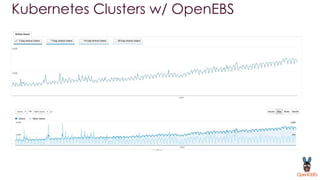
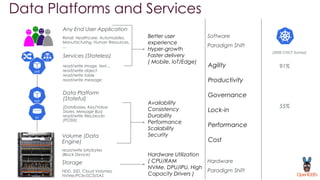
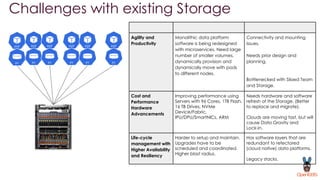
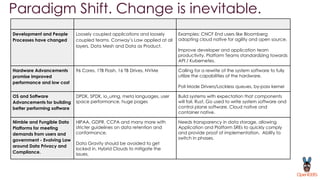
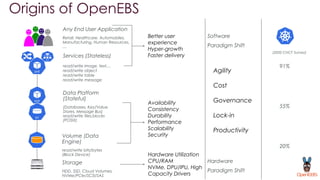
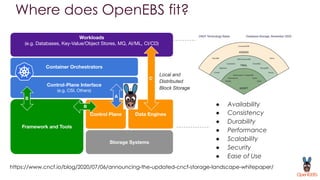
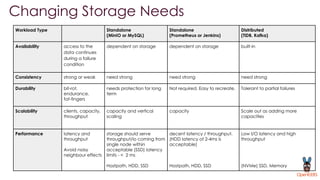
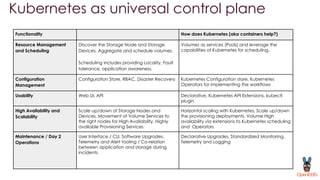
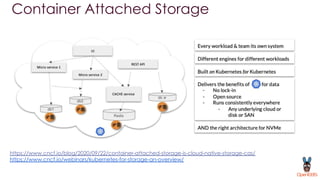
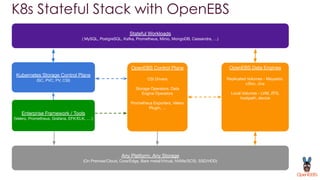
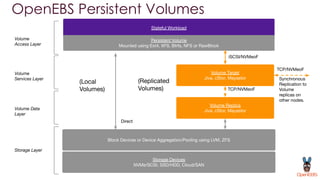
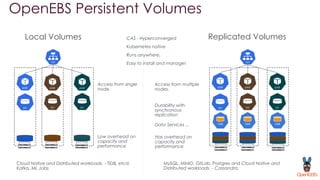
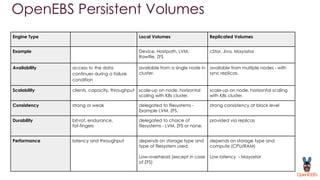
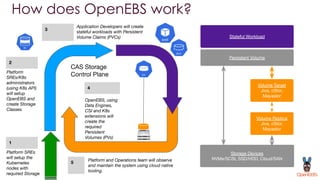
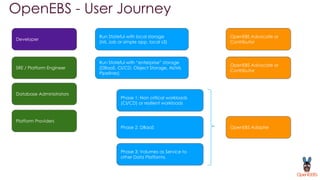
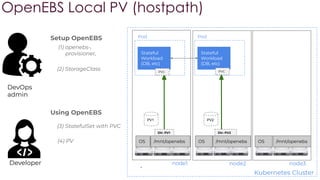
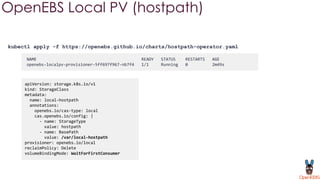
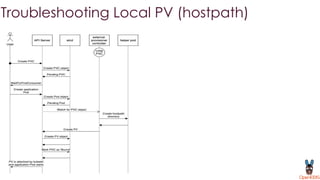
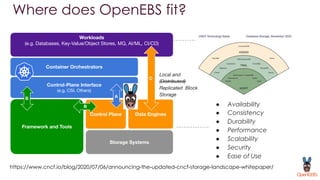
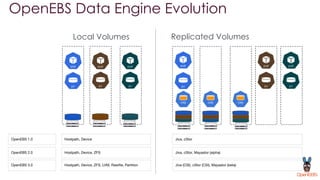
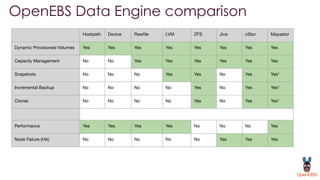
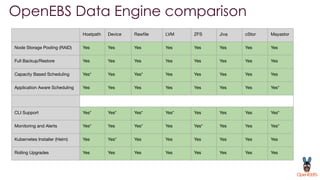
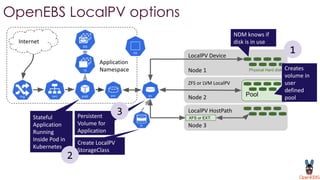
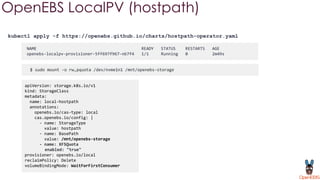
