Download as PDF, PPTX










![Avro Schema
Understanding Avro schema is very important for Avro
Data.
Ø JSON Format is used to define schema
Ø Simpler than IDL(Interface Definition Language) of
Protocol Buffers and thrift
Ø very useful in RPC. Schemas will be exchanged to
ensure the data correctness
Ø You can specify order (Ascending or Descending) for
fields.
Sample Schema:
{
"type": "record",
"name": "Meetup",
"fields": [ {
"name": "name",
"type": "string”,
"order" : "descending"
}, {
"name": "value",
"type": ["null", "string”]
}
…..
]
}
Union](https://image.slidesharecdn.com/airisdataavroparquet-160405212144/85/Parquet-and-AVRO-10-320.jpg)
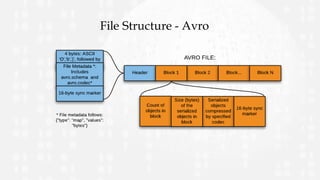




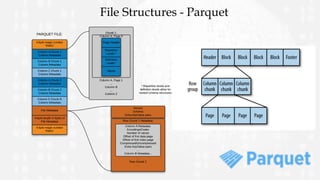

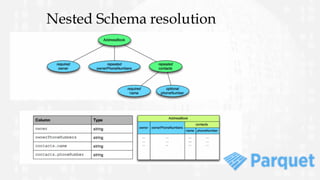











This document provides an overview and comparison of the Avro and Parquet data formats. It begins with introductions to Avro and Parquet, describing their key features and uses. The document then covers Avro and Parquet schemas, file structures, and includes code examples. Finally, it discusses considerations for choosing between Avro and Parquet and shares experiences using the two formats.













































































