Downloaded 83 times



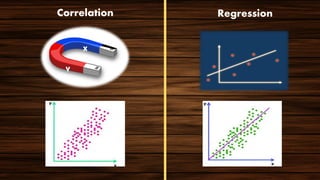

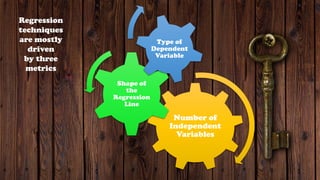
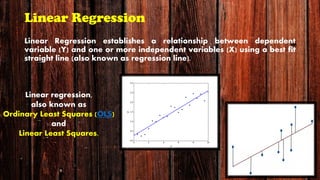
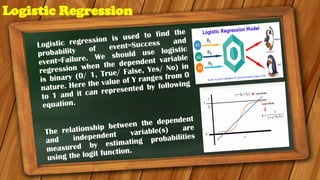

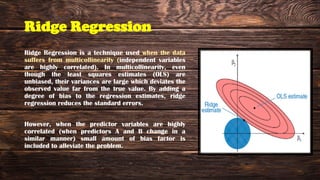





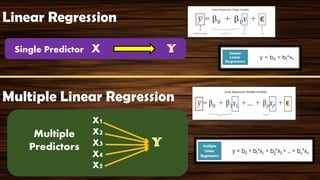

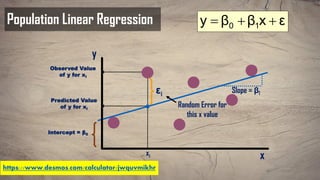



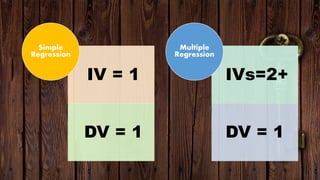

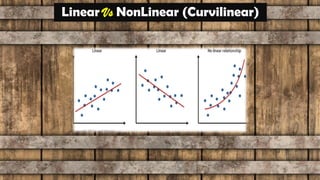
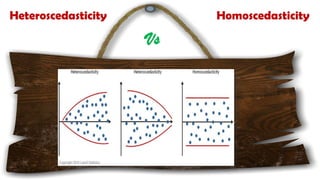
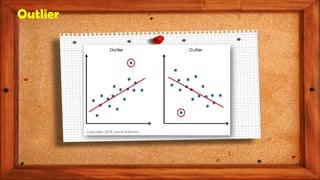
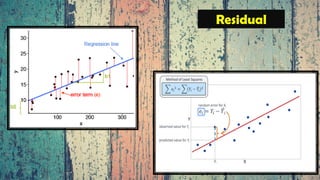

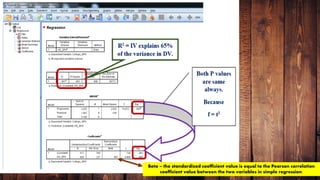








The document provides an overview of various regression analysis techniques used in statistical modeling, including linear, logistic, polynomial, stepwise, ridge, lasso, and elastic-net regression. It outlines their purposes, how they handle different types of data, and describes the assumptions and tests necessary for each method. Additionally, it discusses the historical background of regression and its applications in predicting dependent variables based on independent variables.























































































