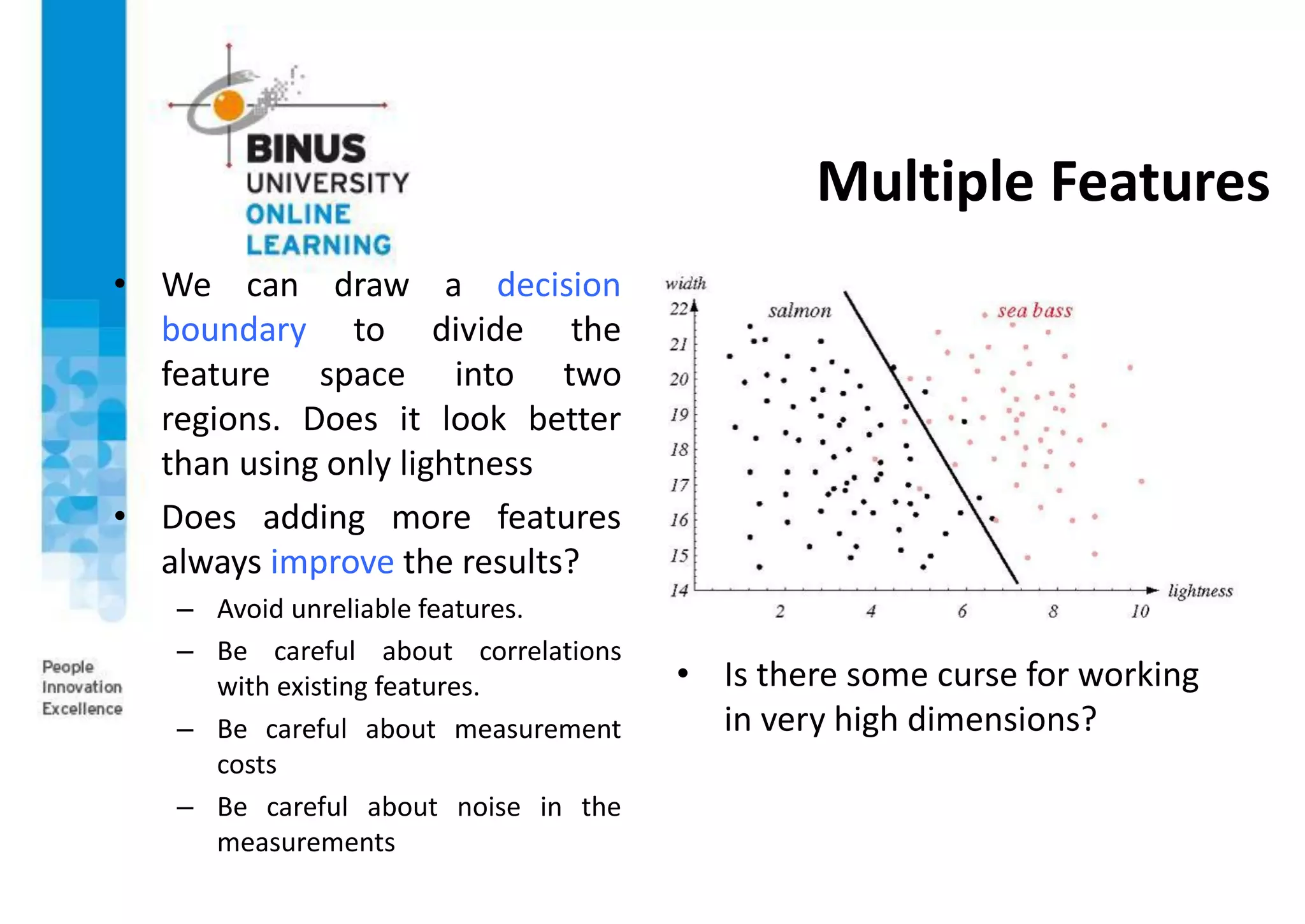
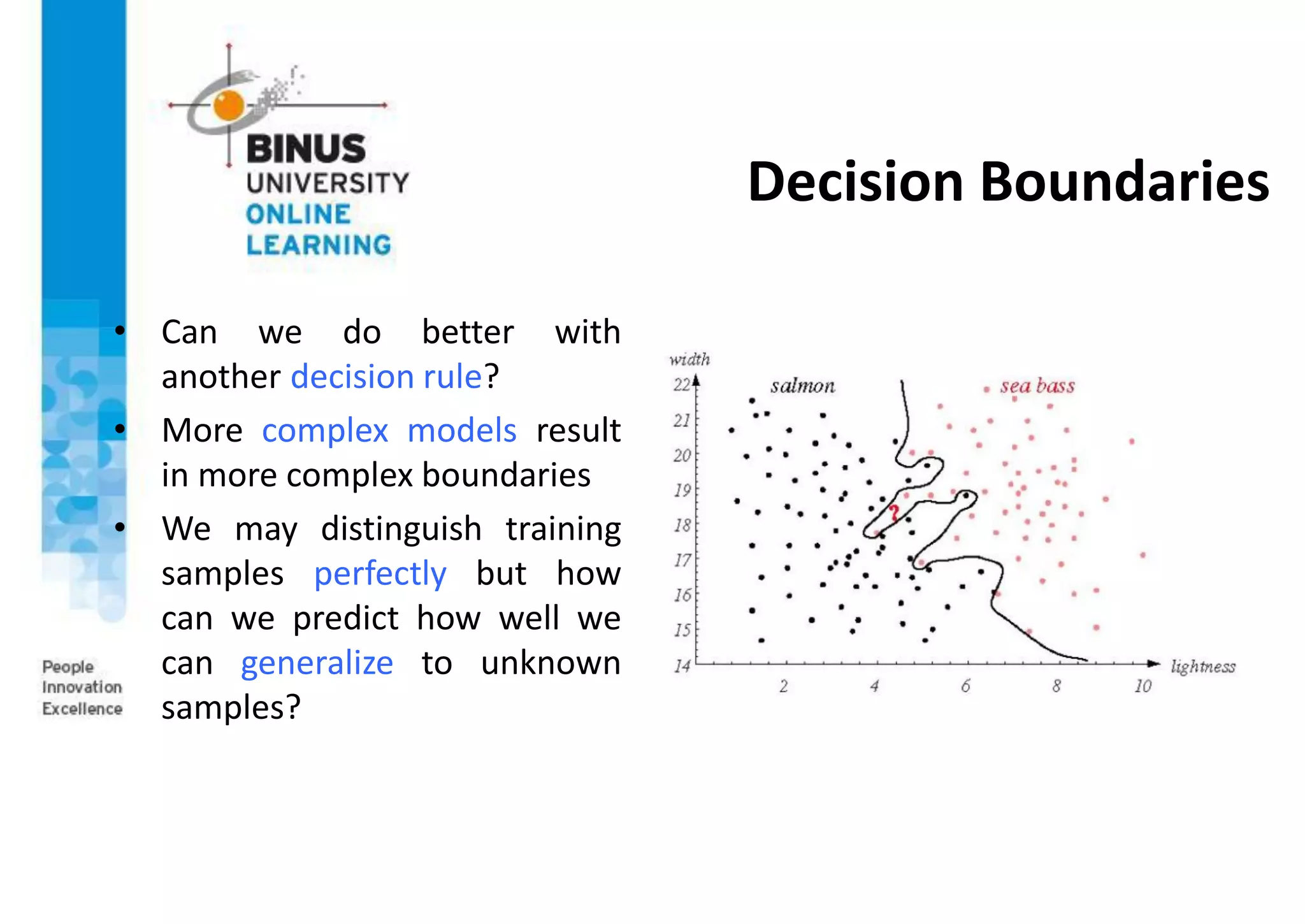
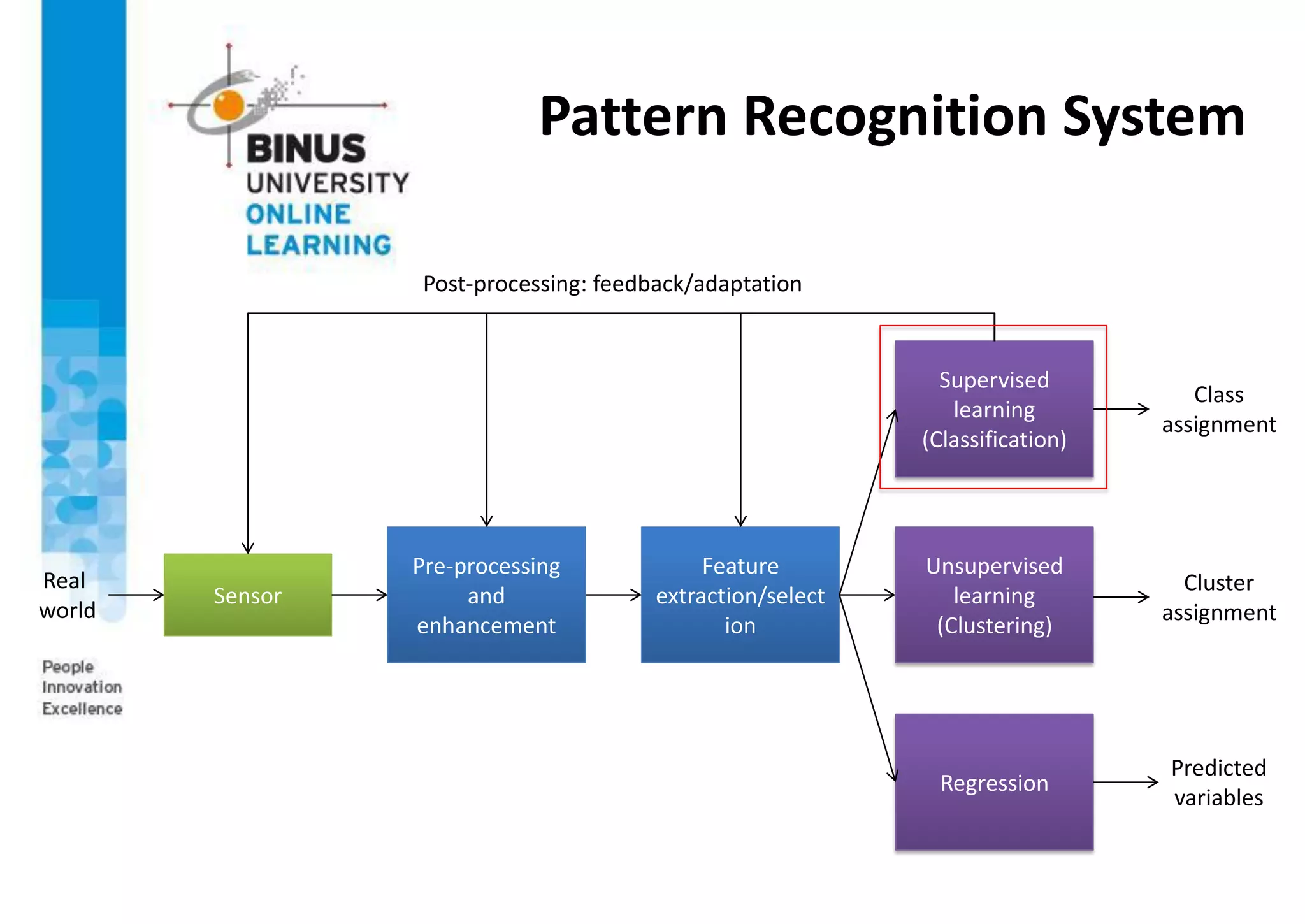
