Download as PDF, PPTX













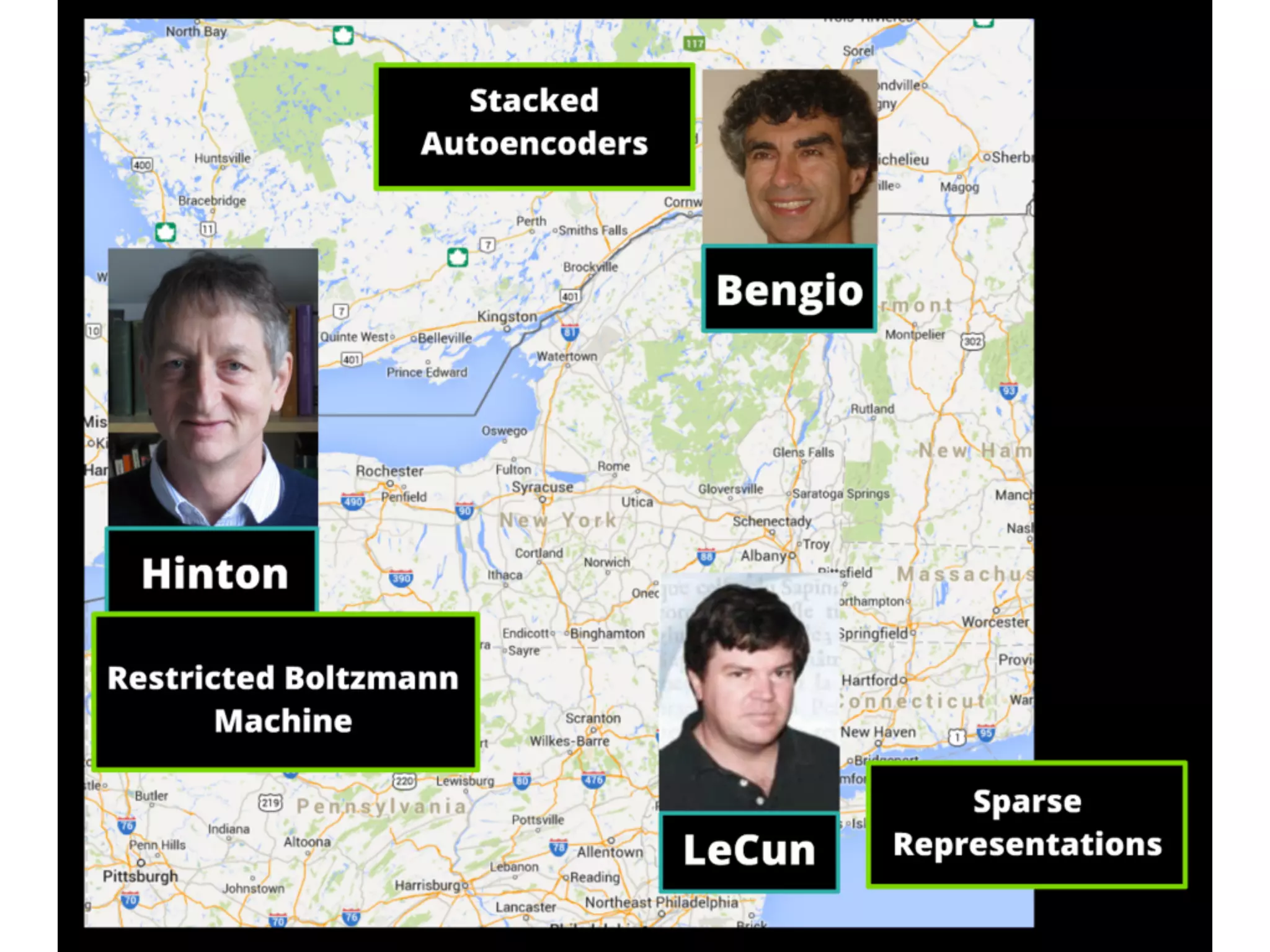
![“2006”
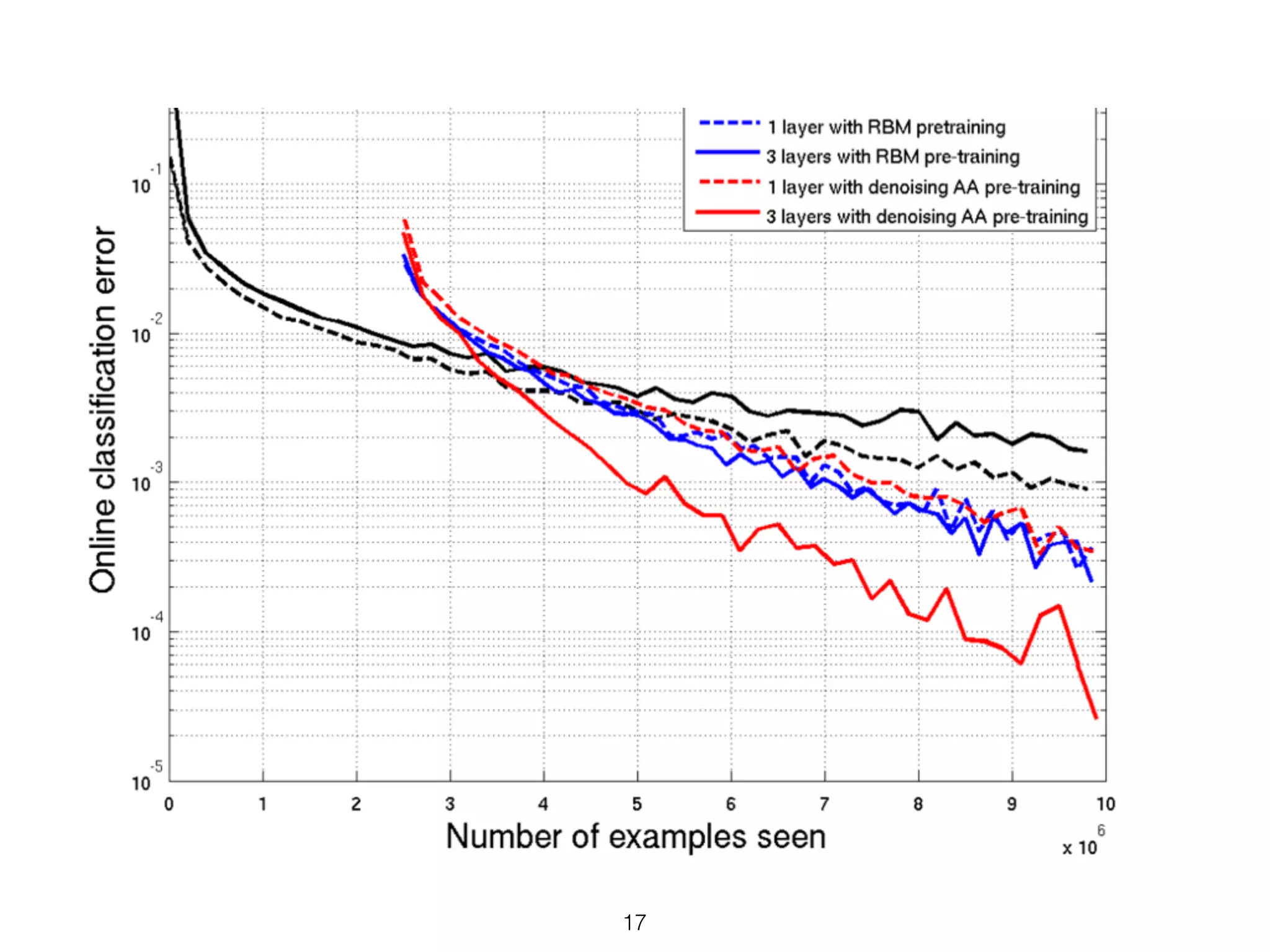
• New methods for unsupervised pre-training
• Stacked RBM’s (Deep Belief Networks [DBN’s] )
• Hinton, G. E, Osindero, S., and Teh, Y. W. (2006). A fast learning
algorithm for deep belief nets. Neural Computation,
18:1527-1554.
