Recommended
PDF
PDF
Linux KVM環境におけるGPGPU活用最新動向
PDF
ODP
DRBD/Heartbeat/Pacemakerで作るKVM仮想化クラスタ
PDF
(JP) GPGPUがPostgreSQLを加速する
PDF
Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp
PDF
PDF
Maxwell と Java CUDAプログラミング
PDF
1076: CUDAデバッグ・プロファイリング入門
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17)
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ (BPStudy38)
PDF
Ubuntuとコンテナ技術 What is LXD? and Why? 2015-12-08
PDF
C#, C/CLI と CUDAによる画像処理ことはじめ
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
PDF
1075: .NETからCUDAを使うひとつの方法
PDF
PDF
“bcache”を使ってSSDの速さと HDDの大容量のいいとこどり 2015-12-12
KEY
PDF
KVM Cluster with DRBD, ioDrive2 and Infiniband (130802 OSC京都)
PDF
PDF
30分でRHEL6 High Availability Add-Onを超絶的に理解しよう!
PDF
PDF
もしCloudStackのKVMホストでPCIパススルーできるようになったら
PDF
GPU仮想化最前線 - KVMGTとvirtio-gpu -
PDF
PDF
PDF
retrobsd-2012-JUL-07 at JNUG BSD BoF
PDF
PDF
Pythonによる並列プログラミング -GPGPUも-
PDF
More Related Content
PDF
PDF
Linux KVM環境におけるGPGPU活用最新動向
PDF
ODP
DRBD/Heartbeat/Pacemakerで作るKVM仮想化クラスタ
PDF
(JP) GPGPUがPostgreSQLを加速する
PDF
Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp
PDF
PDF
Maxwell と Java CUDAプログラミング
What's hot
PDF
1076: CUDAデバッグ・プロファイリング入門
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17)
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ (BPStudy38)
PDF
Ubuntuとコンテナ技術 What is LXD? and Why? 2015-12-08
PDF
C#, C/CLI と CUDAによる画像処理ことはじめ
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
PDF
1075: .NETからCUDAを使うひとつの方法
PDF
PDF
“bcache”を使ってSSDの速さと HDDの大容量のいいとこどり 2015-12-12
KEY
PDF
KVM Cluster with DRBD, ioDrive2 and Infiniband (130802 OSC京都)
PDF
PDF
30分でRHEL6 High Availability Add-Onを超絶的に理解しよう!
PDF
PDF
もしCloudStackのKVMホストでPCIパススルーできるようになったら
PDF
GPU仮想化最前線 - KVMGTとvirtio-gpu -
PDF
PDF
PDF
retrobsd-2012-JUL-07 at JNUG BSD BoF
PDF
Viewers also liked
PDF
Pythonによる並列プログラミング -GPGPUも-
PDF
PDF
PDF
PDF
PPTX
Pythonとdeep learningで手書き文字認識
PDF
Chainerチュートリアル -v1.5向け- ViEW2015
Similar to GPGPUによるパーソナルスーパーコンピュータの可能性
PDF
KEY
NVIDIA Japan Seminar 2012
PDF
2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
PDF
【旧版】2009/12/10 GPUコンピューティングの現状とスーパーコンピューティングの未来
PDF
PDF
PDF
【A-1】AIを支えるGPUコンピューティングの今
KEY
KEY
PDF
PDF
2015年度GPGPU実践基礎工学 第14回 GPGPU組込開発環境
PPTX
2012 1203-researchers-cafe
PDF
20170421 tensor flowusergroup
PDF
PDF
PDF
PDF
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
KEY
PDF
CPU / GPU高速化セミナー!性能モデルの理論と実践:実践編
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
More from Yusaku Watanabe
PDF
組織をシステム化するReactiveManagement
PDF
エンジニアがプロダクトマネージャーに進化すると何が起きるのか
PDF
PDF
Regional Scrum Gathering® Tokyo 2014
PDF
Jvm operation casual talks
PDF
WEB開発を加速させる。アジャイル開発に最適なデータ構造とORマッパの形
PDF
PageRankアルゴリズムを使った人事評価についての実験
PDF
KEY
実録 WEBエンジニアが Titanium Mobileアプリを開発するまで
