Download as PDF, PPTX




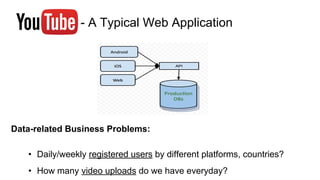
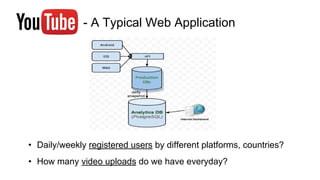

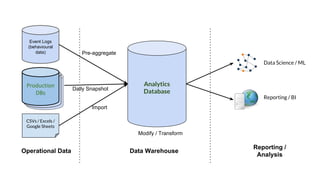
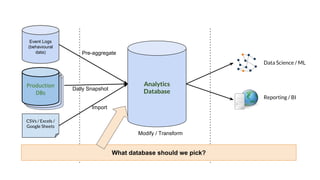
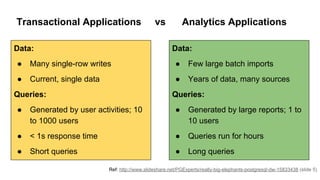


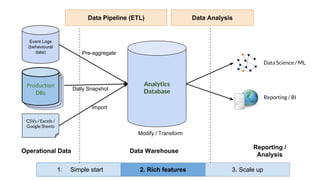
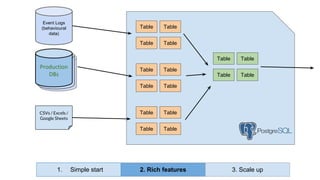


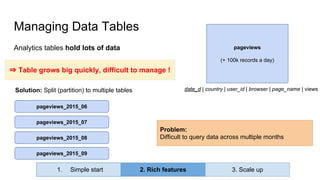
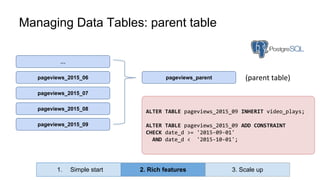

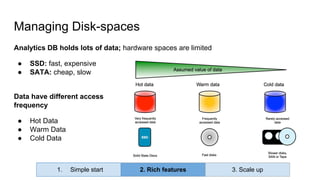
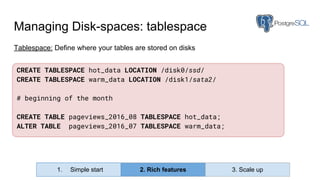
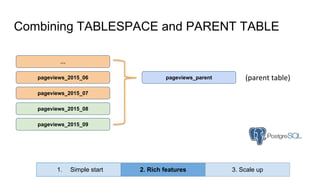

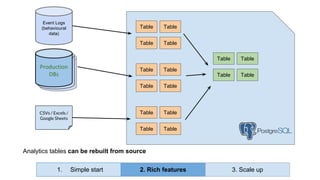
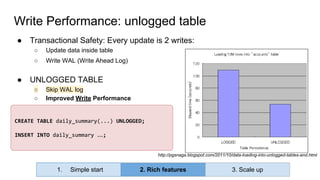

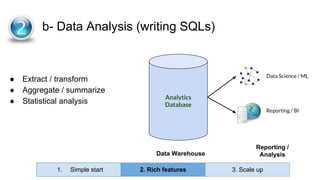



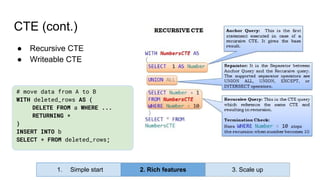
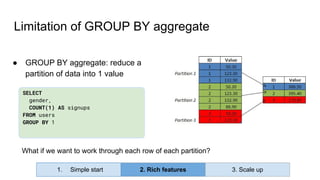
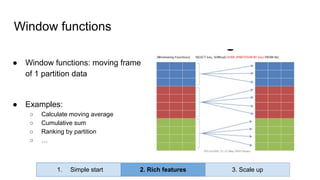



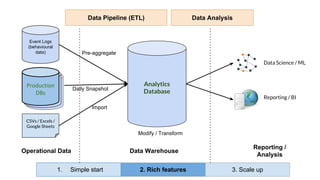


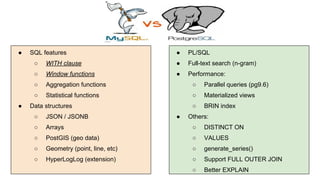
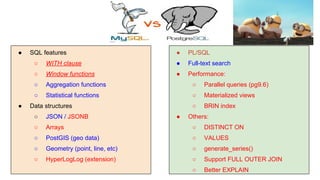





Huy Nguyen, cofounder of Holistics.io, discusses the advantages of using PostgreSQL for analytics infrastructure, highlighting its ease of use, rich analytics features, and scalability. The presentation addresses typical data-related business challenges, data pipelines, and managing data complexity through techniques like table partitioning and unlogged tables for improved performance. It also compares PostgreSQL with other databases, emphasizing its strengths while acknowledging potential downsides and outlining the path for scaling to data warehouses.










































































