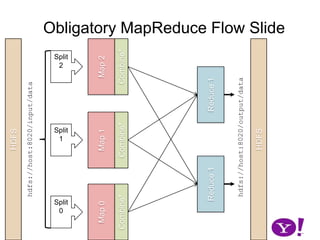
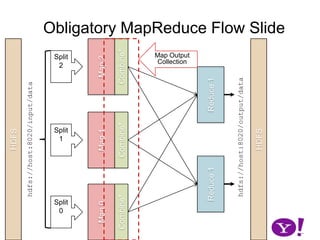
The document discusses different approaches to sorting in MapReduce frameworks over time. It describes Hadoop versions between 0.10-0.22, where sorting was handled by buffering records in memory, spilling to disk when thresholds were exceeded, and merging the spilled files. Later versions improved by distributing the sorting work across maps and making the memory footprint more predictable.

![OverviewHadoop (∞, 0.10)Hadoop [ 0.10, 0.17)Hadoop [0.17, 0.22]LuceneHADOOP-331HADOOP-2919](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-4-320.jpg)
![OverviewHadoop (∞, 0.10)Hadoop [ 0.10, 0.17)Hadoop [0.17, 0.22]LuceneHADOOP-331HADOOP-2919CretaceousJurassicTriassic](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-5-320.jpg)


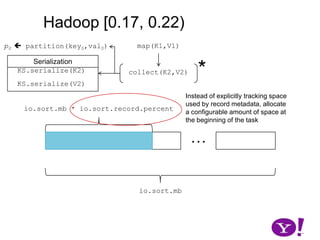
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-8-320.jpg)
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-9-320.jpg)
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-10-320.jpg)
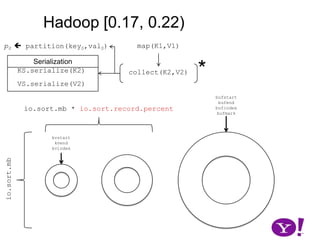
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)key0](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-11-320.jpg)
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)key0](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-12-320.jpg)
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)key0val0](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-13-320.jpg)
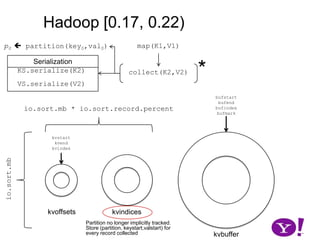
![Problem Descriptionp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)key0val0](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-14-320.jpg)
![Problem Descriptionintp0 partition(key0,val0)map(K1,V1)*Serializationcollect(K2,V2)*K2.write(DataOutput)write(byte[], int, int)*V2.write(DataOutput)write(byte[], int, int)key0val0byte[]byte[]](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-15-320.jpg)

![Ordered set of write(byte[], int, int) for keyn](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-17-320.jpg)
![Ordered set of write(byte[], int, int) for valnChallenges:Size of key/value unknown a priori](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-18-320.jpg)