PDF
GPGPUによるパーソナルスーパーコンピュータの可能性 1. 2. 概要.........................................................................................................................................3
NVIDIA CUDA について.....................................................................................................4
機能、特徴...........................................................................................................................4
アーキテクチャ....................................................................................................................5
CPU との性能比較..................................................................................................................6
開発環境..................................................................................................................................7
コンパイル、及びオプション.................................................................................................8
デバッグ..................................................................................................................................9
環境構築...............................................................................................................................10
Linux.....................................................................................................................................10
MacOS..................................................................................................................................10
環境の確認.............................................................................................................................11
演算パフォーマンス.............................................................................................................12
考察....................................................................................................................................... 13
2
3. 概要
現在の CPU はムーアの法則と呼ばれる経験則の通り処理能力を上げてきたが、トランジスタ
の集積率の限界、発熱問題などにより限界に達しつつある。
そのため各ベンダーは Intel Core シリーズ、AMD Athlon64 などマルチコア化の道へ踏み出
している。
その流れに対して、GPU は座標変換や光源処理などに使う比較的単純な演算を大量に行うこ
とでグラフィックス性能を今もなお大幅に上げ続けている。
単純な演算であるが故に演算処理をソフトウェアで処理せずに、ハードウェア化し高速化を図
っていることや、ハードウェアによるメニーコアによる処理が可能なことがその下支えとなっ
ている。
GPGPU はそのメニーコア技術を汎用的に利用できるようにする仕組み( General Purpose
Computation on Graphics Processing Unit)、汎用 GPU の」略である。
GPU に搭載されているメニーコアによる演算能力をグラフィックス以外にも利用する技術と
して近年注目を集めている。
長崎大学では GPU を 760 個並列し 158TFLOPS の演算性能をたたき出し、地球シミュレータ
の 122TFLOPS を上回る性能を出した。
ちなみに発表された開発費は 3800 万円である。(※地球シミュレータは 400 億円)
3
4. NVIDIA CUDA について
NVIDIA が提供する GPU を利用した並列コンピューティングアーキテクチャ。
機能、特徴
• GPU で並列アプリケーション開発を行うための標準 C 言語
• FFT (高速フーリエ変換) および BLAS (線形代数の基本サブルーチン)
用標準数値ライブラリ
• GPU と CPU 間での高速データ転送パスを使用したコンピューティング
専用 CUDA ドライバ
