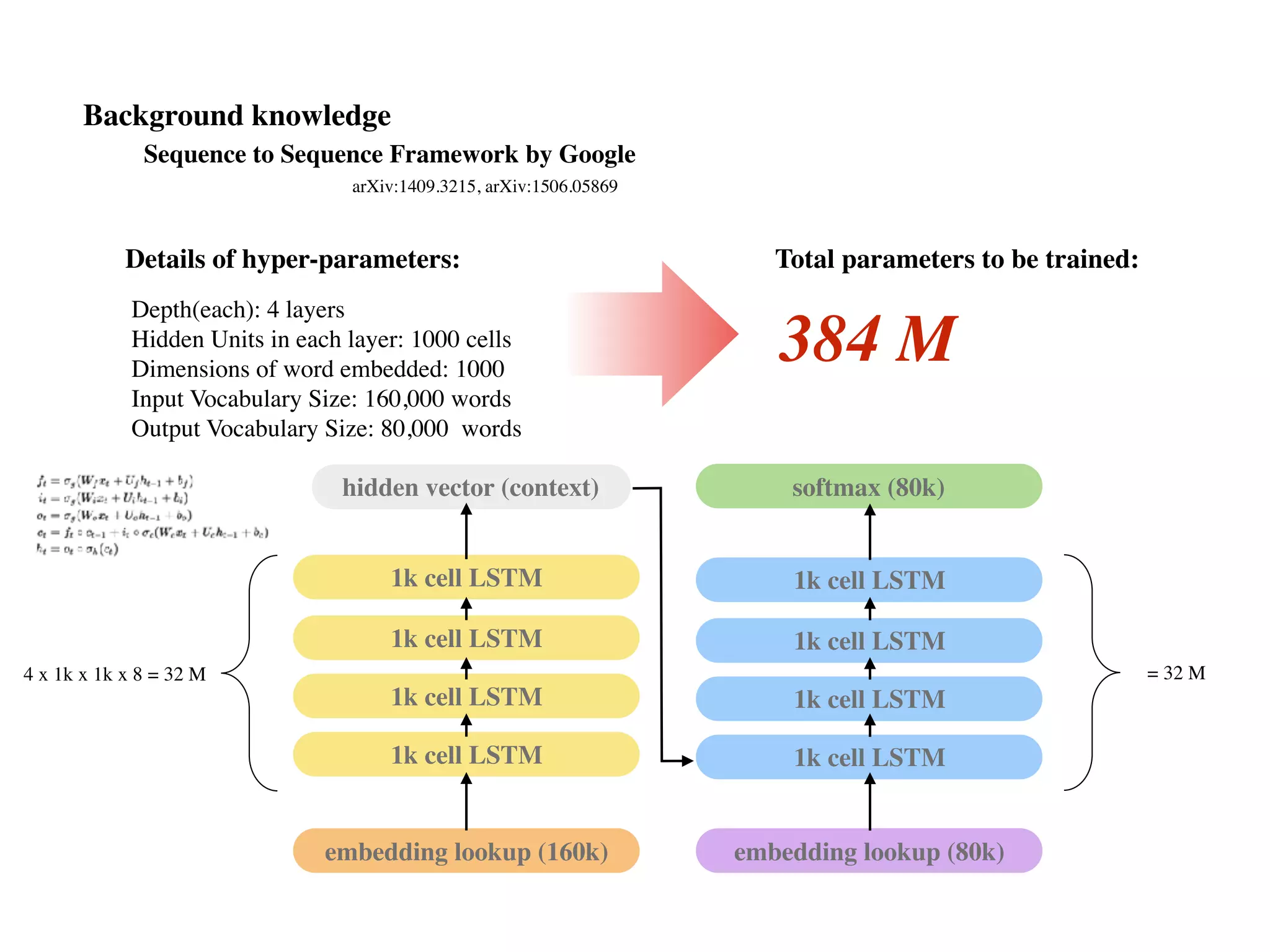
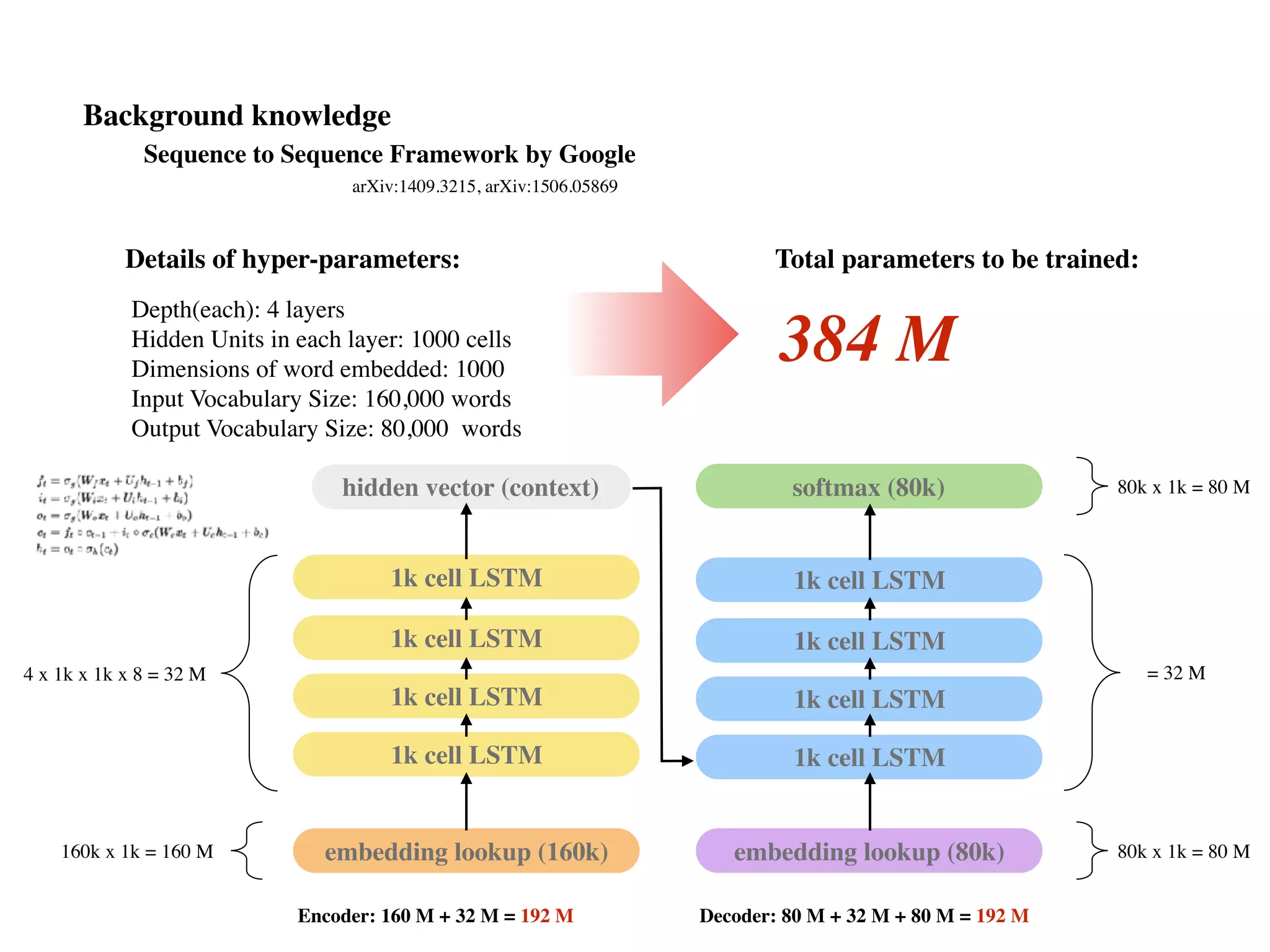
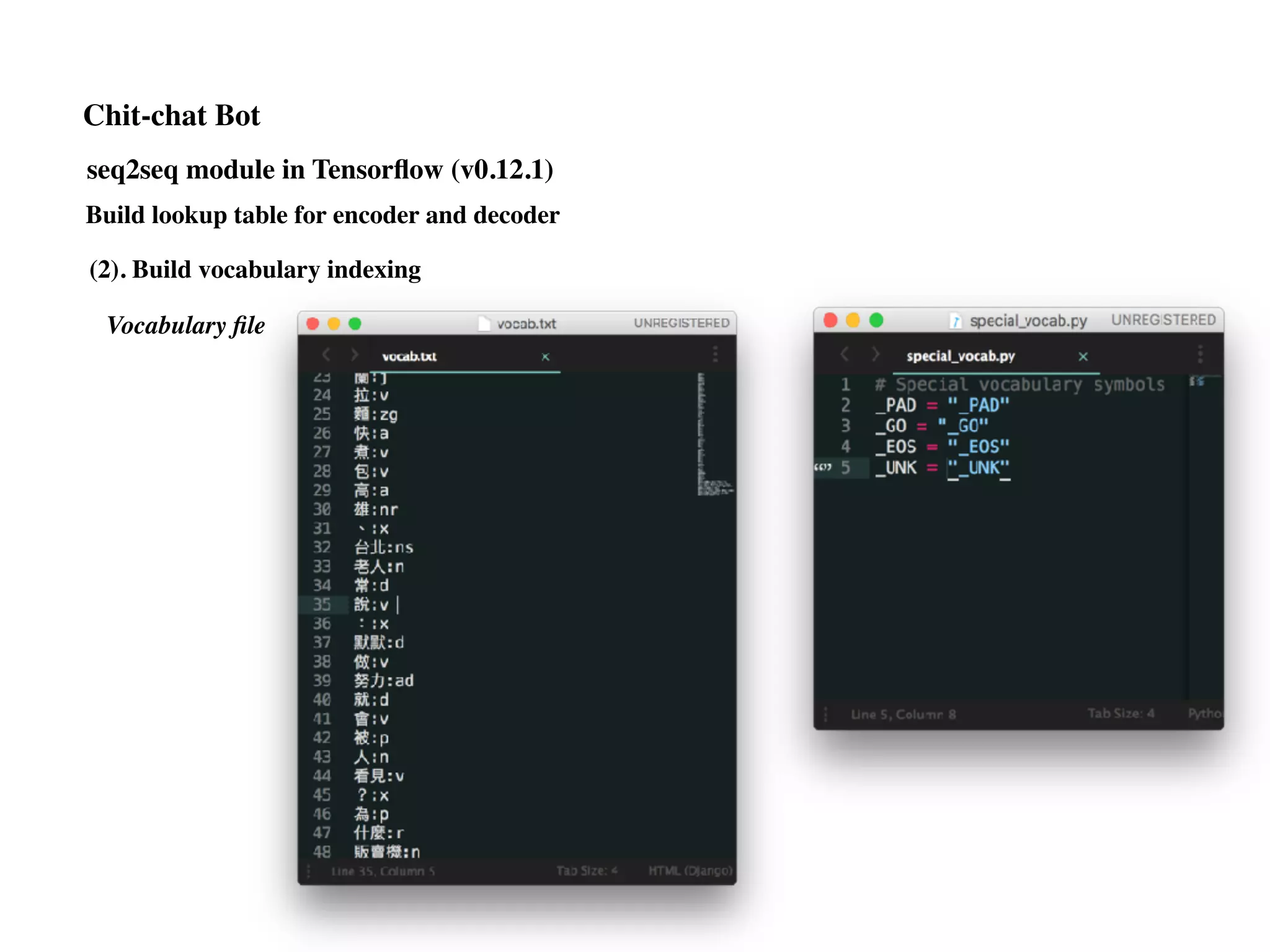
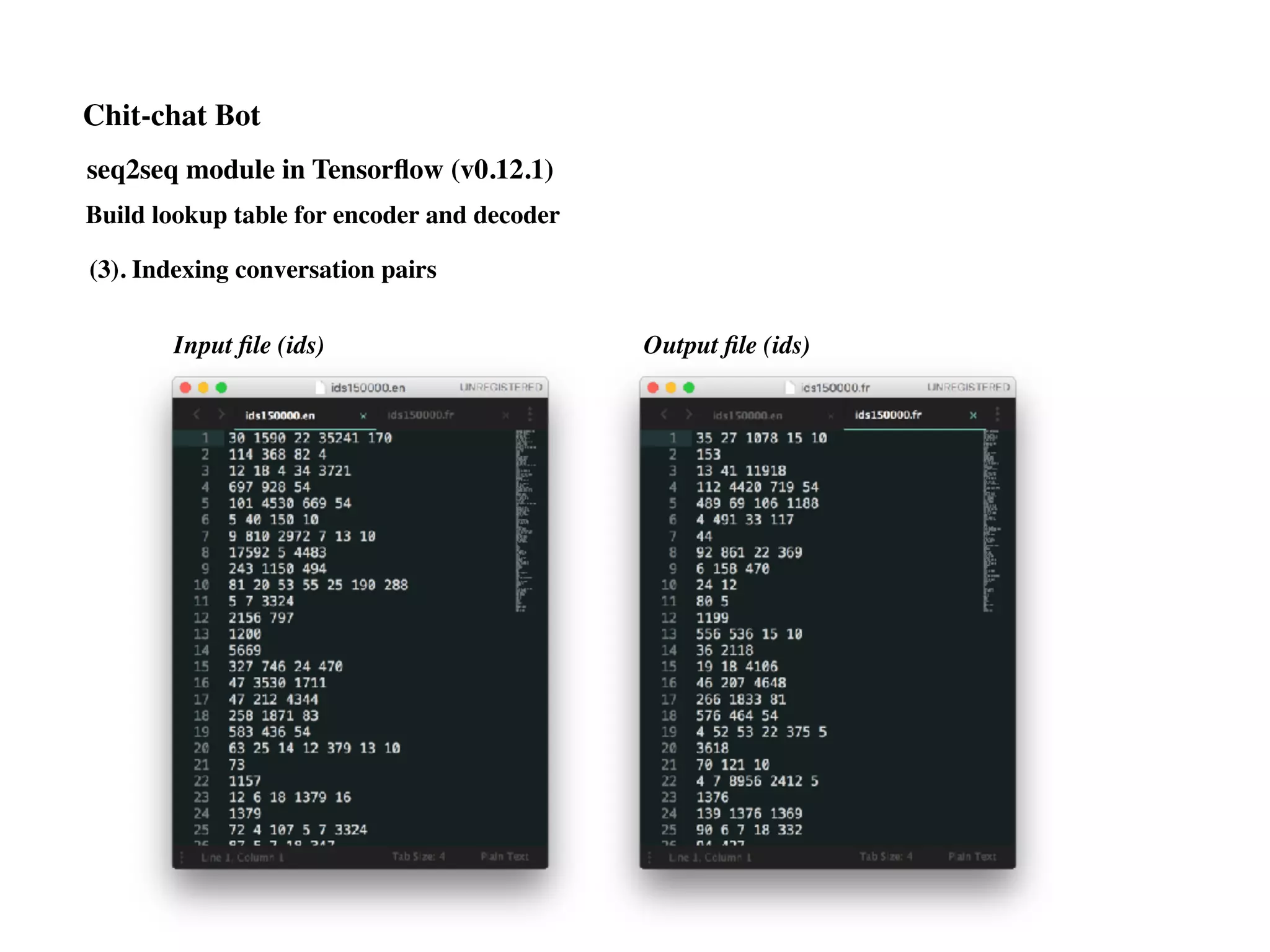