![Sort occurs after the records are serializedOverviewHadoop (∞, 0.10)Hadoop [ 0.10, 0.17)Hadoop [0.17, 0.22]LuceneHADOOP-331HADOOP-2919CretaceousJurassicTriassic](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-20-320.jpg)
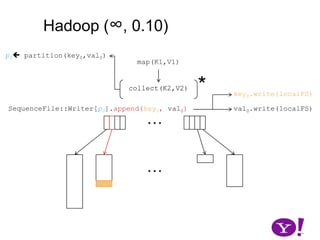
![Hadoop (∞, 0.10)p0 partition(key0,val0)map(K1,V1)*collect(K2,V2)collect(K2,V2)SequenceFile::Writer[p0].append(key0, val0)……](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-21-320.jpg)
![Hadoop (∞, 0.10)p0 partition(key0,val0)map(K1,V1)*collect(K2,V2)collect(K2,V2)key0.write(localFS)SequenceFile::Writer[p0].append(key0, val0)val0.write(localFS)……](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-22-320.jpg)
![Hadoop (∞, 0.10)p0 partition(key0,val0)map(K1,V1)*collect(K2,V2)collect(K2,V2)key0.write(localFS)SequenceFile::Writer[p0].append(key0, val0)val0.write(localFS)……](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-23-320.jpg)
![Hadoop (∞, 0.10)Not necessarily true. SeqFile may buffer configurable amount of data to effect block compresion, stream buffering, etc.p0 partition(key0,val0)map(K1,V1)*collect(K2,V2)collect(K2,V2)key0.write(localFS)SequenceFile::Writer[p0].append(key0, val0)val0.write(localFS)……](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-24-320.jpg)
![Hadoop (∞, 0.10)key0key1clone(key0, val0)map(K1,V1)key2*flush()collect(K2,V2)collect(K2,V2)reduce(keyn, val*)SequenceFile::Writer[p0].append(keyn’, valn’)…p0 partition(key0,val0)…](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-25-320.jpg)
![Hadoop (∞, 0.10)key0key1clone(key0, val0)map(K1,V1)key2*flush()collect(K2,V2)collect(K2,V2)reduce(keyn, val*)SequenceFile::Writer[p0].append(keyn’, valn’)…p0 partition(key0,val0)…](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-26-320.jpg)
![Hadoop (∞, 0.10)key0key1clone(key0, val0)map(K1,V1)key2*flush()collect(K2,V2)collect(K2,V2)reduce(keyn, val*)SequenceFile::Writer[p0].append(keyn’, valn’)…p0 partition(key0,val0)…Combiner may change the partition and ordering of input records. This is no longer supported](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-27-320.jpg)