• OpenGL および DirectX グラフィックスドライバと CUDA ドライバを同時使
用可能
• Linux 32/64 ビット、Windows XP 32/64 ビット、および Mac の OS を
サポート
4
5. アーキテクチャ
Global Memory
Constant/Texture Memory
Shared Memory Shared Memory Shared Memory Shared Memory
Grid
thread thread thread thread thread thread thread
thread
thread thread thread thread thread thread thread thread
Block Block Block
Block
thread thread thread thread thread thread thread thread
thread thread thread thread thread thread thread thread
実行される thread は Block という単位で束ねられ、それぞれの Block は共有のメモリを持つ
(Shared Memory)。
Block を束ねるものとして Grid という概念があるが、GPU カーネル上で動作する Grid は一
つだけである。
Block は最大で 65536 個生成可能、1Block あたりの最大スレッド数は 512 となっている。
※ ハードウェア的には Block に対応する Processor(StreamingMultiprocessor)と thread
に対応する Processor(ScalarProcessor)の搭載数が違うので、実行順に各 Pocessor に割
り当てられる。
ちなみに各 thread の生成コストは非常に少ない(1 クロック)ので、ソフトウェアで生成
するスレッドのようにあまり生成コストをあまり気にかける必要はない。
メモリは thread ローカルメモリ→ SharedMemory→GlobalMemory の順でレイテンシが大
きくなるので注意が必要。
基本的に read/write 共に 1clock で完了するが、GlobalMemory に関しては 400〰600 クロッ
クのレイテンシが加わる。
5
6. CPU との性能比較
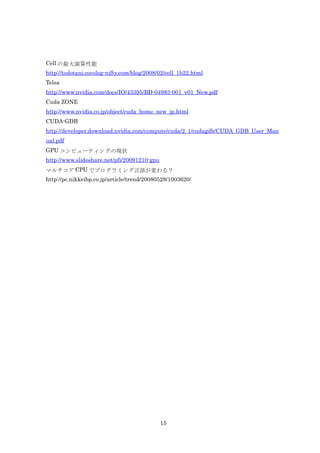
演算装置 製品 クロック周波 core 数 TDP メモリクロッ メモリバンド
数 ク 幅
CPU Corei7 3.33GHz 8 130W 266MHz(DD 17.067GB/sec
R3-2133 の場
(-975 (HT を含む) 合)
Extreme
Edition)
GPU GeForce 1.35 GHz 112 105W 900MHz 57.6GB/sec
9800 GT
GPU(Fel Tesla 1.40GHz 512 225W 2048MHz 170GB/sec
mi 2070
GPU は CPU に比べて、クロック周波数が低いものの core 数が文字通り桁違いに多く搭載さ
れていることがわかる。
またメモリ性能についても 3 倍~10 倍の性能差がある。
※Felmi は NVIDIA の次世代 GPU アーキテクチャ
6
7. 開発環境
CUDA ドライバ
CUDA ツールキット一式
CUDA SDK コードサンプル
が NVIDIA からダウンロード可能。
SDK には以下の内容が含まれる
nvcc C コンパイラ
GPU のための CUDA FFT および BLAS ライブラリ
プロファイラ
GPU のための gdb デバッガ
CUDA ランダムドライバ(標準 NVIDIA GPU ドライバでも使用可能)
CUDA プログラミングマニュアル
7
8. コンパイル、及びオプション
C 言語で記載されたソースコード( cuda 用には拡張子.cu 使う)を nvcc を使ってコンパイル
を行う。
主な(よく使う)オプションは
--output-file <file> (-o)
ファイル出力先の指定をする
--pre-include <include-file> (-include)
include ファイルの指定を行う。
Cuda 用のユーティリティとして cutil が提供されているので、そのヘッダーファイル
(cutil.h)の指定を行う
--library <library> (-l)
ライブラリの指定を行う。
--device-debug <level> (-G)
デバッグ時はこのオプションをつけてコンパイルする必要がある。
--device-emulation (-deviceemu)
GPU が搭載されていない環境で実行する際はエミュレーションモードで起動する必要が
あるので、このオプションを付加する。
例)
nvcc –g –G -o /home/hoge/cudaDev/affineConvertOnCuda –include /home/hoge/
/NVIDIA_GPU_Computing_SDK/C/common/inc/cutil.h
/home/hoge/cudaDev/affineConvertOnCuda.cu
8
9. デバッグ
cuda-gdb を利用する。
基本的な使い方は GDB を踏襲するが以下の拡張機能がある。
デバイス(GPU)メモリ上の変数を参照可能
スレッド間の切り替え可能(thread <<<(BX,BY),(TX,TY,TZ)>>>)
CUDA 上のブロック数、スレッド数を参照可能(info cuda threads)
上記機能拡張によりスレッドを切り替えて、ステップ実行というような細かいデバッグが可能
である。
[yuhsaku@localhost cudaDev]$ cuda-gdb affineConvertOnCuda ←cuda-gdb をプログラム指定で
起動
(cuda-gdb) break affineConvertOnCuda.cu :73 ←73 行 目 に ブ レ イ ク ポ イ ン ト を
設定
(cuda-gdb) run ←実行
[Current CUDA Thread <<<(0,0),(0,0,0)>>>] ←現在のスレッドが表示される
