Downloaded 65 times









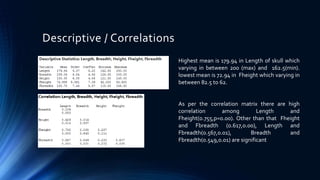

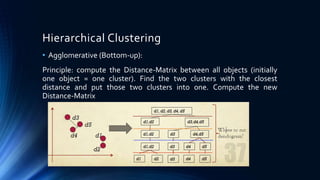


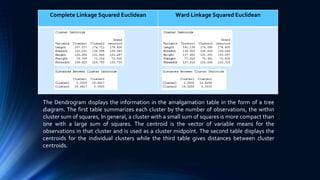
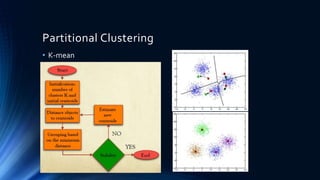
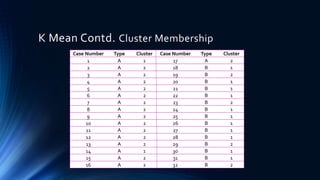









The document discusses a cluster analysis case study on Tibetan skulls collected by Colonel L.A. Waddel, analyzing measurements from two distinct types of skulls to test the hypothesis regarding their genetic origins. It outlines various clustering methods, including hierarchical and k-means clustering, and concludes that the skulls from the Khams district show significant differences from general Tibetans based on measured traits. Validation through discriminant analysis indicates a high discriminatory ability and strong separation between groups.



































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)