Downloaded 226 times







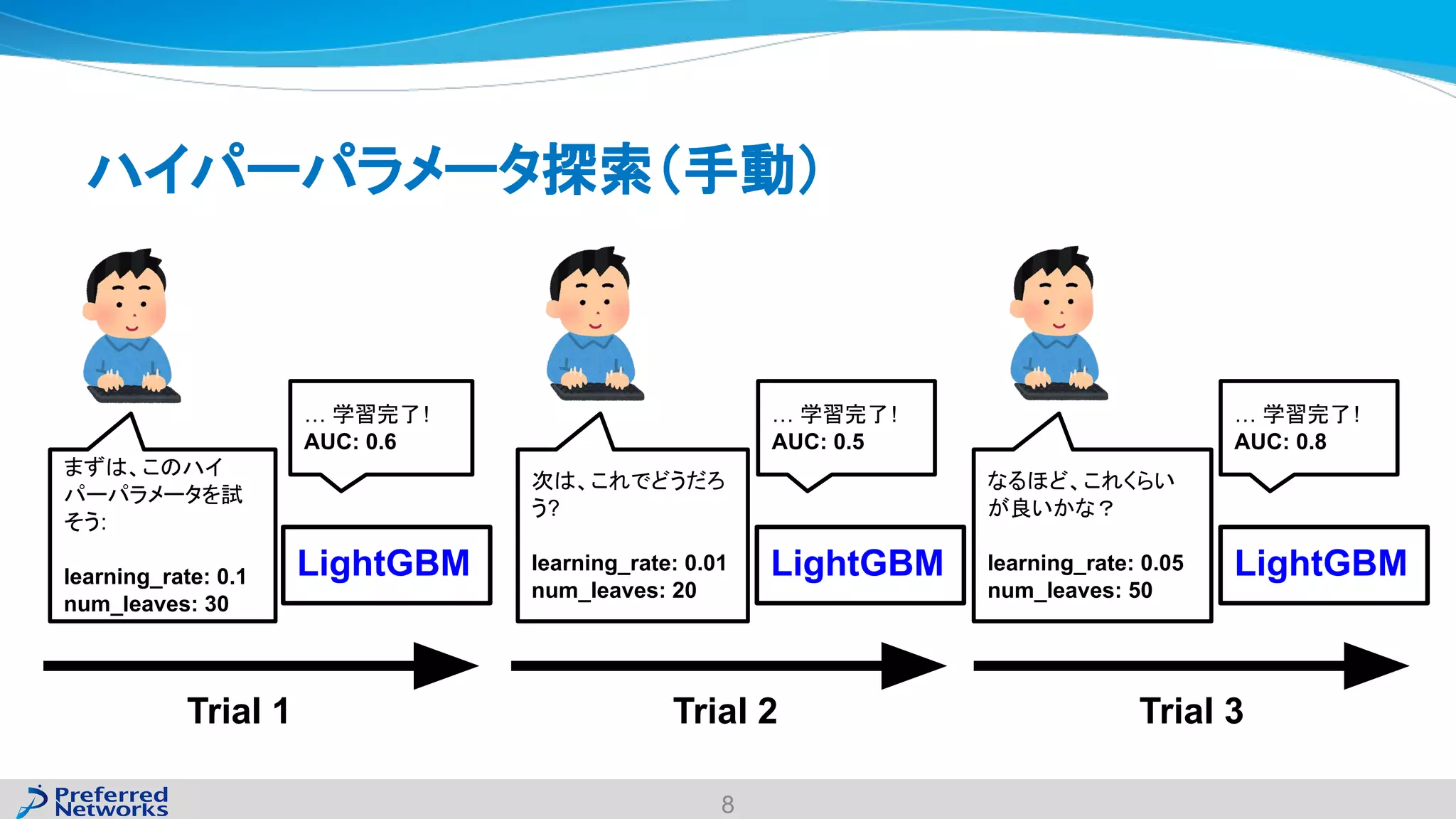
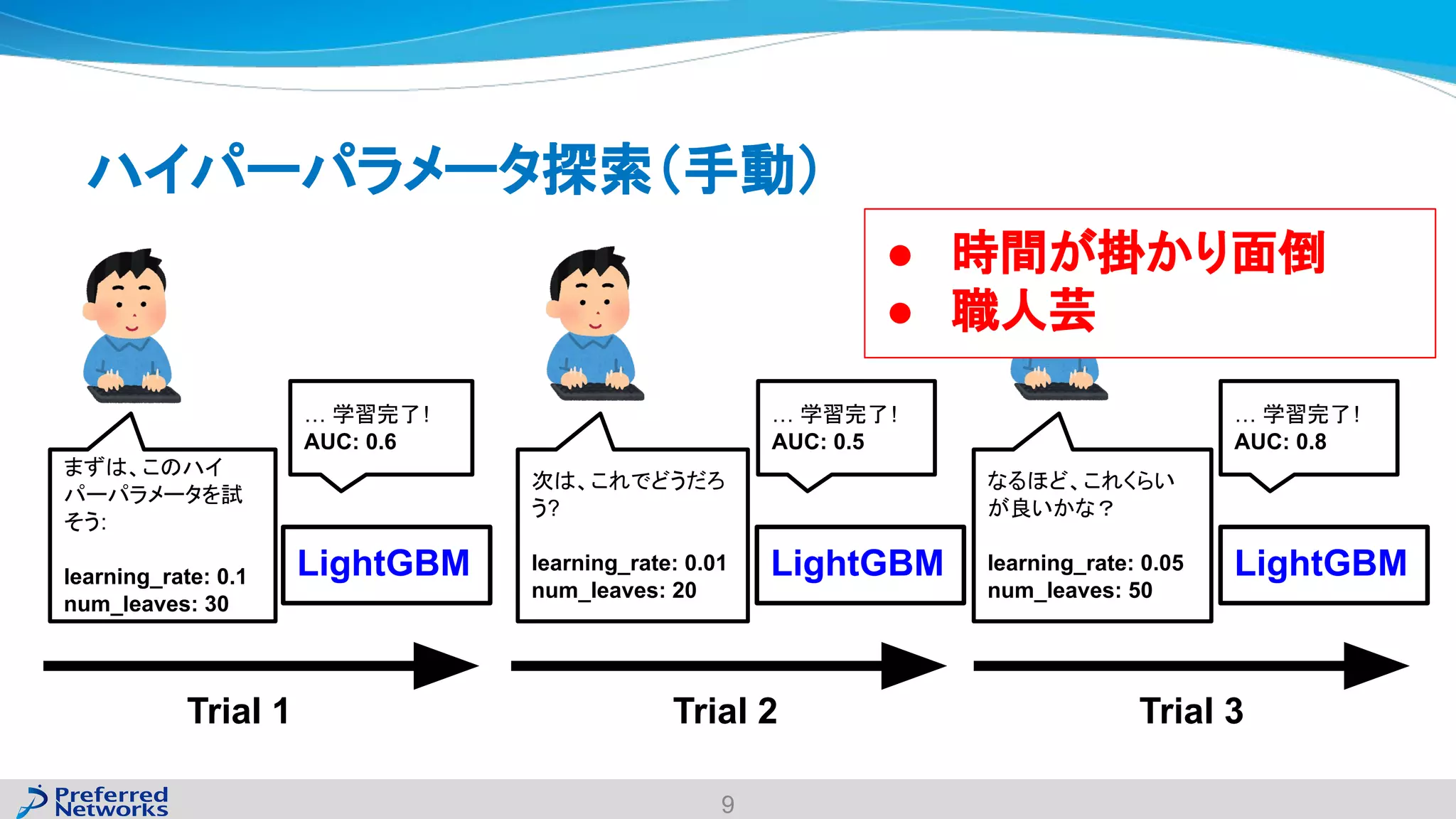
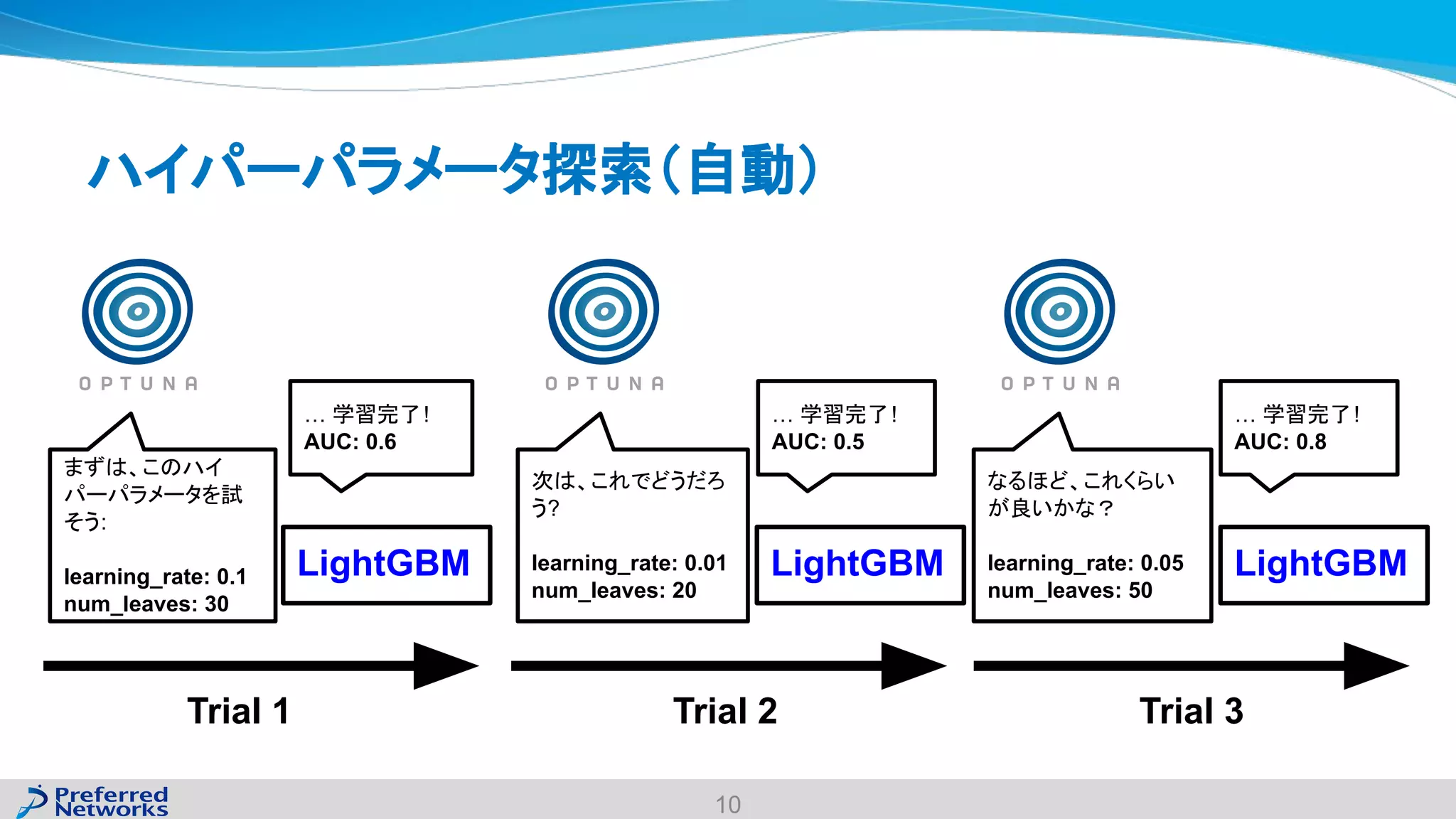


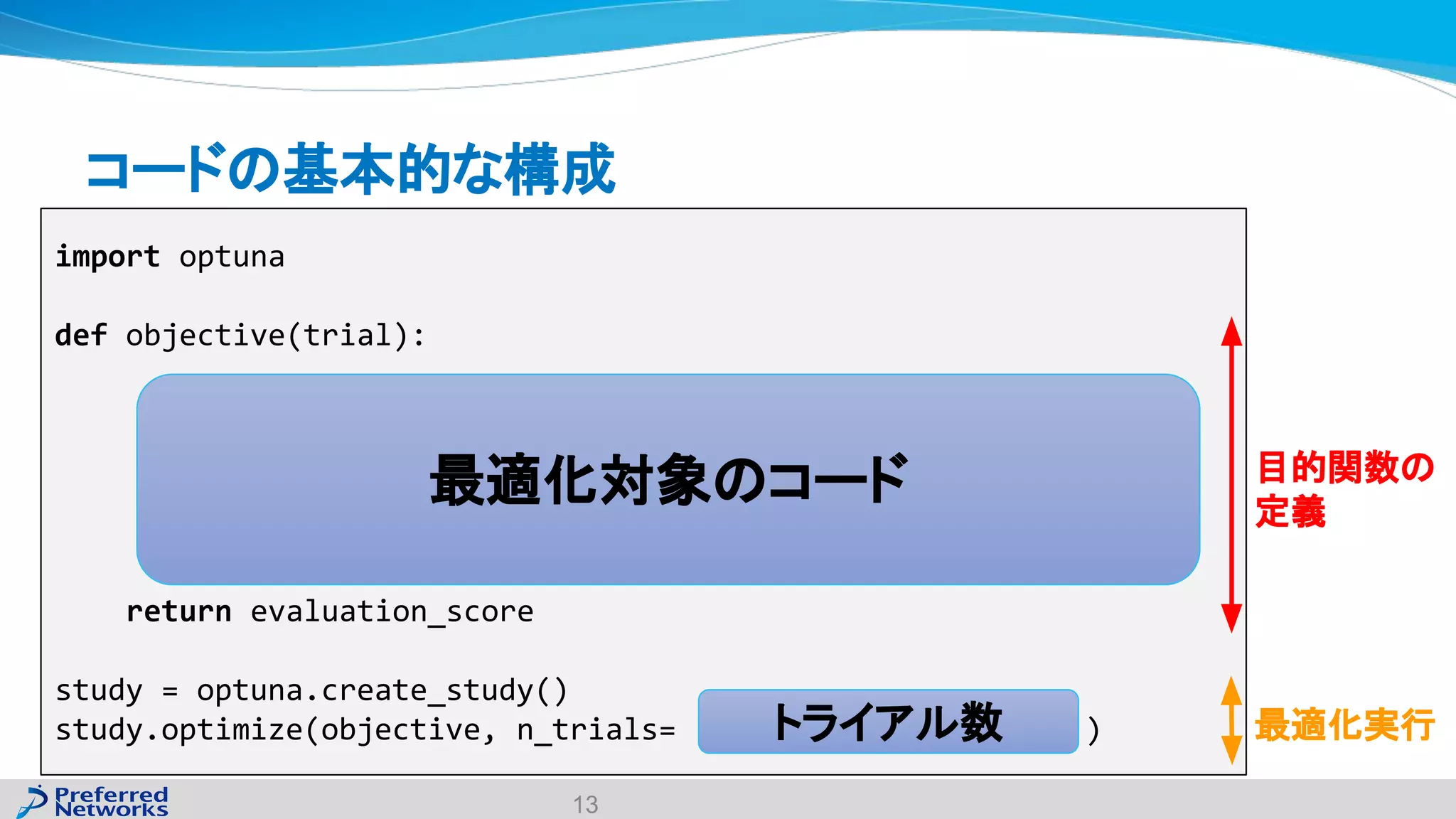
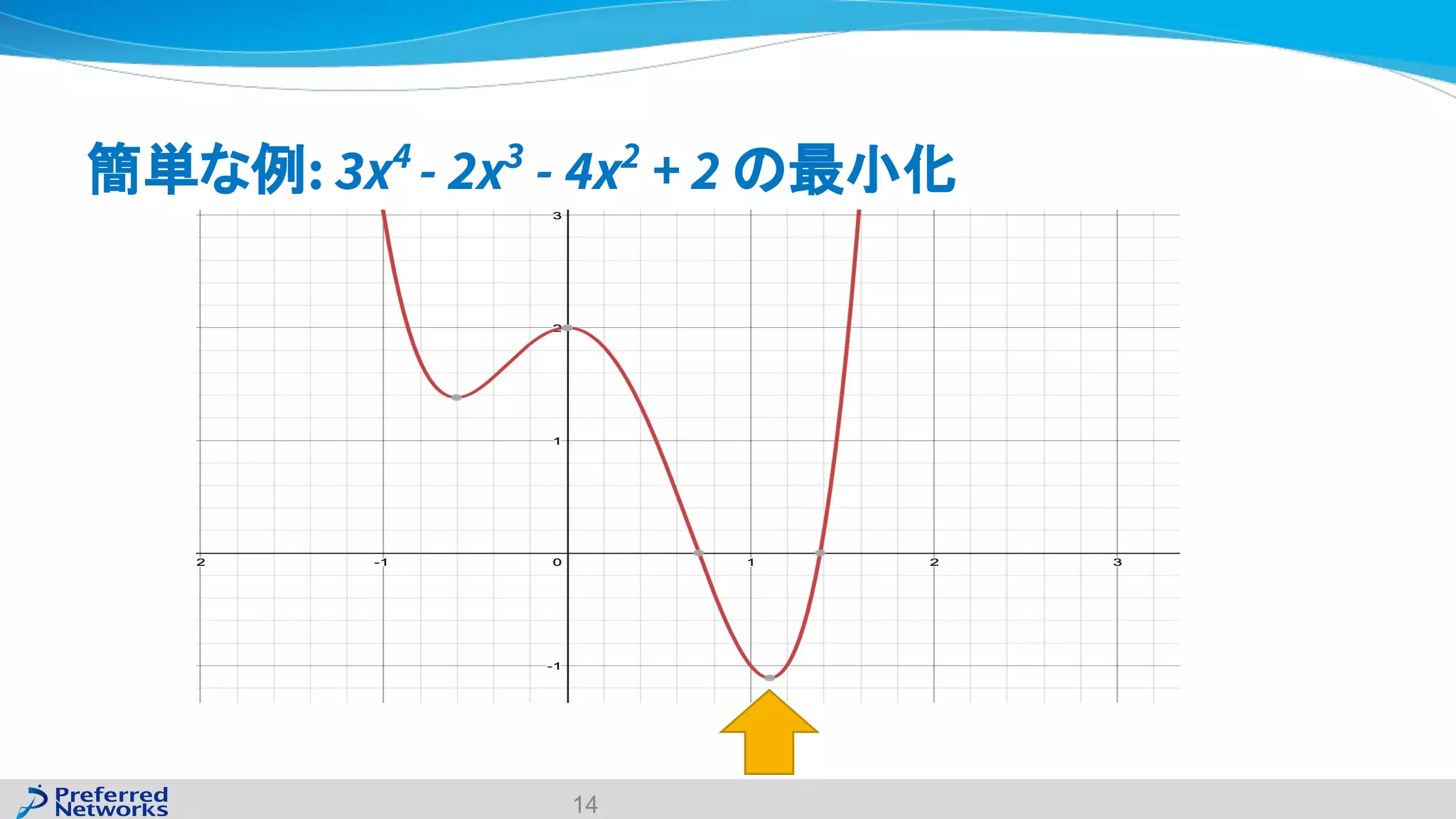

