Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
TY
Uploaded by
Tomoki Yoshida
PDF, PPTX
1,007 views
XGBoostからNGBoostまで
XGBoost, LightGBM, CatBoost, NGBoostを解説.
Data & Analytics
◦
Related topics:
Decision Tree Models
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
Most read
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
Most read
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
Most read
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions
by
Deep Learning JP
PDF
NIPS2017読み会 LightGBM: A Highly Efficient Gradient Boosting Decision Tree
by
Takami Sato
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
SSII2020TS: 機械学習モデルの判断根拠の説明 〜 Explainable AI 研究の近年の展開 〜
by
SSII
PDF
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎
by
Preferred Networks
PDF
PRML Chapter 14
by
Masahito Ohue
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
[DL輪読会]Understanding Black-box Predictions via Influence Functions
by
Deep Learning JP
NIPS2017読み会 LightGBM: A Highly Efficient Gradient Boosting Decision Tree
by
Takami Sato
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
機械学習の理論と実践
by
Preferred Networks
SSII2020TS: 機械学習モデルの判断根拠の説明 〜 Explainable AI 研究の近年の展開 〜
by
SSII
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎
by
Preferred Networks
PRML Chapter 14
by
Masahito Ohue
What's hot
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
ブースティング入門
by
Retrieva inc.
PPTX
CatBoost on GPU のひみつ
by
Takuji Tahara
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PDF
第10章後半「ブースティングと加法的木」
by
T T
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
PDF
Graph Attention Network
by
Takahiro Kubo
PPTX
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
不均衡データのクラス分類
by
Shintaro Fukushima
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
機械学習モデルの判断根拠の説明
by
Satoshi Hara
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PRML学習者から入る深層生成モデル入門
by
tmtm otm
GAN(と強化学習との関係)
by
Masahiro Suzuki
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
ブースティング入門
by
Retrieva inc.
CatBoost on GPU のひみつ
by
Takuji Tahara
バンディットアルゴリズム入門と実践
by
智之 村上
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
第10章後半「ブースティングと加法的木」
by
T T
報酬設計と逆強化学習
by
Yusuke Nakata
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
Graph Attention Network
by
Takahiro Kubo
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
Similar to XGBoostからNGBoostまで
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PDF
Kaggleのテクニック
by
Yasunori Ozaki
PPTX
Gradient Tree Boosting はいいぞ
by
7X RUSK
PDF
PRML 第14章
by
Akira Miyazawa
PDF
LightGBM: a highly efficient gradient boosting decision tree
by
Yusuke Kaneko
PDF
多数のグラフからの統計的機械学習 (2014.7.24 人工知能学会 第94回人工知能基本問題研究会 招待講演)
by
Ichigaku Takigawa
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PPT
Lp Boost
by
Yasuo Tabei
PPTX
miru2020-200727021915200727021915200727021915200727021915.pptx
by
RajSharma11707
PPTX
GBDTアルゴリズムを比べてみる
by
ShoichiYashiro
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V7
by
Shunsuke Nakamura
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PPTX
Xgboost for share
by
Shota Yasui
