Download as PDF, PPTX

















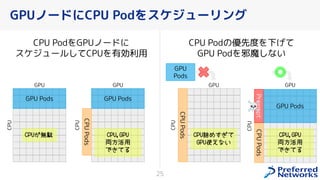

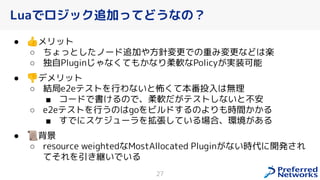
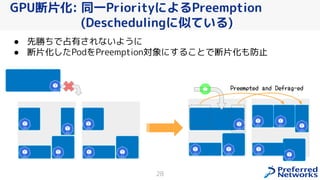


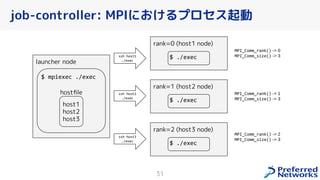
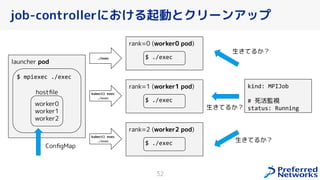


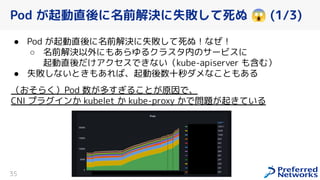
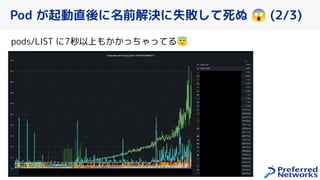
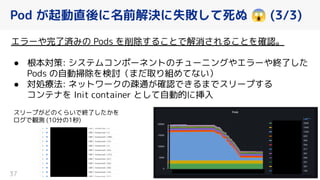


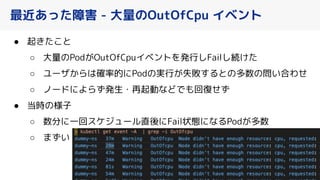
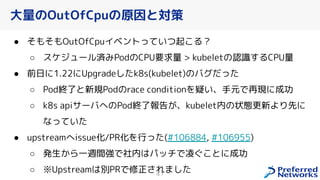

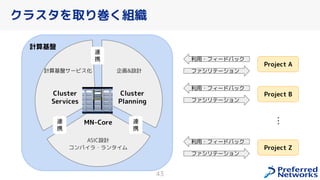
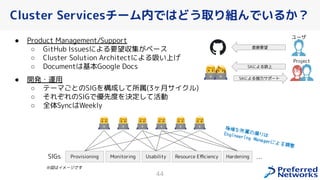

PFN は、「現実世界を計算可能にする」を Vision として,膨大な計算量を必要とするシミュレーションや深層学習などの計算ワークロードを実行するためのオンプレ ML 基盤を持っています。 この発表では、「オンプレクラスタの概要」と最近のトピックとして「新しく構築した「MN-2b」」、「Pod のリソース要求量の最適化を助けるしくみ」、「Kubernetes クラスタのアップグレード」についてお話します。 本イベント「オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜」では、オンプレミスの Kubernetes クラスタ上に構築された機械学習基盤を持つ PFN とヤフーのエンジニアが自社での取り組みについて語り尽くします! イベントサイト: https://ml-kubernetes.connpass.com/event/255797/










































![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)