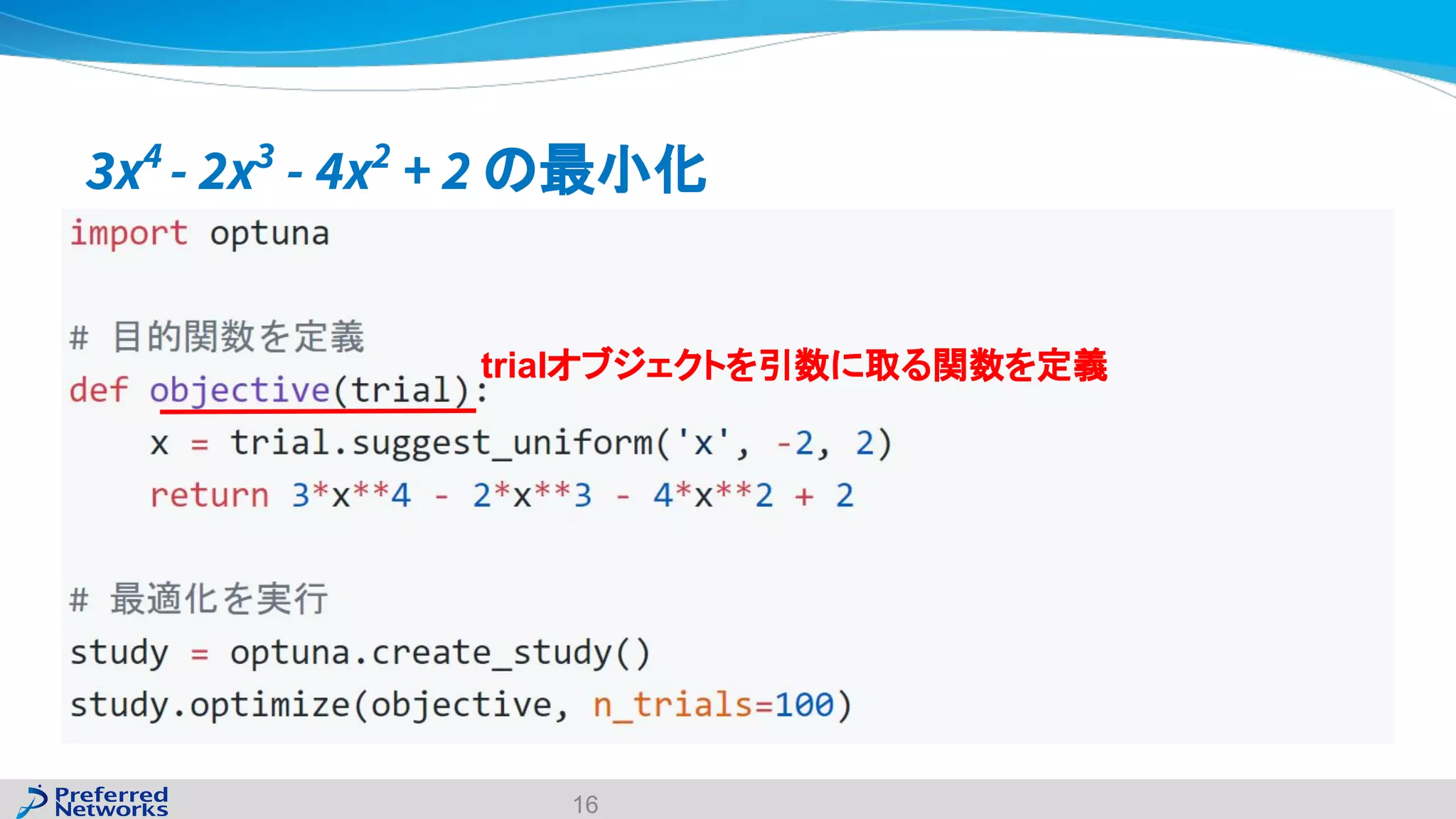


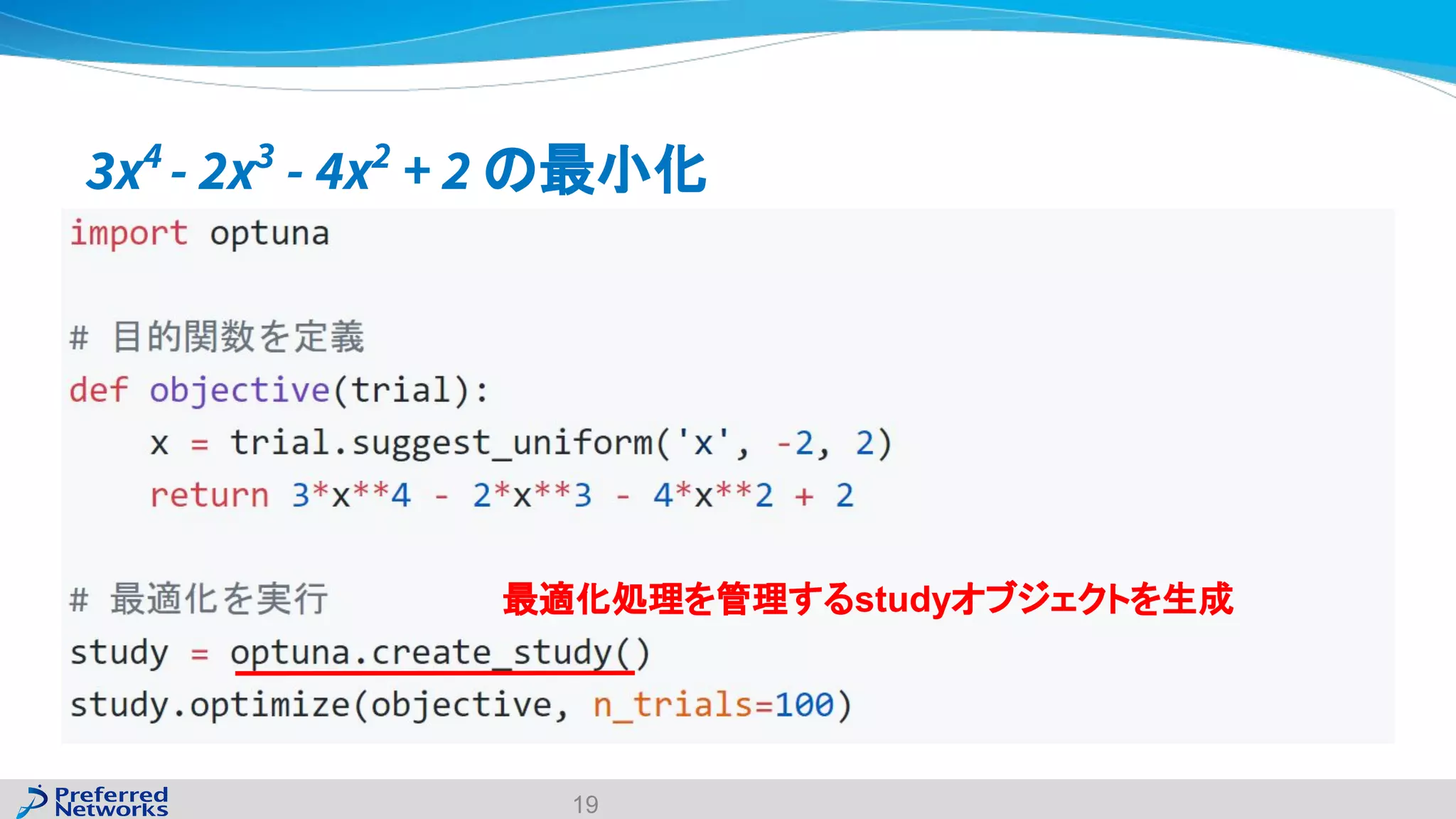

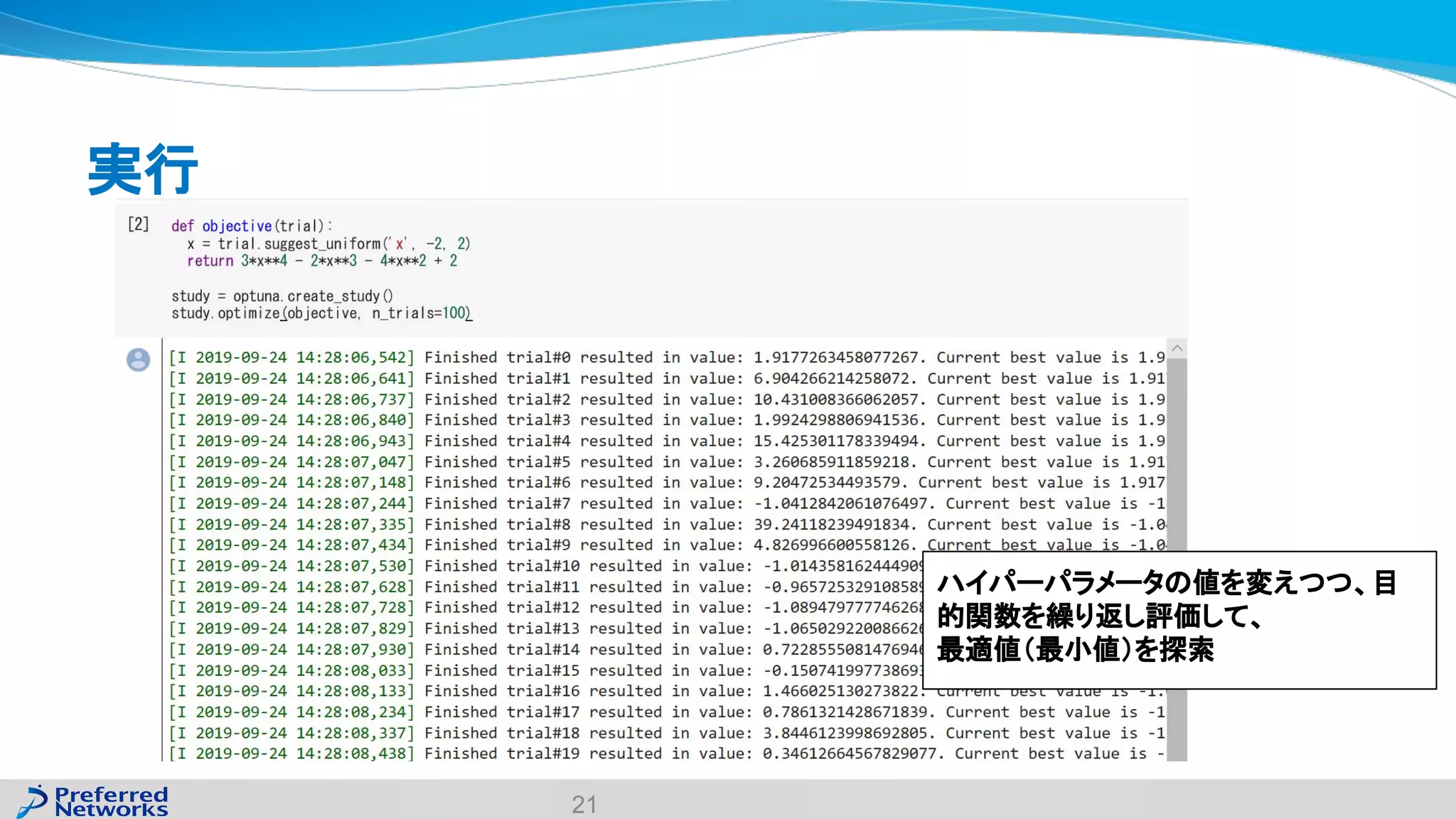
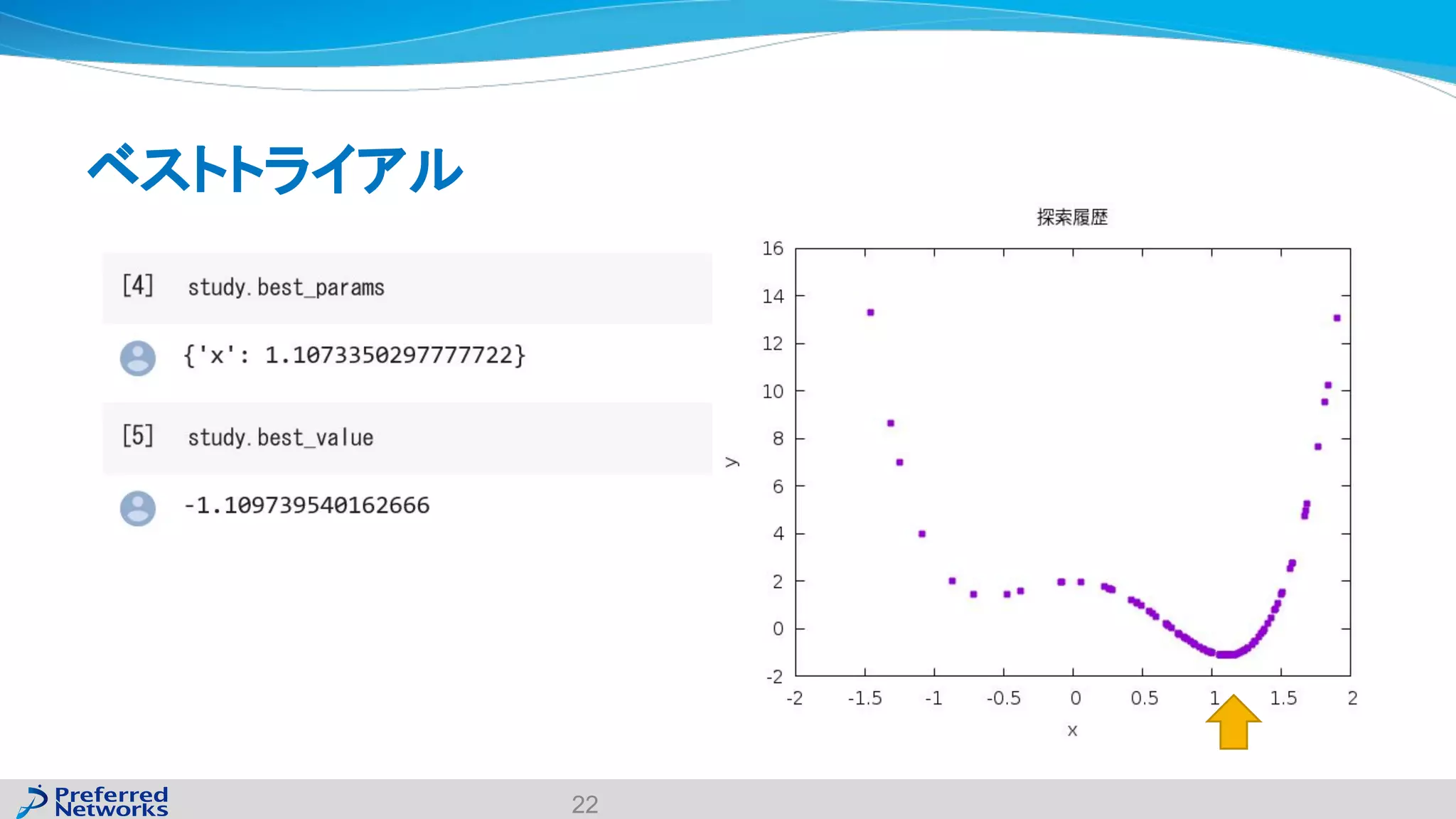
