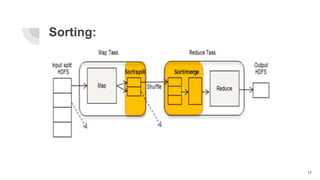
MapReduce is a programming framework within Hadoop for processing large data sets using a parallel and distributed model that operates on key-value pairs. It involves two main processes: 'map', which filters and sorts input data, and 'reduce', which aggregates results into a final output. Key features include input/output formats, joining capabilities for large datasets, built-in counters for job statistics, and scalability with fault tolerance.