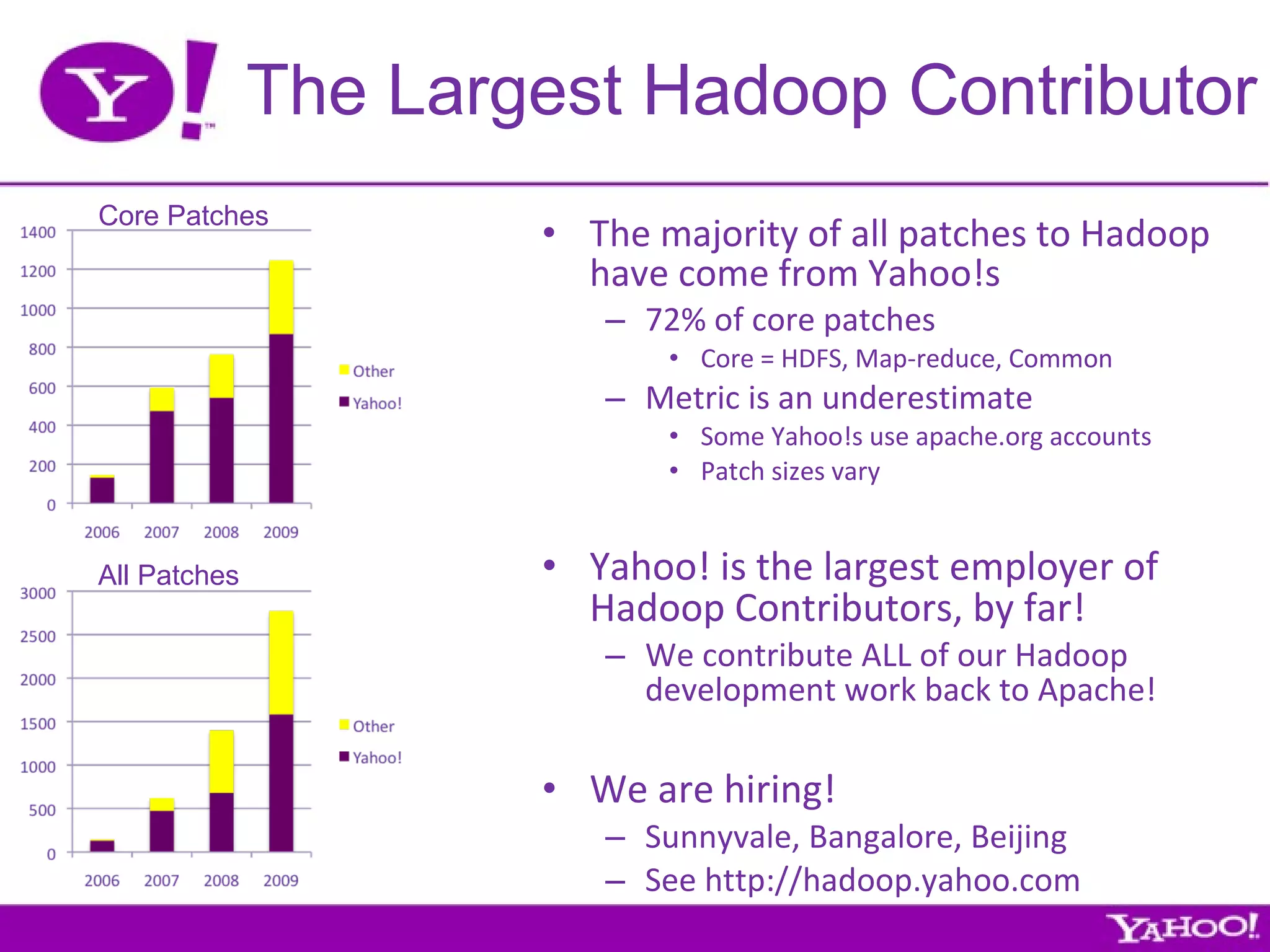
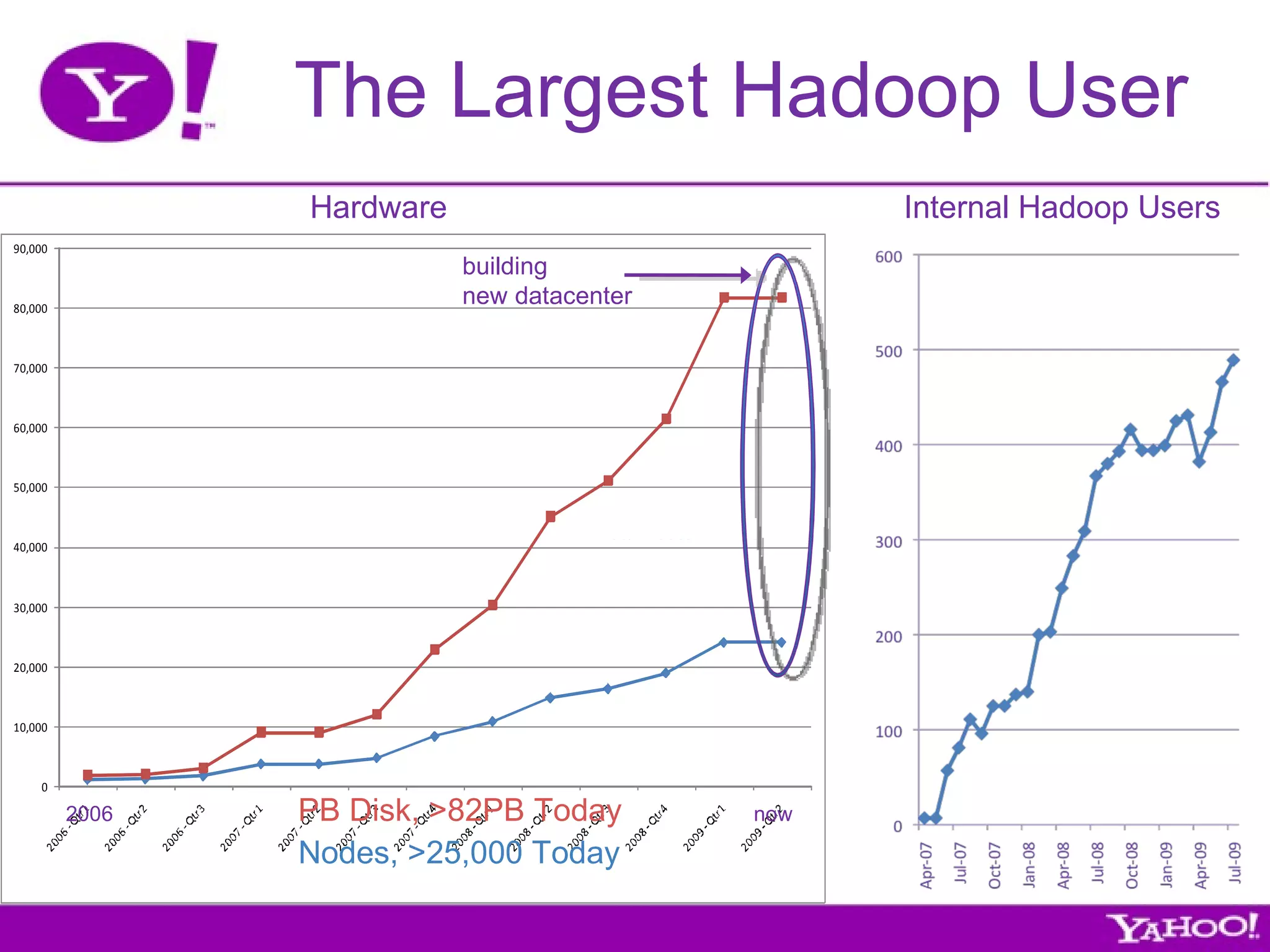
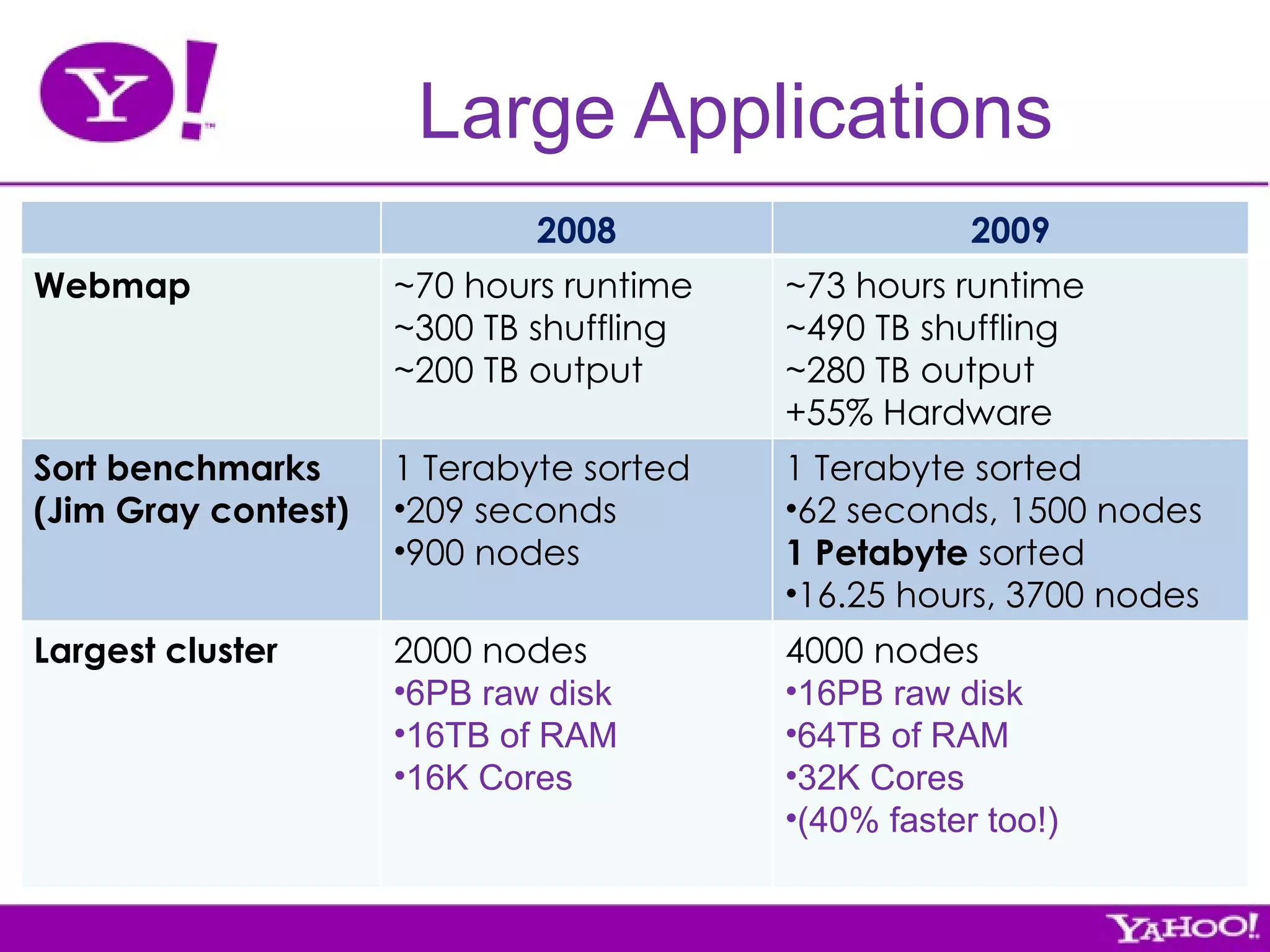
Yahoo! is the largest contributor, tester, and user of Hadoop. They have over 4,000 node Hadoop clusters and use Hadoop to run many of their services and applications. Yahoo! contributes all of their Hadoop development work back to the Apache Foundation as open source software. They are also the largest employer of Hadoop contributors.
















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