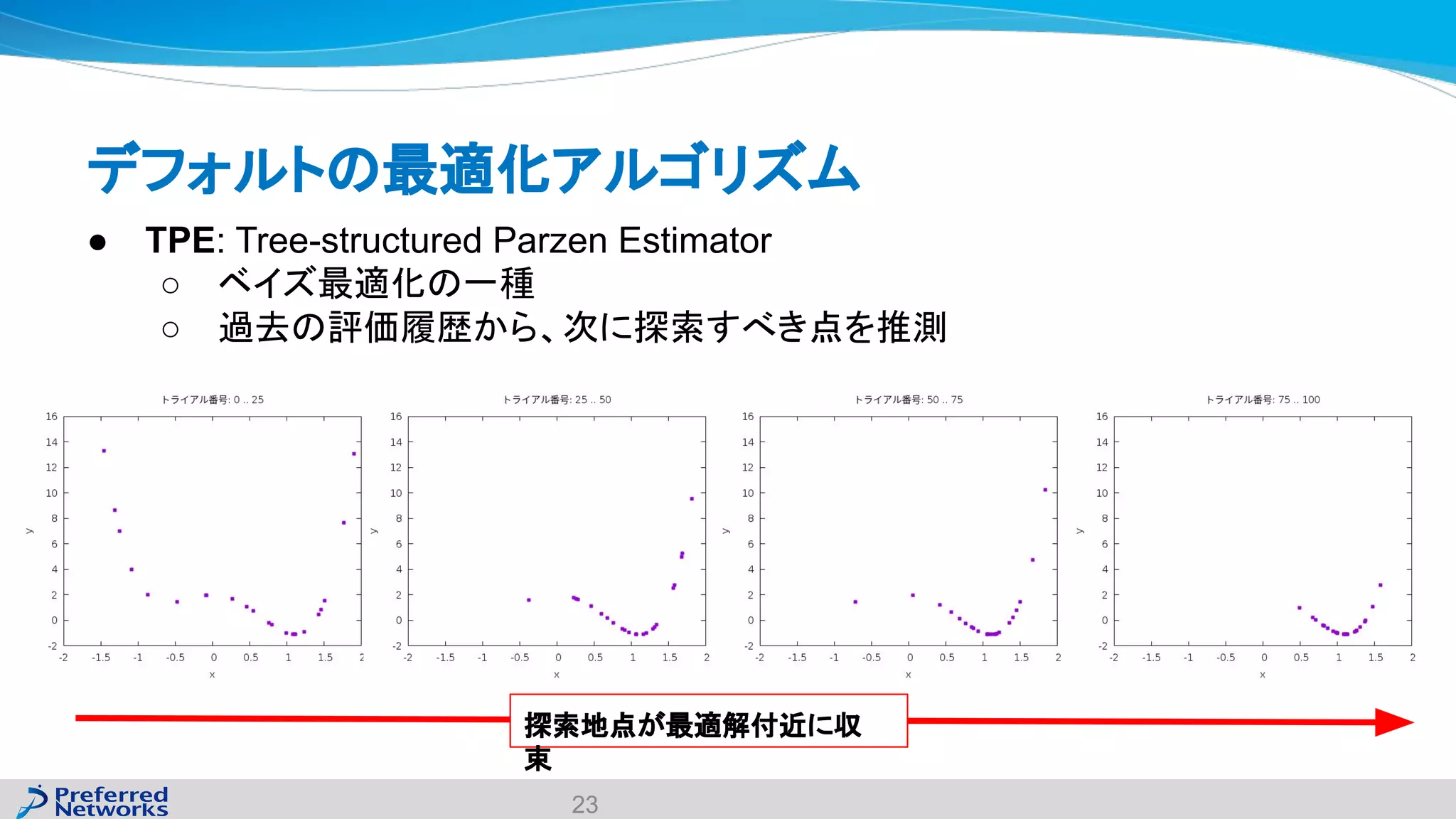
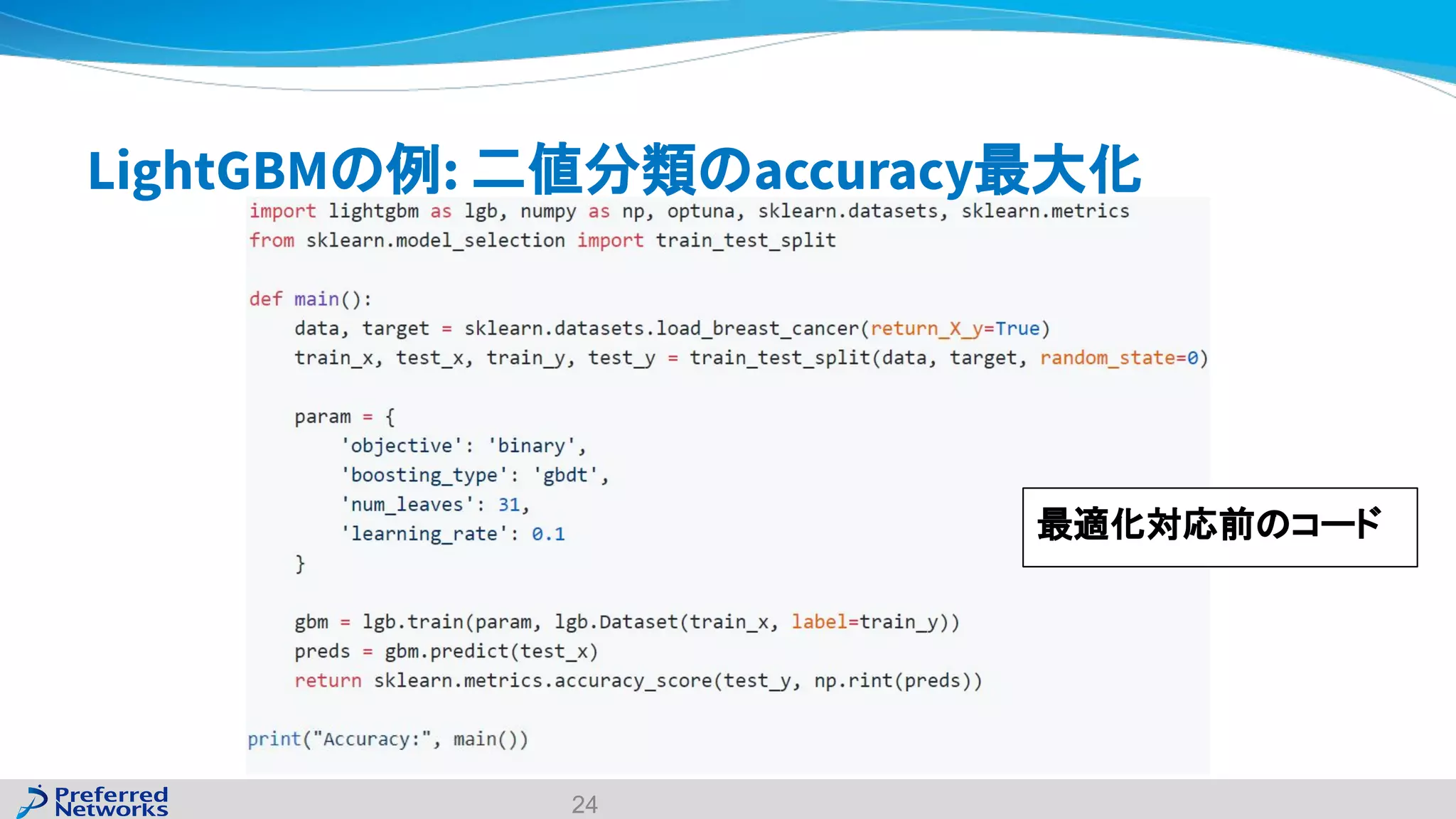
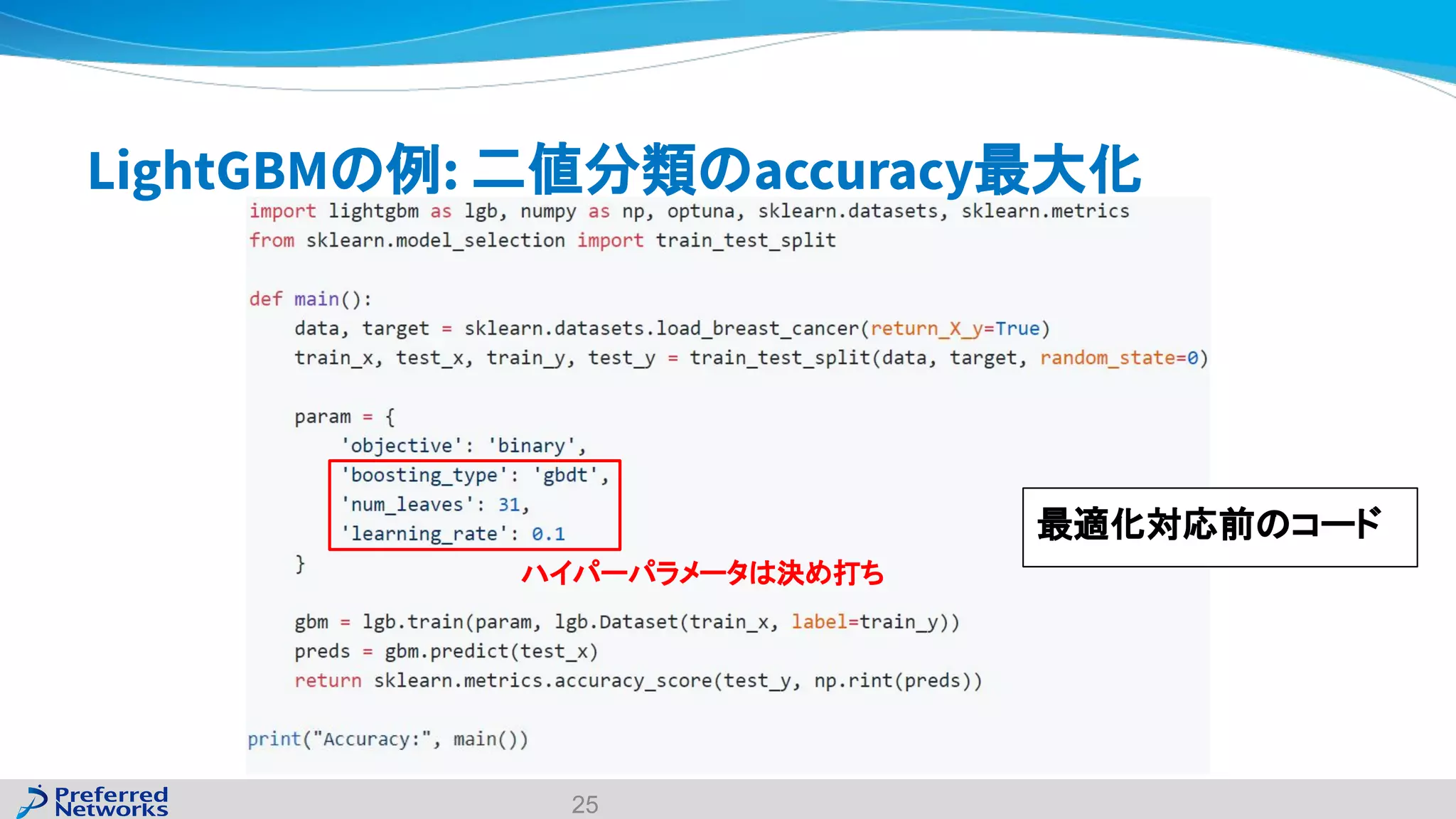
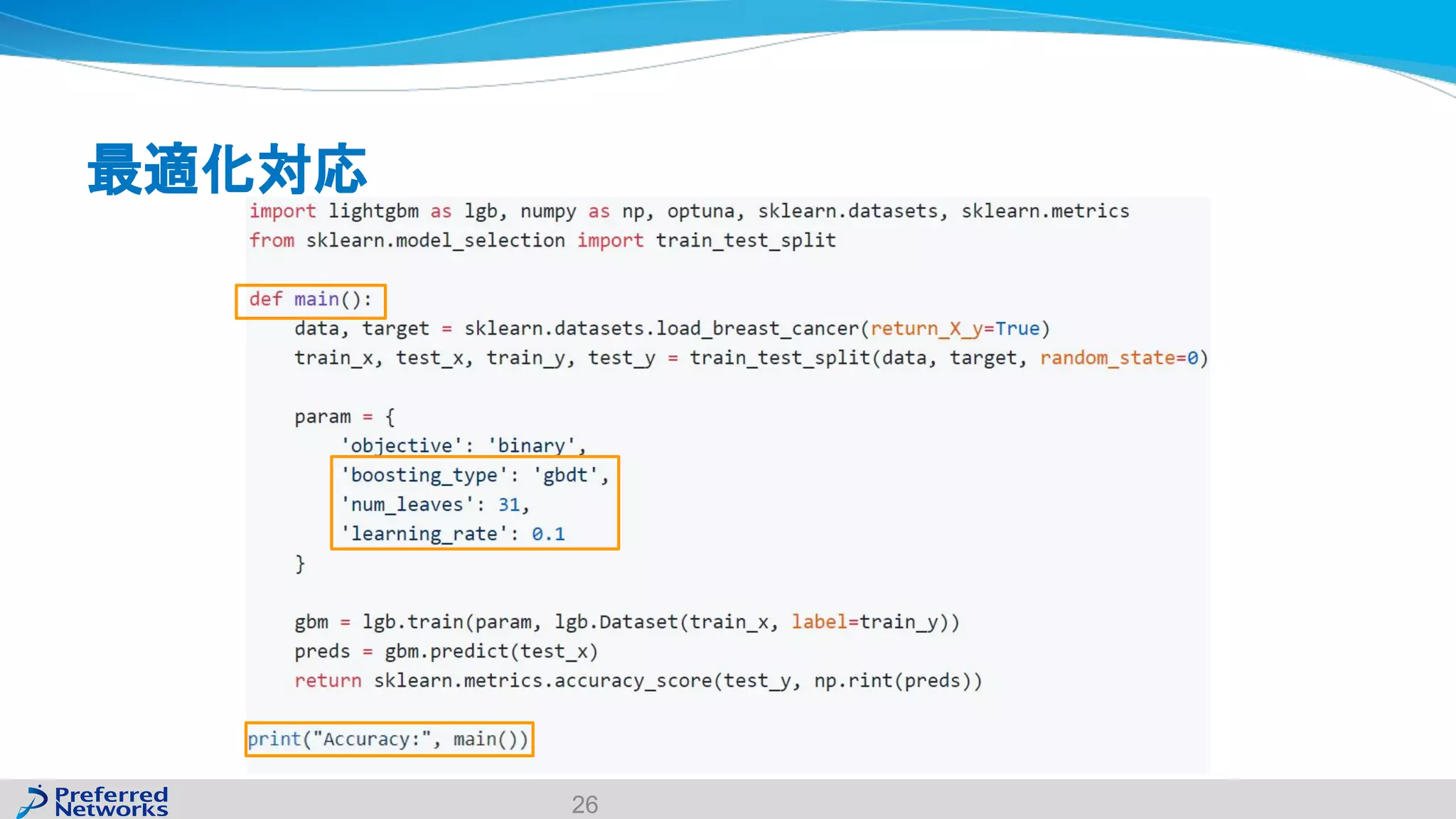

