Download as PDF, PPTX

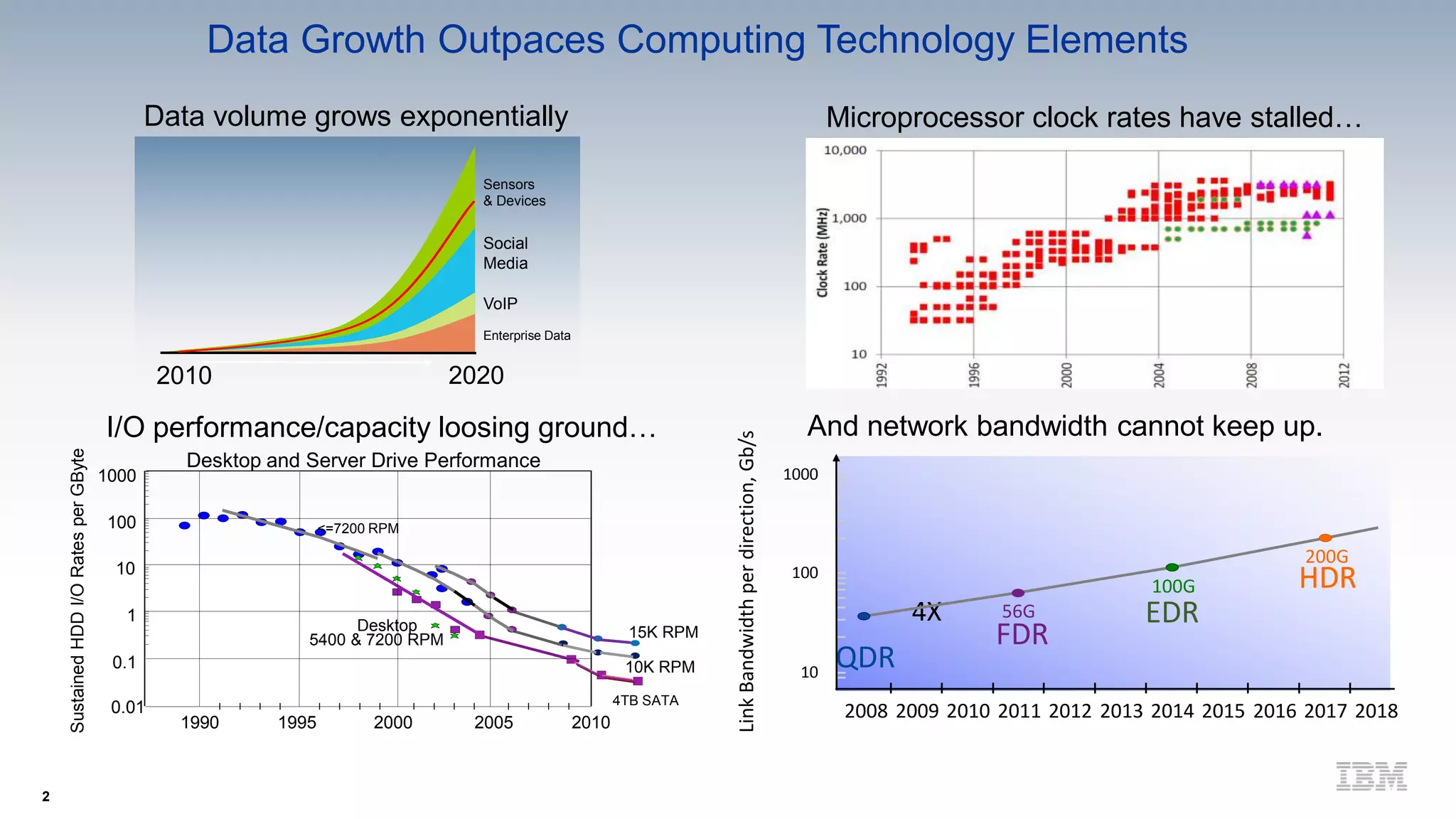


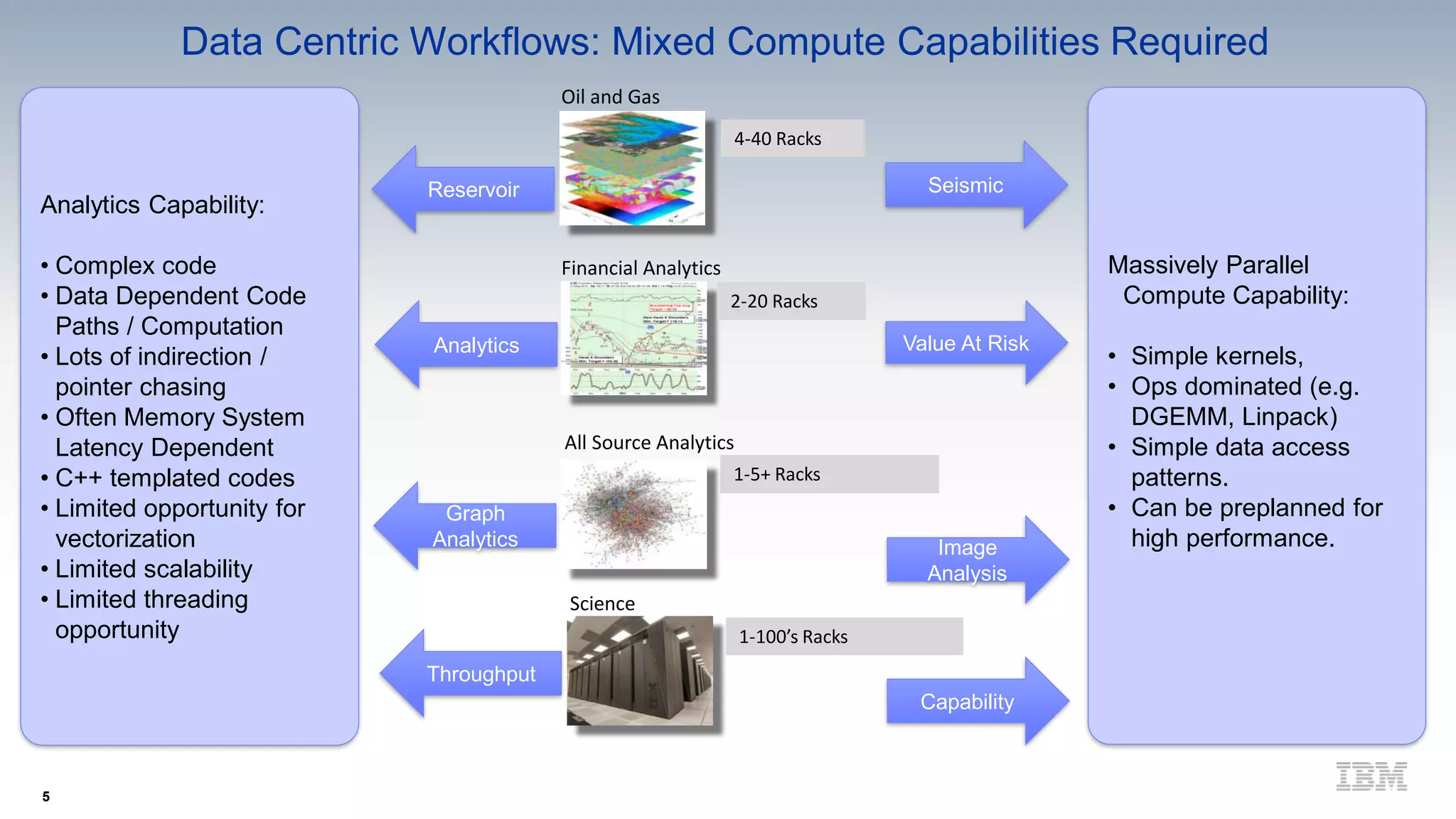















IBM's research on data-centric systems highlights the exponential growth of data and the need for computing technologies to keep pace. Their approach emphasizes shifting from a compute-centric to a data-centric model, focusing on minimizing data movement and enabling compute functionality throughout the system architecture. The OpenPOWER framework aims to enhance flexibility and innovation in handling massive data requirements through a modular and composable architecture.























































