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
PDF
Dive into XGBoost.pdf
by
Yuuji Hiramatsu
PDF
KDD2013読み会: Direct Optimization of Ranking Measures
by
sleepy_yoshi
PDF
それっぽく感じる機械学習
by
Yuki Igarashi
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
Kaggleのテクニック
by
Yasunori Ozaki
Gradient Tree Boosting はいいぞ
by
7X RUSK
PRML 第14章
by
Akira Miyazawa
LightGBM: a highly efficient gradient boosting decision tree
by
Yusuke Kaneko
多数のグラフからの統計的機械学習 (2014.7.24 人工知能学会 第94回人工知能基本問題研究会 招待講演)
by
Ichigaku Takigawa
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
Lp Boost
by
Yasuo Tabei
miru2020-200727021915200727021915200727021915200727021915.pptx
by
RajSharma11707
GBDTアルゴリズムを比べてみる
by
ShoichiYashiro
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V7
by
Shunsuke Nakamura
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
20170422 数学カフェ Part1
by
Kenta Oono
Xgboost for share
by
Shota Yasui
0610 TECH & BRIDGE MEETING
by
健司 亀本
Dive into XGBoost.pdf
by
Yuuji Hiramatsu
KDD2013読み会: Direct Optimization of Ranking Measures
by
sleepy_yoshi
それっぽく感じる機械学習
by
Yuki Igarashi
More from Tomoki Yoshida
PDF
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
PDF
凸最適化 〜 双対定理とソルバーCVXPYの紹介 〜
by
Tomoki Yoshida
PPTX
AHC008振り返り - Heuristic Contest初参戦 -
by
Tomoki Yoshida
PDF
⽣成AIをコアとするプロダクト開発で使う技術 - 複数AIと対話できるプロダクトと業務を通して -
by
Tomoki Yoshida
PDF
ライブコミュニケーションアプリPocochaで学ぶサービスを成長させるレコメンド
by
Tomoki Yoshida
PPTX
Santa2022振り返り 〜初めてのチームマージ〜
by
Tomoki Yoshida
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
凸最適化 〜 双対定理とソルバーCVXPYの紹介 〜
by
Tomoki Yoshida
AHC008振り返り - Heuristic Contest初参戦 -
by
Tomoki Yoshida
⽣成AIをコアとするプロダクト開発で使う技術 - 複数AIと対話できるプロダクトと業務を通して -
by
Tomoki Yoshida
ライブコミュニケーションアプリPocochaで学ぶサービスを成長させるレコメンド
by
Tomoki Yoshida
Santa2022振り返り 〜初めてのチームマージ〜
by
Tomoki Yoshida
XGBoostからNGBoostまで
1.
XGBoostからNGBoostまで 吉田知貴 システム本部AIシステム部データサイエンス第一グループ 株式会社ディー・エヌ・エー
2.
自己紹介 ● 吉田 知貴 ○
名古屋工業大学大学院 情報工学専攻 竹内・烏山研究室 出身 ○ 2020年 DeNA入社 ○ 趣味: 野鳥撮影 在学時代 ● 機械学習の凸最適化の理論研究 ○ KDD 2018 | Safe Triplet Screening for Distance Metric Learning ○ KDD 2019 | Learning Interpretable Metric between Graphs: Convex Formulation and Computation with Graph Mining ● 理論系のQiita記事 ○ ラグランジュ双対問題について解説: https://qiita.com/birdwatcher/items/b23209f06177373c6df4 ○ 機械学習の高速化手法Safe Screeningを解説: https://qiita.com/birdwatcher/items/6c3f86693f02762d05b9 2
3.
目次 3 勾配ブースティング XGBoost LightGBM 1 3 CatBoost4 2 NGBoost5 その他6
4.
①:勾配ブースティング Friedmanによる元祖勾配ブースティング 4
5.
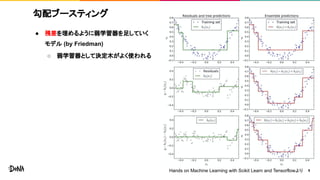
勾配ブースティング ● 残差を埋めるように弱学習器を足していく モデル (by
Friedman) ○ 弱学習器として決定木がよく使われる 5Hands on Machine Learning with Scikit Learn and Tensorflowより
6.
勾配ブースティングの歴史 ● Friedmanの勾配ブースティング (1999) ○
勾配ブースティング発案 近年... ● XGBoost (KDD2016) ○ 正則化, 定式化ベースでの導出, 実装上の工夫 ● LightGBM (NIPS2017) ○ 高速化 ● CatBoost (NIPS2018) ○ カテゴリ変数の扱い ● NGBoost (2019) ○ 不確かさを扱う 6
7.
Friedmanの勾配ブースティング 7 The Elements of
Statistical Learningより サンプルに対する勾配 勾配を出力するような木を構築 葉の値は損失を下げるように ● 普通の勾配法に基づいた考え方 ○ 勾配を決定木で表現して足していく
8.
②:XGBoost 最近のベース手法 8
9.
XGBoostの定式化 ● 目的関数 ○ 正則化項 9 葉の数
葉の値 (T次元ベクトル) 正則化係数 (葉の数抑制) 正則化係数 (1つの木の影響力抑制 ) 一つ前の予測値 損失関数 サンプルに関する和 決定木
10.