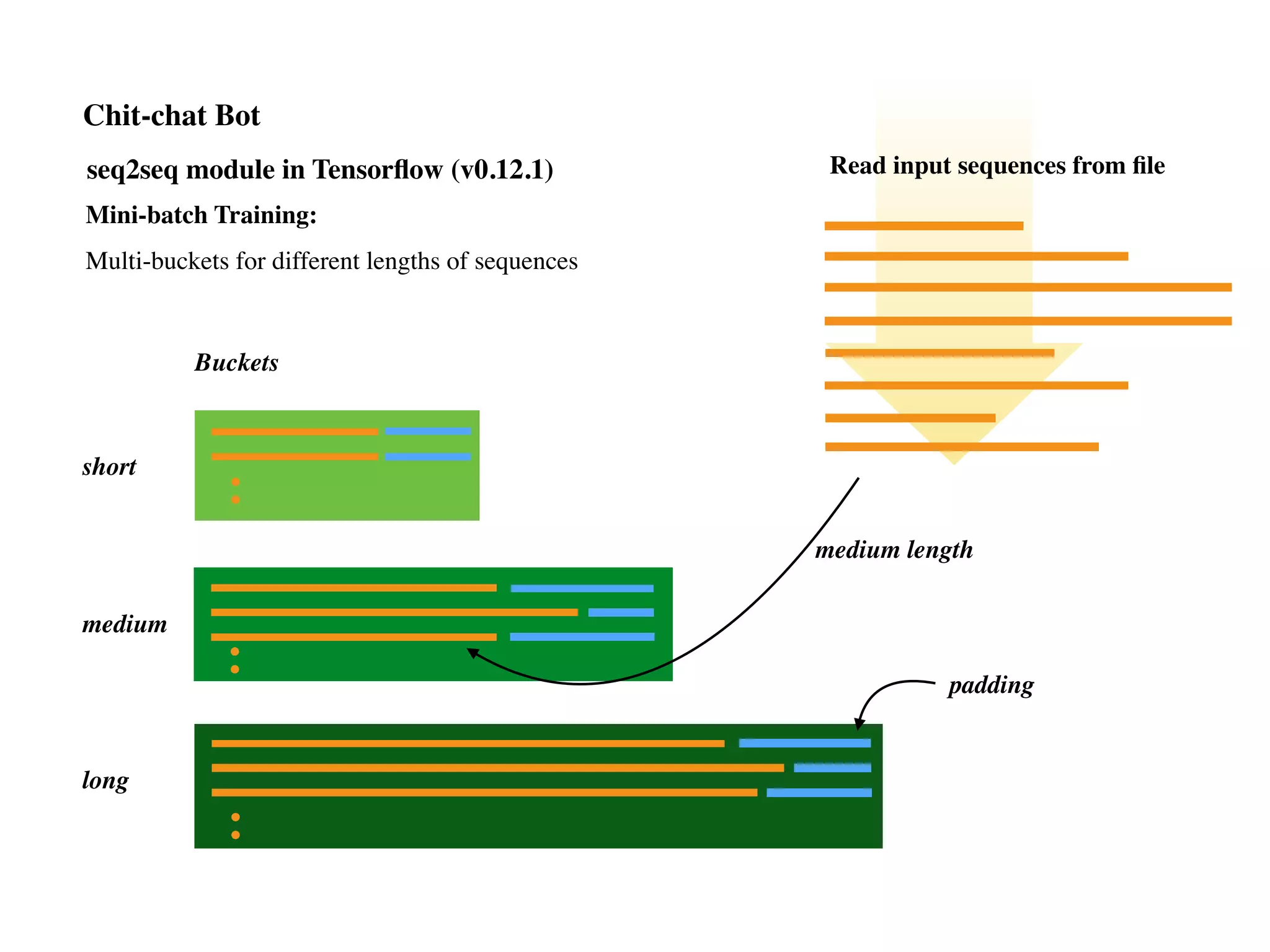
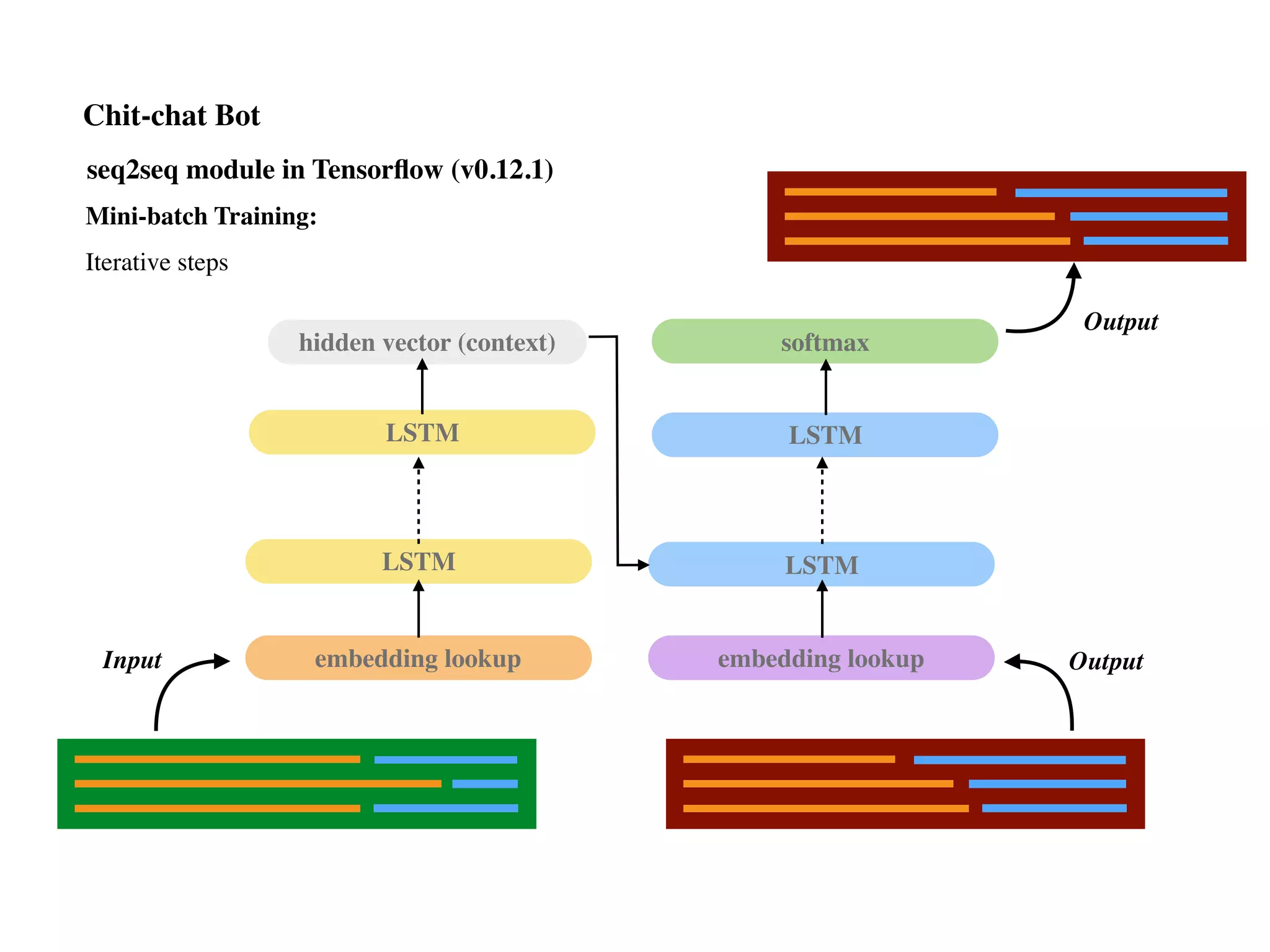
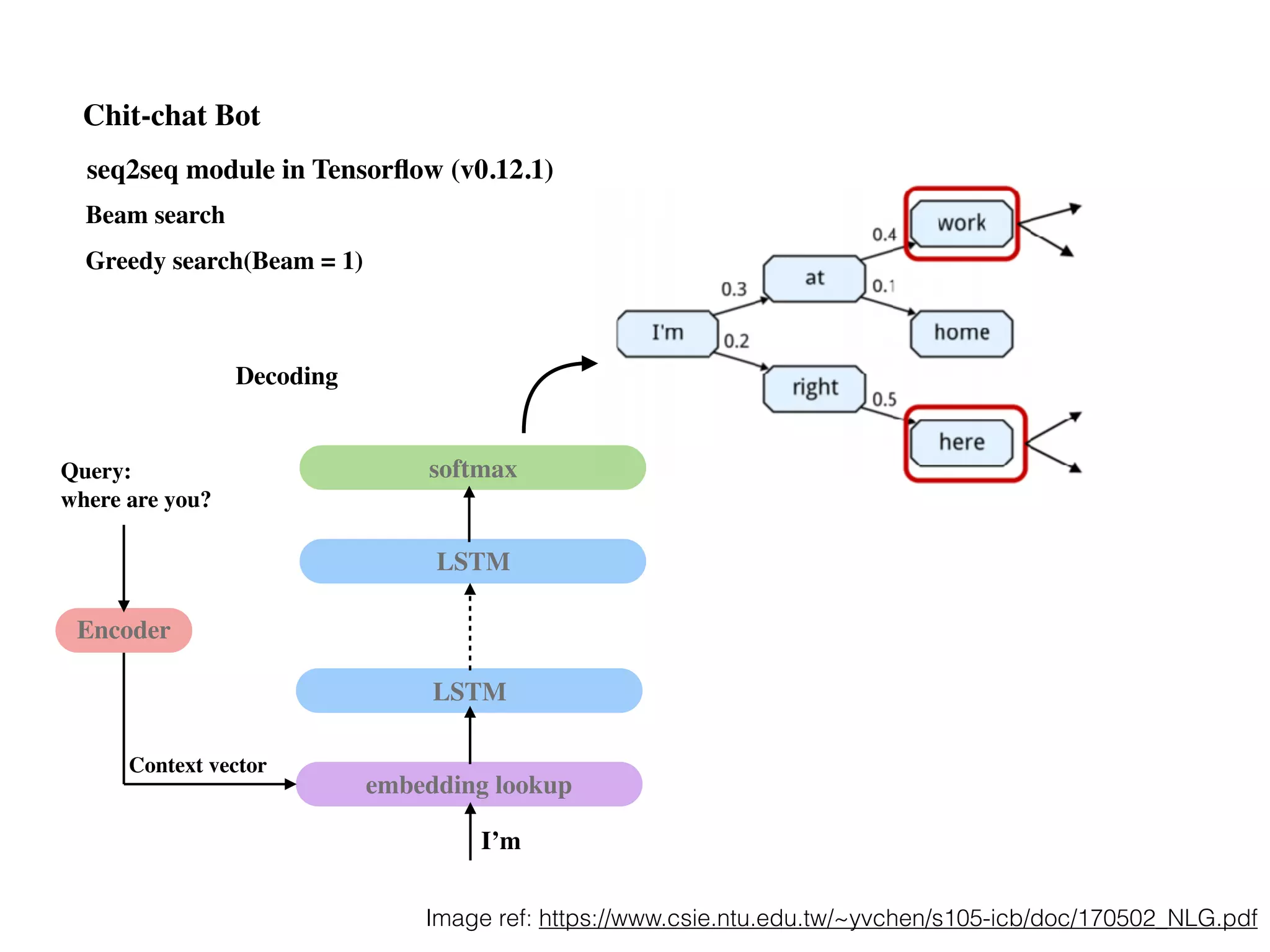