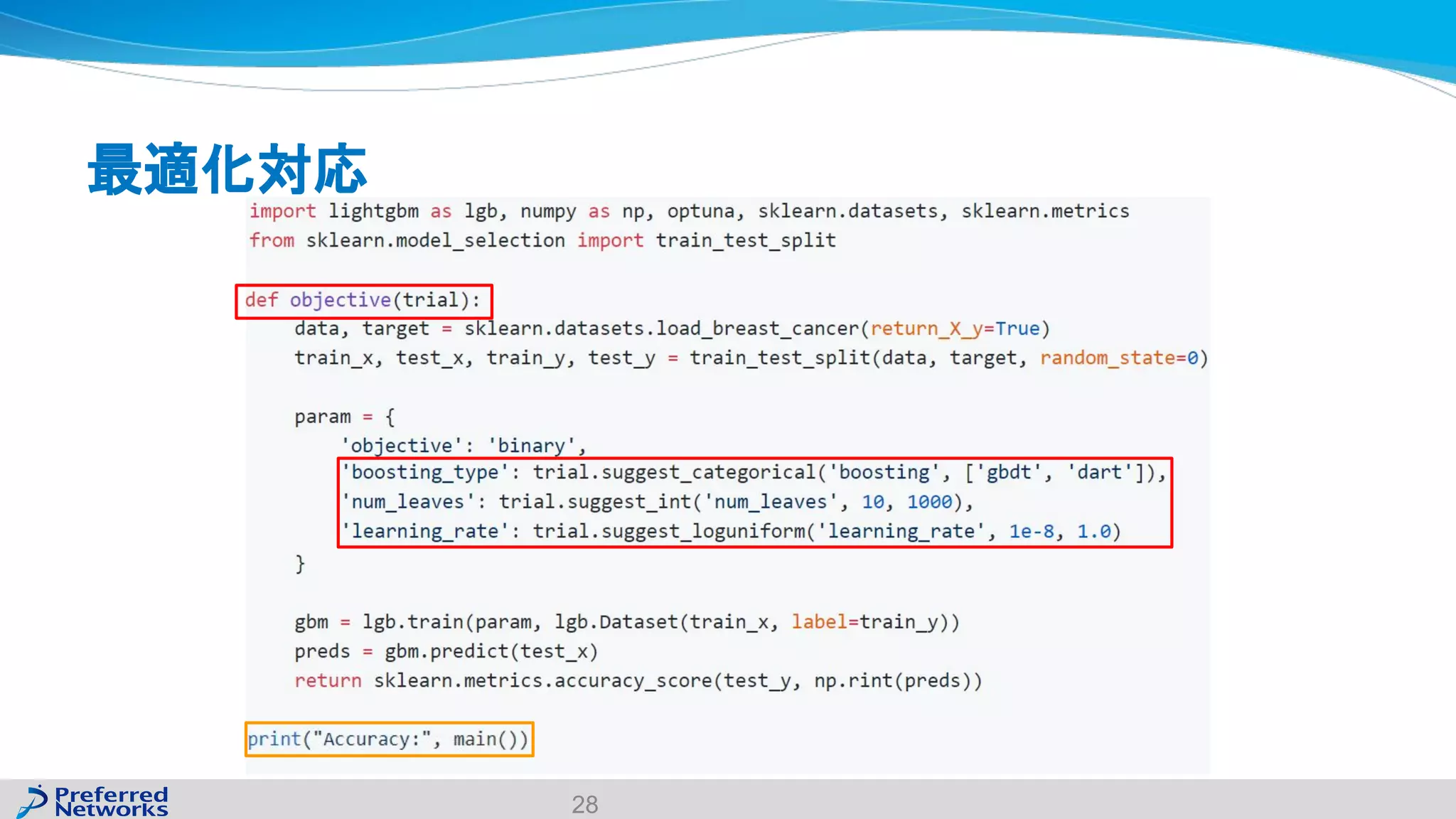
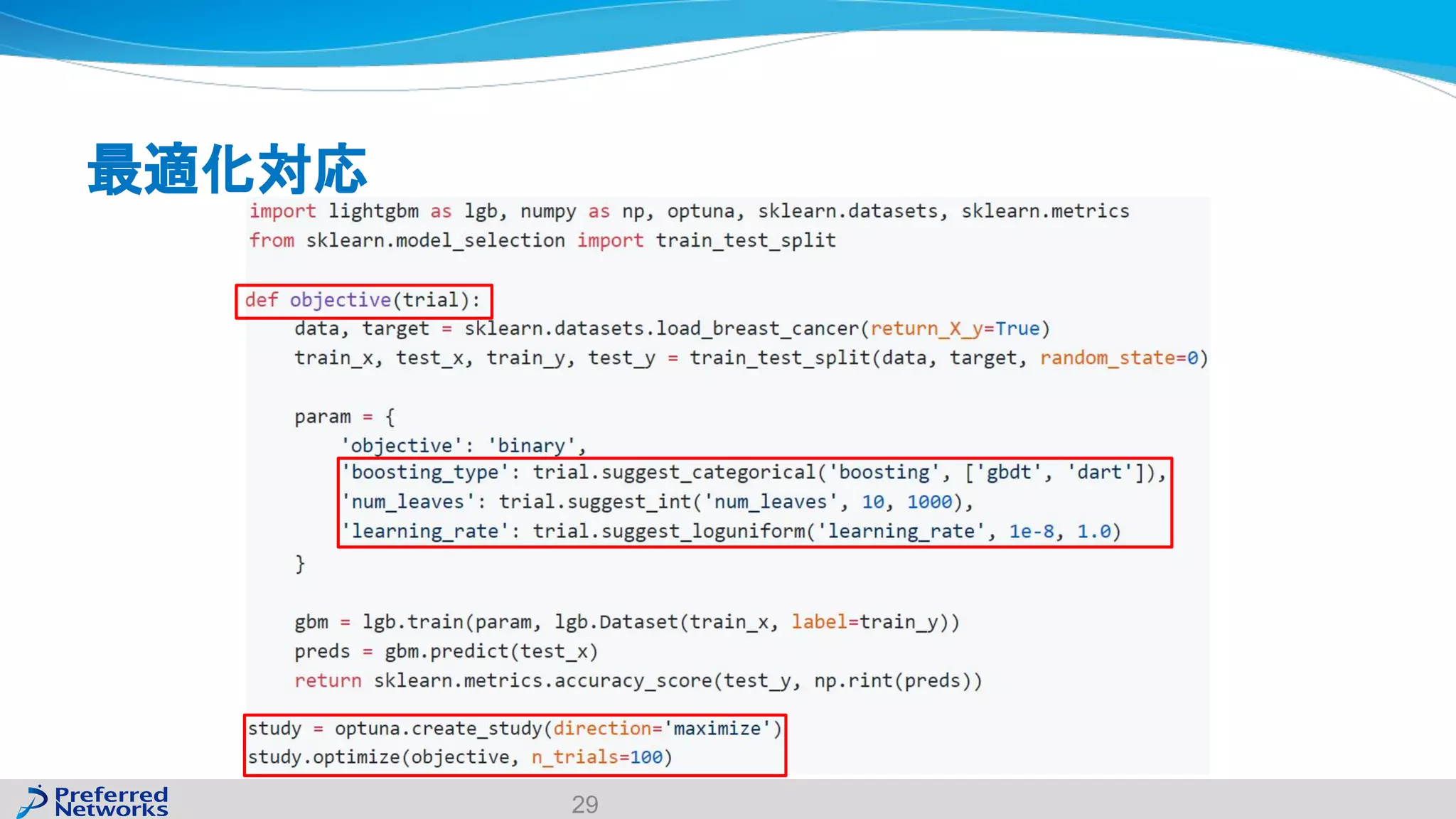


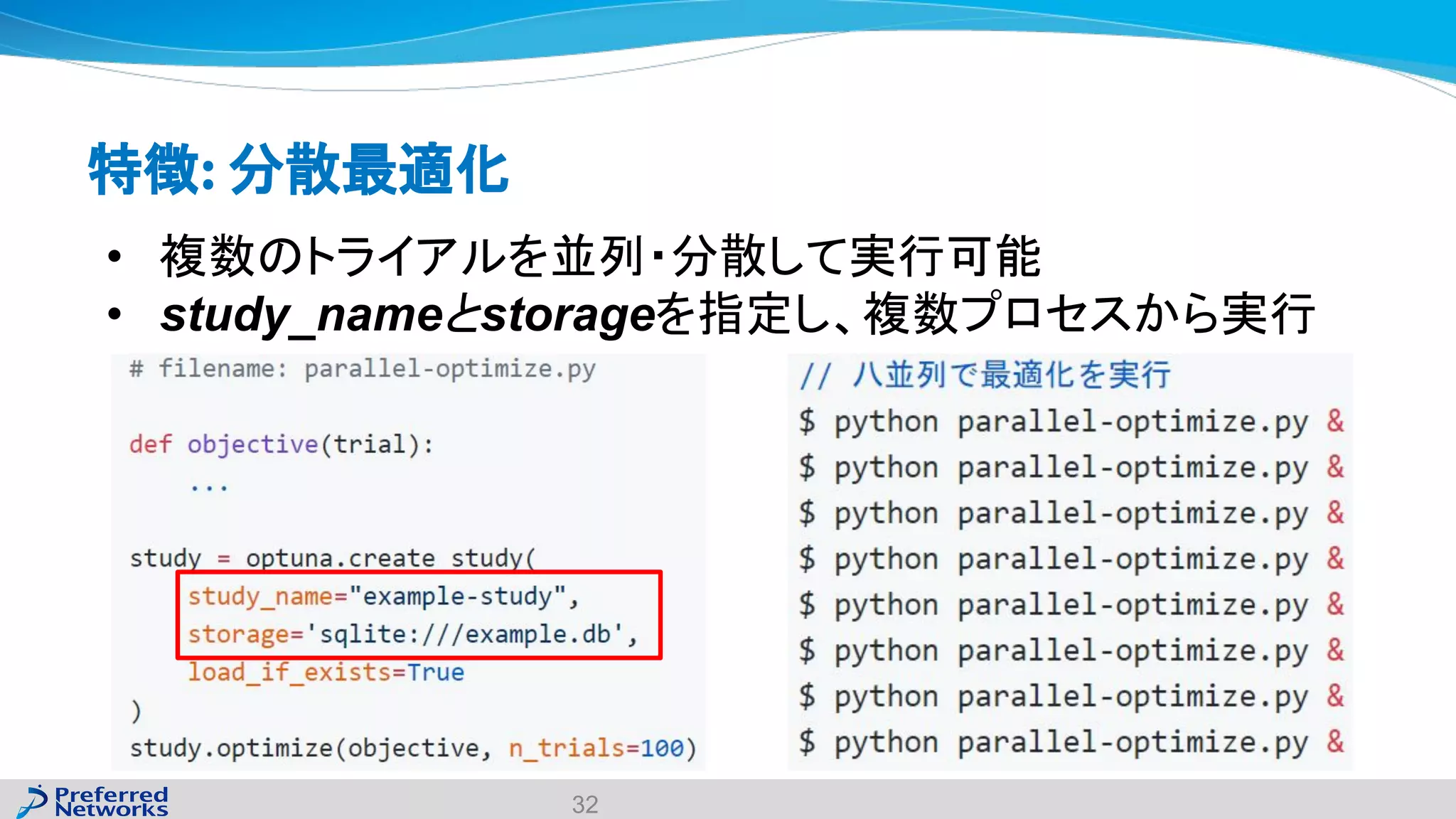
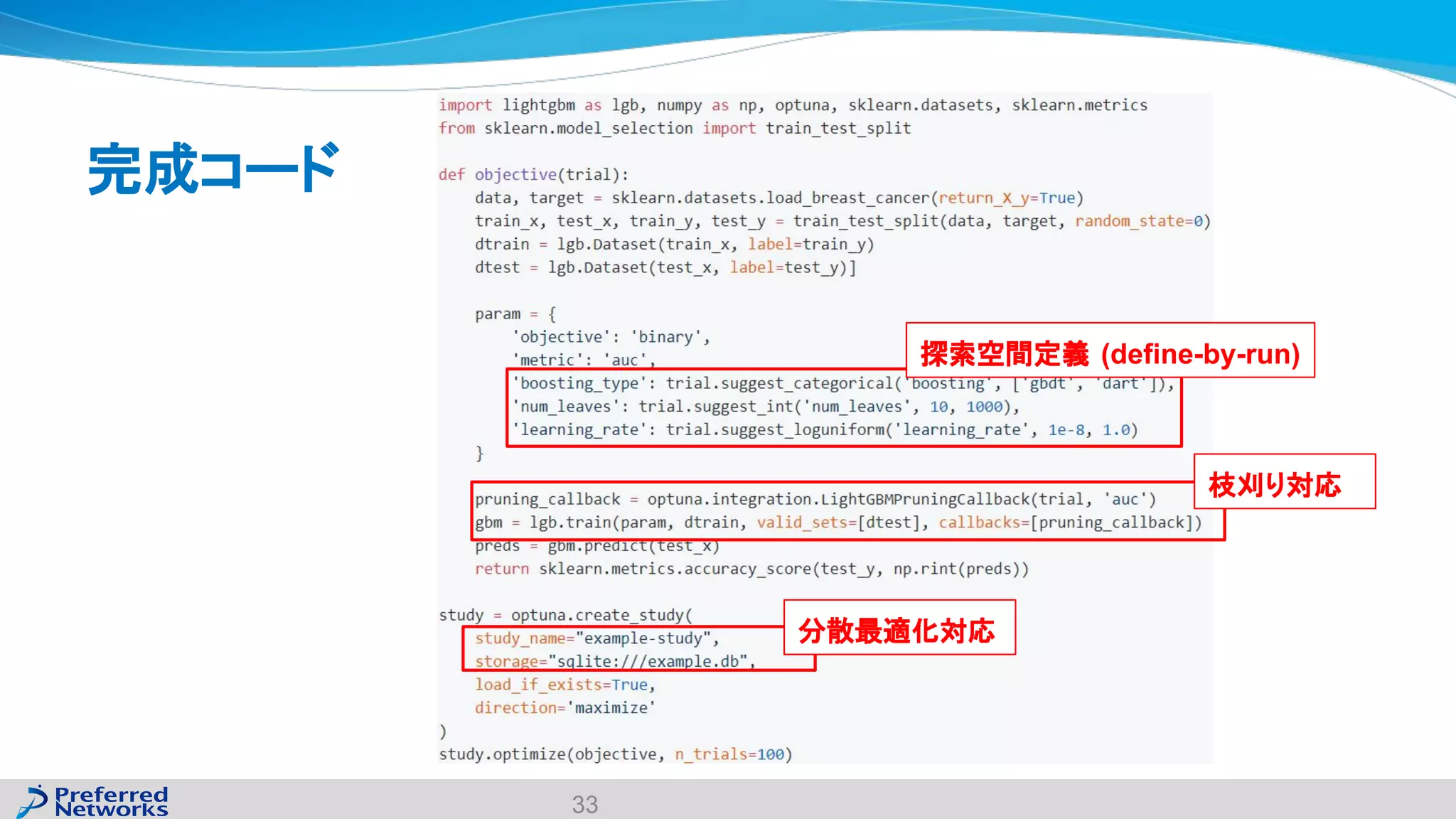


