Download as ODP, PPTX


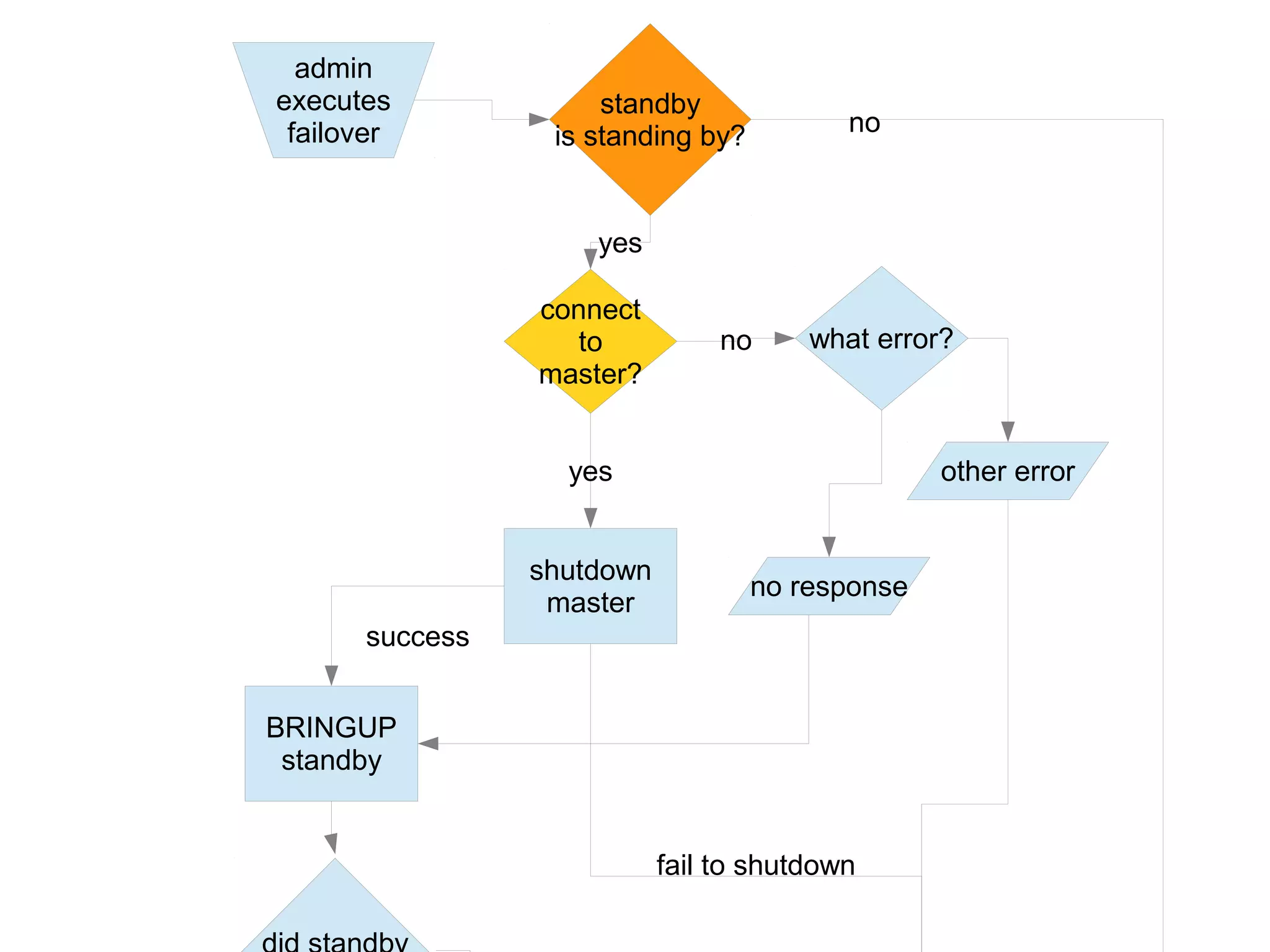














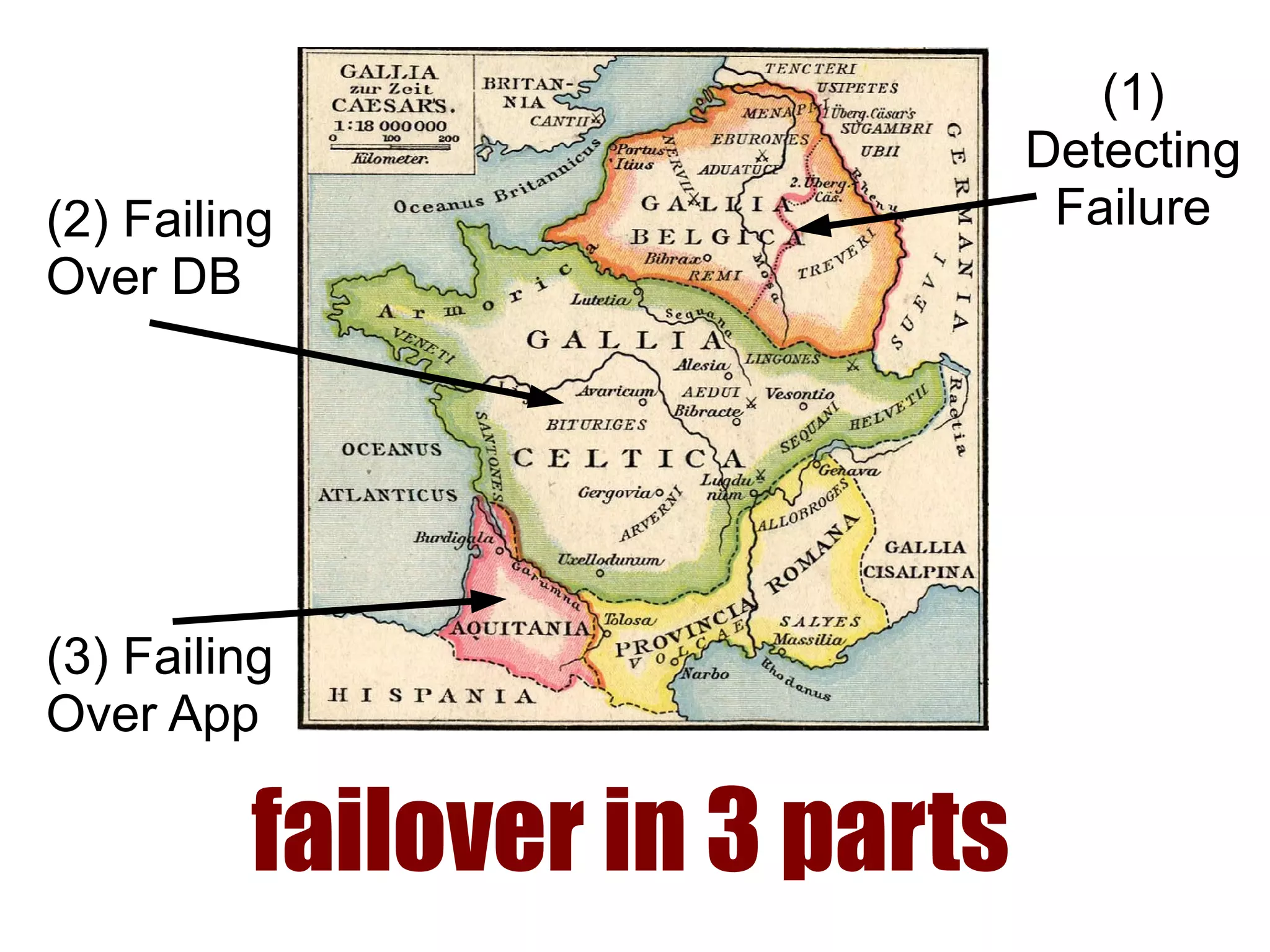






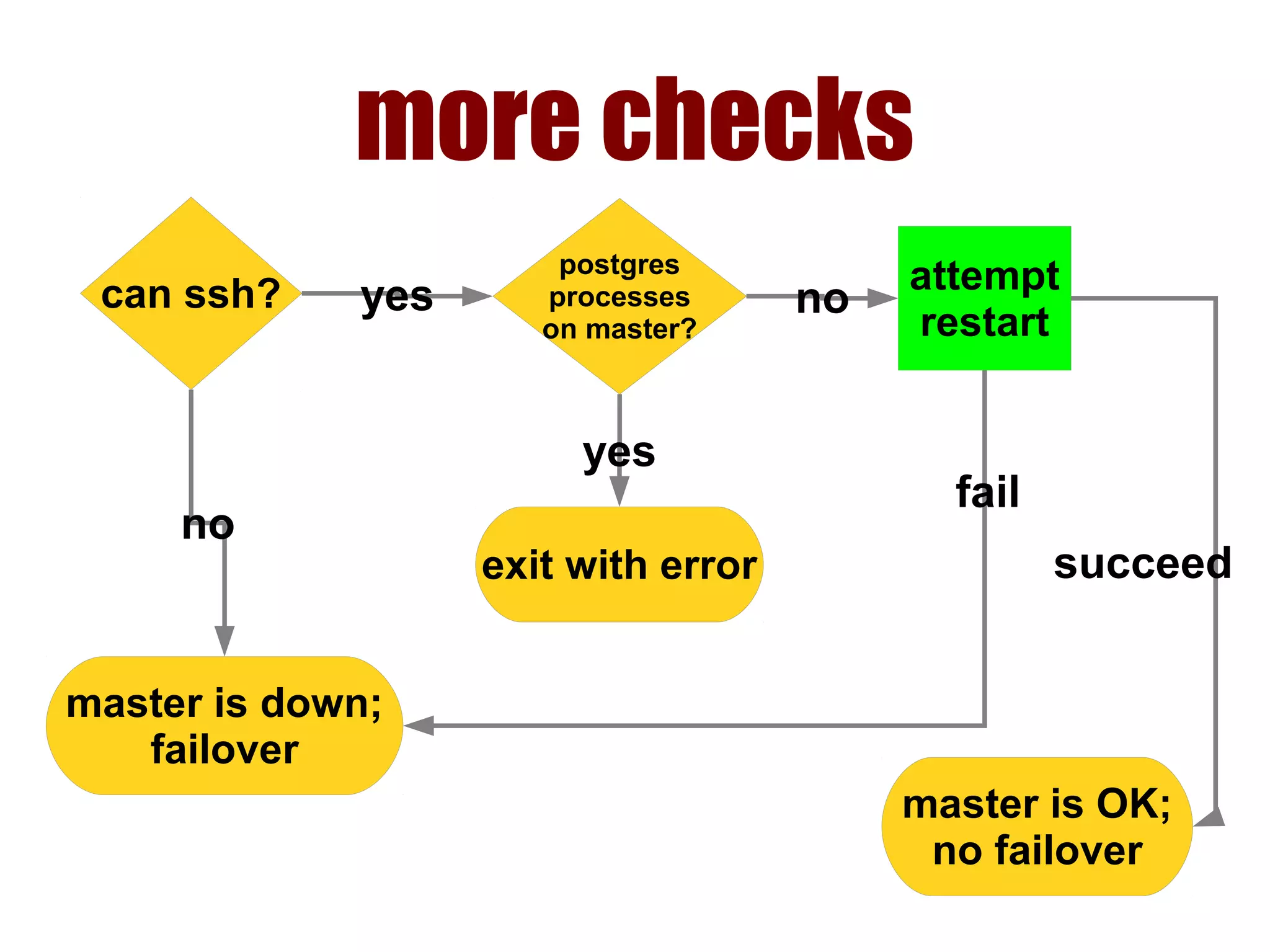
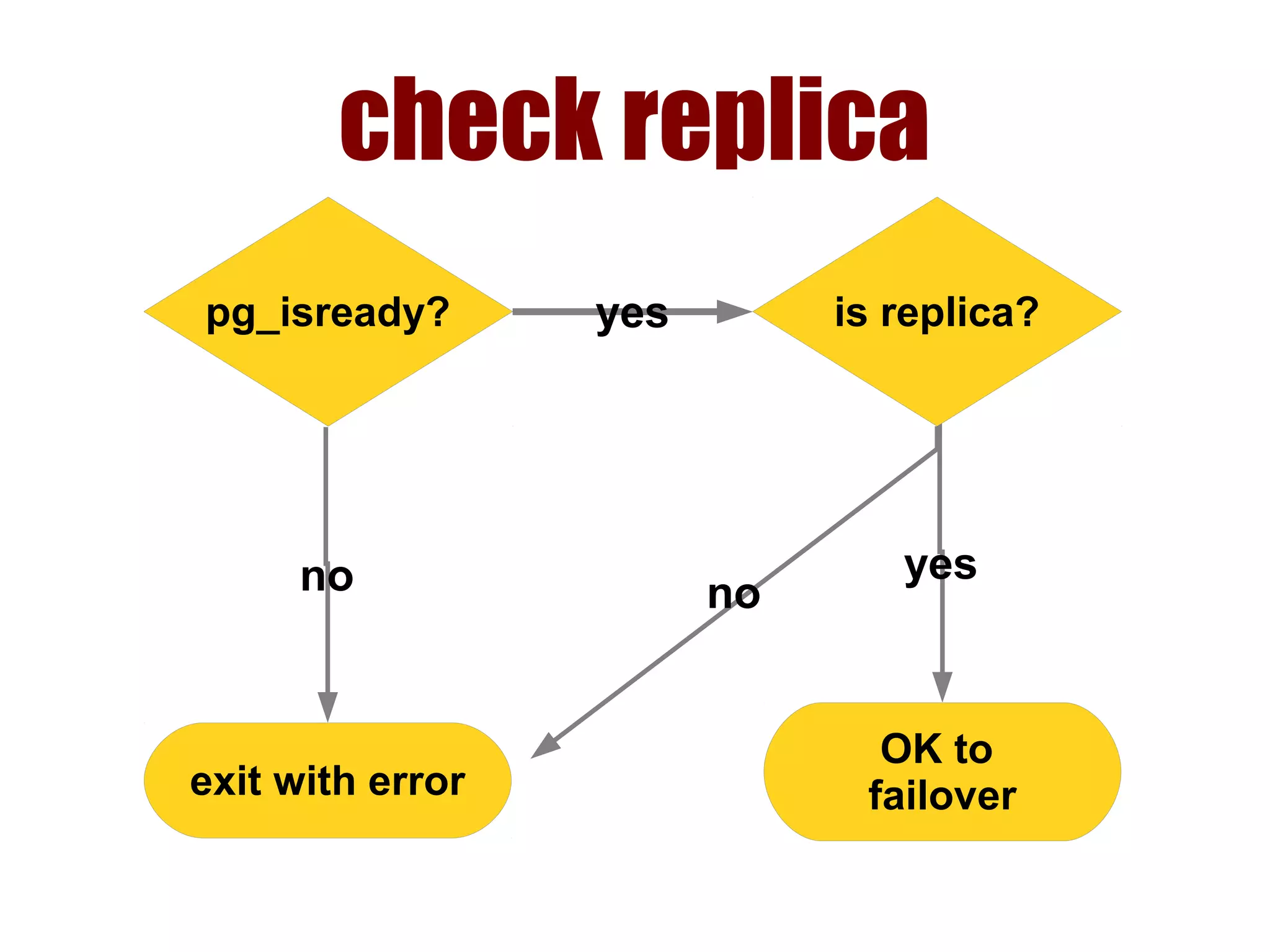

