Downloaded 70 times




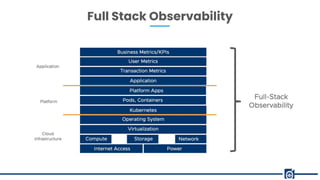
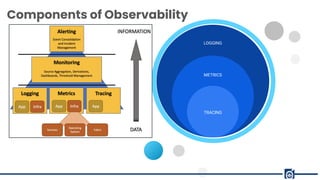
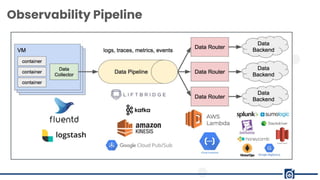






The document presents a detailed overview of observability in DevOps, emphasizing its critical role in system reliability and issue resolution. It covers the components, benefits, and common pitfalls associated with observability, as well as best practices for scaling observability efforts. Key benefits highlighted include improved understanding of system performance, reduced downtime, and enhanced customer satisfaction.























































