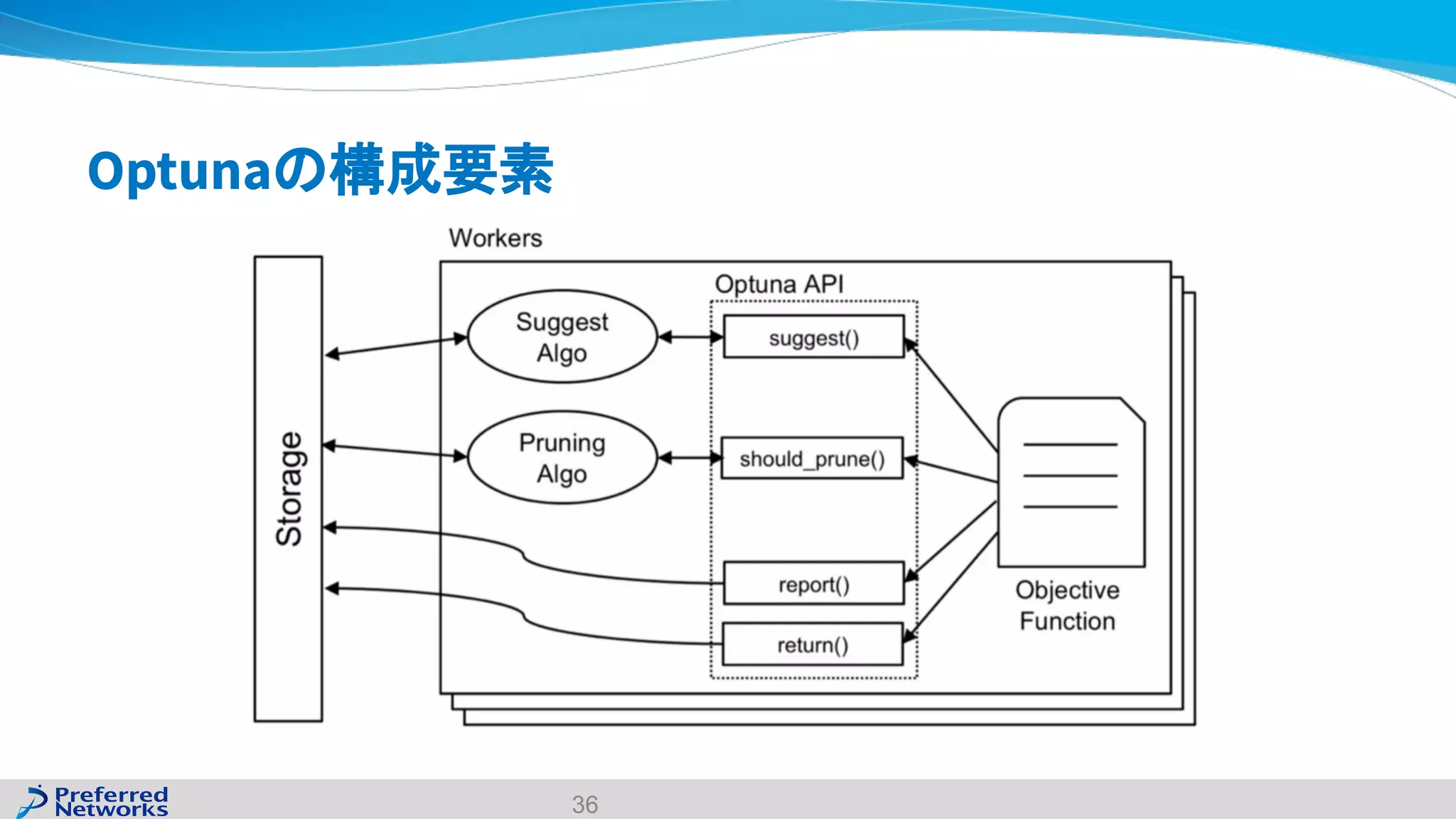
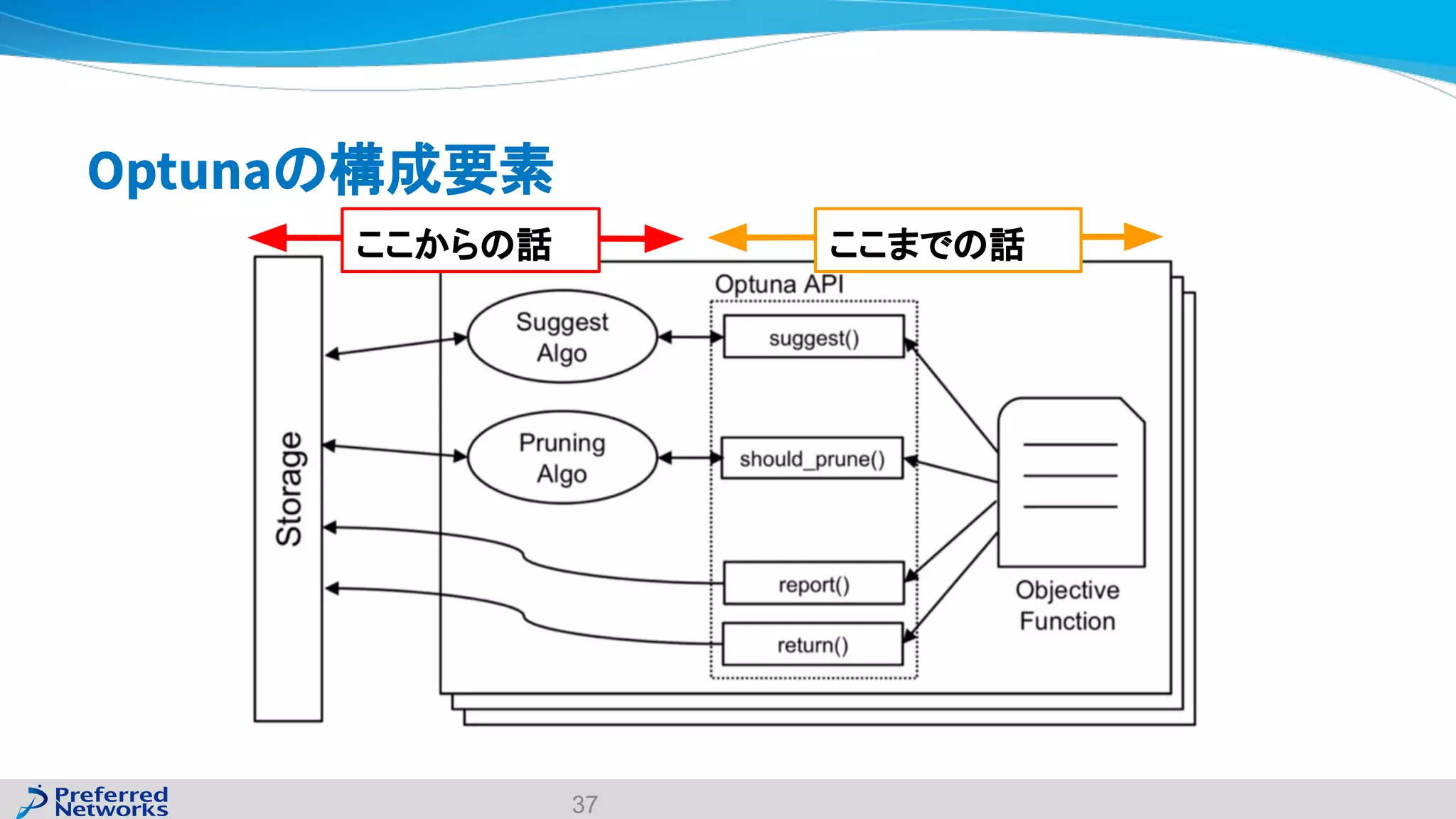
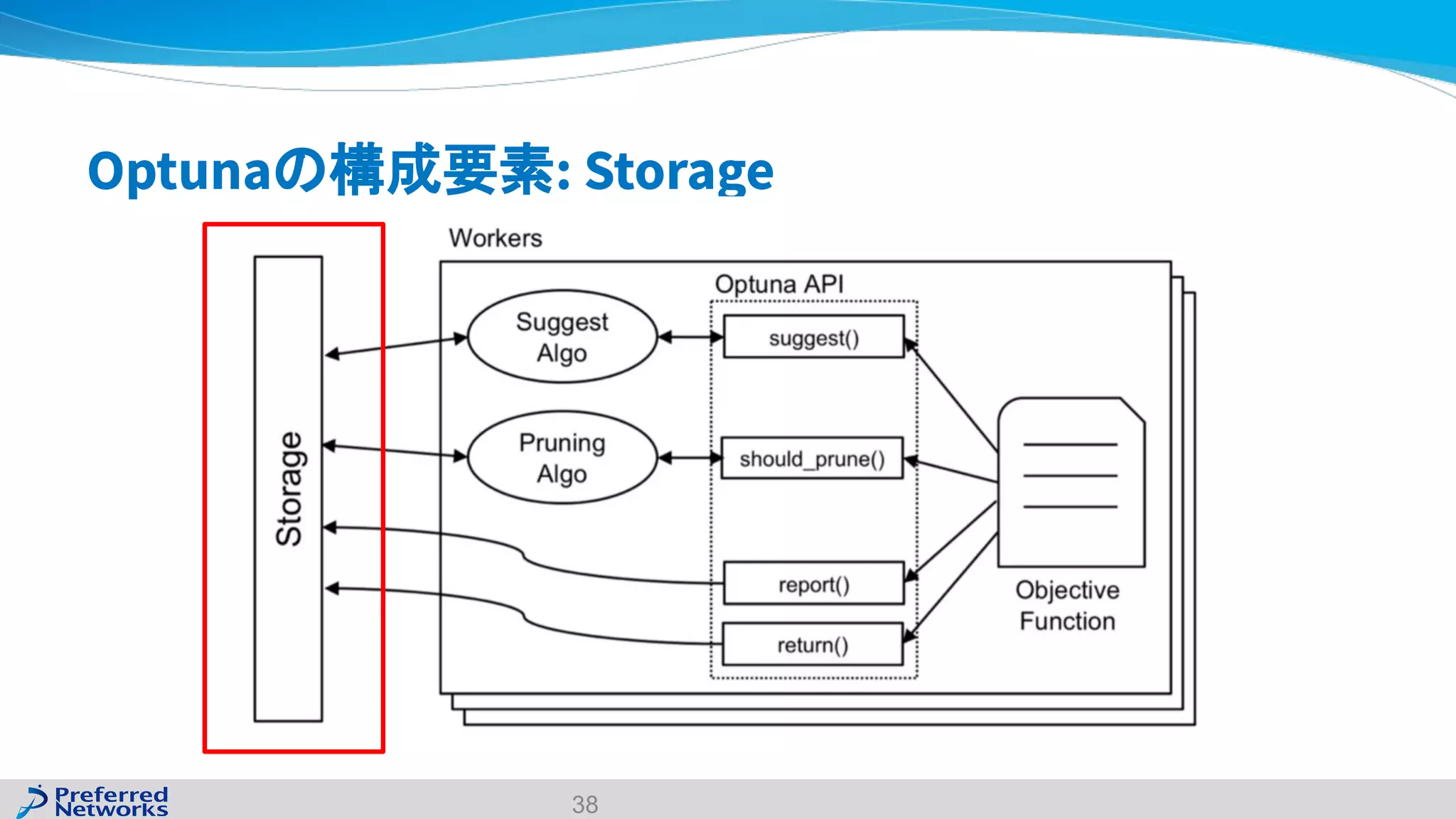
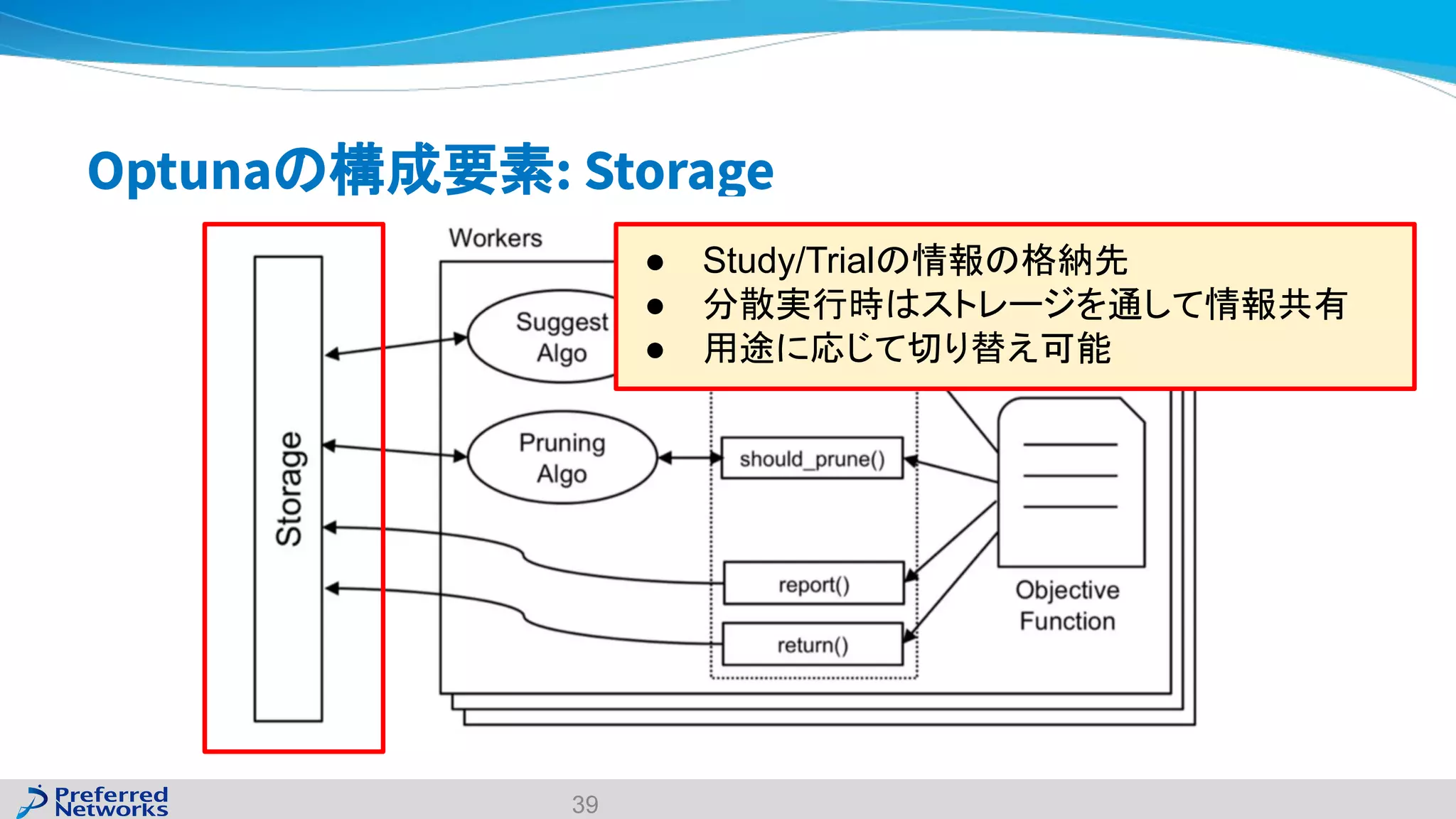



