Download as PDF, PPTX






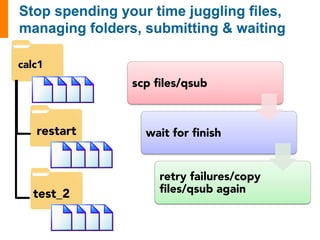






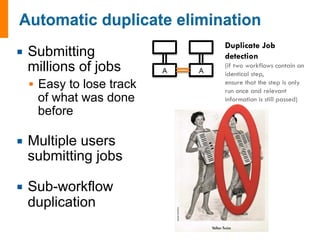



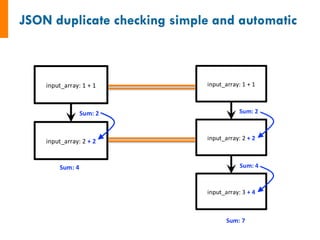
![input_array: [1, 2, 3]
1. Sum input array
2. Write to file
3. Pass result to next job
input_array: [4, 5, 6]
1. Sum input array
2. Write to file
3. Pass result to next job
6 15
input_data: [6, 15]
1. Sum input data
2. Write to file
3. Pass result to next job
-------------------------------------
1. Copy result to home dir](https://image.slidesharecdn.com/jainfw-141111164102-conversion-gate02/85/FireWorks-workflow-software-22-320.jpg)
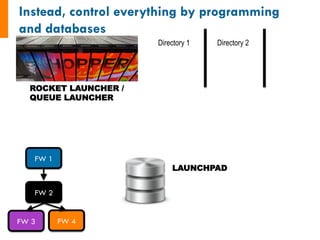
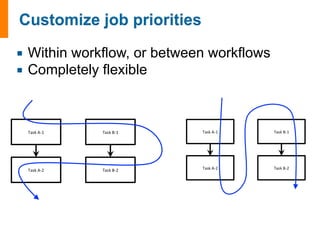
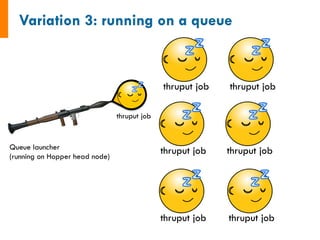
![class
MyAdditionTask(FireTaskBase):
_fw_name
=
"My
Addition
Task"
def
run_task(self,
fw_spec):
input_array: [1, 2, 3]
1. Sum input array
2. Write to file
3. Pass result to next job
input_array
=
fw_spec['input_array']
m_sum
=
sum(input_array)
print("The
sum
of
{}
is:
{}".format(input_array,
m_sum))
with
open('my_sum.txt',
'a')
as
f:
f.writelines(str(m_sum)+'n')
#
store
the
sum;
push
the
sum
to
the
input
array
of
the
next
sum
return
FWAction(stored_data={'sum':
m_sum},
mod_spec=[{'_push':
{'input_array':
m_sum}}])
See
also:
http://pythonhosted.org/FireWorks/guide_to_writing_firetasks.html](https://image.slidesharecdn.com/jainfw-141111164102-conversion-gate02/85/FireWorks-workflow-software-23-320.jpg)
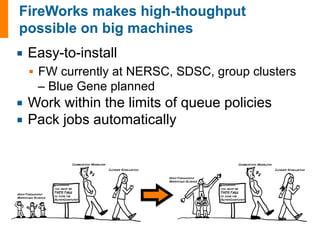
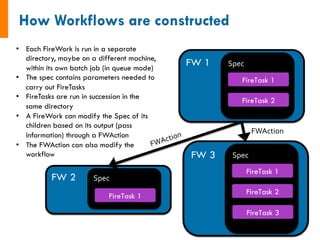
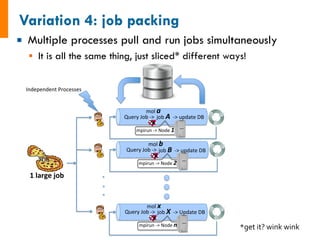
![input_array: [1, 2, 3]
1. Sum input array
2. Write to file
3. Pass result to next job
input_array: [4, 5, 6]
1. Sum input array
2. Write to file
3. Pass result to next job
6 15!
input_data: [6, 15]
1. Sum input data
2. Write to file
3. Pass result to next job
-------------------------------------
1. Copy result to home dir
#
set
up
the
LaunchPad
and
reset
it
launchpad
=
LaunchPad()
launchpad.reset('',
require_password=False)
#
create
Workflow
consisting
of
a
AdditionTask
FWs
+
file
transfer
fw1
=
Firework(MyAdditionTask(),
{"input_array":
[1,2,3]},
name="pt
1A")
fw2
=
Firework(MyAdditionTask(),
{"input_array":
[4,5,6]},
name="pt
1B")
fw3
=
Firework([MyAdditionTask(),
FileTransferTask({"mode":
"cp",
"files":
["my_sum.txt"],
"dest":
"~"})],
name="pt
2")
wf
=
Workflow([fw1,
fw2,
fw3],
{fw1:
fw3,
fw2:
fw3},
name="MAVRL
test")
launchpad.add_wf(wf)
#
launch
the
entire
Workflow
locally
rapidfire(launchpad,
FWorker())](https://image.slidesharecdn.com/jainfw-141111164102-conversion-gate02/85/FireWorks-workflow-software-24-320.jpg)











FireWorks is Python workflow software that was created to address issues with running computational jobs like VASP calculations. It has no error detection, failure recovery, or ability to rerun jobs that failed. FireWorks provides features like automatic storage of job details, error detection and recovery, ability to rerun failed jobs with one command, and scaling of jobs without manual effort. It uses a Launchpad to define and launch workflows of FireTasks that can run jobs on different machines and directories.














![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


























































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