![OOMExceptions from untracked memory in buffers, particularly when using compression (HADOOP-570)OverviewHadoop (∞, 0.10)Hadoop [ 0.10, 0.17)Hadoop [0.17, 0.22]LuceneHADOOP-331HADOOP-2919CretaceousJurassicTriassic](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-35-320.jpg)
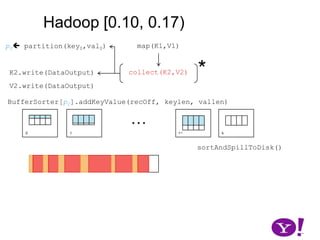
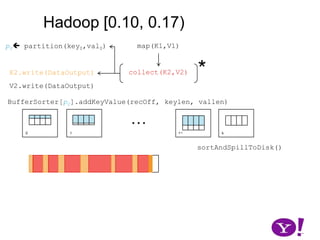
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-36-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-37-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-38-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-39-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-40-320.jpg)
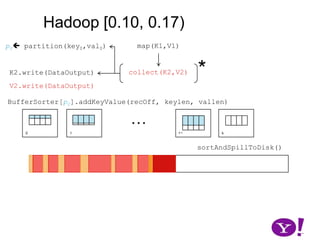
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)Add memory used by all BufferSorter implementations and keyValBuffer. If spill threshold exceeded, then spill contents to disk*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()Keep offset into buffer, length of key, value.](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-41-320.jpg)
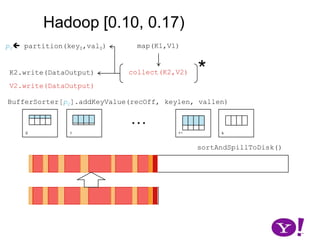
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…*01k-1ksortAndSpillToDisk()*Sort permutes offsets into (offset,keylen,vallen). Once ordered, each record is output into a SeqFile and the partition offsets recorded0](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-42-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…*01k-1ksortAndSpillToDisk()*Sort permutes offsets into (offset,keylen,vallen). Once ordered, each record is output into a SeqFile and the partition offsets recorded0K2.readFields(DataInput)V2.readFields(DataInput)SequenceFile::append(K2,V2)](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-43-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()*If defined, the combiner is now run during the spill, separately over each partition. Values emitted from the combiner are written directly to the output partition.0K2.readFields(DataInput)V2.readFields(DataInput)*<< Combiner >>SequenceFile::append(K2,V2)](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-44-320.jpg)