Breakpoint 1, convert () at /home/yuhsaku/cudaDev/affineConvertOnCuda.cu:73
73 to_matrix_p[to_counter] = matrix_p[counter];←73 行目のコードが表示される
Current language: auto; currently c++
(cuda-gdb) print counter ← 現 在 の ス レ ッ ド の 変 数 counter を 表 示
する
$1 = 0
(cuda-gdb) info cuda threads ←現在の全スレッドを確認する
<<<(0,0),(0,0,0)>>> ... <<<(15,0),(23,0,0)>>> convert ()
at /home/yuhsaku/cudaDev/affineConvertOnCuda.cu:73
(cuda-gdb) thread <<<(1,0),(1,0,0)>>> ←ブロック 1 の中のスレッド 1 に切り替え
る
(cuda-gdb) print counter ← 切 り 替 え た ス レ ッ ド の 変 数 counter を
表示する
$1 = 1
(cuda-gdb) cont ←次のブレイクポイントまで実行する
9
10. 11. 環境の確認
deviceQuery を実行し、CUDA が利用可能か確認する
※ GPU が対応していない、認識されない場合は以下の Device の箇所が
Device 0: "Device Emulation (CPU)"
と表示される。
以下に主要な情報について記載する
[yuhsaku@localhost release]$ ./deviceQuery
CUDA Device Query (Runtime API) version (CUDART static linking)
There is 1 device supporting CUDA
Device 0: "GeForce 9800 GT"
CUDA Driver Version: 2.30
CUDA Runtime Version: 2.30
CUDA Capability Major revision number: 1
CUDA Capability Minor revision number: 1
Total amount of global memory: 1073020928 bytes ←グローバルメモリ
Number of multiprocessors: 14
Number of cores: 112 ←コア数
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes ←ブロック別の shared メモリ
Total number of registers available per block: 8192
Warp size: 32
Maximum number of threads per block: 512 ←1 ブ ロ ッ ク 内 に 設 定 で き る
thread 数
Maximum sizes of each dimension of a block: 512 x 512 x 64
Maximum sizes of each dimension of a grid: 65535 x 65535 x 1
Maximum memory pitch: 262144 bytes
Texture alignment: 256 bytes
Clock rate: 1.35 GHz ←クロック
Concurrent copy and execution: Yes
Run time limit on kernels: No
Integrated: No
Support host page-locked memory mapping: No
Compute mode: Default (multiple host threads can use this device simultaneously)
11
12. 演算パフォーマンス
行列同士を積算させるプログラムをコンパイルして実行を行い検証する。
環境:CentOS5.4, Corei3、 mem4G, GeForce 9800GT
※ サンプルコードは別途参照
※CPU での処理はシングルスレッドのため、1 コアしか利用していない
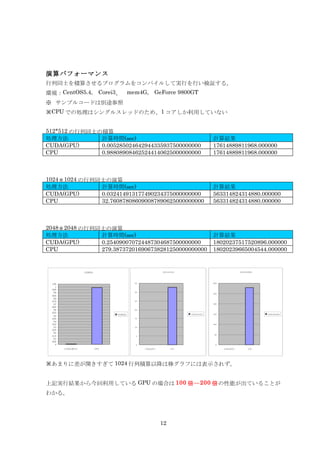
512*512 の行列同士の積算
処理方法 計算時間(sec) 計算結果
CUDA(GPU) 0.005285024642944335937500000000 17614889811968.000000
CPU 0.988089084625244140625000000000 17614889811968.000000
1024*1024 の行列同士の演算
処理方法 計算時間(sec) 計算結果
CUDA(GPU) 0.032414913177490234375000000000 563314824314880.000000
CPU 32.760878086090087890625000000000 563314824314880.000000
2048*2048 の行列同士の演算
処理方法 計算時間(sec) 計算結果
CUDA(GPU) 0.254090070724487304687500000000 18020237517520896.000000
CPU 279.387372016906738281250000000000 18020239665004544.000000
512*512 1 02 4*102 4 2 04 8*20 48
1.
05 35 30 0
1
0.
95
0.9 30
25 0
0.
85
0.8
0.
75 25
0.7 20 0
0.
65
0.6 20
0.
55
512*512 10 24 *10 24 15 0 20 48 *2 04 8
0.5
0.
45 15
0.4
0.
35 10 0
0.3 10
0.
25
0.2
50
0.
15 5
0.1
0.
