Downloaded 48 times











![MadLINQ [EuroSys’12]
Linear algebra platform on Dryad
Not efficient for sparse matrix comp.](https://image.slidesharecdn.com/presto-130523031143-phpapp02/85/Presto-Distributed-Machine-Learning-and-Graph-Processing-with-Sparse-Matrices-12-320.jpg)
![Ricardo [SIGMOD’10]
But ends up inheriting the
inefficiencies of the MapReduce
interface
R Hadoop
aggregation-processing queries
aggregated data](https://image.slidesharecdn.com/presto-130523031143-phpapp02/85/Presto-Distributed-Machine-Learning-and-Graph-Processing-with-Sparse-Matrices-13-320.jpg)

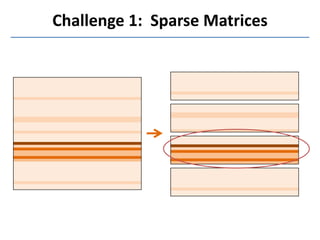
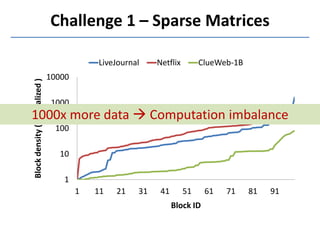
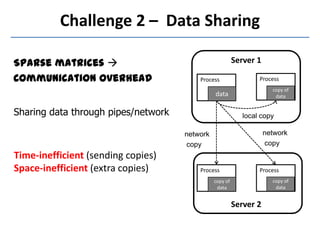

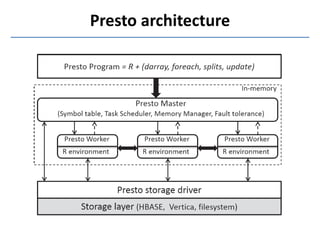
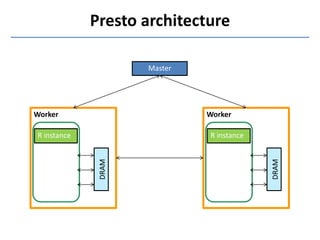
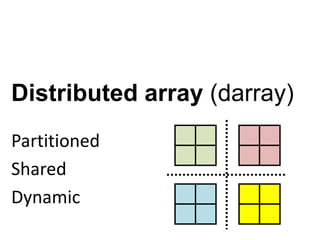
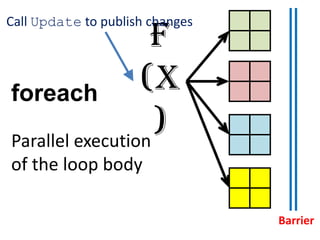
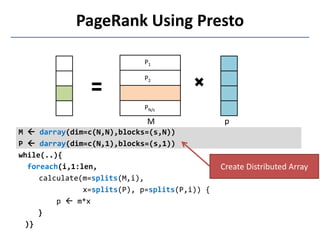
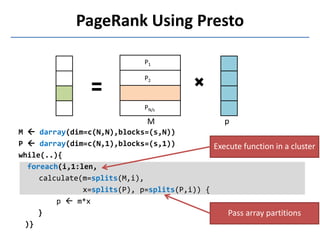

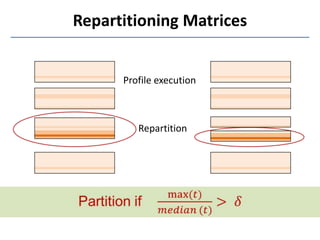

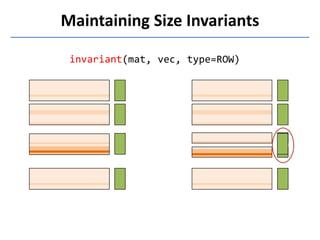

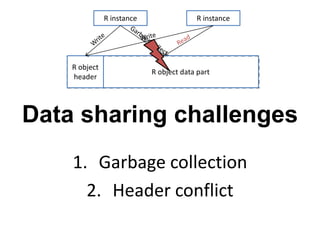
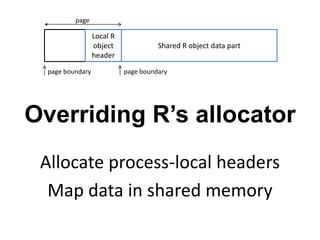



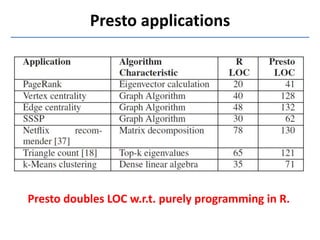

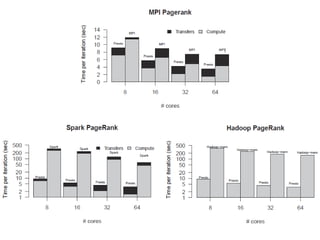
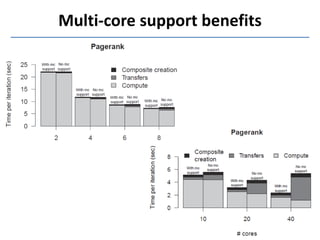
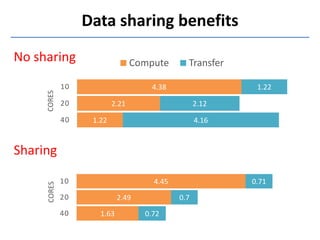
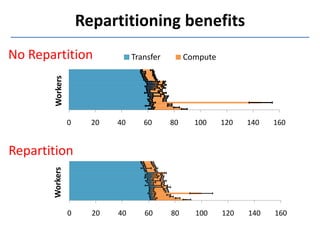
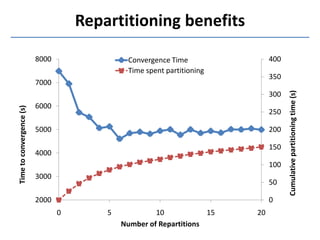




Presto is a large-scale array-based framework that extends R to enable distributed machine learning and graph processing on sparse matrices. It addresses challenges with sparse matrices through techniques like dynamic repartitioning to balance workloads, and allowing shared reading of data through zero-copy transfers while maintaining correctness. Evaluation shows Presto can process problems faster than Spark and Hadoop on in-memory datasets by leveraging these techniques.







![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)























































































