Download to read offline







![The neuron
x = [x1, x2, …. xI ]
w = [w1, w2, …. wI ]
u = x.w
Activation function](https://image.slidesharecdn.com/20170921mxnetworkshop-170922141656/85/Deep-Learning-with-Apache-MXNet-September-2017-7-320.jpg)


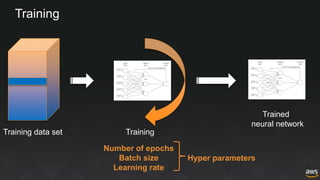
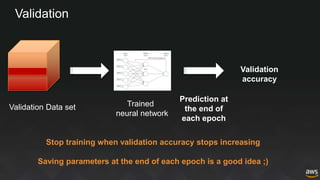
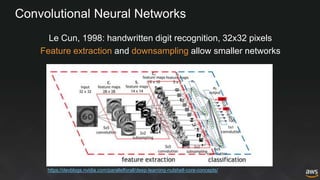


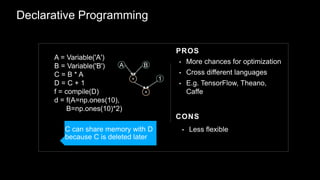
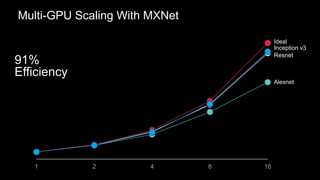
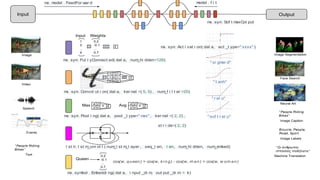



The document provides an overview of deep learning with Apache MXNet. It discusses key concepts like neural networks, training processes, convolutional neural networks, and Apache MXNet. It also outlines examples of using MXNet, including building a first network, using pre-trained models, learning from scratch on datasets like MNIST, and fine-tuning models on CIFAR-10. The document concludes by mentioning an example of using MXNet with Keras and a quick reference to Sockeye.




















































