05
0 0 0
C U D A (G P U ) CPU C UD A(G PU ) CP U CU DA (GP U) C PU
※あまりに差が開きすぎて 1024 行列積算以降は棒グラフには表示されず。
上記実行結果から今回利用している GPU の場合は 100 倍〰 200 倍の性能が出ていることが
わかる。
12
13. 考察
今回は NVIDIA から提供されている CUDA を利用した。
今後は ATI から提供されている ATI Stream などもあることから、統合フレームワークの
OpenCL を利用した開発が効率的かと思われる。
基本的には演算処理を文字通り桁違いに速くできる(並列化できる)ので、大量の計算処理が
必要な R&D 向きかと思われる。
実際、NVIDIA(CUDA)の採用事例としても物理シミュレーションから石油・ガス探査、製
品設計、医療用画像などが挙げられている。
しかし、今回の検証で得られたことは
・ 並列処理を意識したプログラミングスキルを習得することによって個人でも新た
な可能性を生み出すことができる。
・ 「演算のみ速くできても、(フロントエンドとしての) Web サービスでは利用シー
ンがない」ではなく「常識を覆すほどの演算能力を手に入れることにより、常識を覆
す Web サービスを作ることができる可能性がある」ということを意識できる。
という点になる。
13
14. 15.









![デバッグ
cuda-gdb を利用する。
基本的な使い方は GDB を踏襲するが以下の拡張機能がある。
デバイス(GPU)メモリ上の変数を参照可能
スレッド間の切り替え可能(thread <<<(BX,BY),(TX,TY,TZ)>>>)
CUDA 上のブロック数、スレッド数を参照可能(info cuda threads)
上記機能拡張によりスレッドを切り替えて、ステップ実行というような細かいデバッグが可能
である。
[yuhsaku@localhost cudaDev]$ cuda-gdb affineConvertOnCuda ←cuda-gdb をプログラム指定で
起動
(cuda-gdb) break affineConvertOnCuda.cu :73 ←73 行 目 に ブ レ イ ク ポ イ ン ト を
設定
(cuda-gdb) run ←実行
[Current CUDA Thread <<<(0,0),(0,0,0)>>>] ←現在のスレッドが表示される
Breakpoint 1, convert () at /home/yuhsaku/cudaDev/affineConvertOnCuda.cu:73
73 to_matrix_p[to_counter] = matrix_p[counter];←73 行目のコードが表示される
Current language: auto; currently c++
(cuda-gdb) print counter ← 現 在 の ス レ ッ ド の 変 数 counter を 表 示
する
$1 = 0
(cuda-gdb) info cuda threads ←現在の全スレッドを確認する
<<<(0,0),(0,0,0)>>> ... <<<(15,0),(23,0,0)>>> convert ()
at /home/yuhsaku/cudaDev/affineConvertOnCuda.cu:73
(cuda-gdb) thread <<<(1,0),(1,0,0)>>> ←ブロック 1 の中のスレッド 1 に切り替え
る
(cuda-gdb) print counter ← 切 り 替 え た ス レ ッ ド の 変 数 counter を
表示する
$1 = 1
(cuda-gdb) cont ←次のブレイクポイントまで実行する
9](https://image.slidesharecdn.com/random-100419081827-phpapp01/85/GPGPU-9-320.jpg)

![環境の確認
deviceQuery を実行し、CUDA が利用可能か確認する
※ GPU が対応していない、認識されない場合は以下の Device の箇所が
Device 0: "Device Emulation (CPU)"
と表示される。
以下に主要な情報について記載する
[yuhsaku@localhost release]$ ./deviceQuery
CUDA Device Query (Runtime API) version (CUDART static linking)
There is 1 device supporting CUDA
Device 0: "GeForce 9800 GT"
CUDA Driver Version: 2.30
CUDA Runtime Version: 2.30
CUDA Capability Major revision number: 1
CUDA Capability Minor revision number: 1
Total amount of global memory: 1073020928 bytes ←グローバルメモリ
Number of multiprocessors: 14
Number of cores: 112 ←コア数
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes ←ブロック別の shared メモリ
Total number of registers available per block: 8192
Warp size: 32
Maximum number of threads per block: 512 ←1 ブ ロ ッ ク 内 に 設 定 で き る
thread 数
Maximum sizes of each dimension of a block: 512 x 512 x 64
Maximum sizes of each dimension of a grid: 65535 x 65535 x 1
Maximum memory pitch: 262144 bytes
Texture alignment: 256 bytes
Clock rate: 1.35 GHz ←クロック
Concurrent copy and execution: Yes
Run time limit on kernels: No
Integrated: No
Support host page-locked memory mapping: No
Compute mode: Default (multiple host threads can use this device simultaneously)
11](https://image.slidesharecdn.com/random-100419081827-phpapp01/85/GPGPU-11-320.jpg)