Downloaded 40 times





















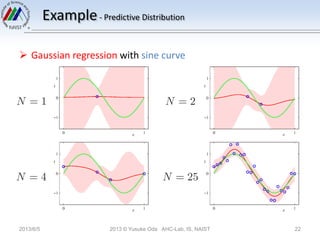
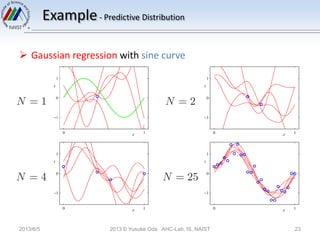
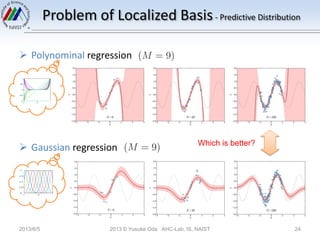










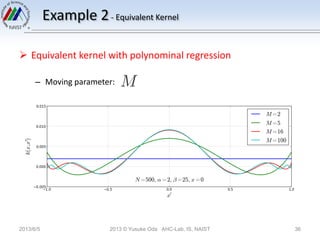



The document discusses Bayesian linear regression. It introduces the parameter distribution by assuming a Gaussian prior distribution for the model parameters. This leads to a Gaussian posterior distribution. It then discusses the predictive distribution for new data points by marginalizing over the posterior distribution of the parameters. Finally, it introduces the concept of an equivalent kernel, which allows predictions to be written as a linear combination of the training targets using a kernel matrix rather than by calculating the model parameters.




![[DL輪読会]Bayesian Uncertainty Estimation for Batch Normalized Deep Networks](https://cdn.slidesharecdn.com/ss_thumbnails/190719dlver2-190719035734-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Ridge-i 論文よみかい] Wasserstein auto encoder](https://cdn.slidesharecdn.com/ss_thumbnails/wassersteinauto-encoder-181006055019-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)










![[AI07] Revolutionizing Image Processing with Cognitive Toolkit](https://cdn.slidesharecdn.com/ss_thumbnails/ai07-170602095346-thumbnail.jpg?width=640&height=640&fit=bounds)




























