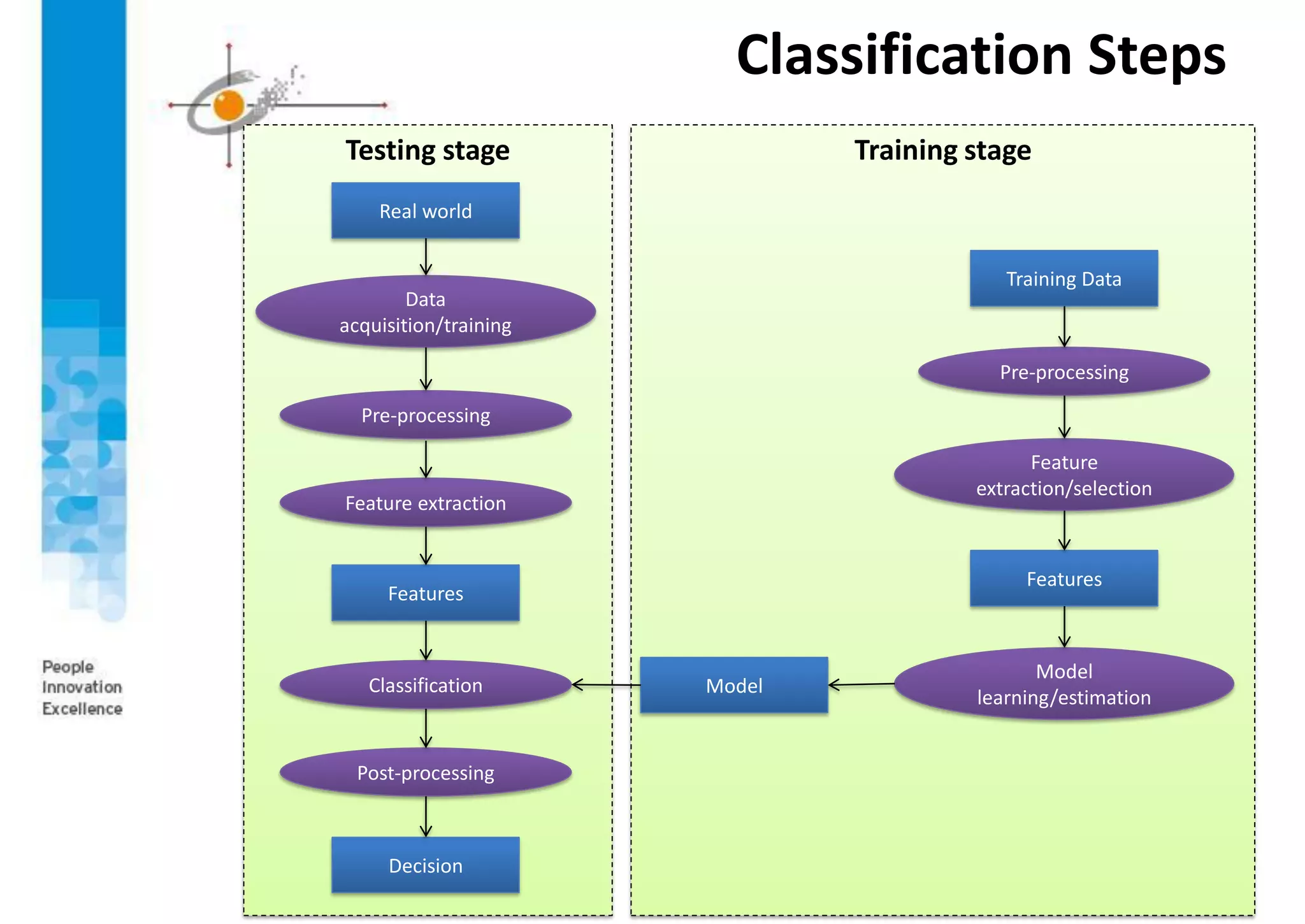
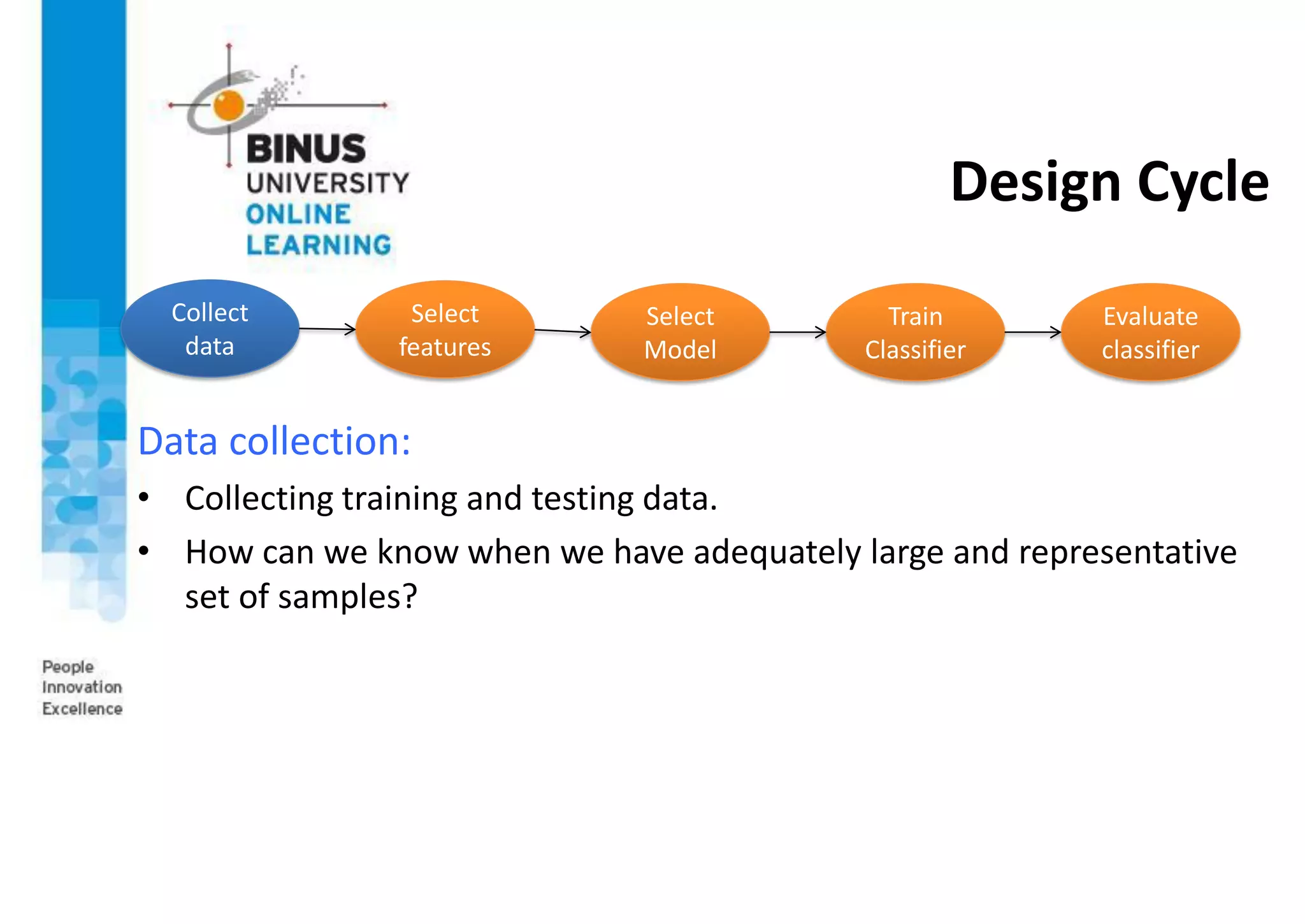
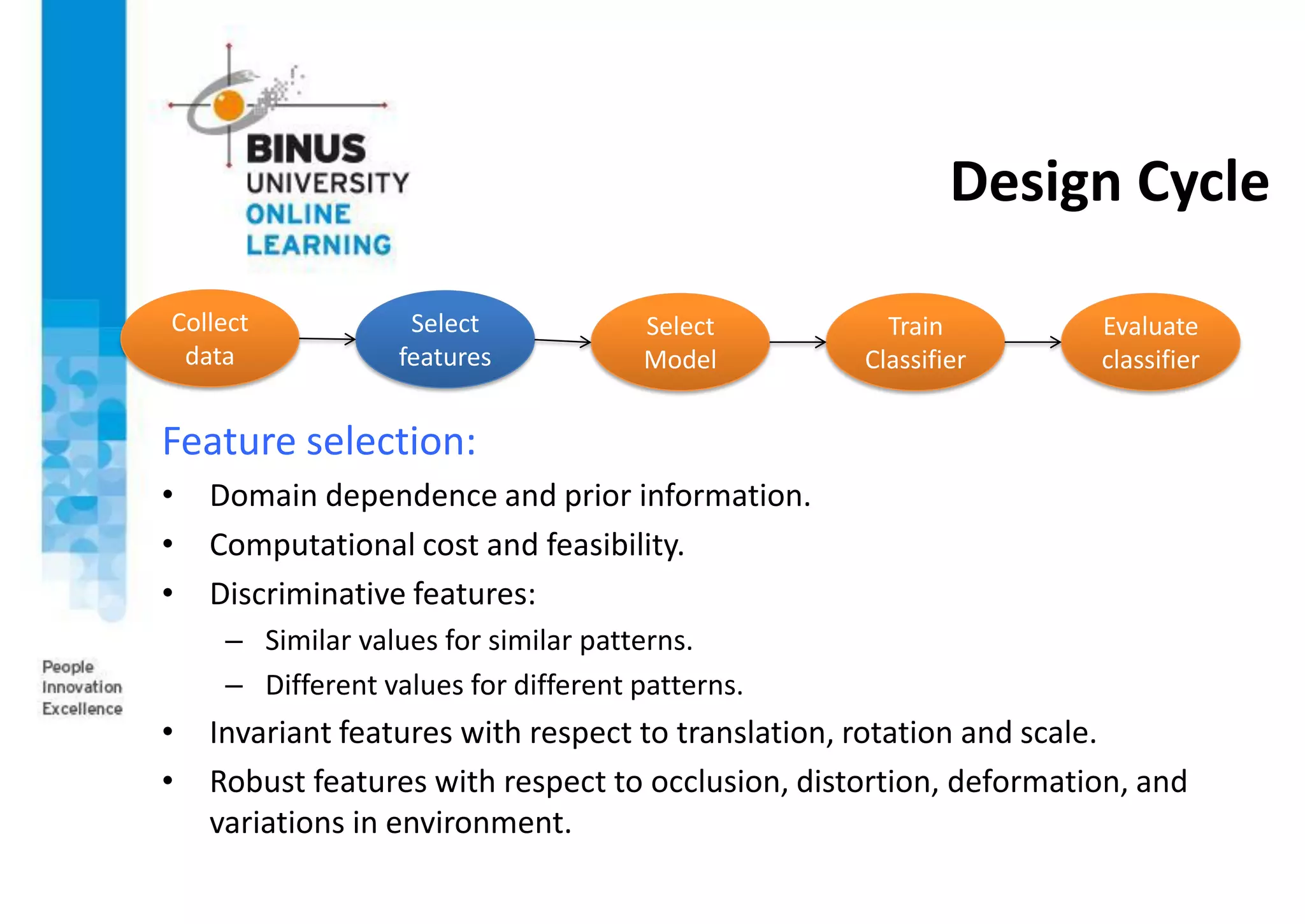