XGBoostの考え方 (1/3) ● 最適な葉の値wを求めるために 目的関数の2次近似:
ft に関して0の周りでテイラー展開 10 1次微分 2次微分 wにとって定数
11.
XGBoostの考え方 (2/3) ● 定数除去 ●
fをwの値で陽に書き表すと... ● wの二次関数になった!! ○ 最適なwが求まる 11 正則化項Ω 葉 j にたどりつくサンプルたち このとき
12.
XGBoostの考え方 (3/3) ● 分岐時は,
次のスコアが最大になるような分割を探す ○ 最も目的関数(の近似)が下がる分岐を探していることに対応する ● Friedmanとぜんぜん違うように見える...? ○ XGBoostも式変形すると, Friedmanと同じように (重み付き)勾配にフィットする木を作ることになっていることに注意 12 分岐前 分岐後 左の葉 右の葉 分岐前
13.
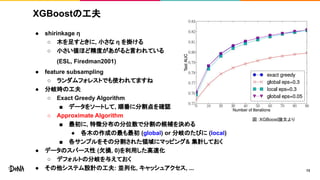
XGBoostの工夫 ● shirinkage η ○
木を足すときに, 小さな η を掛ける ○ 小さい値ほど精度があがると言われている (ESL, Firedman2001) ● feature subsampling ○ ランダムフォレストでも使われてますね ● 分岐時の工夫 ○ Exact Greedy Algorithm ■ データをソートして, 順番に分割点を確認 ○ Approximate Algorithm ■ 最初に, 特徴分布の分位数で分割の候補を決める ● 各木の作成の最も最初 (global) or 分岐のたびに (local) ■ 各サンプルをその分割された領域にマッピング& 集計しておく ● データのスパース性 (欠損, 0)を利用した高速化 ○ デフォルトの分岐を与えておく ● その他システム設計の工夫: 並列化, キャッシュアクセス, ... 13 図:XGBoost論文より
14.
XGBoostライブラリのパラメータ 14https://xgboost.readthedocs.io/en/latest/parameter.html より
15.
③:LightGBM Kaggleでよく使われる高速化された手法 15
16.
LightGBM ● 高速化する工夫が入っている ○ Gradient-based
One-Side Sampling (GOSS) ■ 小さい勾配を持つサンプルを除去 ○ Exclusive Feature Bundling (EFB) ■ 排他的な特徴をまとめて扱う ● LightGBMはヒストグラムベース ○ XGBoostはオプションで選べた 16
17.
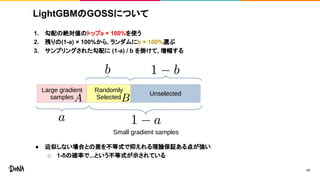
LightGBMのGOSSについて 1. 勾配の絶対値のトップa ×
100%を使う 2. 残りの(1-a) × 100%から, ランダムにb × 100%選ぶ 3. サンプリングされた勾配に (1-a) / b を掛けて, 増幅する ● 近似しない場合との差を不等式で抑えれる理論保証ある点が強い ○ 1-δの確率で...という不等式が示されている 17
18.
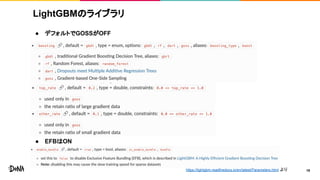
LightGBMのライブラリ ● デフォルトでGOSSがOFF ● EFBはON 18https://lightgbm.readthedocs.io/en/latest/Parameters.html
より
19.
④:CatBoost カテゴリ変数に強いが, 遅いのがネック 19
20.
CatBoost ● ターゲットエンコーディングに基づく ○ カテゴリ変数を予測の平均値で置き換える ○
論文内ではTS (Target Statistic)と呼ばれている ● リークを防ぎつつ, 全訓練データをTSと学習使う ● Ordered TS: (オンライン学習からインスパイアされた) ○ 訓練サンプルにランダムな順列σを導入 ○ 各サンプルのカテゴリ値は, 順列σに従ってTSされる ○ 最初の方のサンプルは分散が大きいため, Boostingステップで異なる順列を使う 20 動物 y TS Ordered TS 猫 1 0.5 0 犬 1 2/3 0 鳥 1 1 0 猫 0 0.5 1 犬 0 2/3 1 犬 1 2/3 0.5 順列σ
21.
