



![• AdTech company (ad exchange, ad server, RTB, DMP etc.)
since 2006
• 10,000,000,000+ events/day
• 2K/event
• 3 months retention (90-120 days)
10B * 2K * [90-120] = [1.8-2.4]PB](https://image.slidesharecdn.com/clickhouse-171103171519/85/Migration-to-ClickHouse-Practical-guide-by-Alexander-Zaitsev-4-320.jpg)


























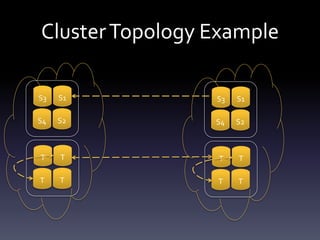






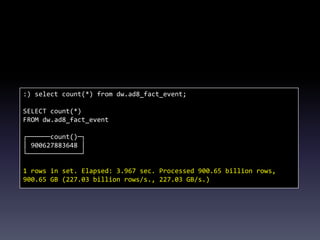
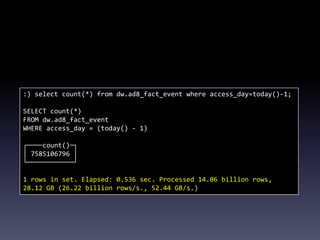
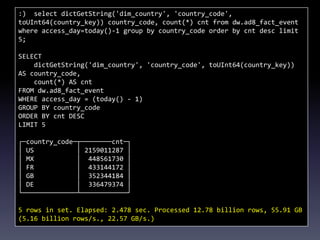
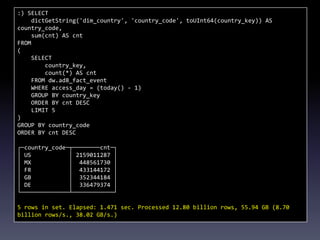
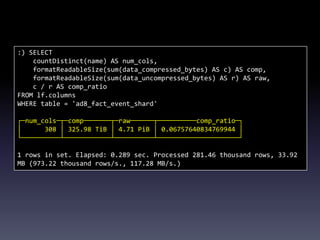









This document provides a summary of migrating to ClickHouse for analytics use cases. It discusses the author's background and company's requirements, including ingesting 10 billion events per day and retaining data for 3 months. It evaluates ClickHouse limitations and provides recommendations on schema design, data ingestion, sharding, and SQL. Example queries demonstrate ClickHouse performance on large datasets. The document outlines the company's migration timeline and challenges addressed. It concludes with potential future integrations between ClickHouse and MySQL.























































































