Download as PDF, PPTX






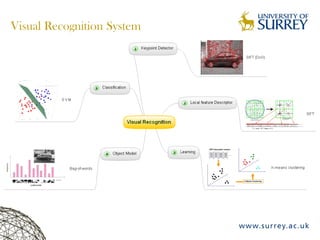

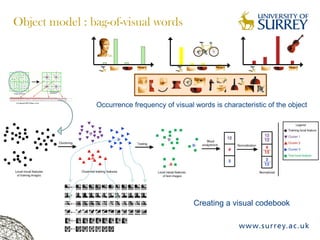
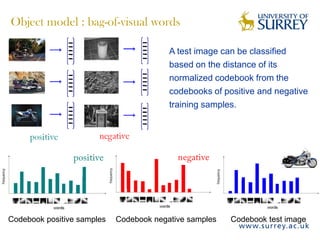
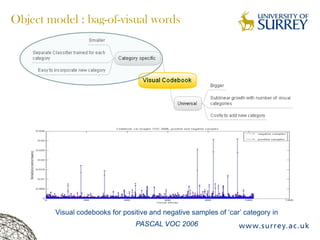
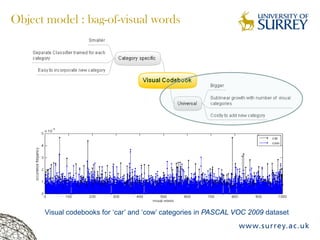
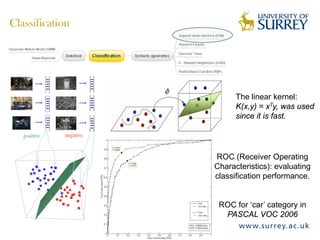
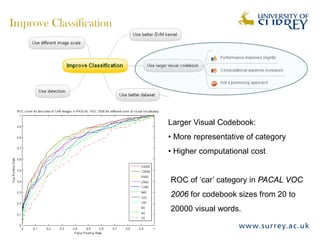
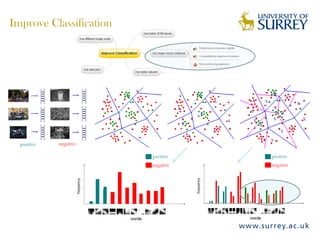
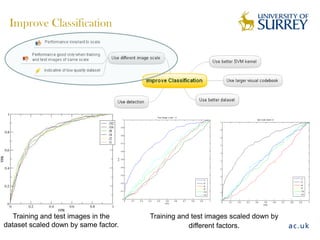
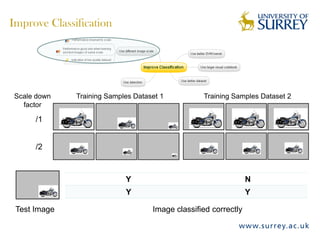
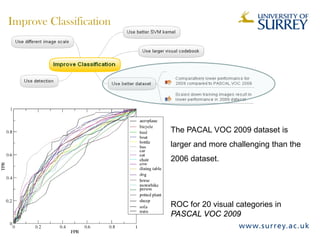
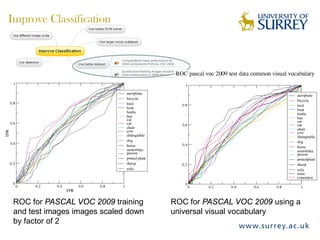
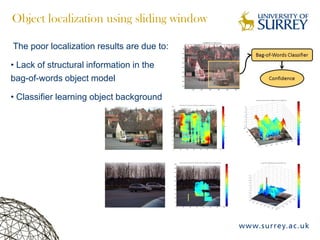



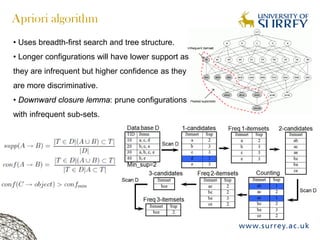
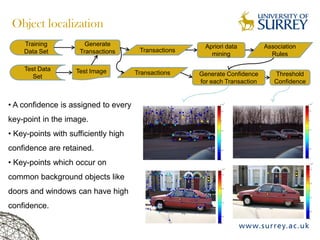
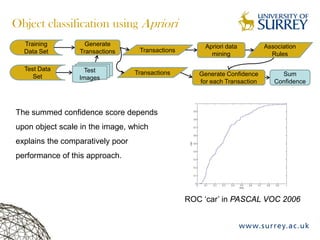






Visual object category recognition using weakly supervised learning is the research topic. The goal is to recognize objects based on their visual properties despite challenges from variations in appearance, pose, scale, occlusion, etc. A visual recognition system is proposed that uses bag-of-visual-words modeling and SIFT features. Classification is improved by increasing the visual codebook size and addressing scale differences between training and test images. Keypoint configurations providing structural information are also explored to improve localization, though classification results were better using bag-of-words. Future work focuses on improving the visual codebook and combining segmentation, context, and hierarchical models.