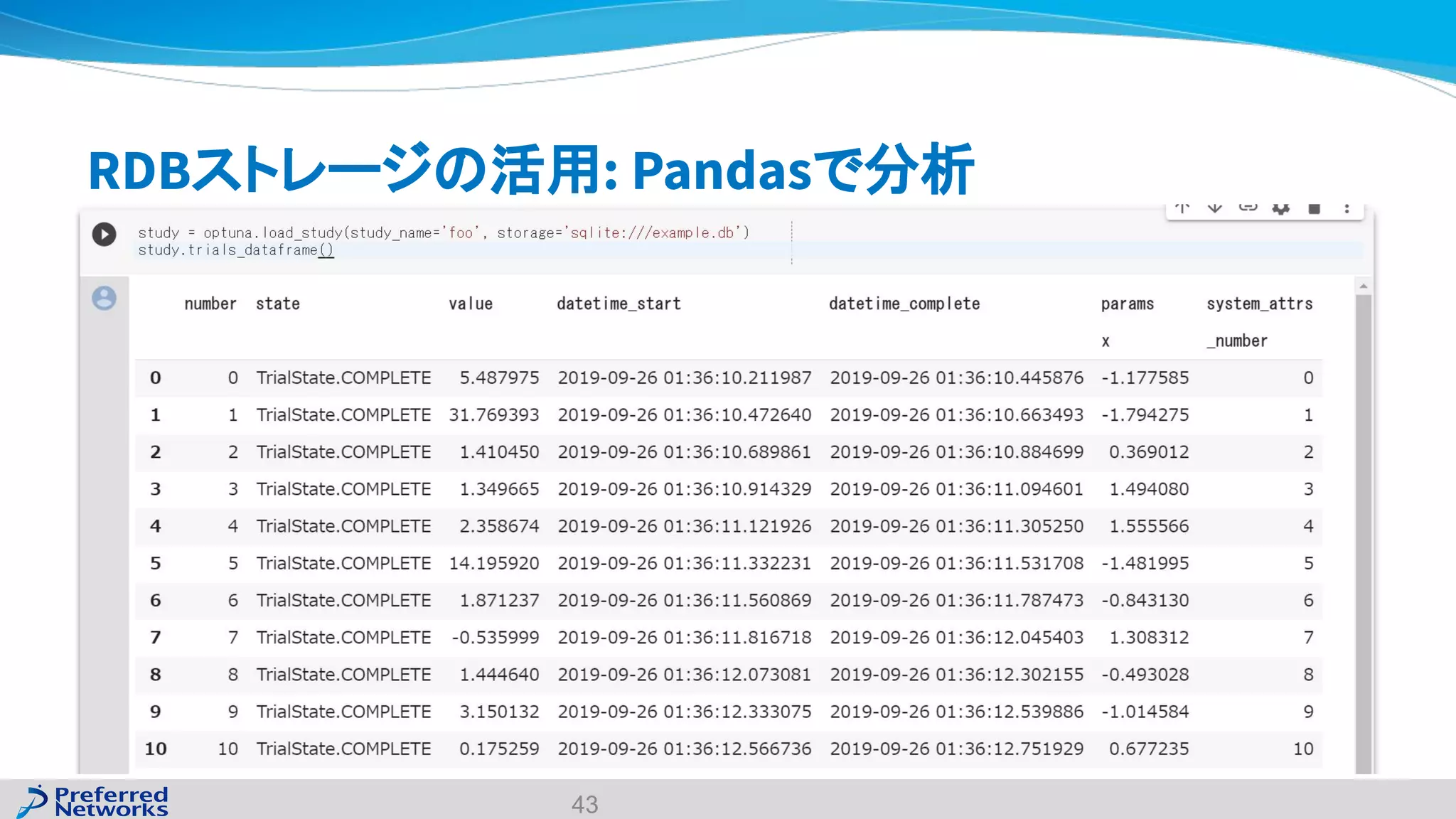
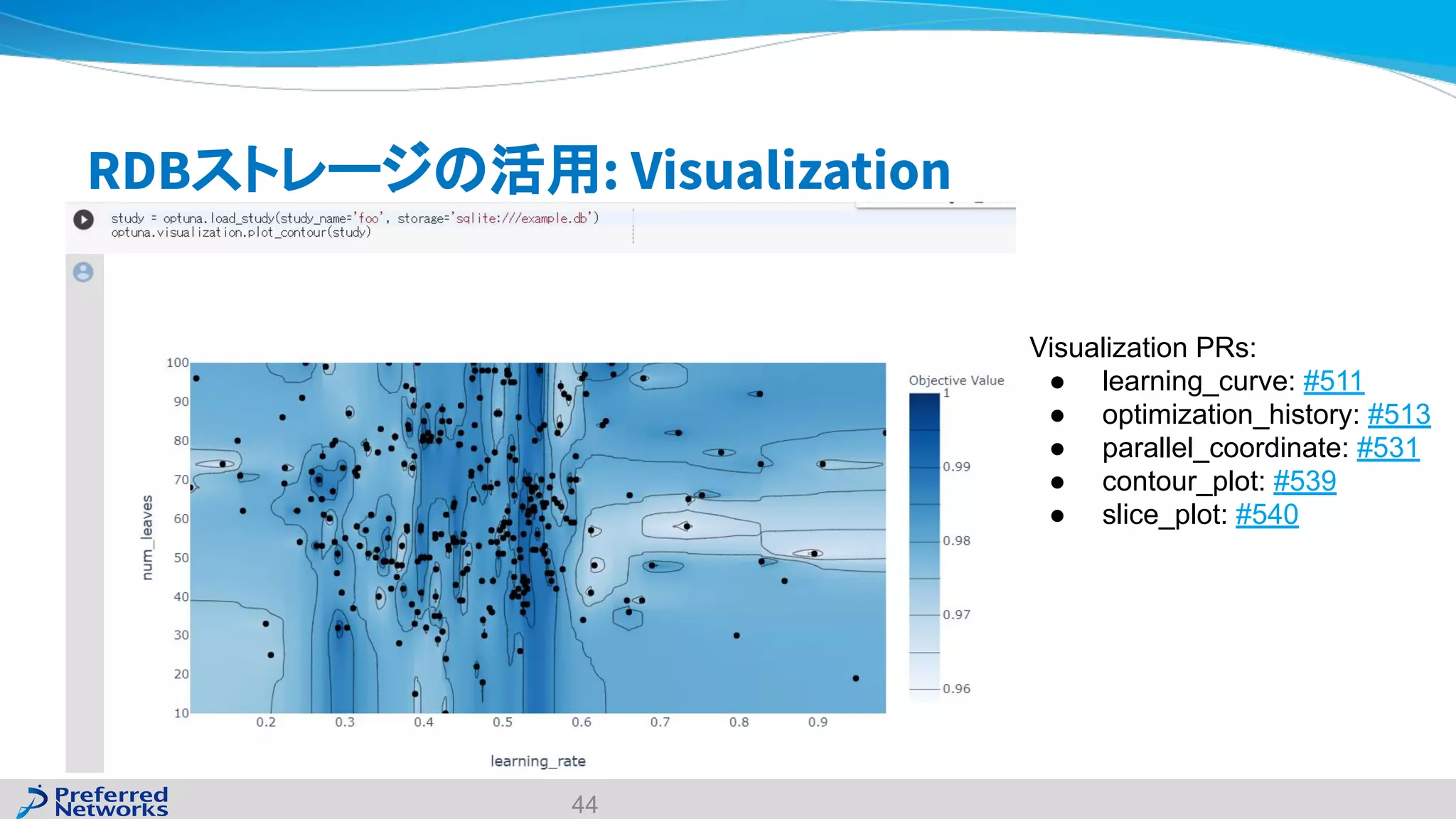
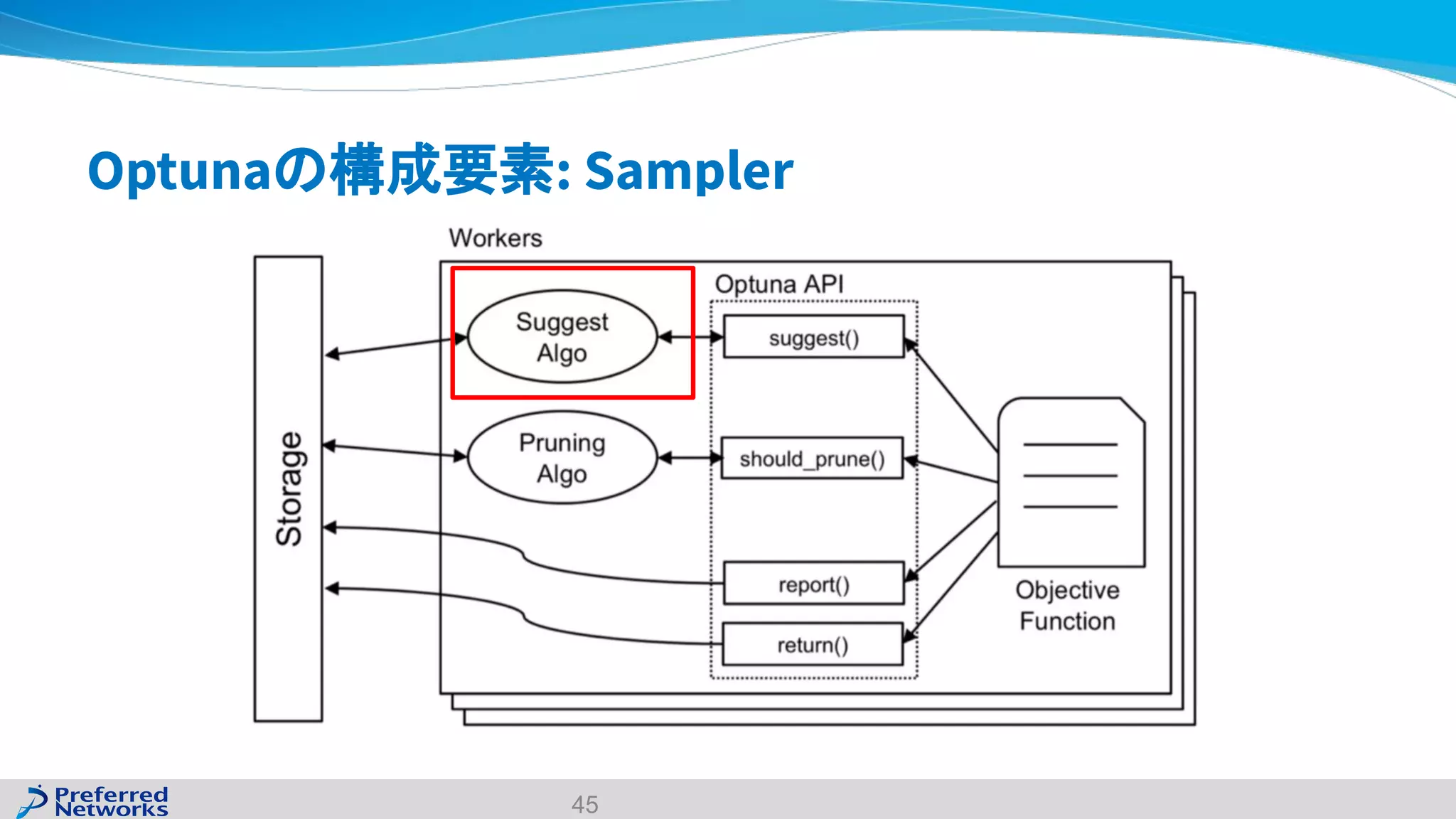
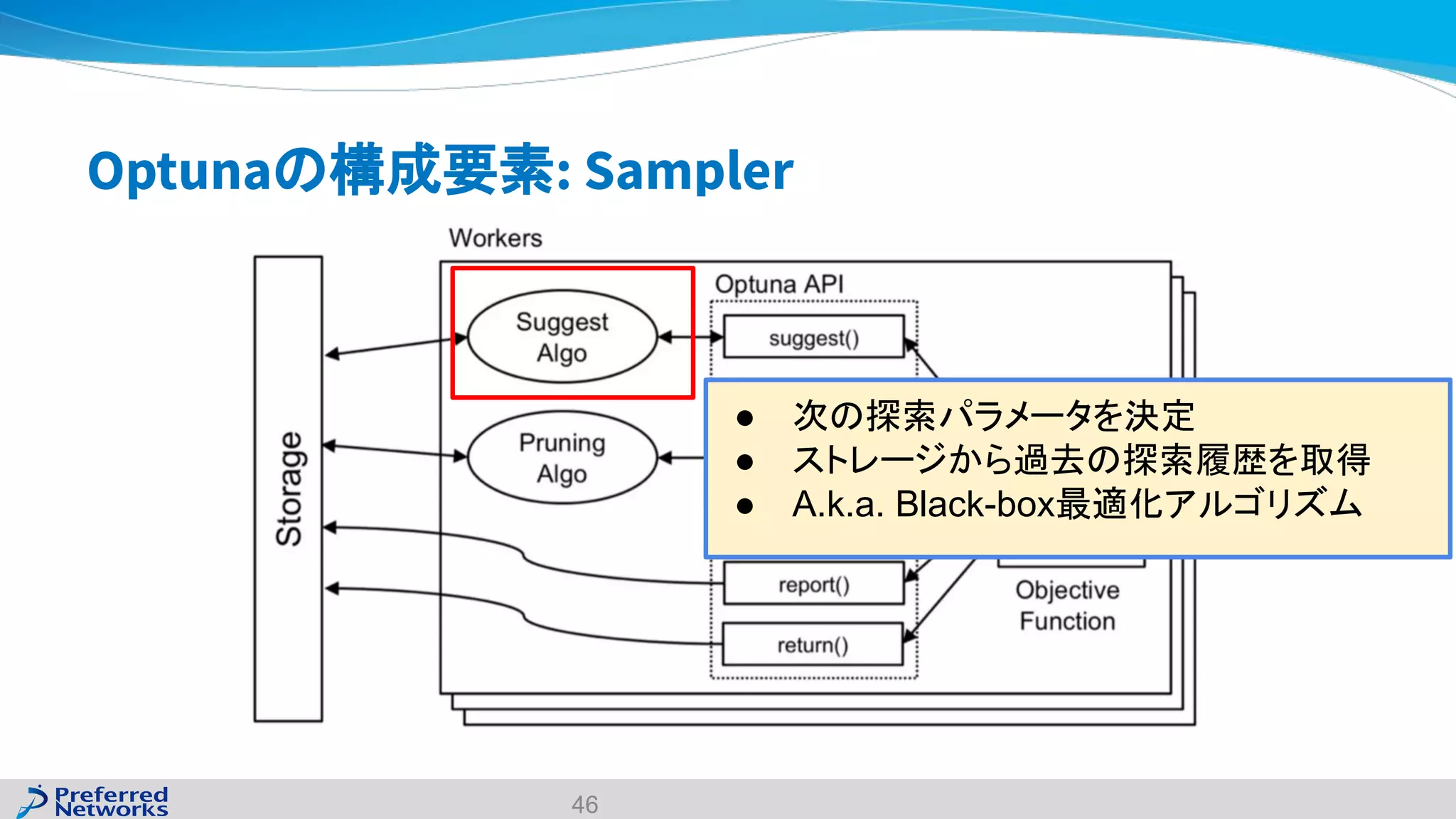

