Downloaded 16 times











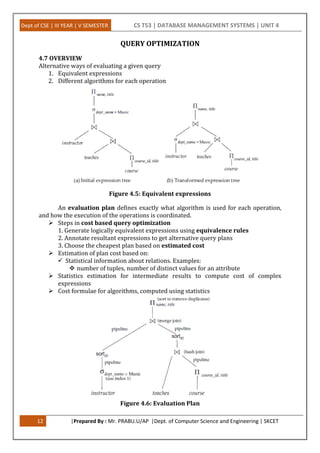



















This document provides an overview of query processing and optimization techniques in database management systems. It discusses measures of query cost, various query operations like selection, sorting, joining, and aggregation. It also covers transaction processing concepts like atomicity, durability, and isolation levels. Specific algorithms covered include nested-loop join, merge join, hash join, and their cost analysis. The document is divided into sections on query processing, transaction processing, and covers various operations involved in query evaluation and optimization.