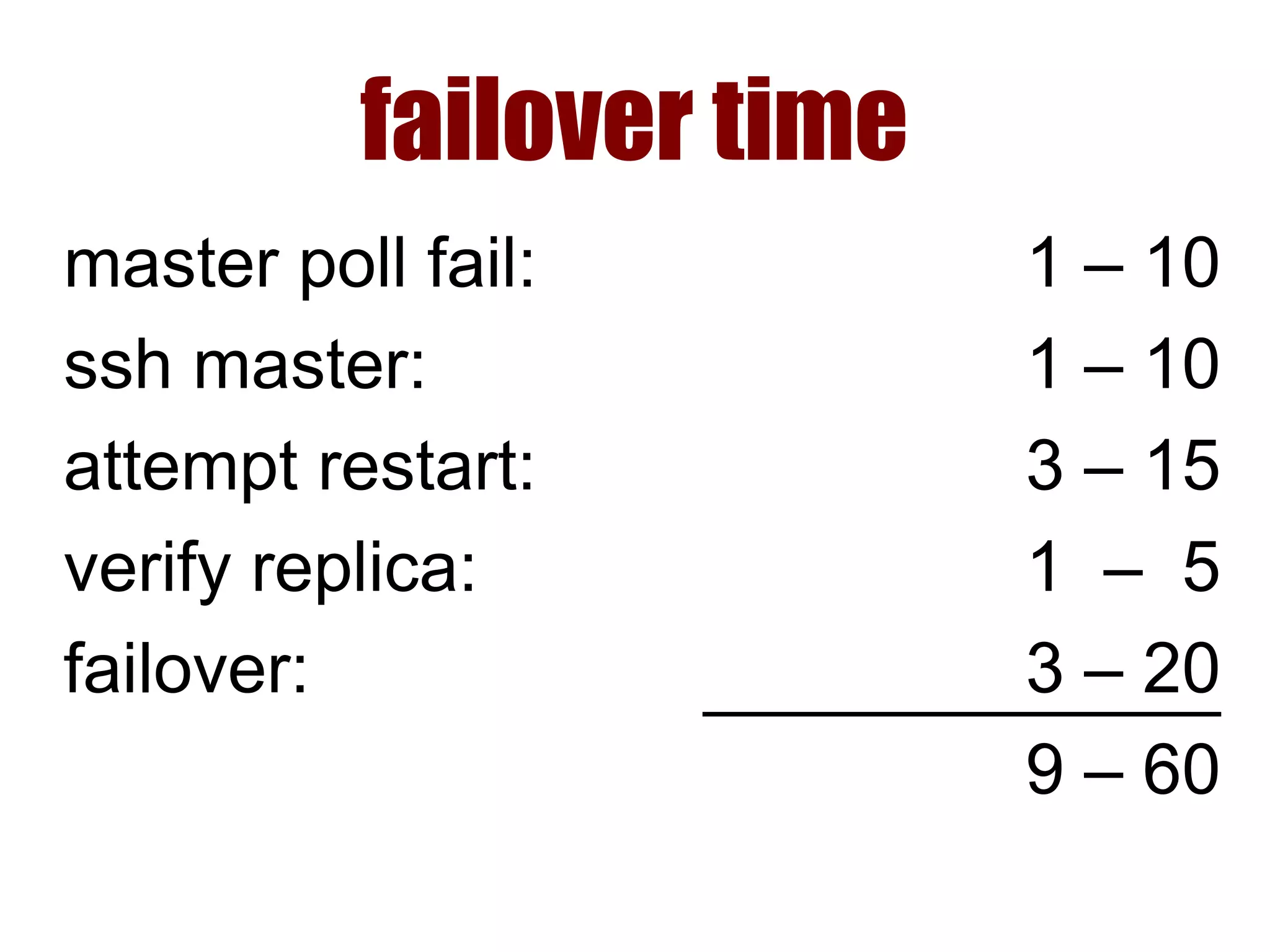

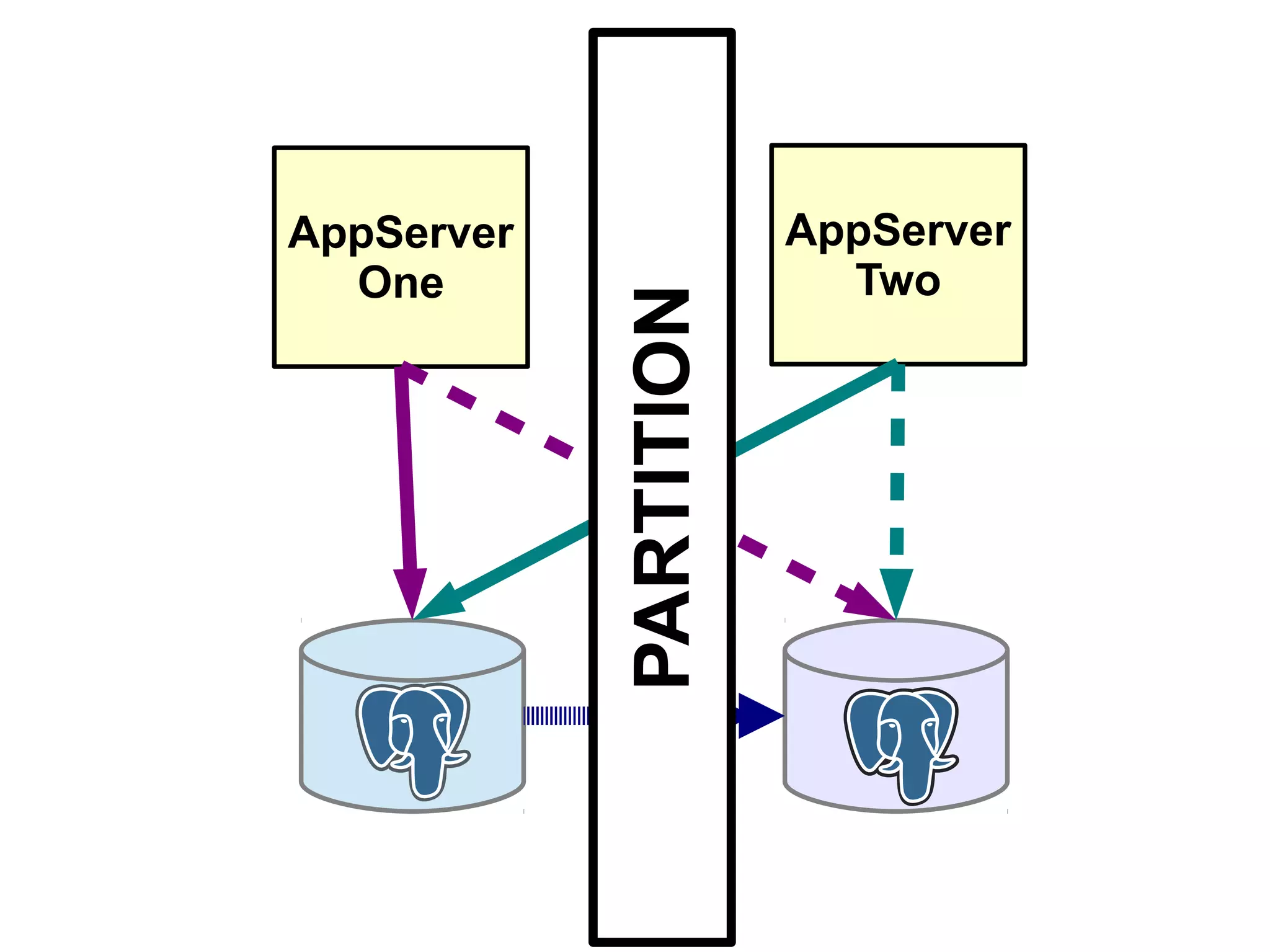
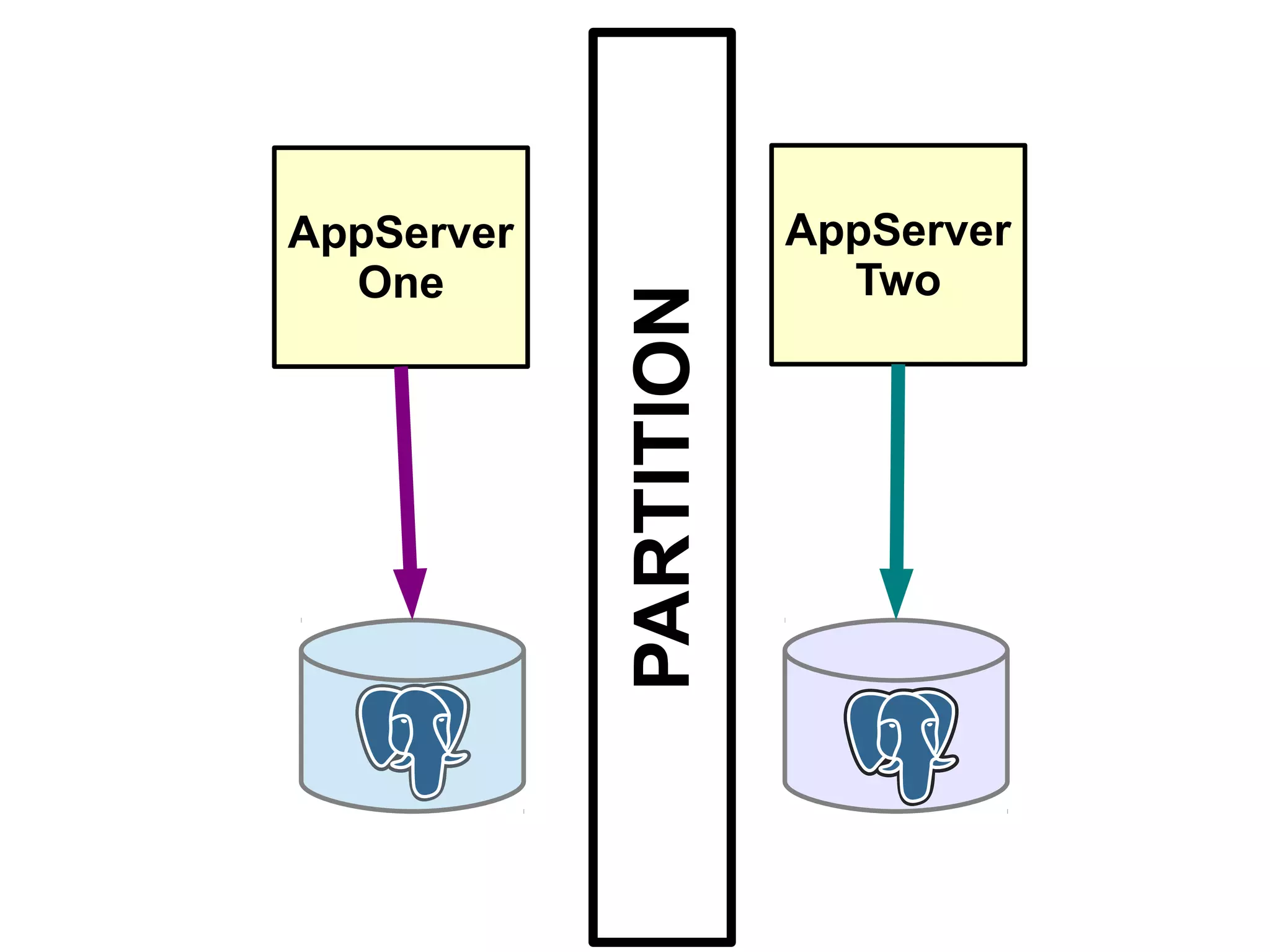
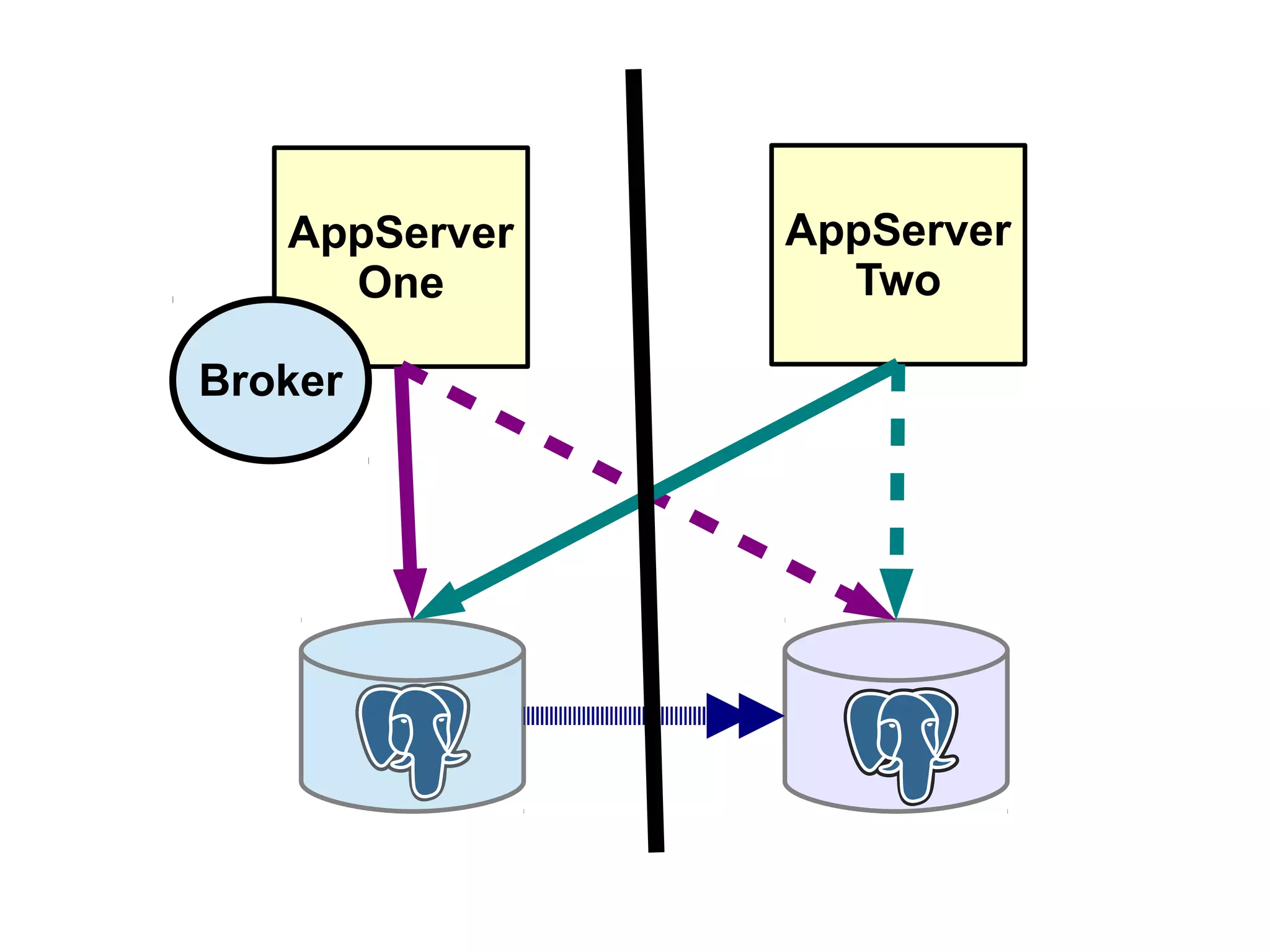