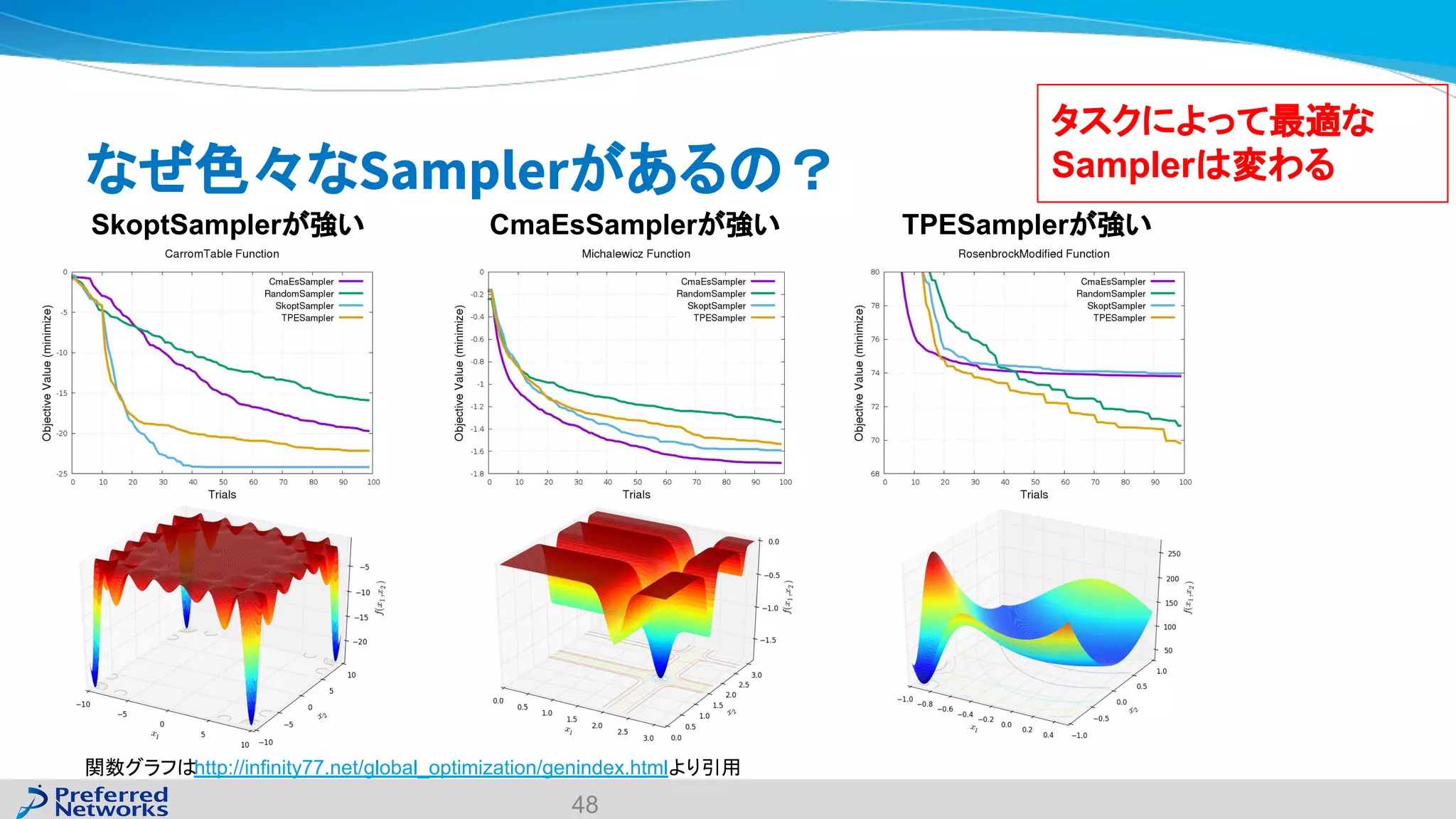

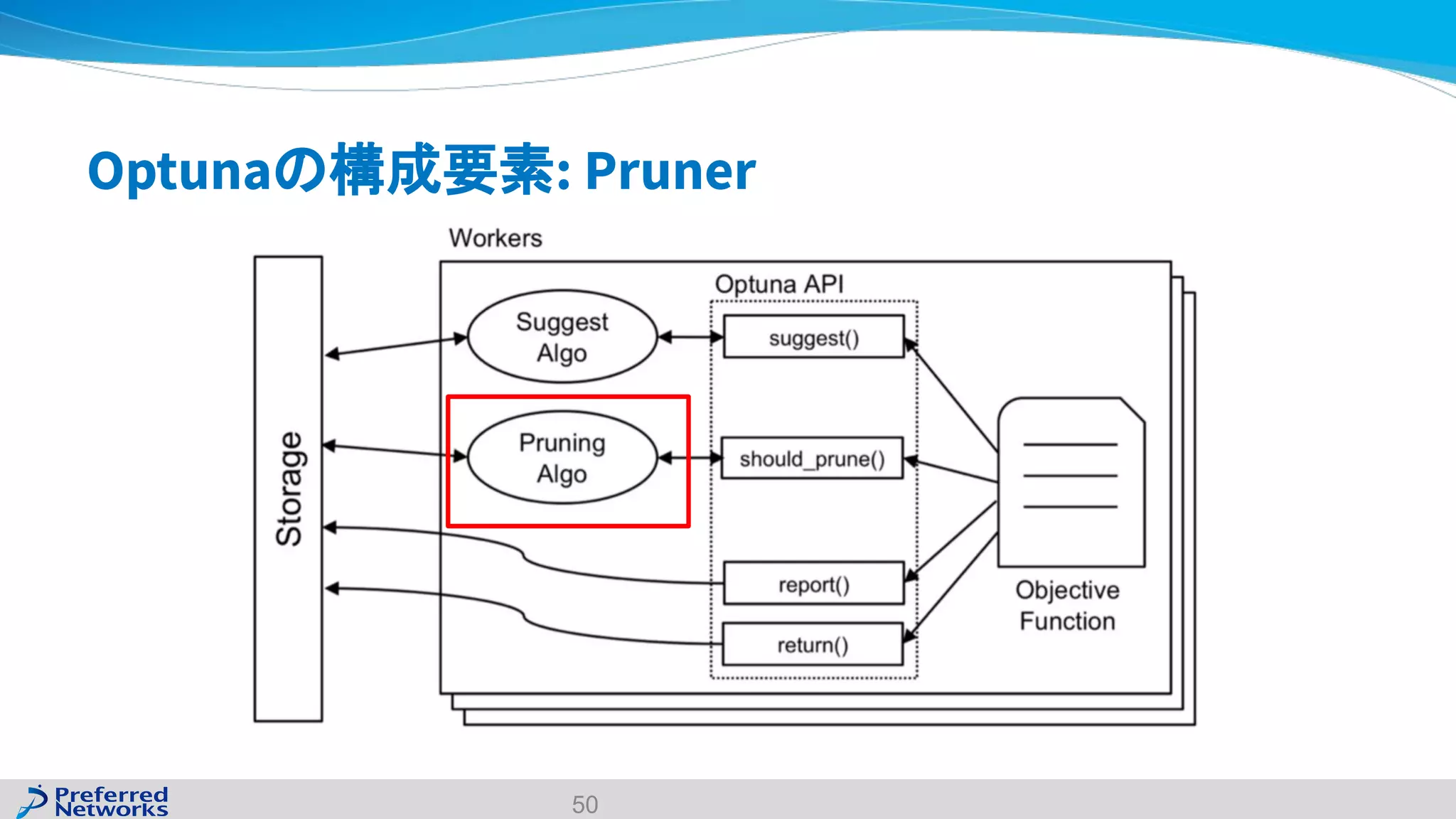
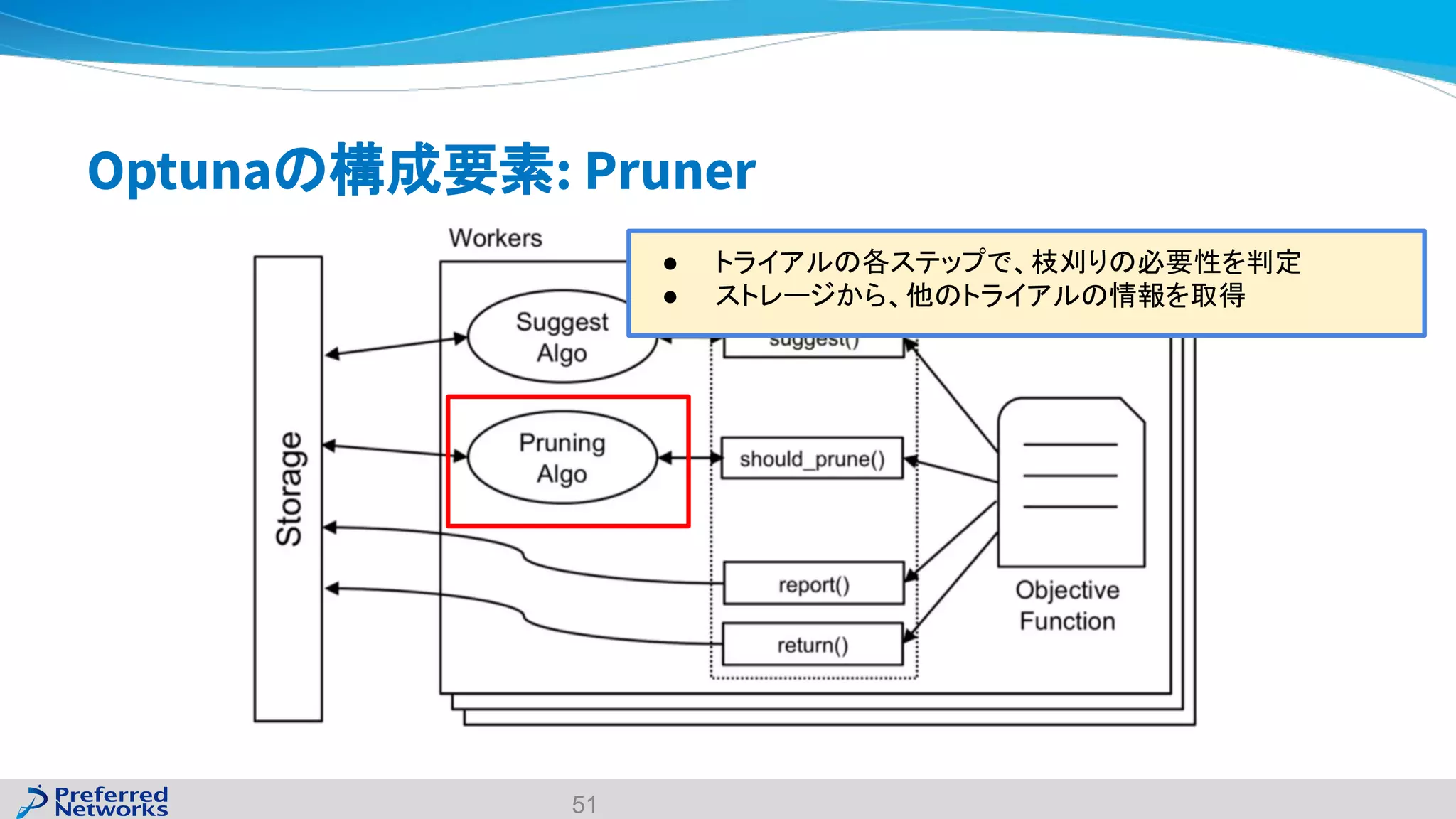
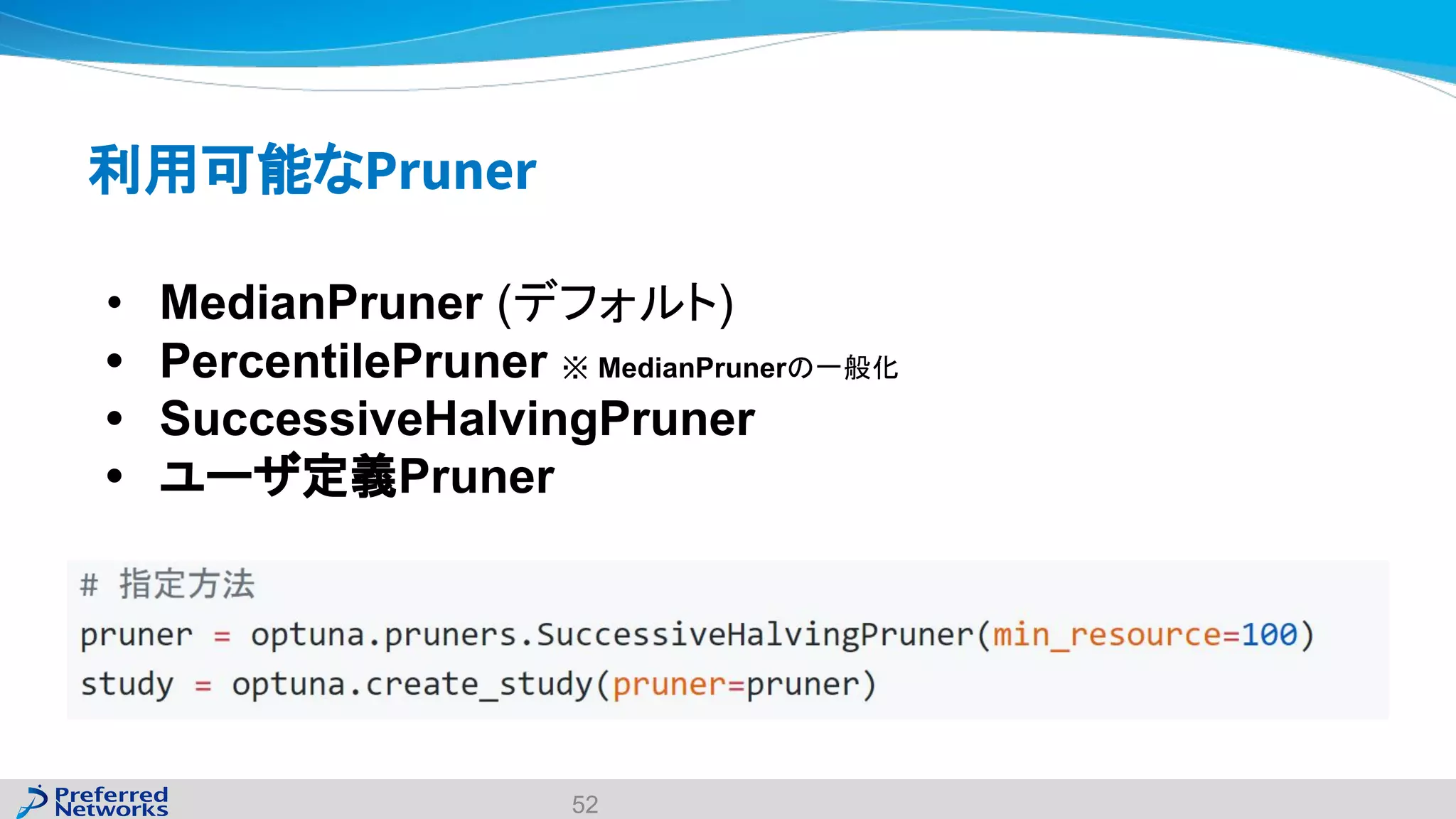
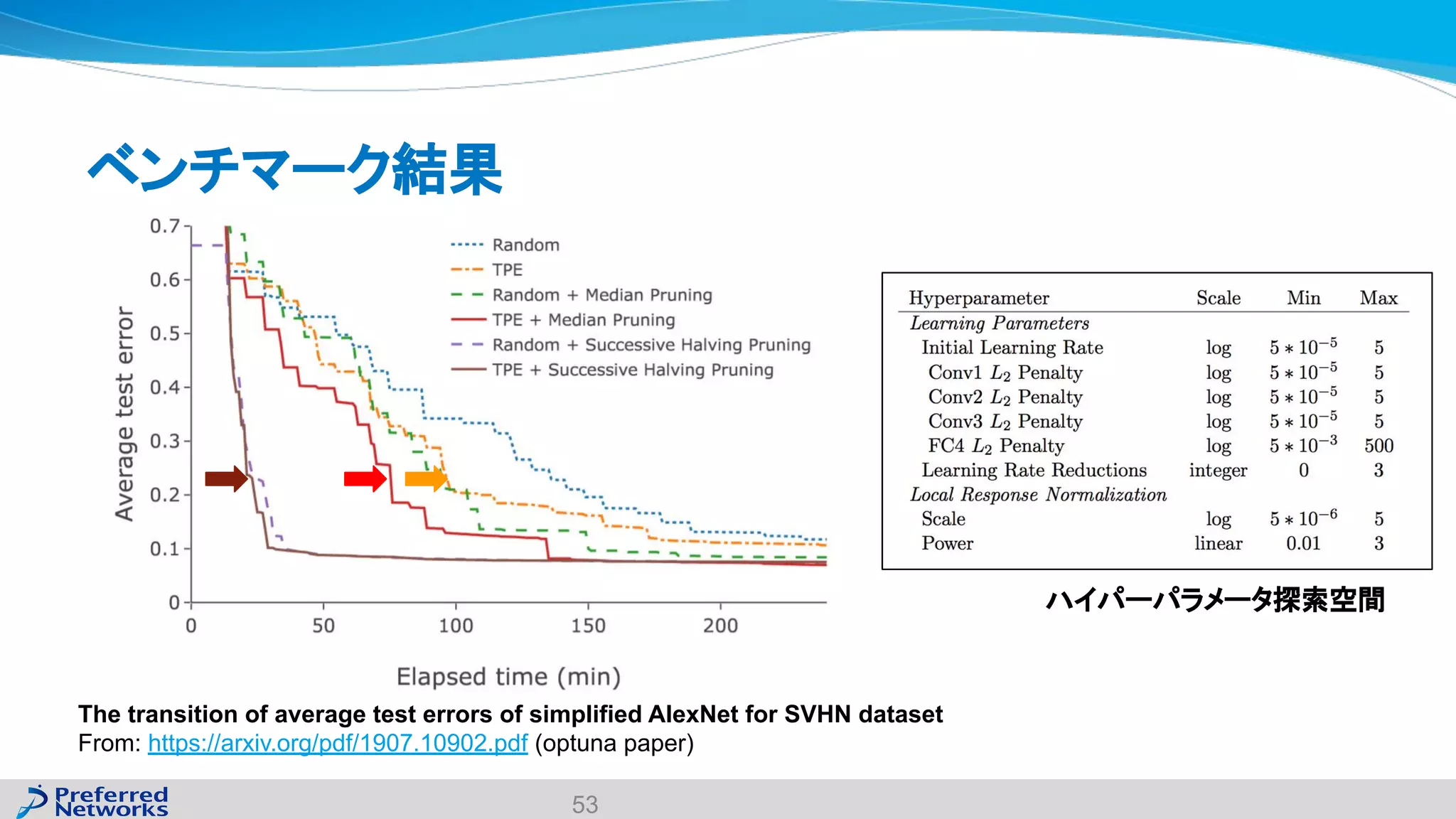