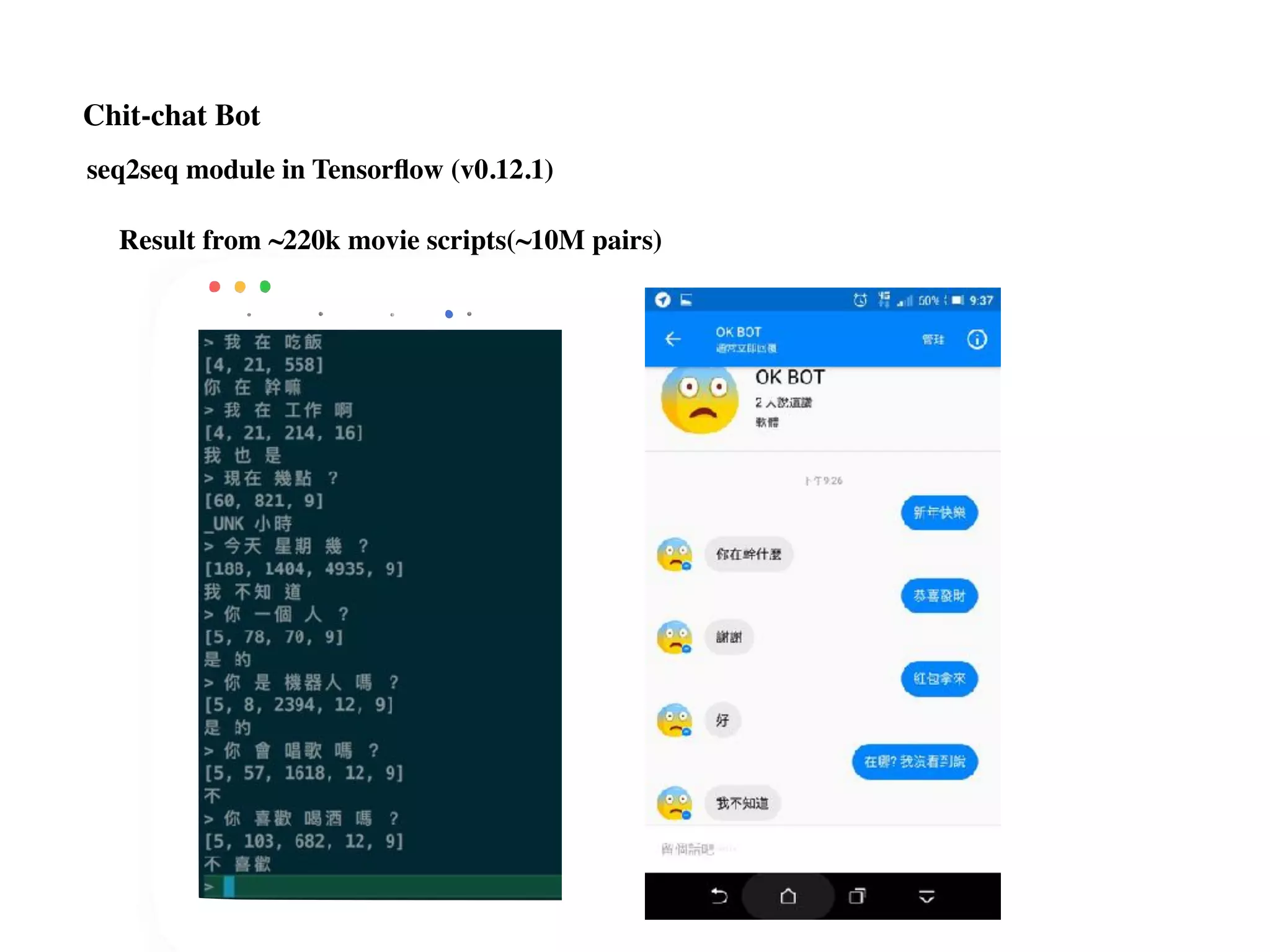
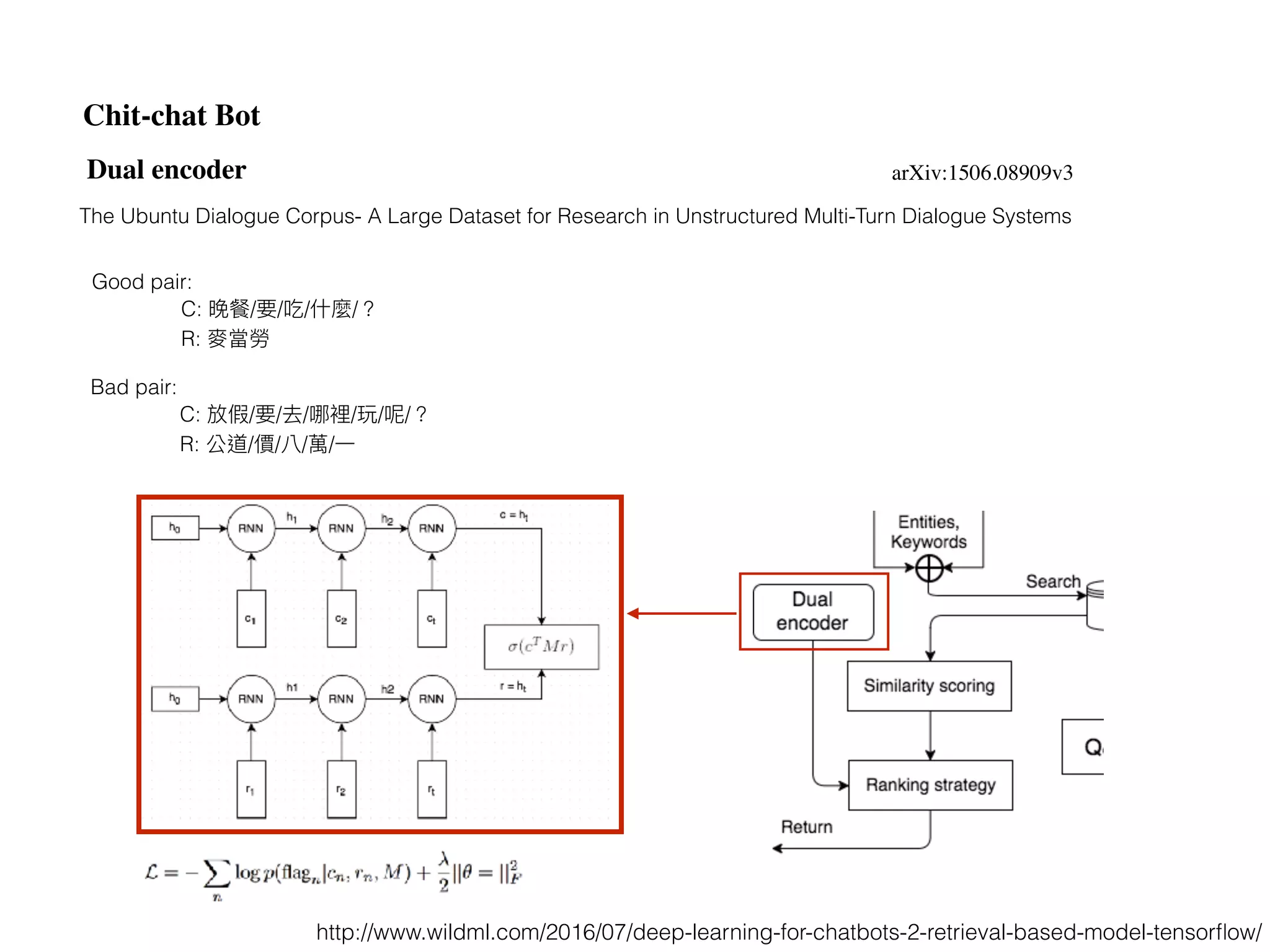
![seq2seq module in Tensorflow (v0.12.1)
from tensorflow.models.rnn.translate import seq2seq_model
