Downloaded 10 times












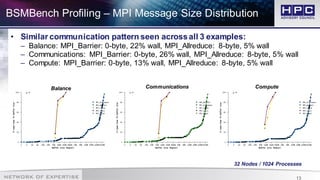
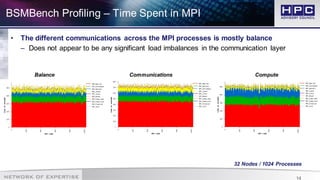
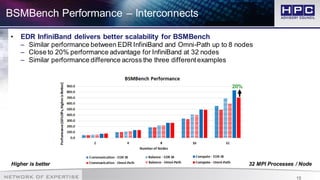
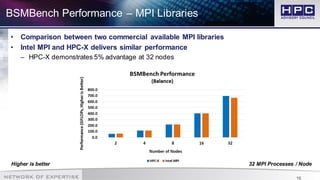

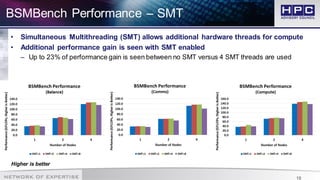
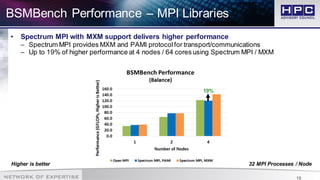
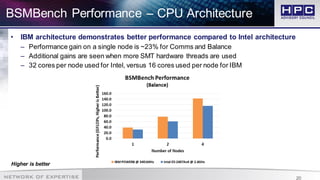




The document presents best practices for application profiling at the HPC Advisory Council High Performance Center, detailing various HPC applications and systems configurations. It emphasizes the importance of performance benchmarking using tools like BSMBench, which examines MPI library performance, interconnect comparisons, and optimization tuning across different architectures. The findings indicate that EDR InfiniBand offers superior scalability and performance advantages over other options, particularly when utilizing simultaneous multithreading and IBM CPU architecture.



































































