Downloaded 30 times

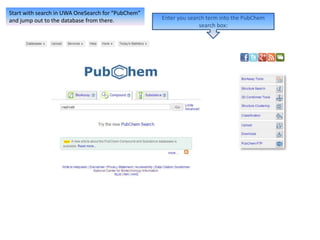






The document outlines the features of the PubChem database developed by NCBI, which provides biological information on small molecules. It describes how to search for bioassays, compounds, and substances, and highlights the availability of drug information, pharmacology, and literature references. Users are encouraged to explore curated content for in-depth research on specific drugs, exemplified by the exploration of the compound peramivir.





































































