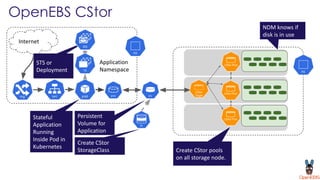
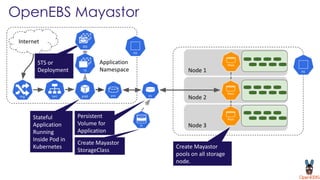
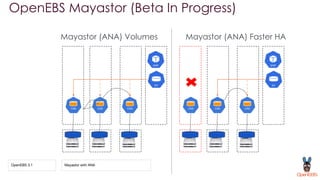
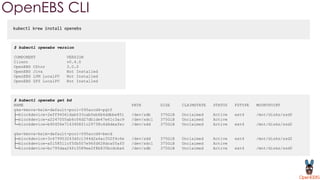
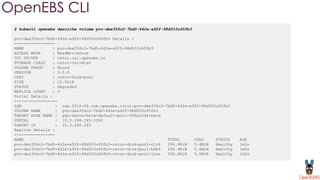
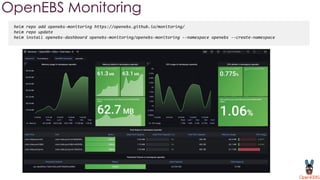
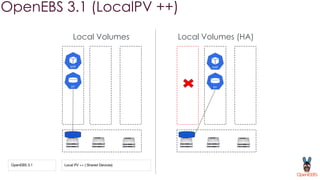
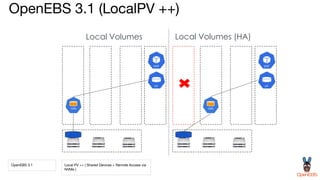
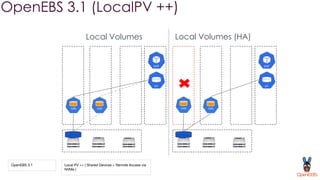
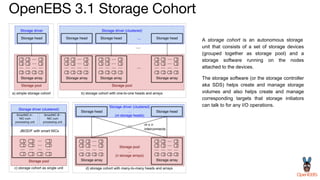
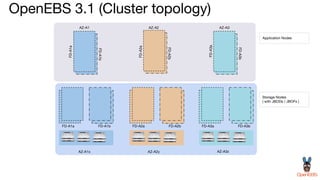
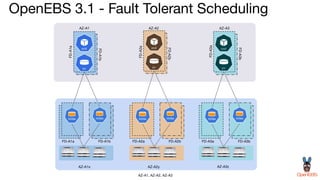
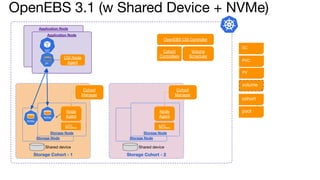
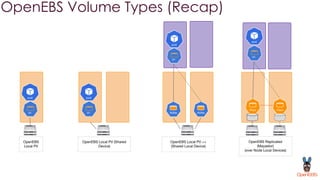
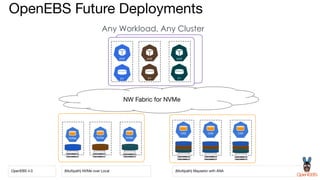
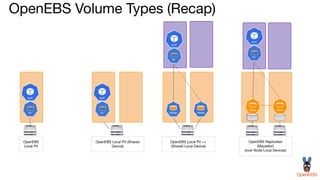
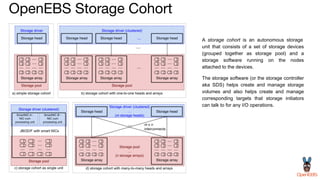
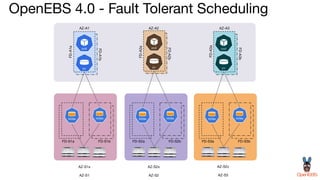
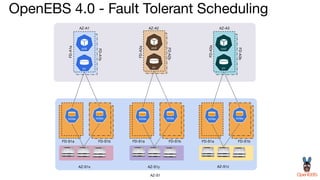
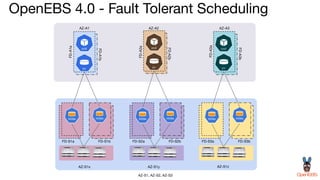
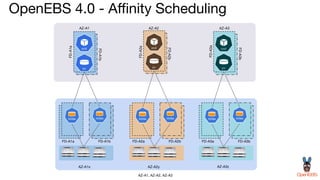
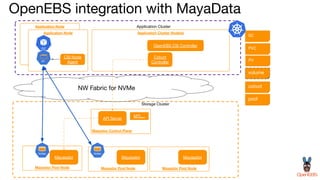
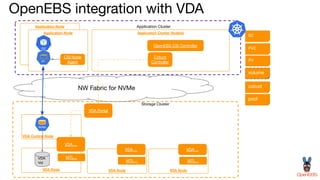
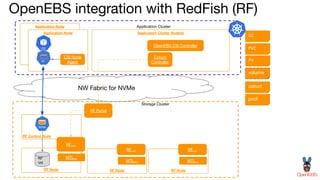
