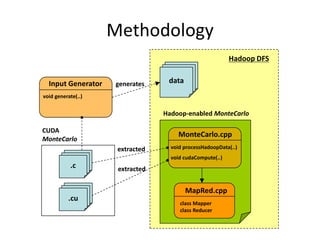
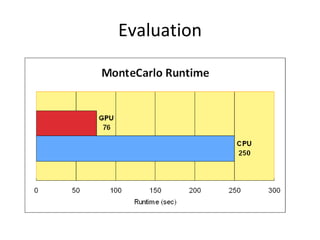
This document summarizes a study on using GPUs (CUDA) to accelerate Hadoop MapReduce workloads. It introduces CUDA into Hadoop clusters, evaluates the performance speedup and power efficiency on matrix multiplication and molecular dynamics simulations, and concludes that GPU acceleration provides up to 20x speedup and reduces power consumption by up to 19/20, making it a cost-effective approach compared to CPU-only upgrades. Future work is outlined to port more applications and support heterogeneous GPU/CPU clusters.


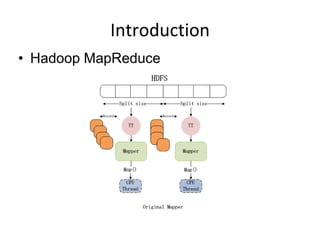
![Introduction
CPU+GPU Architecture
5.devC[]=devA[]+devB[]
G P U
1.Malloc a[],b[],c[]
Main Mem
C P U
2.cudaMalloc
(devA[],
devB[],
devC[])
6.store
8.recycle(devA[],
devB[],devC[])
BUS
3.copy a[],b[]
To devA[].devB[]
7.Copy devC[] to c[]
4.load](https://image.slidesharecdn.com/cuda-131218123829-phpapp01/85/CUDA-performance-study-on-Hadoop-MapReduce-Cluster-4-320.jpg)