Download as PDF, PPTX






















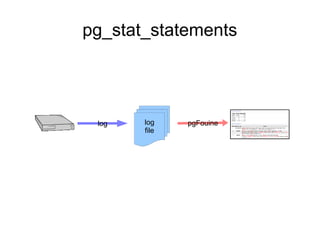
![pg_stat_statements
postgres=# SELECT * FROM pg_stat_statements ORDER BY total_time DESC
LIMIT 3;
-[ RECORD 1 ]------------------------------------------------------------
userid | 10
dbid | 63781
query | UPDATE branches SET bbalance = bbalance + $1 WHERE bid = $2;
calls | 3000
total_time | 20.716706
rows | 3000
-[ RECORD 2 ]------------------------------------------------------------
userid | 10
dbid | 63781
query | UPDATE tellers SET tbalance = tbalance + $1 WHERE tid = $2;
calls | 3000
total_time | 17.1107649999999
rows | 3000
-[ RECORD 3 ]------------------------------------------------------------
userid | 10
dbid | 63781
query | UPDATE accounts SET abalance = abalance + $1 WHERE aid = $2;
calls | 3000
total_time | 0.645601
rows | 3000](https://image.slidesharecdn.com/84featuresfinal-130102194911-phpapp01/85/8-4-Upcoming-Features-26-320.jpg)





![VARIADIC parameters
CREATE OR REPLACE FUNCTION
adder(VARIADIC v int[])
RETURNS int AS $$
DECLARE s int; i int;
BEGIN
s:=0;
FOR i IN SELECT generate_subscripts(v,1) LOOP
s := s + i;
END LOOP;
RETURN s;
END;
$$ LANGUAGE 'plpgsql';
SELECT adder(1);
SELECT adder(1,2,3);
SELECT adder(40,2);](https://image.slidesharecdn.com/84featuresfinal-130102194911-phpapp01/85/8-4-Upcoming-Features-32-320.jpg)
















This document summarizes the key features and changes in PostgreSQL version 8.4. It notes that over 1600 code updates and more than two dozen major features were added over 9 months of development and 5 CommitFests. Major new features include window functions, common table expressions, array_agg, per-database collations, and improved data types like unsigned integers and CIText. Performance and monitoring improvements include parallel restore, improved hash indexes, pg_stat_user_functions, and pg_stat_statements. The document also summarizes security, stored procedure, and exotic features like SQL/MED, multi-column GIN indexes, and Boyer-Moore string searching. It encourages testing and provides contact information for the























































































