Download as ODP, PPTX




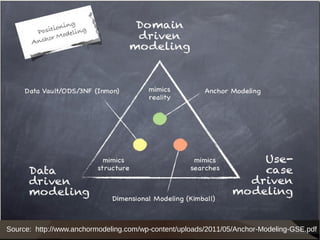





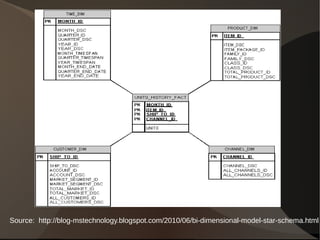


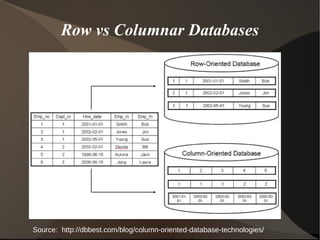



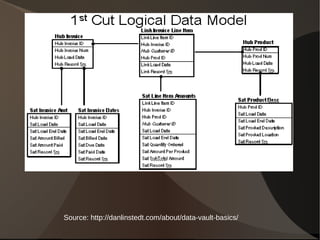



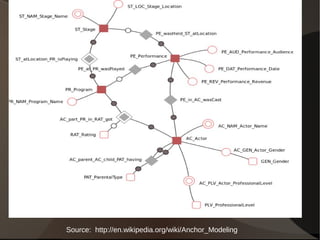




This document summarizes different approaches to data warehousing including Inmon's 3NF model, Kimball's conformed dimensions model, Linstedt's data vault model, and Rönnbäck's anchor model. It discusses the challenges of data warehousing and provides examples of open source software that can be used to implement each approach including MySQL, PostgreSQL, Greenplum, Infobright, and Hadoop. Cautions are also noted for each methodology.















































