CatBoost論文内で既存手法への指摘 ● 勾配にフィットする木を作成するステップにおいて, 勾配の分布がテストデータと学習データでずれている!! (汎化性能に影響) →モデルFt-1 の学習にxk を使っているのが原因 21 勾配
決定木
22.
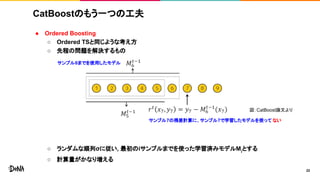
CatBoostのもう一つの工夫 ● Ordered Boosting ○
Ordered TSと同じような考え方 ○ 先程の問題を解決するもの ○ ランダムな順列σに従い, 最初のiサンプルまでを使った学習済みモデルMi とする ○ 計算量がかなり増える 22 サンプル6までを使用したモデル サンプル7の残差計算に, サンプル7で学習したモデルを使って ない 図:CatBoost論文より
23.
CatBoostのライブラリ ● Ordered Boostingは基本的にデフォルトでOFF 23https://catboost.ai/docs/concepts/python-reference_parameters-list.html
より
24.
⑤:NGBoost 不確かさを扱える手法 24
25.
NGBoost ● 不確かさを扱える勾配ブースティング手法 ○ 確率分布を返す ●
任意の弱学習器, 確率分布, スコア関数を使える ● 自然勾配を使って学習 25 https://stanfordmlgroup.github.io/projects/ngboost/ より
26.
NGBoostの構成要素 ● 弱学習器: f
(m) (x) ○ 決定木など ● 確率分布: Pθ (y|x) ○ θはパラメータ ■ 正規分布なら θ = (μ, σ) ● スコア関数: S(Pθ , y) ○ MLE (最尤推定), CRPS (Continuous Ranked Probability Score)など 26 弱学習器 確率分布 スコア関数 図:NGBoost論文より
27.
スコア関数S モデルが出力する分布Pθ と観測データyから計算されるスコア (予測誤差) ● 負の対数尤度
(MLE, 最尤推定) ● Continuous Ranked Probability Score (CRPS) 27
28.
一般化自然勾配 ● 通常の勾配 ○ dがユークリッド空間のノルム ●
一般化自然勾配 ○ 分布Pθ と分布Pθ+d の離れ具合 ○ DS : ダイバージェンス 28
29.
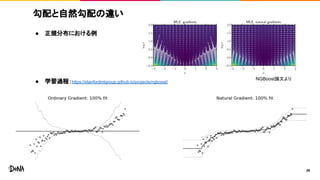
勾配と自然勾配の違い ● 正規分布における例 ● 学習過程:https://stanfordmlgroup.github.io/projects/ngboost/ 29 NGBoost論文より
30.
NGBoostのアルゴリズム 30 NGBoost論文より
31.
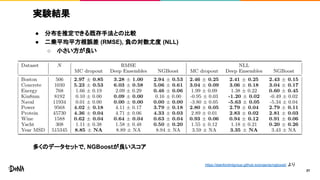
実験結果 ● 分布を推定できる既存手法との比較 ● 二乗平均平方根誤差
(RMSE), 負の対数尤度 (NLL) ○ 小さい方が良い 多くのデータセットで, NGBoostが良いスコア 31 https://stanfordmlgroup.github.io/projects/ngboost/ より
32.
⑥:その他 いろんな活躍が期待される決定木ベースの手法たち 32
33.
その他 木を連ねてニューラルネットに対抗しようとしている人たちがいる ● Deep Forest ●
Multi-Layered Gradient Boosting Decision Tree 33 https://papers.nips.cc/paper/7614-multi-layered-gradient-boosting-decision-trees.pdf より
Download



























![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)































