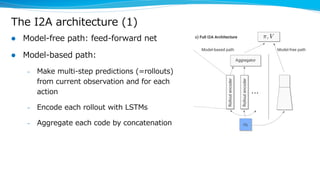
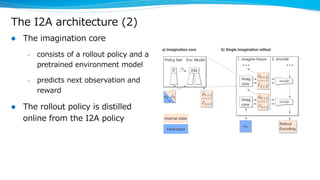
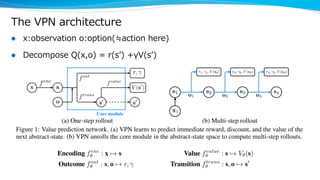
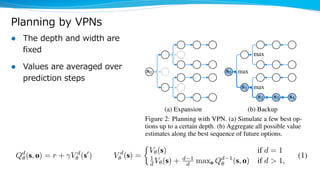
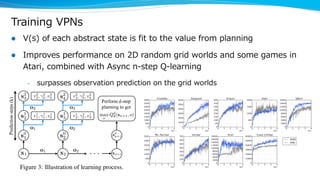
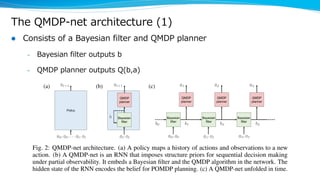
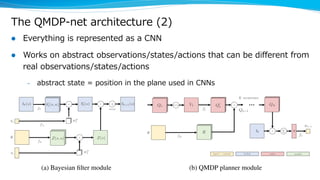
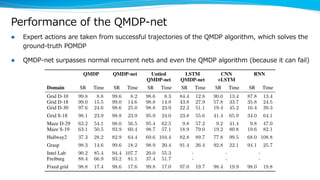
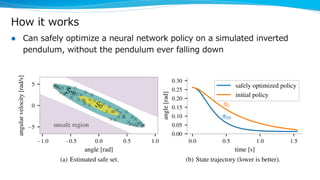
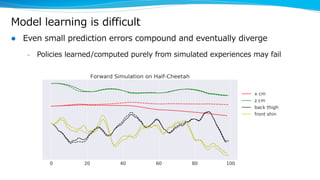
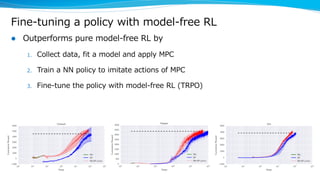
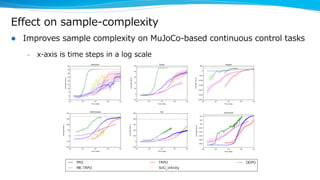
Model-based reinforcement learning techniques were presented that use learned models to improve upon model-free deep reinforcement learning. Several papers augmented deep networks with model-based components like planners or simulators to leverage predictions and reduce sample complexity. Techniques included using model rollouts to augment state representations, learning abstract state representations to simplify value prediction, and optimizing policies on ensemble models. While model-based methods show promise in addressing deep RL limitations, challenges remain in learning accurate models and developing policies robust to model errors.