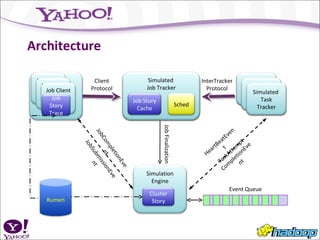
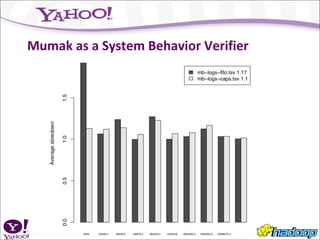
Mumak is a discrete event simulation tool that can simulate a large-scale distributed system like Hadoop faster than running actual benchmarks on a cluster. It reproduces the behavior and performance of the real JobTracker and scheduler by plugging them in and simulating different conditions. While still a work in progress, Mumak has been used to find bugs, profile memory usage, and verify that patches address issues without side effects. Future work includes simulating more conditions and using Mumak to generate unit tests.