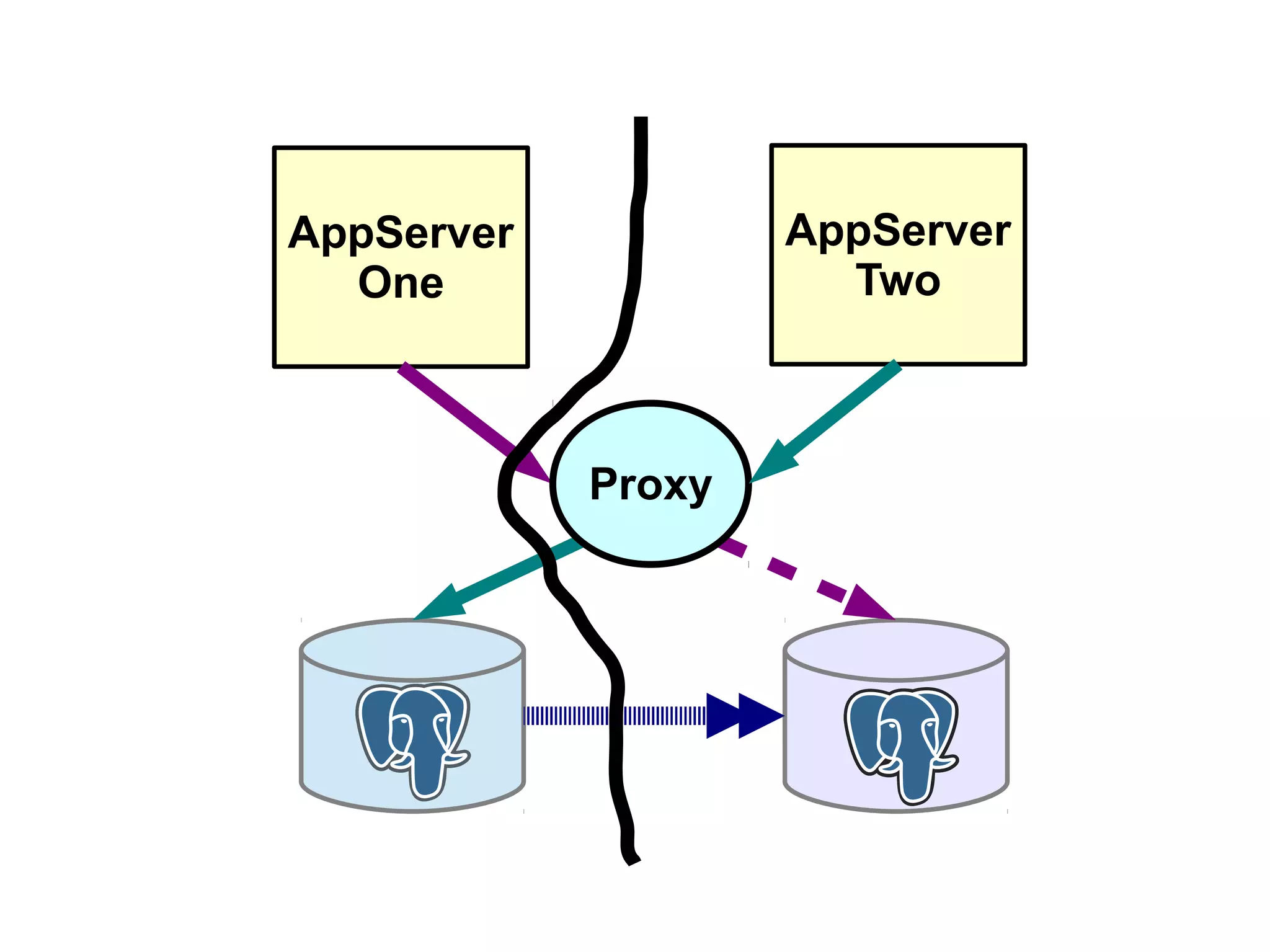





















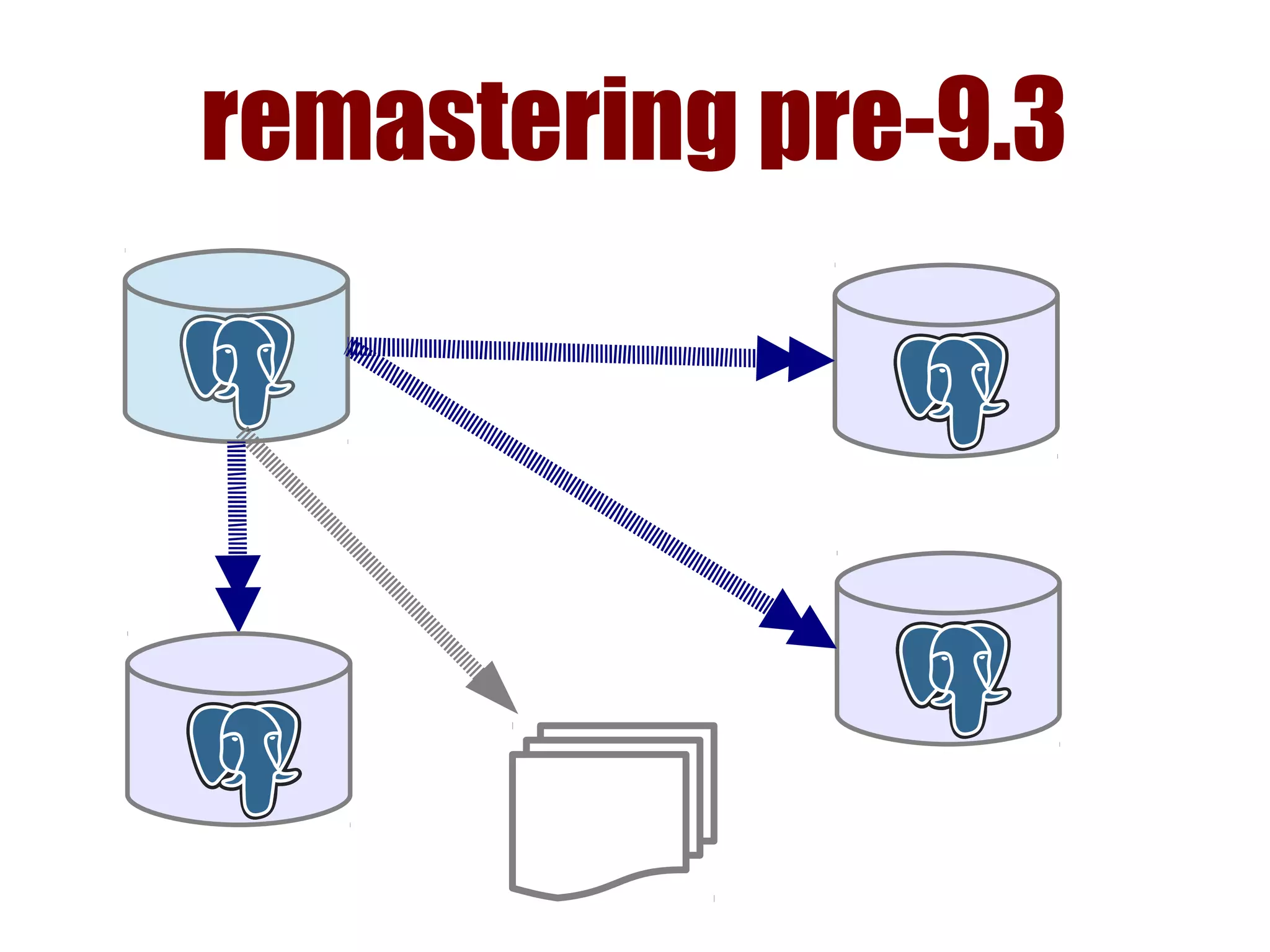

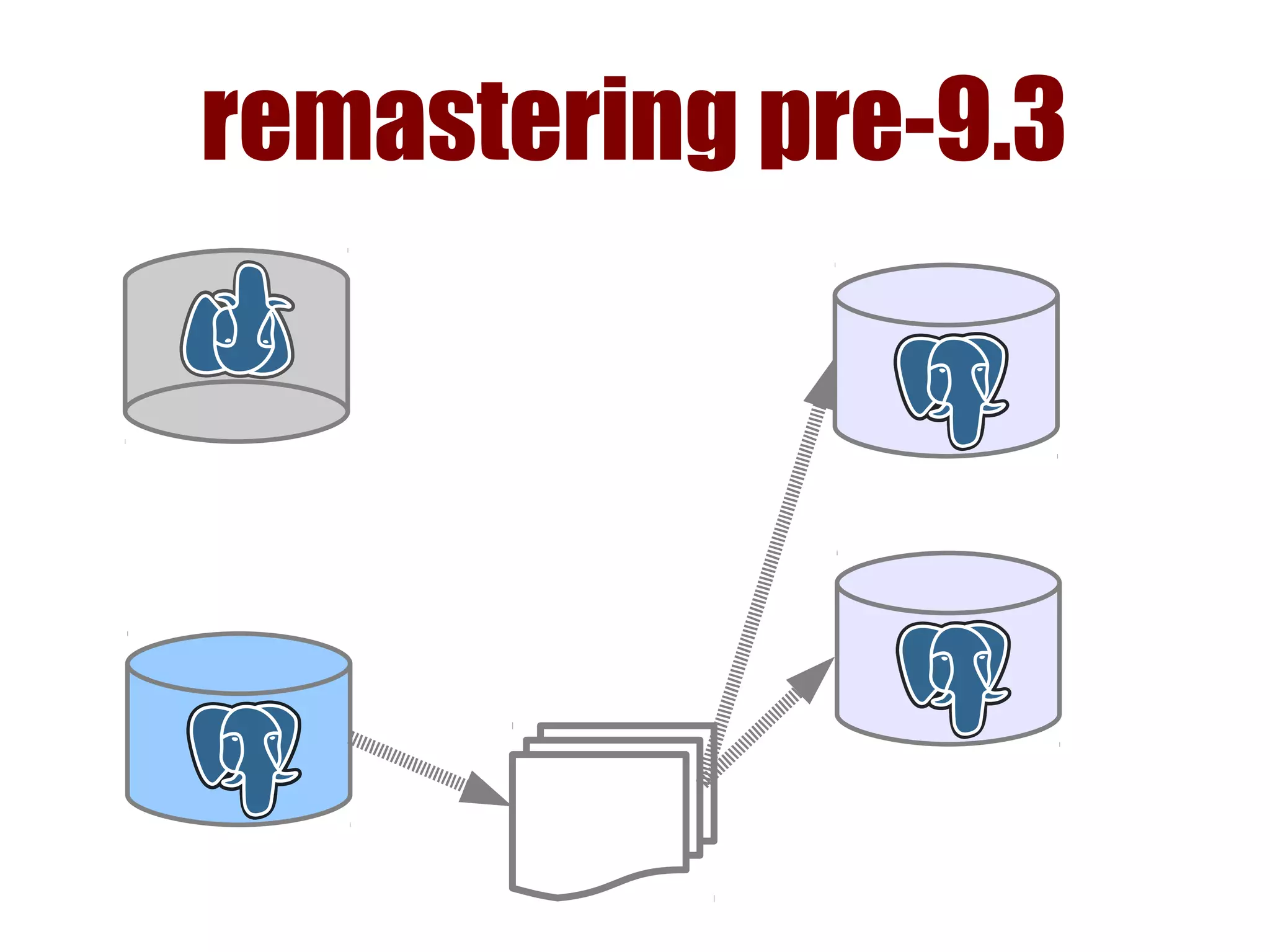
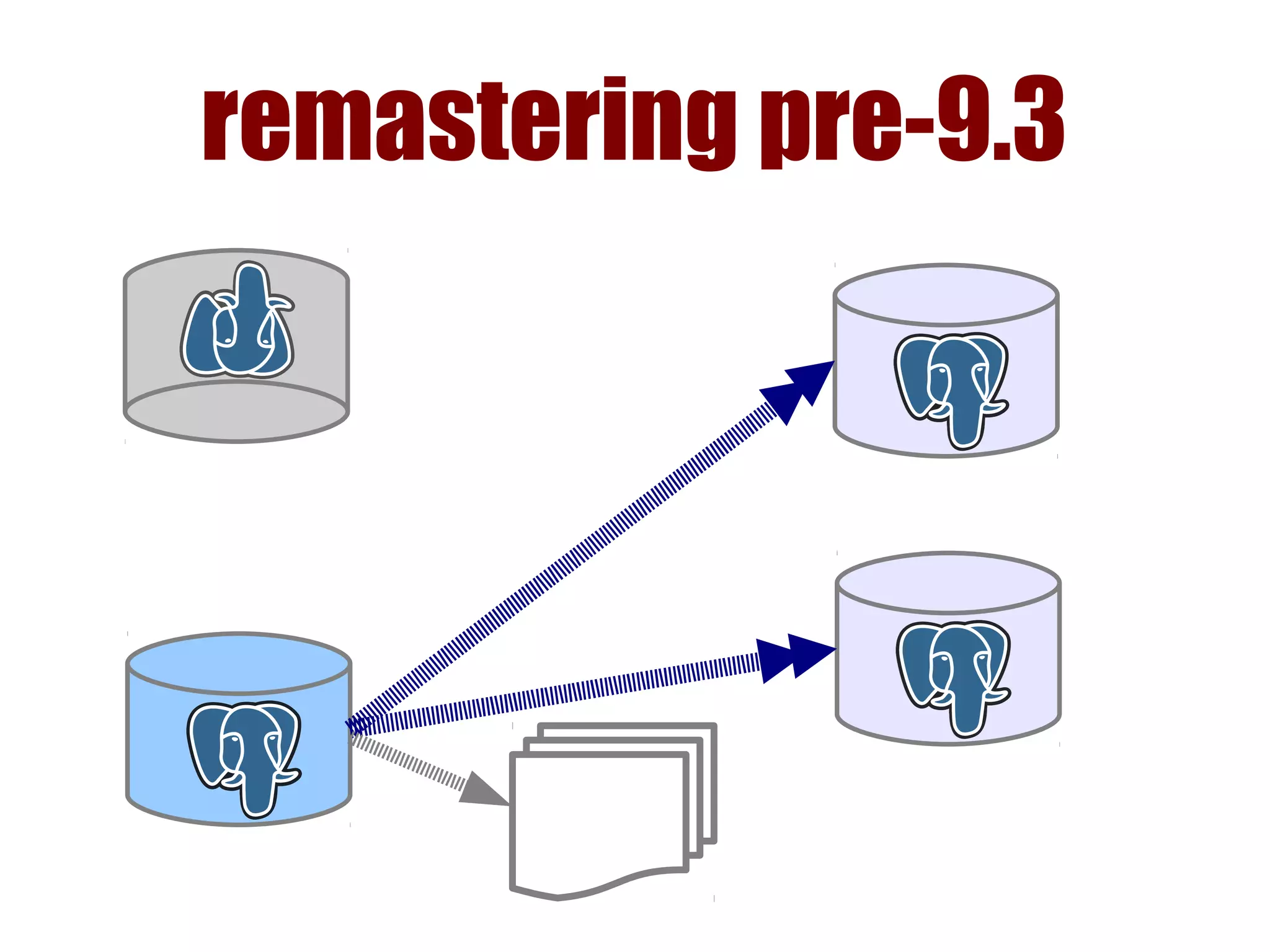
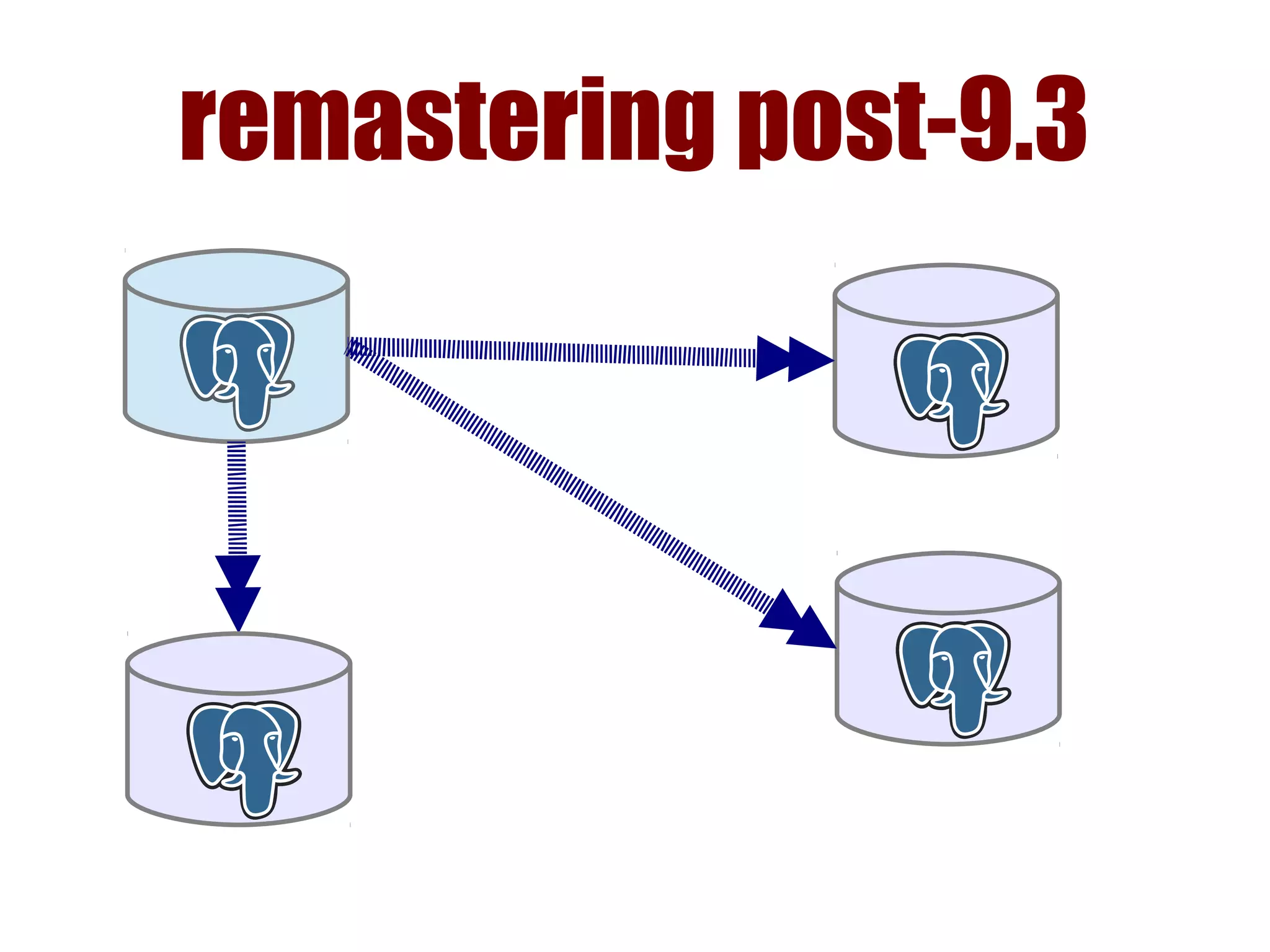

