












![Query Compilation in Impala
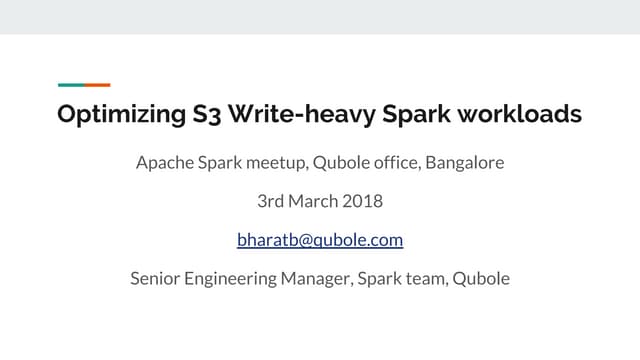
Explain Example: TPCDS Q42
+-----------------------------------------------------+
| Explain String |
+-----------------------------------------------------+
| Estimated Per-Host Requirements: Memory=0B VCores=0 |
| |
| 06:TOP-N [LIMIT=100] |
| 05:AGGREGATE [FINALIZE] |
| 04:HASH JOIN [INNER JOIN] |
| |--02:SCAN HDFS [tpcds1000gb.item i] |
| 03:HASH JOIN [INNER JOIN] |
| |--01:SCAN HDFS [tpcds1000gb.date_dim d] |
| 00:SCAN HDFS [tpcds1000gb.store_sales ss] |
+-----------------------------------------------------+
set explain_level=0;
set num_nodes=1;](https://image.slidesharecdn.com/querycompilationalexbehm-140521125907-phpapp01/85/Query-Compilation-in-Impala-21-320.jpg)
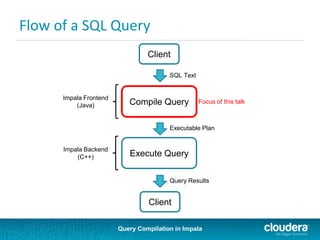
![Query Compilation in Impala
Explain Example: TPCDS Q42
+---------------------------------------------------------------------+
| Explain String |
+---------------------------------------------------------------------+
| Estimated Per-Host Requirements: Memory=3.76GB VCores=3 |
| |
| 12:TOP-N [LIMIT=100] |
| 11:EXCHANGE [PARTITION=UNPARTITIONED] |
| 06:TOP-N [LIMIT=100] |
| 10:AGGREGATE [MERGE FINALIZE] |
| 09:EXCHANGE [PARTITION=HASH(d.d_year,i.i_category_id,i.i_category)] |
| 05:AGGREGATE |
| 04:HASH JOIN [INNER JOIN, BROADCAST] |
| |--08:EXCHANGE [BROADCAST] |
| | 02:SCAN HDFS [tpcds1000gb.item i] |
| 03:HASH JOIN [INNER JOIN, BROADCAST] |
| |--07:EXCHANGE [BROADCAST] |
| | 01:SCAN HDFS [tpcds1000gb.date_dim d] |
| 00:SCAN HDFS [tpcds1000gb.store_sales ss] |
+---------------------------------------------------------------------+
set explain_level=0;
set num_nodes=0;](https://image.slidesharecdn.com/querycompilationalexbehm-140521125907-phpapp01/85/Query-Compilation-in-Impala-22-320.jpg)
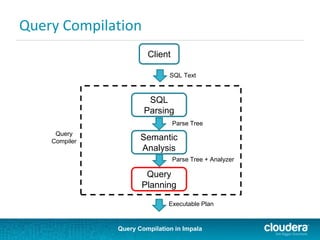
![Query Compilation in Impala
Explain Example: TPCDS Q42
| …
| 03:HASH JOIN [INNER JOIN, BROADCAST] |
| | hash predicates: ss.ss_sold_date_sk = d.d_date_sk |
| | hosts=10 per-host-mem=511B |
| | tuple-ids=0,1 row-size=40B cardinality=8251124389 |
| | |
| |--07:EXCHANGE [BROADCAST] |
| | | hosts=3 per-host-mem=0B |
| | | tuple-ids=1 row-size=16B cardinality=29 |
| | | |
| | 01:SCAN HDFS [tpcds1000gb.date_dim d, PARTITION=RANDOM] |
| | partitions=1/1 size=9.77MB |
| | predicates: d.d_moy = 12, d.d_year = 1998 |
| | table stats: 73049 rows total |
| | column stats: all |
| | hosts=3 per-host-mem=48.00MB |
| | tuple-ids=1 row-size=16B cardinality=29 |
| | |
| 00:SCAN HDFS [tpcds1000gb.store_sales ss, PARTITION=RANDOM] |
| partitions=1823/1823 size=1.10TB |
| table stats: 8251124389 rows total |
| column stats: all |
| hosts=10 per-host-mem=3.75GB |
| tuple-ids=0 row-size=24B cardinality=8251124389 |
+--------------------------------------------------------------+
set explain_level=2;
set num_nodes=0;](https://image.slidesharecdn.com/querycompilationalexbehm-140521125907-phpapp01/85/Query-Compilation-in-Impala-23-320.jpg)
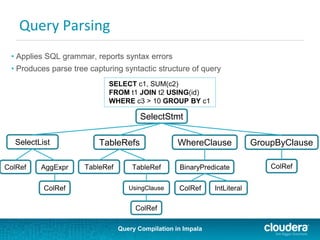
![Query Compilation in Impala
Conclusion
• Cost-based choice of join order and strategy
• Critical for performance
• Relies on table and column stats
• Other plan optimizations currently independent of stats
• Likely to expand plan choices in the future
• Likely to increase reliance on stats
• Helpful Impala commands
• compute stats
• show table/column stats
• explain query/insert stmt
• set explain_level=[0-3]
• set num_nodes=0 show single-node plan](https://image.slidesharecdn.com/querycompilationalexbehm-140521125907-phpapp01/85/Query-Compilation-in-Impala-24-320.jpg)



Query compilation in Impala involves parsing the SQL, semantic analysis to validate the query, planning to generate an executable query plan, and finally executing the query. The query planner considers different join orders and strategies like broadcast joins and partitioned joins to minimize data transfer during query execution based on table and column statistics. The explain output provides details on how the query will be executed in a distributed fashion across nodes.