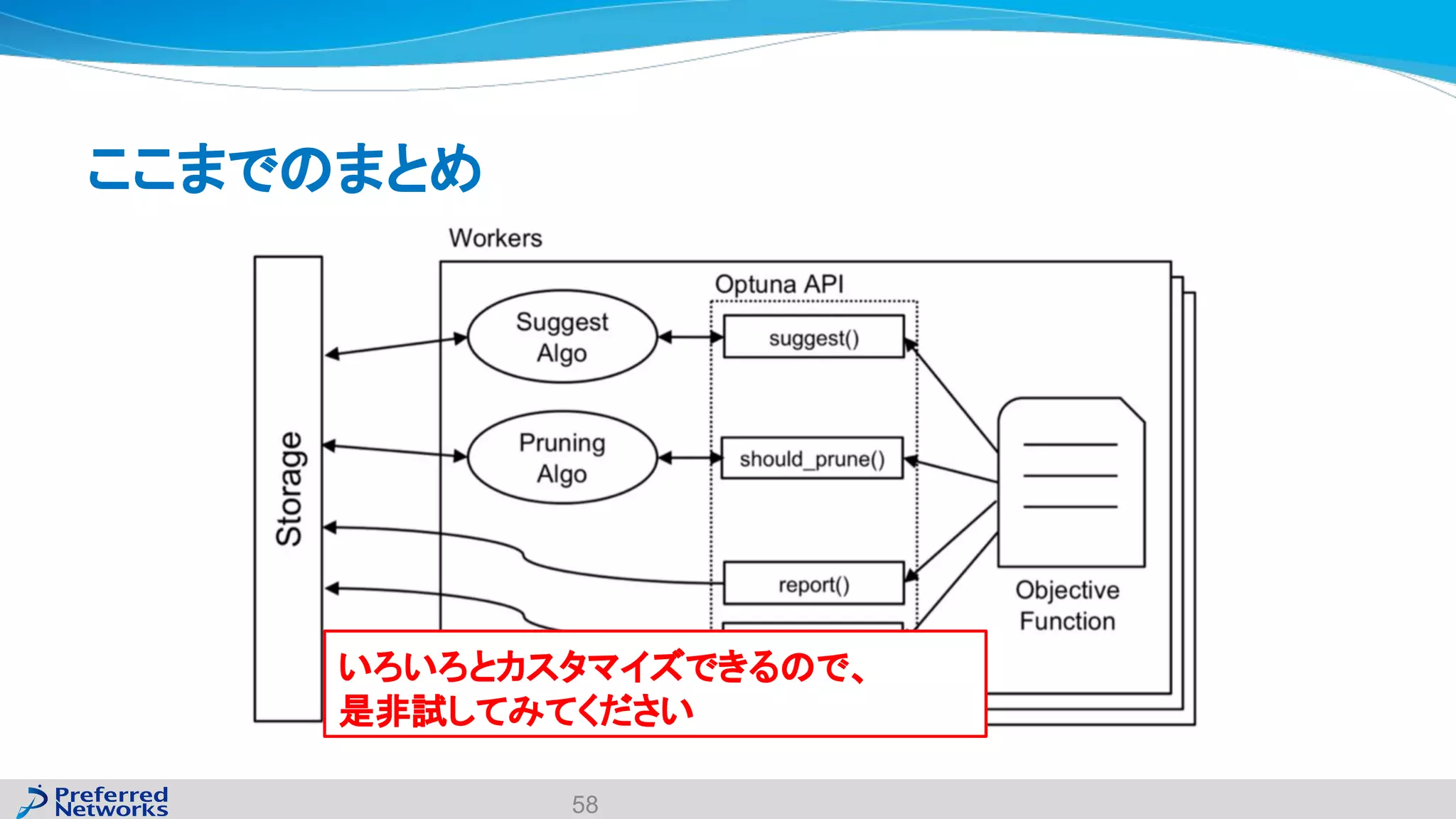


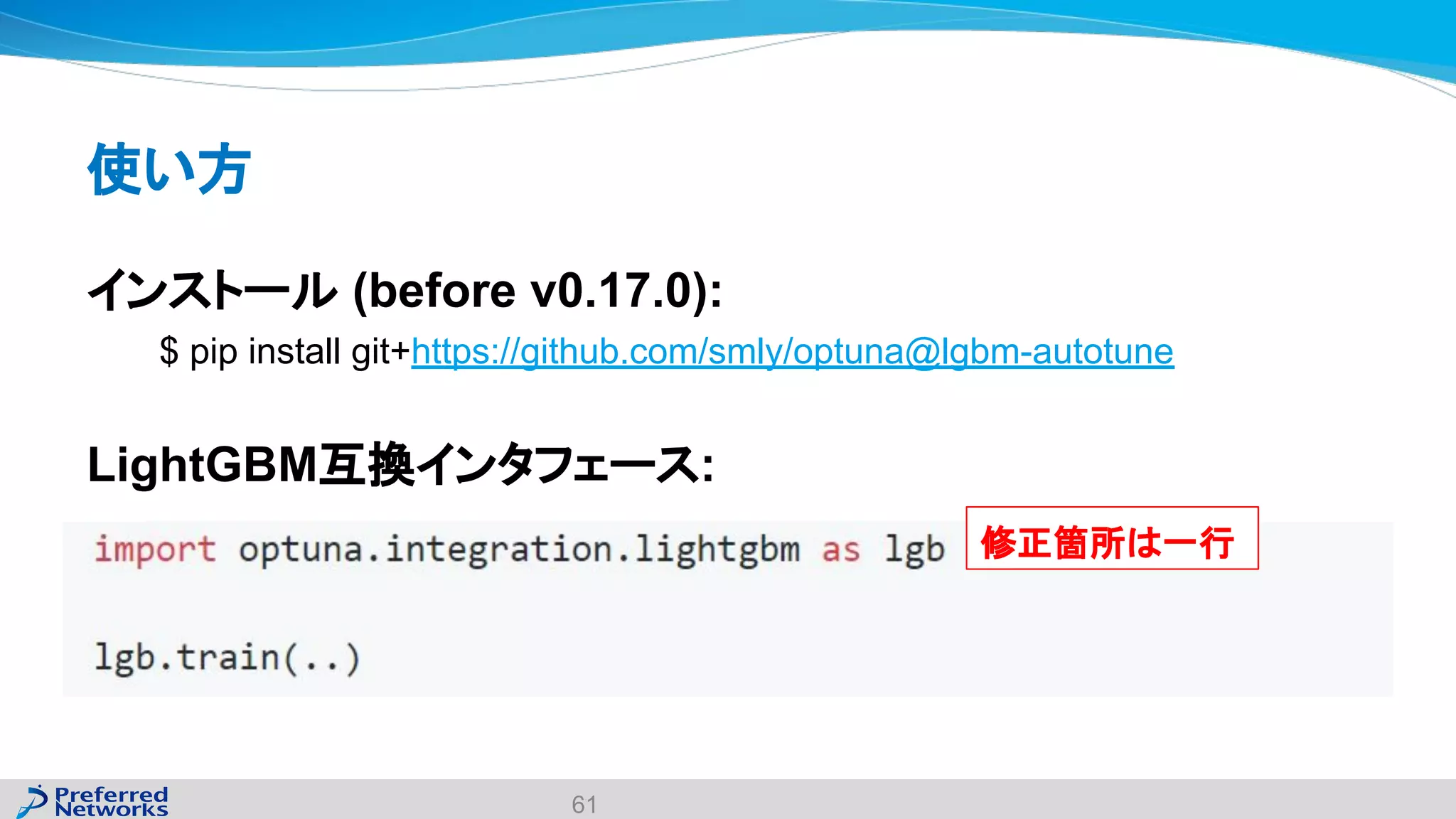

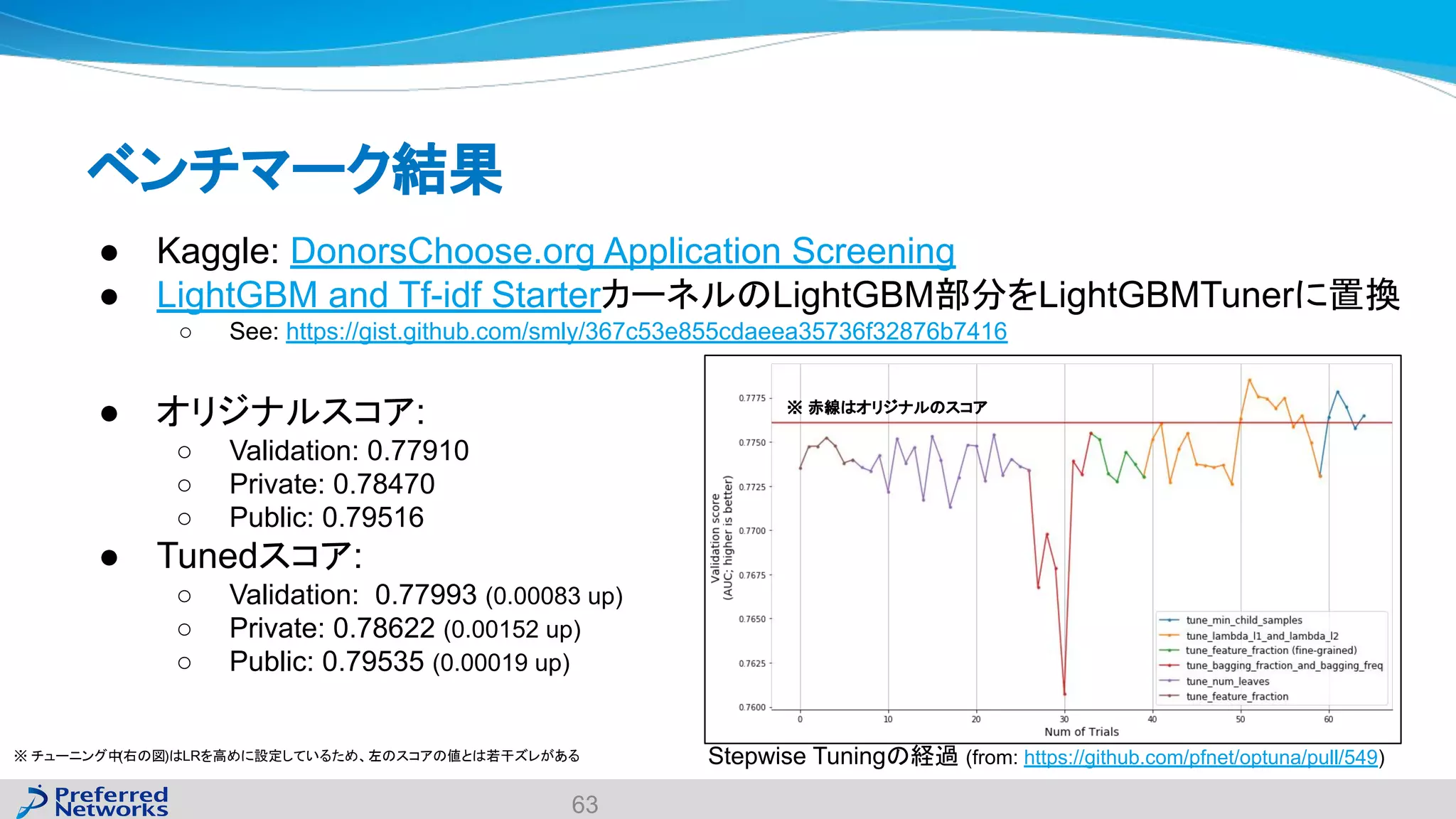





The document discusses the Optuna hyperparameter optimization framework, highlighting its features like define-by-run, pruning, and distributed optimization. It provides examples of successful applications in competitions and introduces the use of LightGBM hyperparameter tuning. Additionally, it outlines the installation procedure, key components of Optuna, and the introduction of the lightgbmtuner for automated optimization.













![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)















































