Download as PDF, PPTX




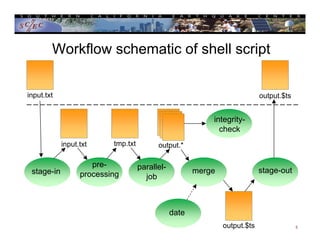












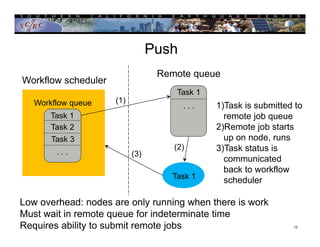
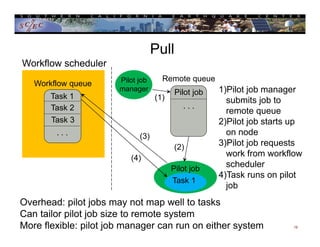
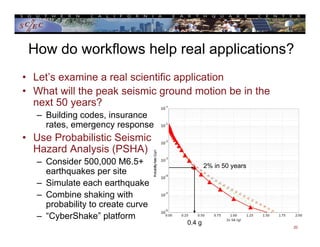












This document provides an overview of scientific workflows, including what they are, common elements, and problems they help address. A workflow is a formal way to express a calculation as a series of tasks with dependencies. Workflow tools automate task execution, data management, scheduling, and more. They can help scale applications from a local system to large clusters. An example is provided of how the CyberShake project uses the Pegasus workflow system to automate probabilistic seismic hazard analysis calculations involving hundreds of thousands of tasks and petabytes of data.










































































