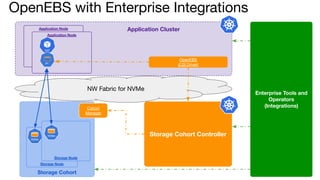
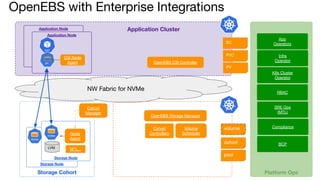
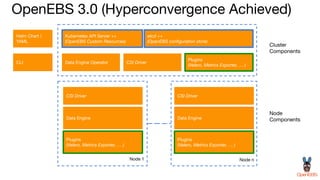
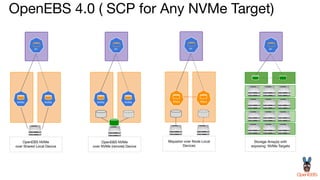
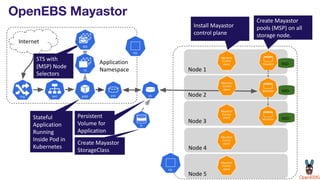
OpenEBS is an open source container attached storage solution for Kubernetes that simplifies running stateful workloads. It provides containerized storage that is native to Kubernetes using features like CSI, dynamic provisioning of volumes, and integration with common DevOps tools. OpenEBS offers both local and replicated volume types to meet different use cases for availability, performance, and scalability. Developers can use OpenEBS volumes like any other Kubernetes storage by creating persistent volume claims in their applications.


























![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[OpenStack] 공개 소프트웨어 오픈스택 입문 & 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)











































