Downloaded 14 times




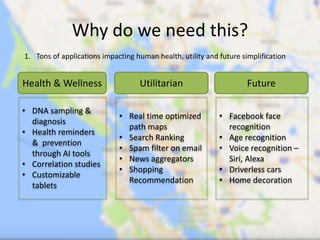

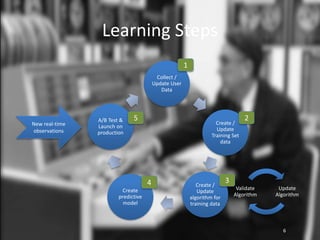

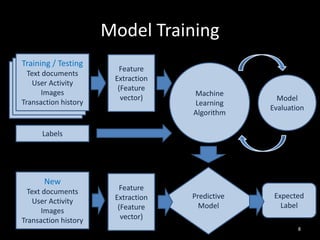

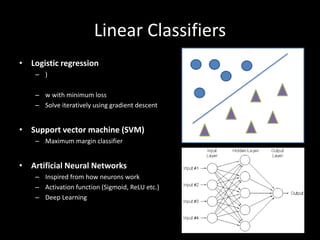
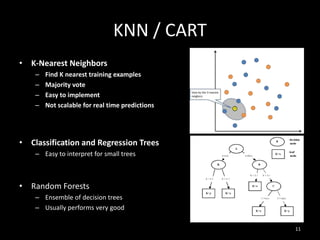
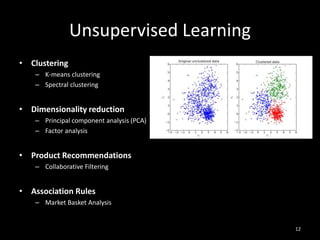
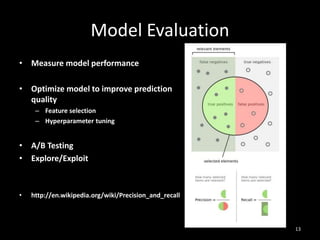
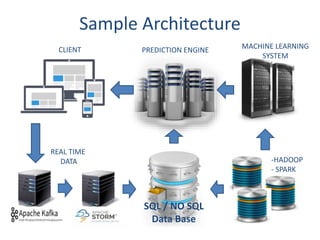



This document provides an overview of machine learning: 1. Machine learning is a branch of artificial intelligence that uses data to help computers learn without being explicitly programmed. It can recognize patterns in large amounts of data. 2. Machine learning involves collecting large datasets, creating algorithms to detect patterns in the data, and using those patterns to make predictions on new data. 3. Machine learning has many applications like improving health, making utilities more efficient, and simplifying the future through technologies like personalized assistants, optimized transportation, and computer vision.







![[2018 台灣人工智慧學校校友年會] Practical experience in mining and evaluating information...](https://cdn.slidesharecdn.com/ss_thumbnails/1615-1655chenaia-info-sys-exp-181130083557-thumbnail.jpg?width=640&height=640&fit=bounds)



































