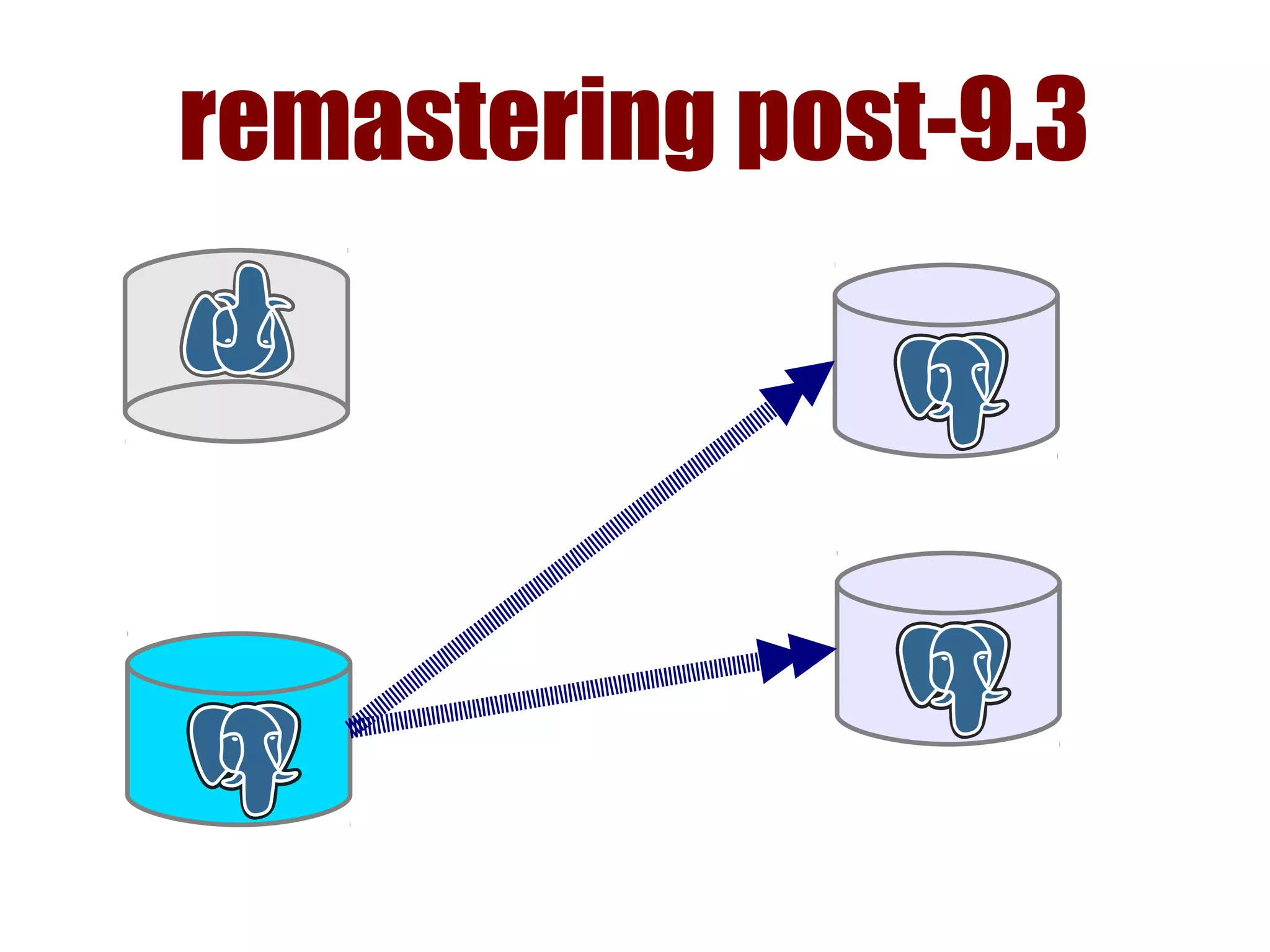


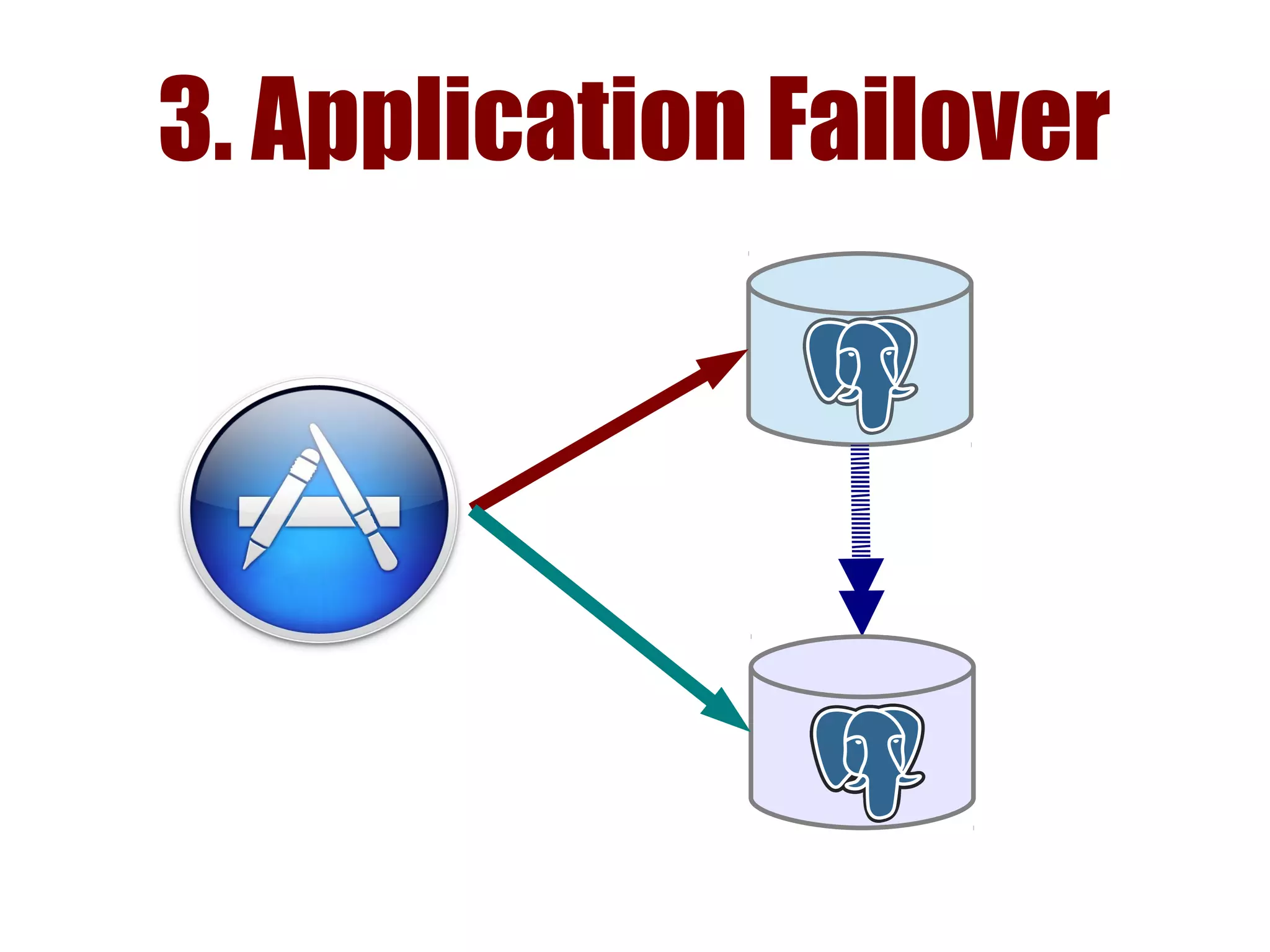









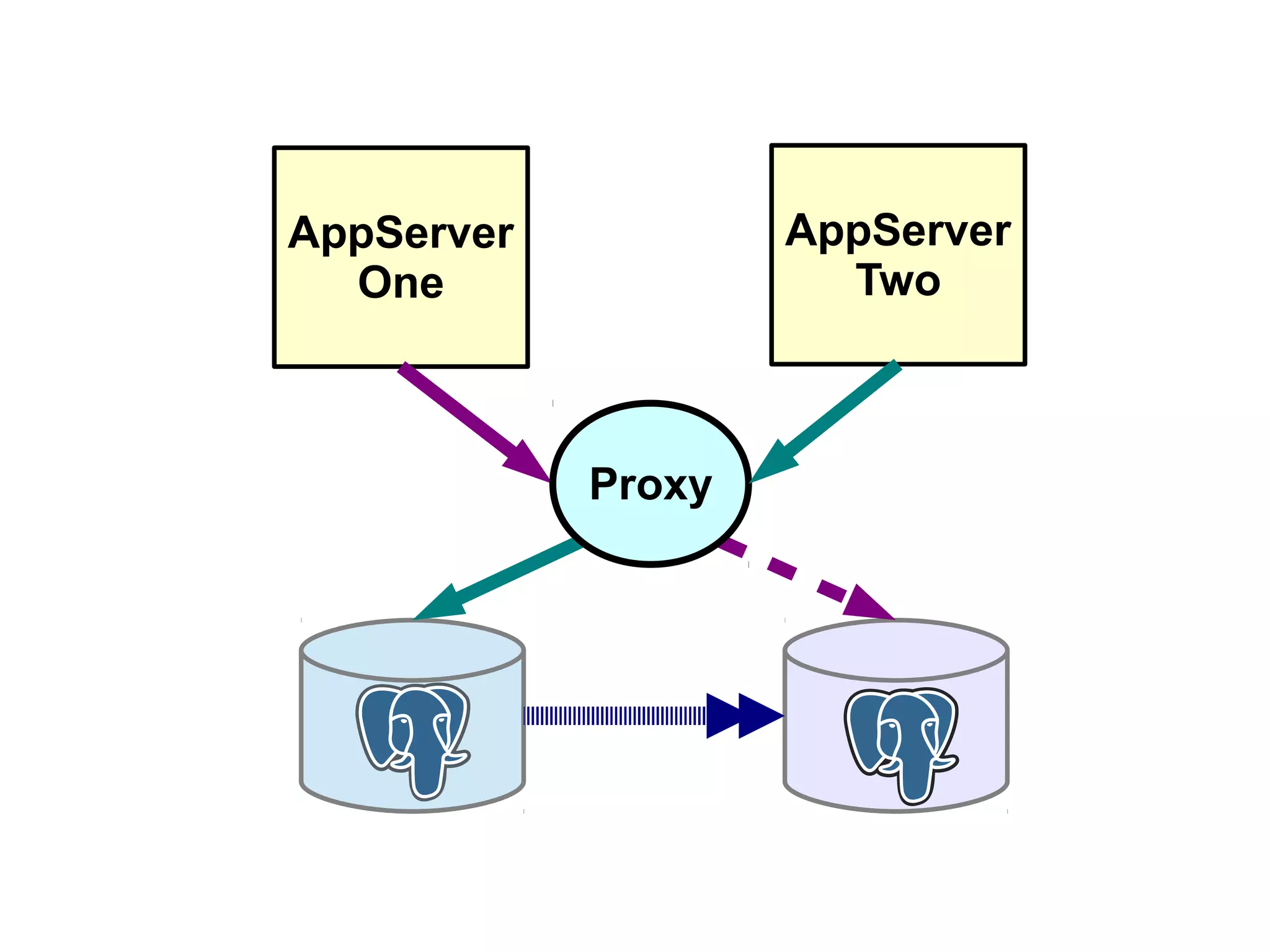
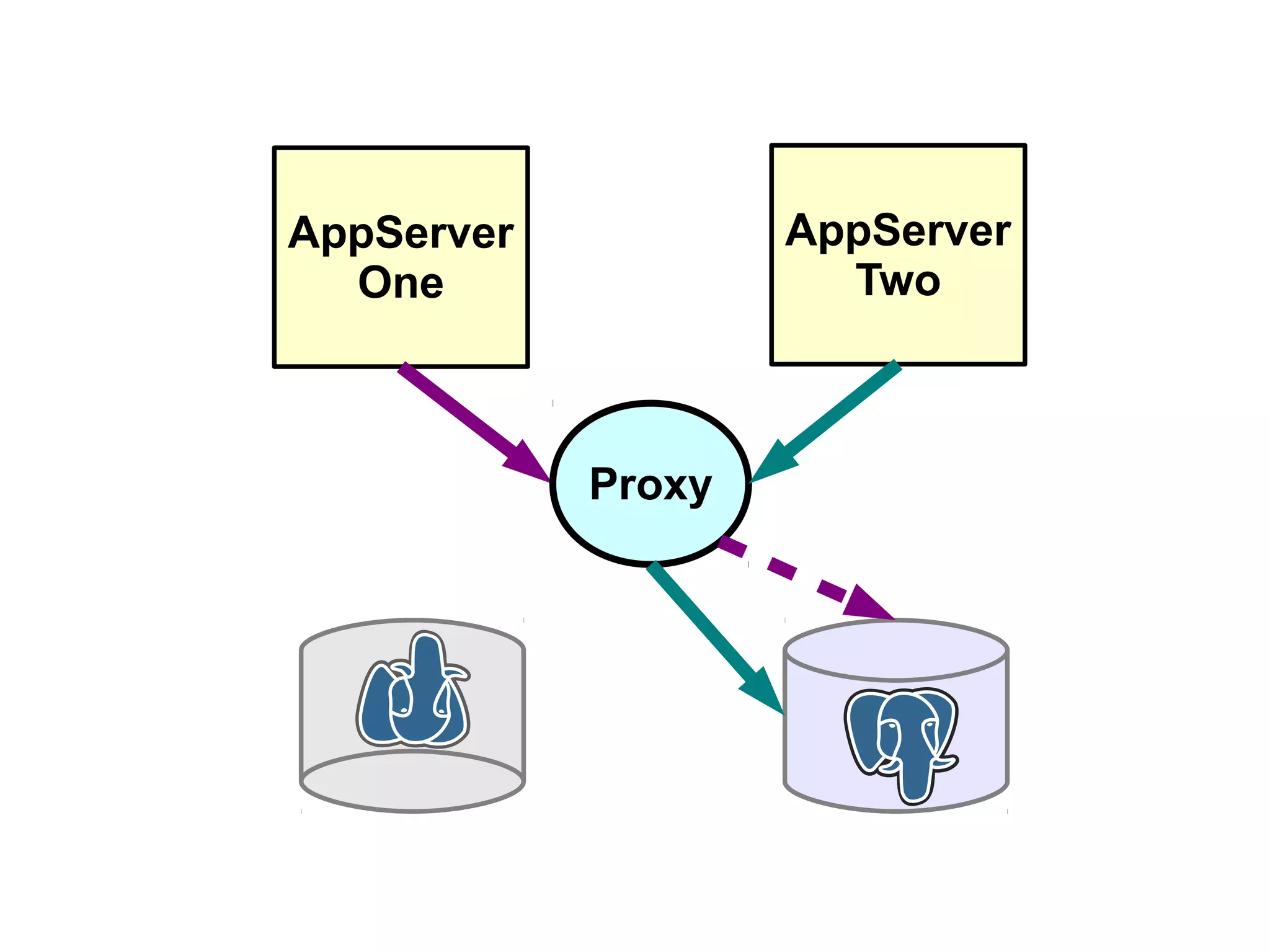















1) Automated failover involves detecting failure of the primary database, promoting a replica to be the new primary, and failing over applications to connect to the new primary. 2) Detecting failure involves multiple checks like connecting to the primary, checking processes, and using pg_isready. Promoting a replica requires choosing the most up-to-date one and running pg_ctl promote. 3) Failing over applications can be done by updating a configuration system and restarting apps, using a tool like Zookeeper, or by failing over a virtual IP with Pacemaker. Proxies can also be used to fail over connections.






























































































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)




