Downloaded 98 times


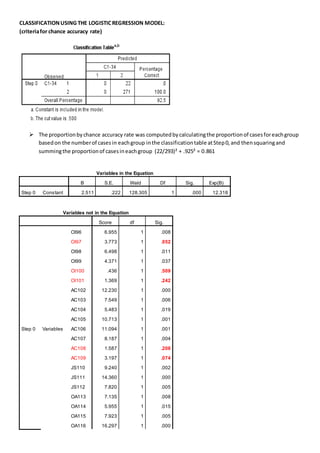
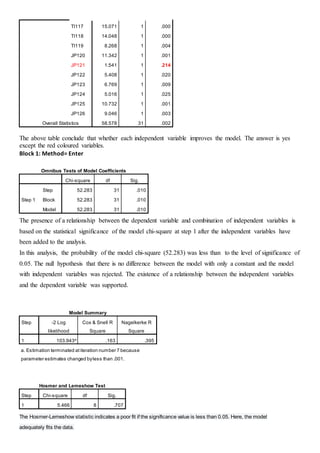
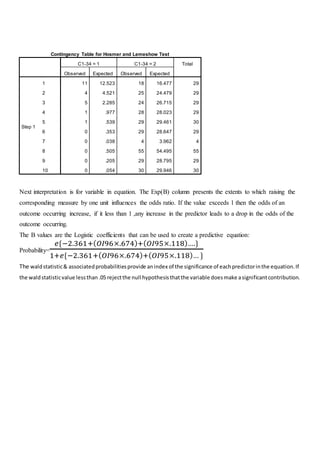
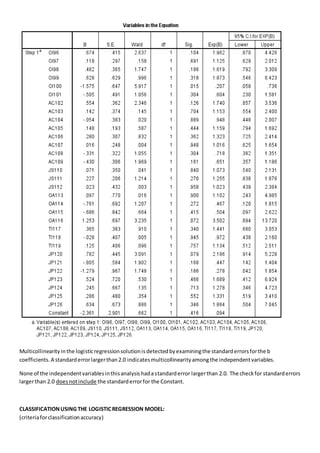


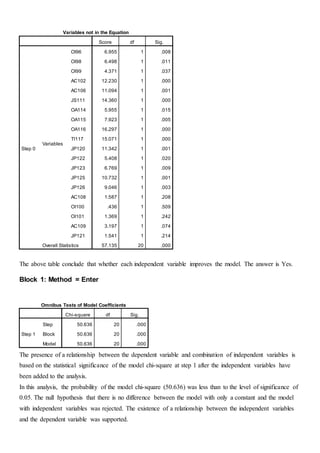
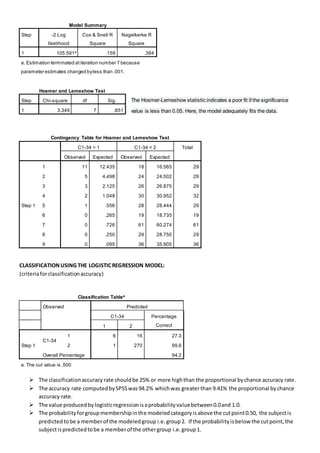
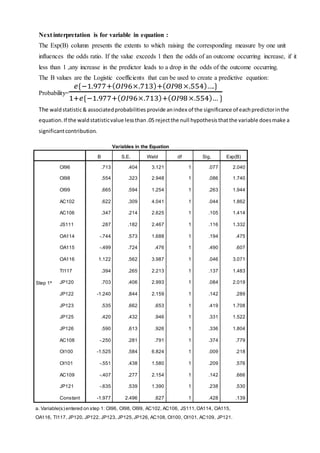
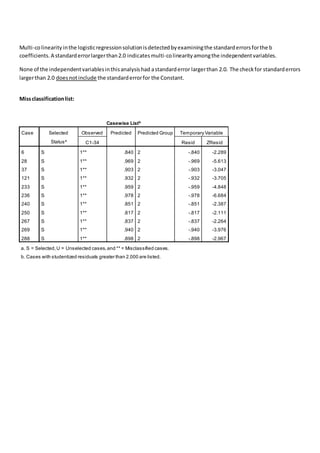

The document discusses a regression analysis aimed at predicting corporate social responsibility using logistic regression based on multiple independent variables. Key elements include the relationship between the variables, model accuracy, and the statistical significance of predictors, which support the existence of a relationship between independent and dependent variables. The logistic regression results indicate good model fit and high classification accuracy rates for predicting group membership.


















































































