Download to read offline







![APACHE
BEAM
UNIFIED MODEL FOR EXECUTING BOTH BATCH
AND STREAM DATA PROCESSING PIPELINES
[whip sound]](https://image.slidesharecdn.com/apachebeampromyknadzieidataengineera-180328191802/85/Apache-beam-promyk-nadziei-data-engineera-na-Torun-JUG-28-03-2018-10-320.jpg)















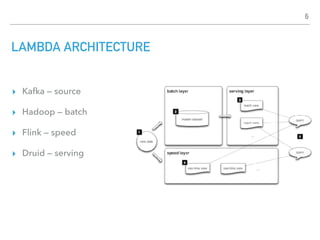
![APACHE BEAM
TWEETS
Predictions
Tweets
READS
WRITES
#juzwiosna; #jug juz dzis; #java 10 GA released
EXTRACT jug, java, juzwiosna
COUNT
EXPAND
jug -> 10k, java -> 4M, juzwiosna -> 100
{j -> [jug -> 10k, java -> 4M, juzwiosna -> 100],
ju-> [jug -> 10k, juzwiosna -> 100]}
26](https://image.slidesharecdn.com/apachebeampromyknadzieidataengineera-180328191802/85/Apache-beam-promyk-nadziei-data-engineera-na-Torun-JUG-28-03-2018-26-320.jpg)
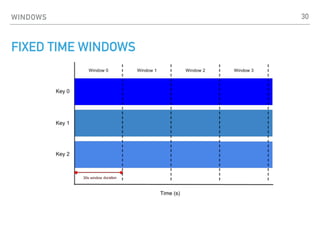
![APACHE BEAM
TWEETS
Predictions
Tweets
READS
WRITES
#juzwiosna; #jug juz dzis; #java 10 GA released
{j->[java, jug, juzwiosna], ju->[jug, juzwiosna]}
EXTRACT jug, java, juzwiosna
COUNT
EXPAND
TOP(3)
jug -> 10k, java -> 4M, juzwiosna -> 100
{j -> [jug -> 10k, java -> 4M, juzwiosna -> 100],
ju-> [jug -> 10k, juzwiosna -> 100]}
27](https://image.slidesharecdn.com/apachebeampromyknadzieidataengineera-180328191802/85/Apache-beam-promyk-nadziei-data-engineera-na-Torun-JUG-28-03-2018-27-320.jpg)





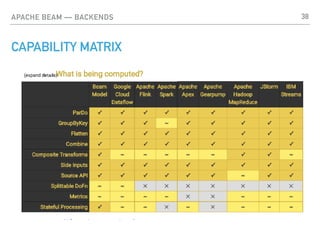









The document discusses Apache Beam, an open-source framework designed for executing ETL (Extract, Transform, Load) processes for both batch and streaming data processing. It details the architecture, core concepts such as transformations and windowing, and practical implementations, showcasing how Apache Beam can streamline data processing tasks across different backends. Additionally, it highlights various use cases for Apache Beam, including fraud detection and sentiment analysis.



































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)