$> python translate.py
--data_dir [your_data_directory] --train_dir [checkpoints_directory]
--en_vocab_size=40000 --fr_vocab_size=40000
$> python translate.py --decode
--data_dir [your_data_directory] --train_dir [checkpoints_directory]
https://www.tensorflow.org/tutorials/seq2seq
Training
Decoding
Data source for demo in tensorflow:
WMT10(Workshop on statistical Machine Translation) http://www.statmt.org
Data source for chit-chat bot:
Movie scripts, PTT corpus
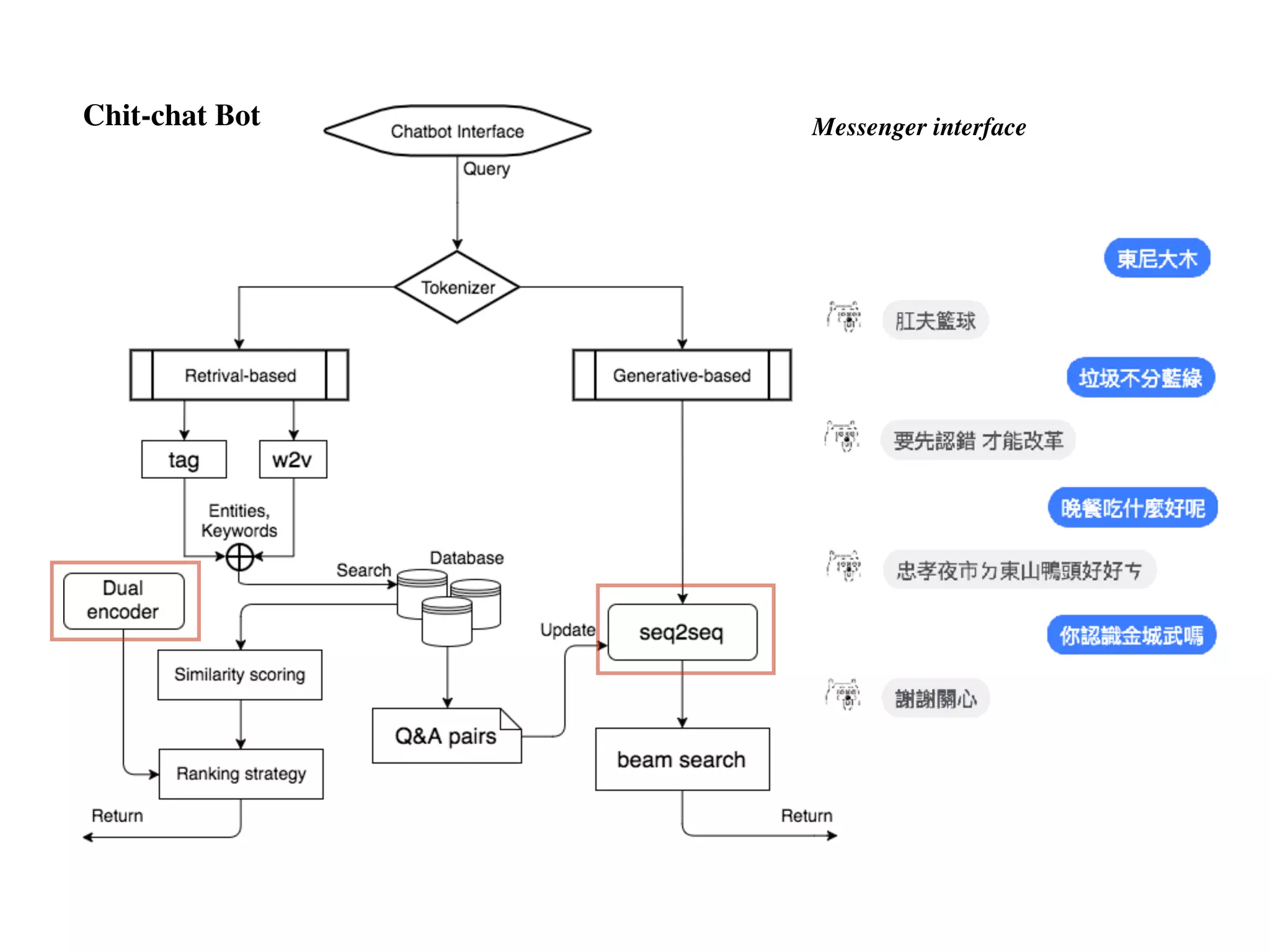
Chit-chat Bot
https://google.github.io/seq2seq/
new version](https://image.slidesharecdn.com/chapter10170505l-170612022817/75/Deep-Learning-Recurrent-Neural-Network-Chapter-10-96-2048.jpg)


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

