Download as PDF, PPTX













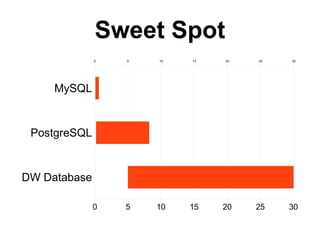




















![CREATE OR REPLACE FUNCTION normalize_query ( queryin text )
RETURNS TEXT LANGUAGE PLPERL STABLE STRICT AS $f$
# this function "normalizes" queries by stripping out constants.
# some regexes by Guillaume Smet under The PostgreSQL License.
local $_ = $_[0];
#first cleanup the whitespace
s/s+/ /g;
s/s,/,/g;
s/,(S)/, $1/g;
s/^s//g;
s/s$//g;
#remove any double quotes and quoted text
s/'//g;
s/'[^']*'/''/g;
s/''('')+/''/g;
#remove TRUE and FALSE
s/(W)TRUE(W)/$1BOOL$2/gi;
s/(W)FALSE(W)/$1BOOL$2/gi;
#remove any bare numbers or hex numbers
s/([^a-zA-Z_$-])-?([0-9]+)/${1}0/g;
s/([^a-z_$-])0x[0-9a-f]{1,10}/${1}0x/ig;
#normalize any IN statements
s/(INs*)(['0x,s]*)/${1}(...)/ig;
#return the normalized query
return $_;
$f$;](https://image.slidesharecdn.com/bigelephants-130102185156-phpapp01/85/Really-Big-Elephants-PostgreSQL-DW-34-320.jpg)
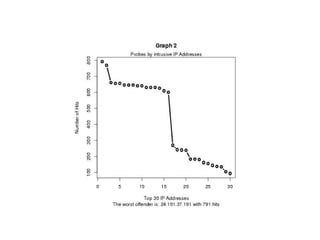
![CREATE OR REPLACE FUNCTION f_graph2() RETURNS text AS '
sql <- paste("SELECT id as x,hit as y FROM mytemp LIMIT
30",sep="");
str <- c(pg.spi.exec(sql));
mymain <- "Graph 2";
mysub <- paste("The worst offender is: ",str[1,3]," with
",str[1,2]," hits",sep="");
myxlab <- "Top 30 IP Addresses";
myylab <- "Number of Hits";
pdf(''/tmp/graph2.pdf'');
plot(str,type="b",main=mymain,sub=mysub,xlab=myxlab,ylab
=myylab,lwd=3);
mtext("Probes by intrusive IP Addresses",side=3);
dev.off();
print(''DONE'');
' LANGUAGE plr;](https://image.slidesharecdn.com/bigelephants-130102185156-phpapp01/85/Really-Big-Elephants-PostgreSQL-DW-35-320.jpg)


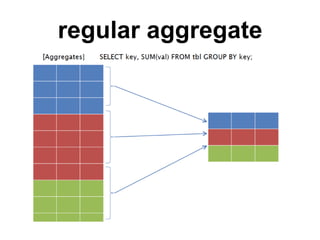
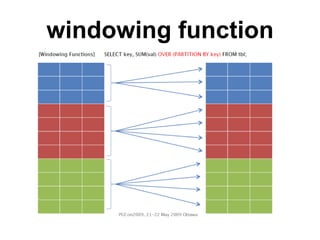























The document discusses using PostgreSQL for data warehousing. It covers advantages like complex queries with joins, windowing functions and materialized views. It recommends configurations like separating the data warehouse onto its own server, adjusting memory settings, disabling autovacuum and using tablespaces. Methods of extract, transform and load (ETL) data discussed include COPY, temporary tables, stored procedures and foreign data wrappers.











































































