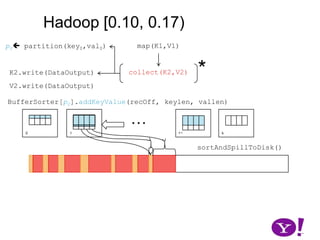
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…*01k-1ksortAndSpillToDisk()01](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-45-320.jpg)
![Hadoop [0.10, 0.17)map(K1,V1)p0 partition(key0,val0)*collect(K2,V2)K2.write(DataOutput)V2.write(DataOutput)BufferSorter[p0].addKeyValue(recOff, keylen, vallen)…01k-1ksortAndSpillToDisk()01……k](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-46-320.jpg)
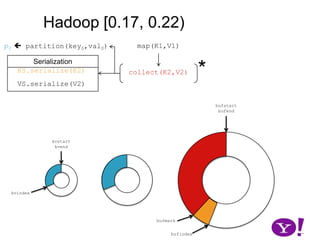
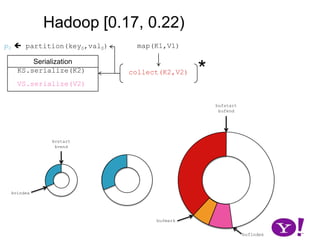
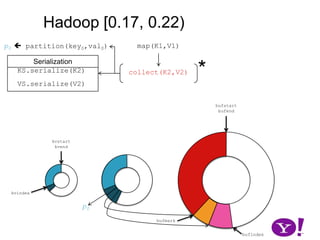
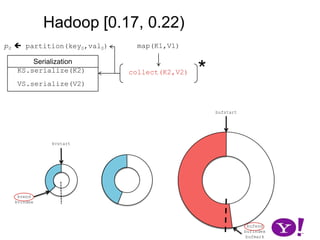
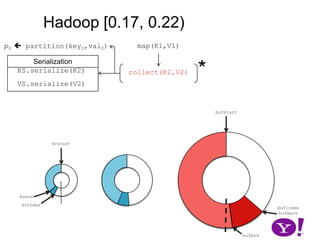
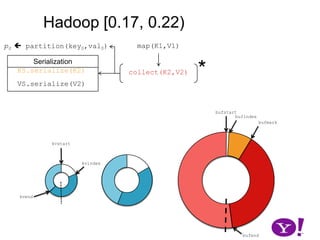
![Though tracked, BufferSort instances take non-negligible space (HADOOP-1698)OverviewHadoop (∞, 0.10)Hadoop [ 0.10, 0.17)Hadoop [0.17, 0.22]LuceneHADOOP-331HADOOP-2919CretaceousJurassicTriassic](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-60-320.jpg)
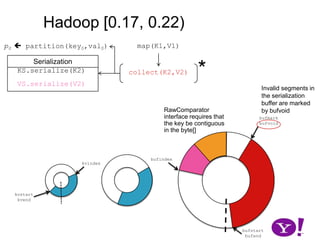
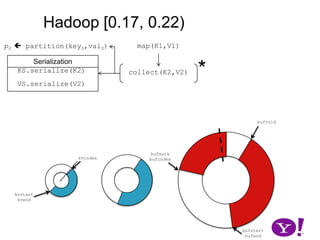

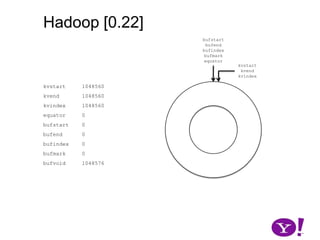
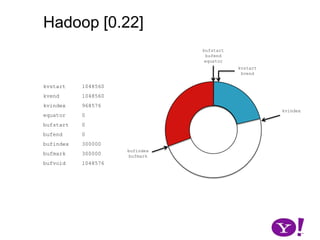
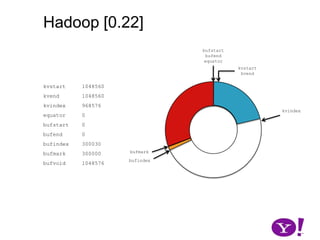
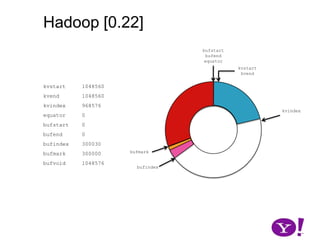
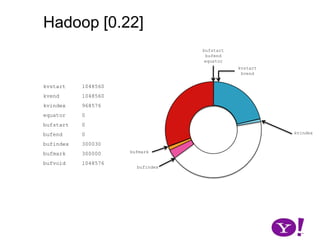
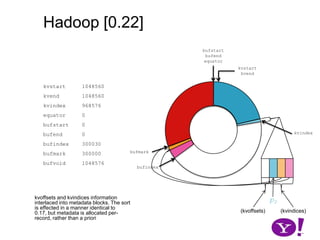
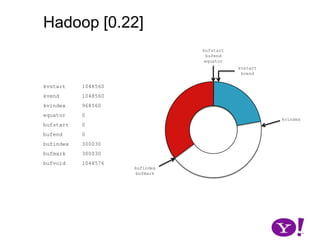
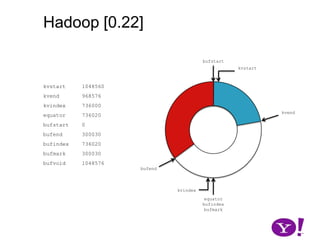
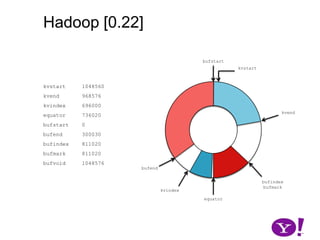
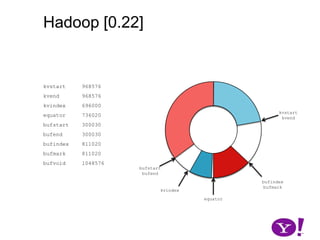
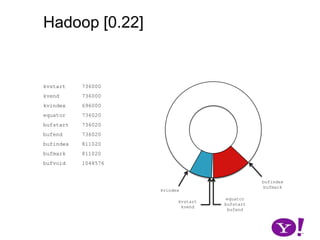
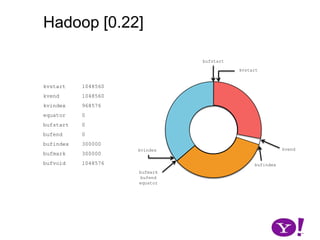
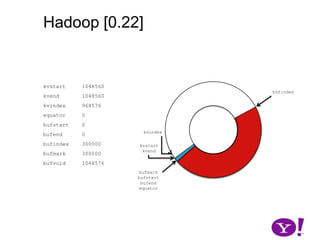
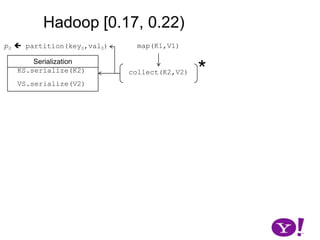
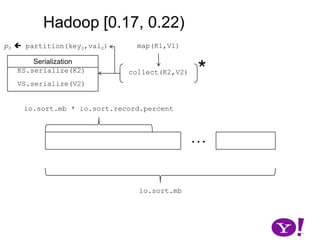
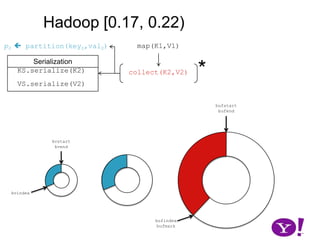
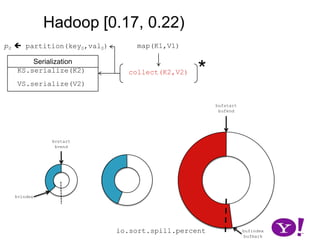
![Hadoop [0.17, 0.22)map(K1,V1)p0 partition(key0,val0)*SerializationKS.serialize(K2)collect(K2,V2)VS.serialize(V2)Invalid segments in the serialization buffer are marked by bufvoidRawComparator interface requires that the key be contiguous in the byte[]bufmarkbufvoidbufindexkvindexkvstartkvendbufstartbufend](https://image.slidesharecdn.com/yahoomr64-100121123614-phpapp02/85/Ordered-Record-Collection-75-320.jpg)