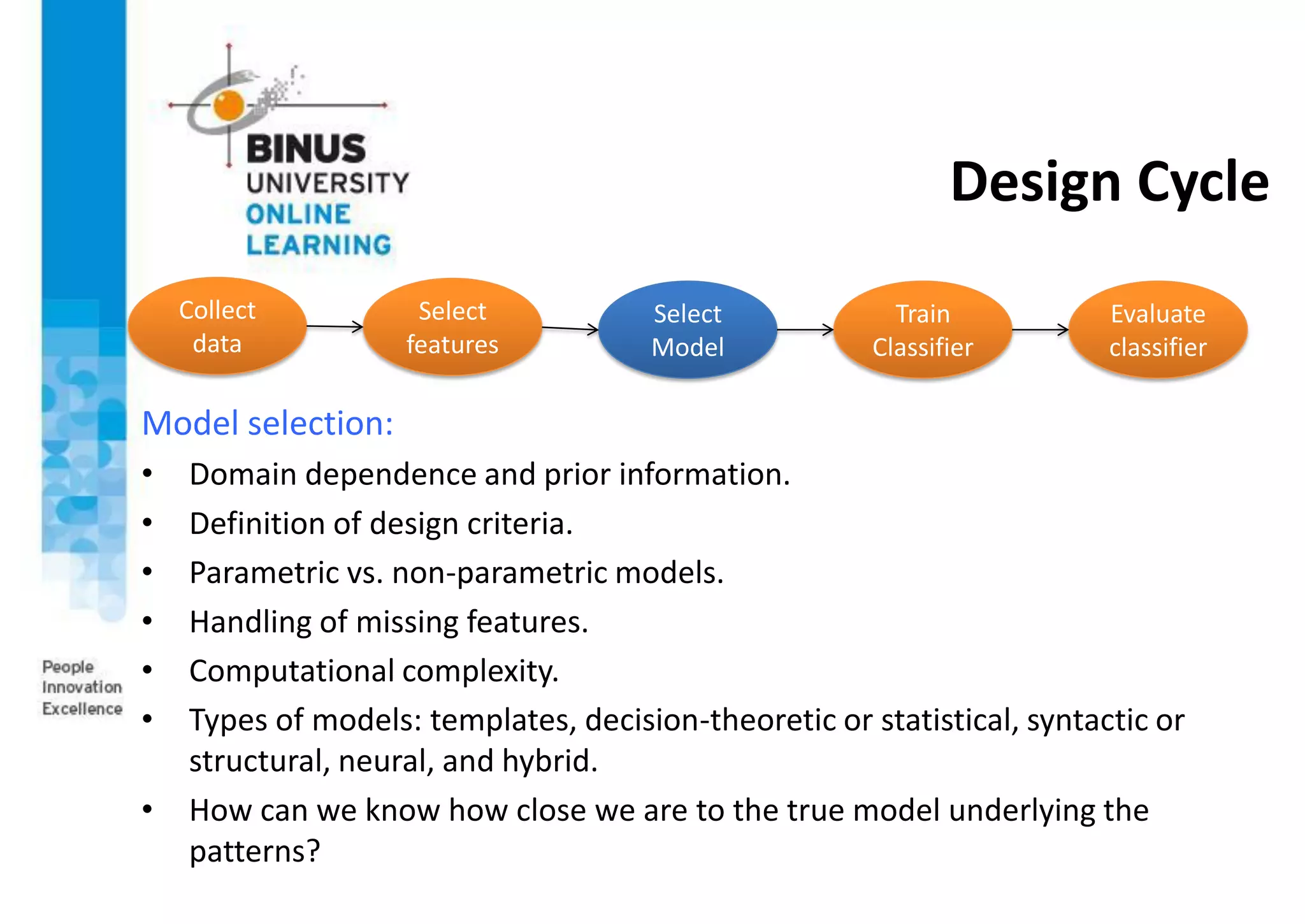
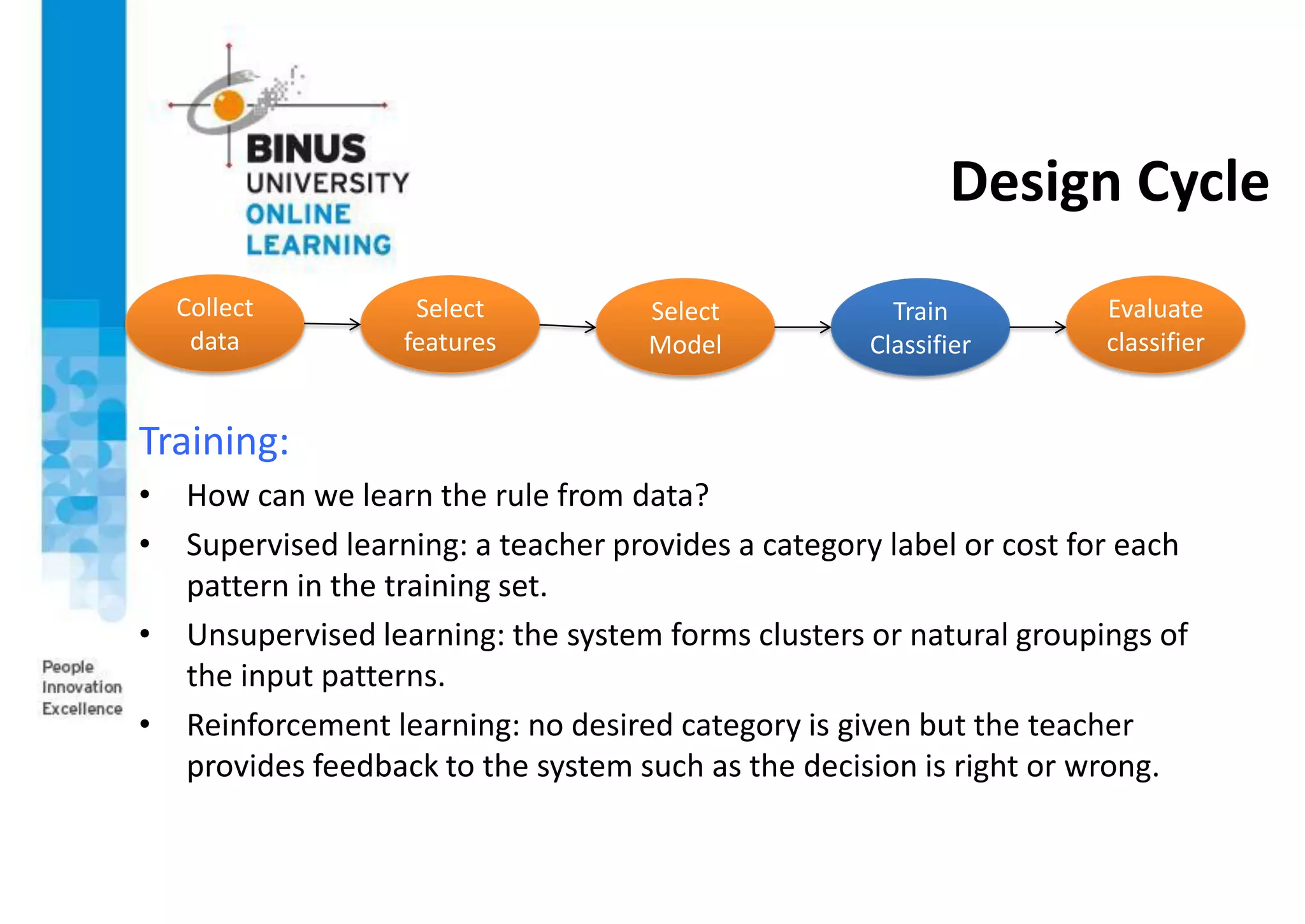
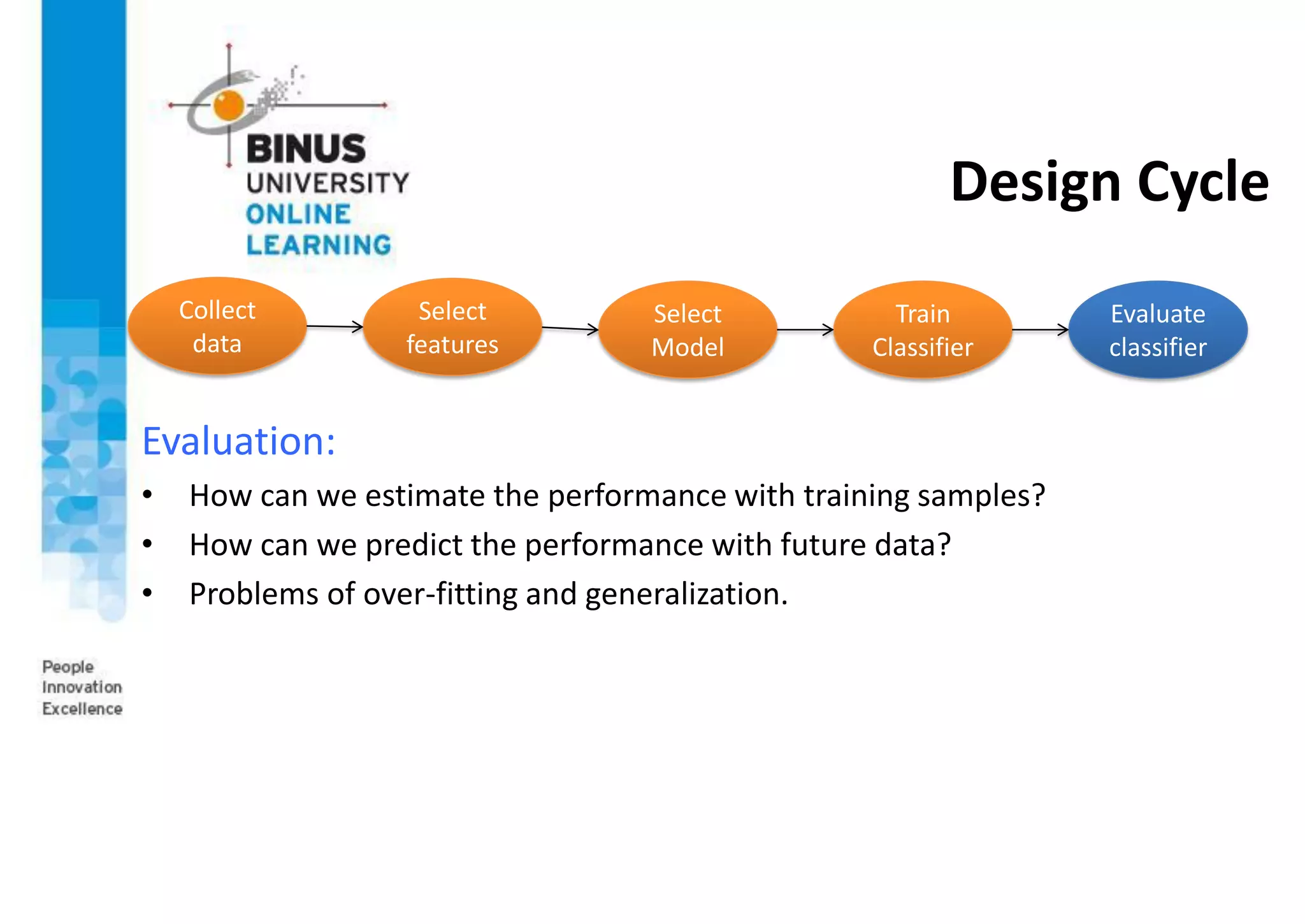
This document provides an overview of pattern recognition and supervised learning for machine vision. It discusses what pattern recognition is, examples of pattern recognition applications, the basic steps in a pattern recognition system including data acquisition, preprocessing, feature extraction, supervised/unsupervised learning, and post-processing. For supervised learning, it describes the process of inferring functions from labeled training data. It also provides an example of using multiple features and decision boundaries for texture classification of images.