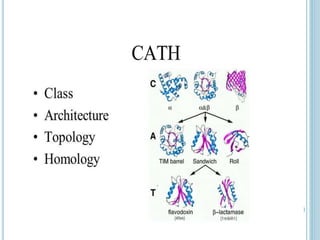
The CATH database hierarchically classifies protein domains obtained from protein structures deposited in the Protein Data Bank. Domain identification and classification uses both manual and automated procedures. CATH includes domains from structures determined at 4 angstrom resolution or better that are at least 40 residues long with 70% or more residues having defined side chains. Submitted protein chains are divided into domains, which are then classified in CATH.