Download as PDF, PPTX




















![from fireworks import Firework, Workflow, LaunchPad, ScriptTask
from fireworks.core.rocket_launcher import rapidfire
# set up the LaunchPad and reset it (first time only)
launchpad = LaunchPad()
launchpad.reset('', require_password=False)
# define the individual FireWorks and Workflow
fw1 = Firework(ScriptTask.from_str('echo "To be, or not to be,"'))
fw2 = Firework(ScriptTask.from_str('echo "that is the question:"'))
wf = Workflow([fw1, fw2], {fw1:fw2}) # set of FWs and dependencies
# store workflow in LaunchPad
launchpad.add_wf(wf)
# pull all jobs and run them locally
rapidfire(launchpad)
33](https://image.slidesharecdn.com/jainfireworksoverviewllnl-161107215223/85/FireWorks-overview-33-320.jpg)


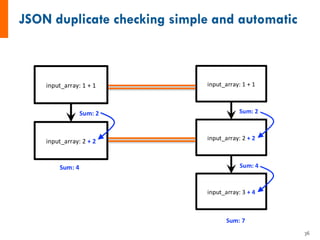


![input_array: [1, 2, 3]
1. Sum input array
2. Write to file
3. Pass result to next job
input_array: [4, 5, 6]
1. Sum input array
2. Write to file
3. Pass result to next job
input_data: [6, 15]
1. Sum input data
2. Write to file
3. Pass result to next job
-------------------------------------
1. Copy result to home dir
6 15](https://image.slidesharecdn.com/jainfireworksoverviewllnl-161107215223/85/FireWorks-overview-42-320.jpg)
![class MyAdditionTask(FireTaskBase):
_fw_name = "My Addition Task"
def run_task(self, fw_spec):
input_array = fw_spec['input_array']
m_sum = sum(input_array)
print("The sum of {} is: {}".format(input_array, m_sum))
with open('my_sum.txt', 'a') as f:
f.writelines(str(m_sum)+'n')
# store the sum; push the sum to the input array of the next
sum
return FWAction(stored_data={'sum': m_sum},
mod_spec=[{'_push': {'input_array': m_sum}}])
See also: http://pythonhosted.org/FireWorks/guide_to_writing_firetasks.html
input_array: [1, 2, 3]
1. Sum input array
2. Write to file
3. Pass result to next job](https://image.slidesharecdn.com/jainfireworksoverviewllnl-161107215223/85/FireWorks-overview-43-320.jpg)
![input_array: [1, 2, 3]
1. Sum input array
2. Write to file
3. Pass result to next job
input_array: [4, 5, 6]
1. Sum input array
2. Write to file
3. Pass result to next job
input_data: [6, 15]
1. Sum input data
2. Write to file
3. Pass result to next job
-------------------------------------
1. Copy result to home dir
6 15!
# set up the LaunchPad and reset it
launchpad = LaunchPad()
launchpad.reset('', require_password=False)
# create Workflow consisting of a AdditionTask FWs + file transfer
fw1 = Firework(MyAdditionTask(), {"input_array": [1,2,3]}, name="pt 1A")
fw2 = Firework(MyAdditionTask(), {"input_array": [4,5,6]}, name="pt 1B")
fw3 = Firework([MyAdditionTask(), FileTransferTask({"mode": "cp", "files": ["my_sum.txt"],
"dest": "~"})], name="pt 2")
wf = Workflow([fw1, fw2, fw3], {fw1: fw3, fw2: fw3}, name="MAVRL test")
launchpad.add_wf(wf)
# launch the entire Workflow locally
rapidfire(launchpad, FWorker())](https://image.slidesharecdn.com/jainfireworksoverviewllnl-161107215223/85/FireWorks-overview-44-320.jpg)










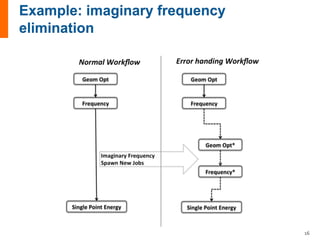
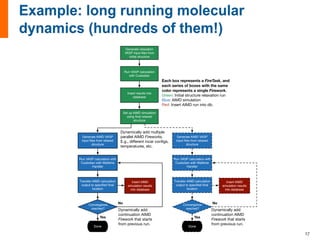
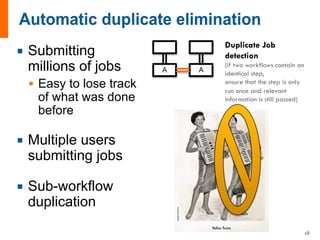
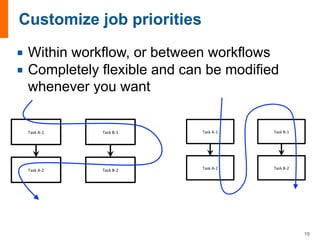
The document provides an introduction and overview of FireWorks workflow software. Some key points: - FireWorks is an open-source, Python-based workflow management software that uses MongoDB and is pip-installable. - It is used by several large DOE projects and materials science groups for tasks like materials modeling, machine learning, and document processing. Over 100 million CPU-hours have been used with everyday production use. - FireWorks allows for very dynamic workflows that can modify themselves intelligently and add/remove tasks over long periods of time in response to results. It also features job detection and status persistence.






























































































