Downloaded 93 times






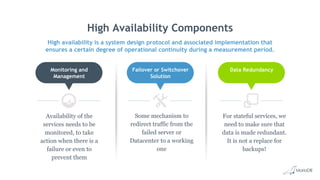








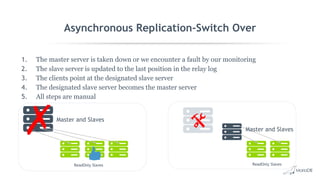
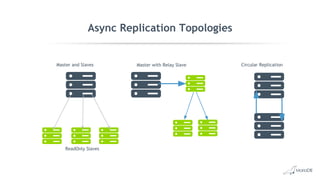




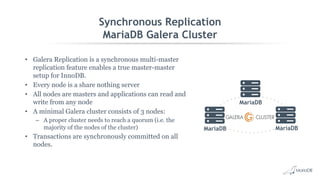

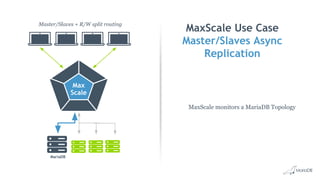
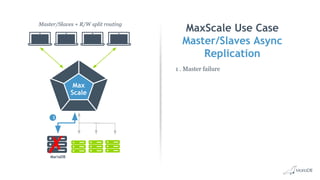
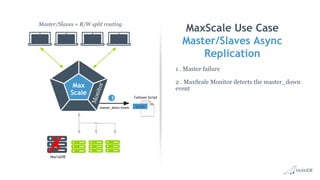
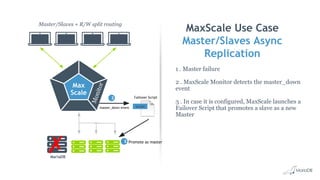
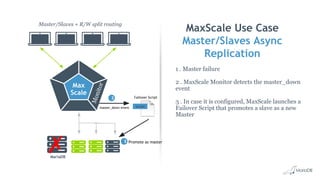
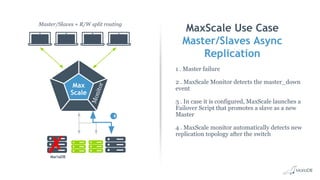
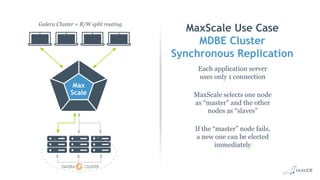
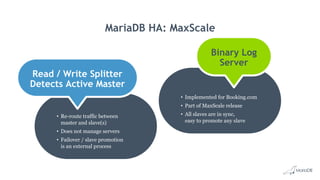


This document discusses high availability and MariaDB replication. It defines high availability and outlines key components like data redundancy, failover solutions, and monitoring. It then describes MariaDB replication in detail, covering asynchronous and semi-synchronous replication as well as Galera cluster synchronous replication. MaxScale is introduced as a tool for load balancing, monitoring, and facilitating failovers in MariaDB replication topologies.







![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)















































