• Hinton, G. E. and Salakhutdinov, R. R, Reducing the
dimensionality of data with neural networks. Science, Vol. 313.
no. 5786, pp. 504 - 507, 28 July 2006.
13
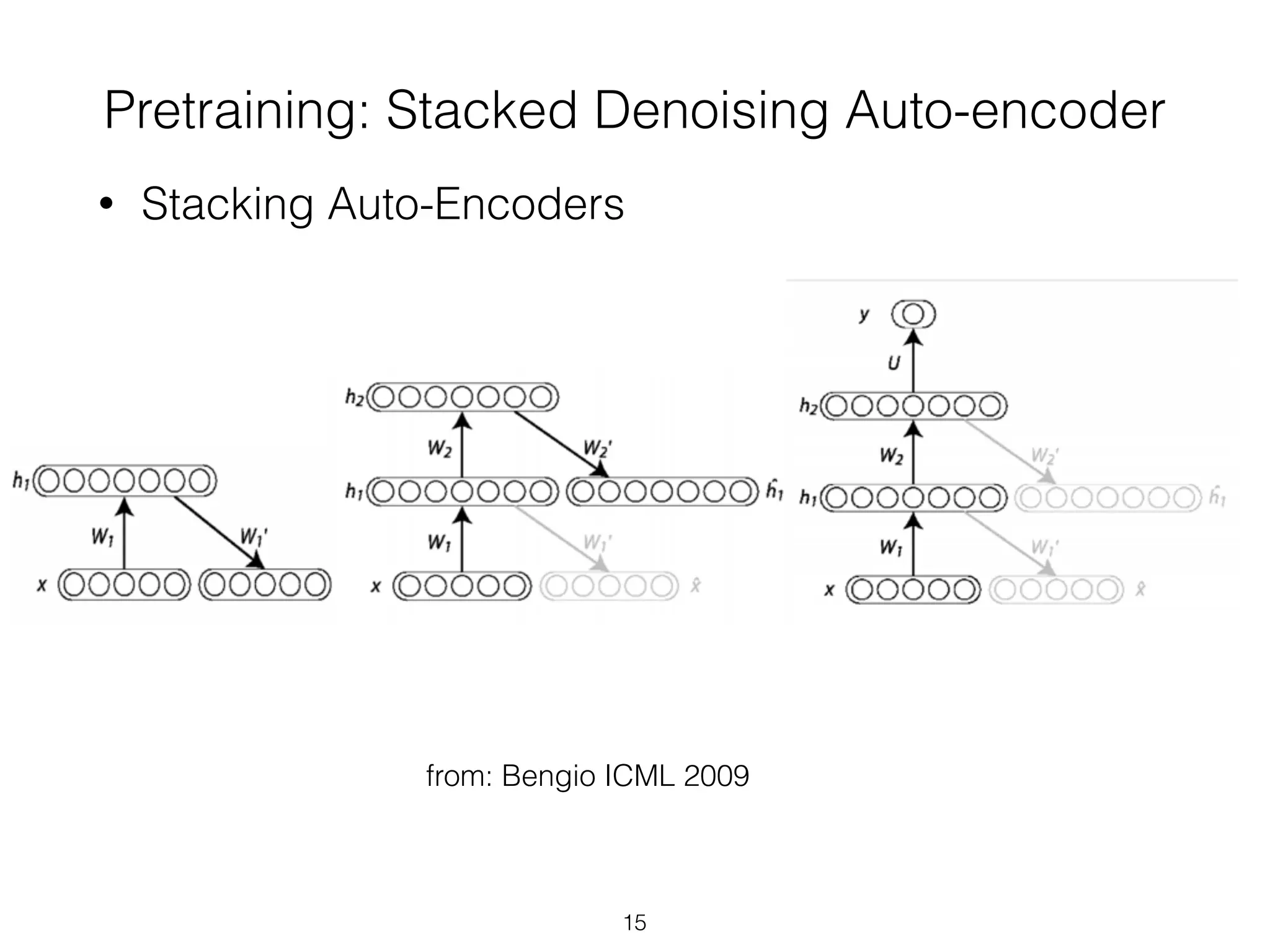
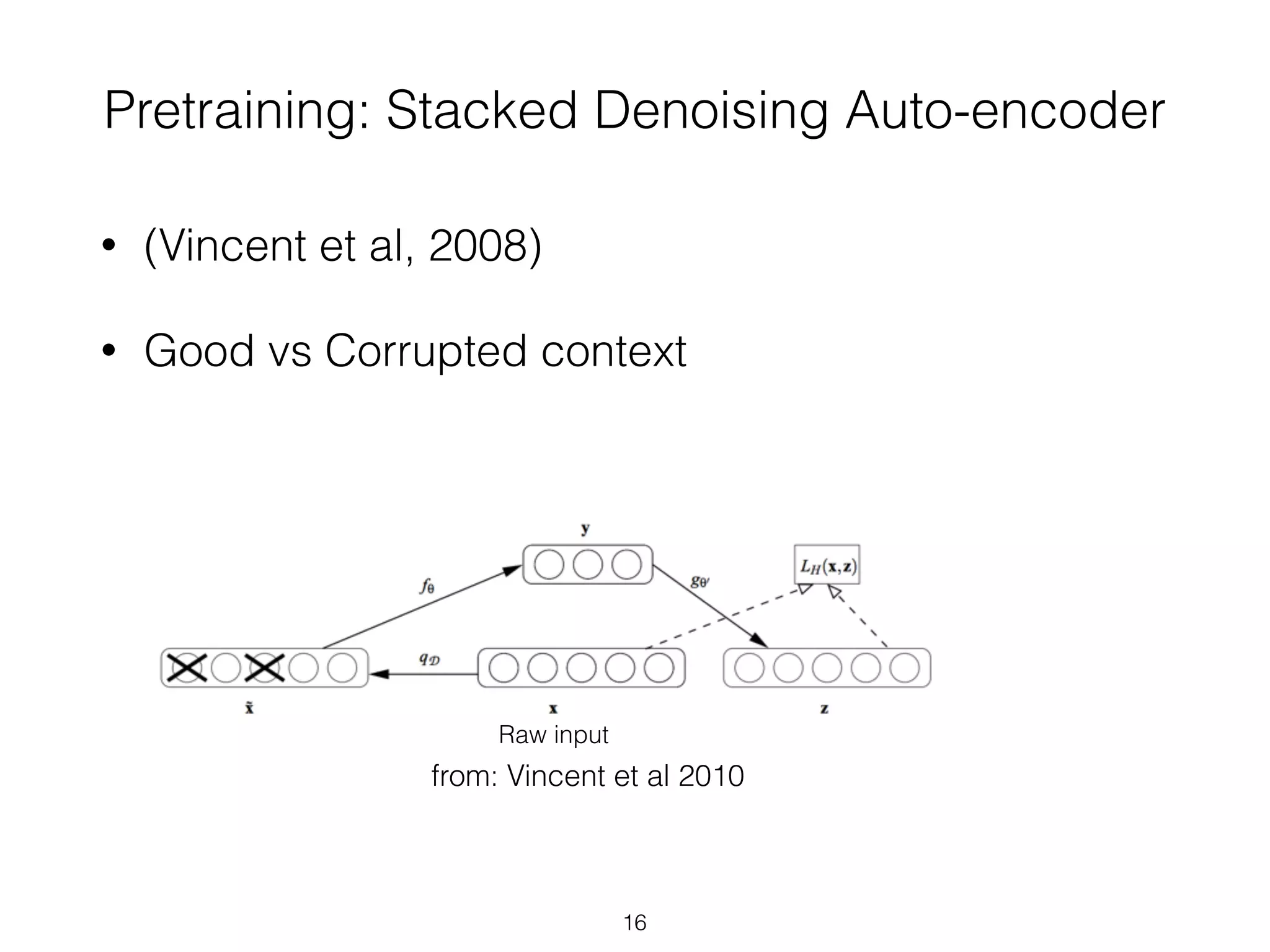
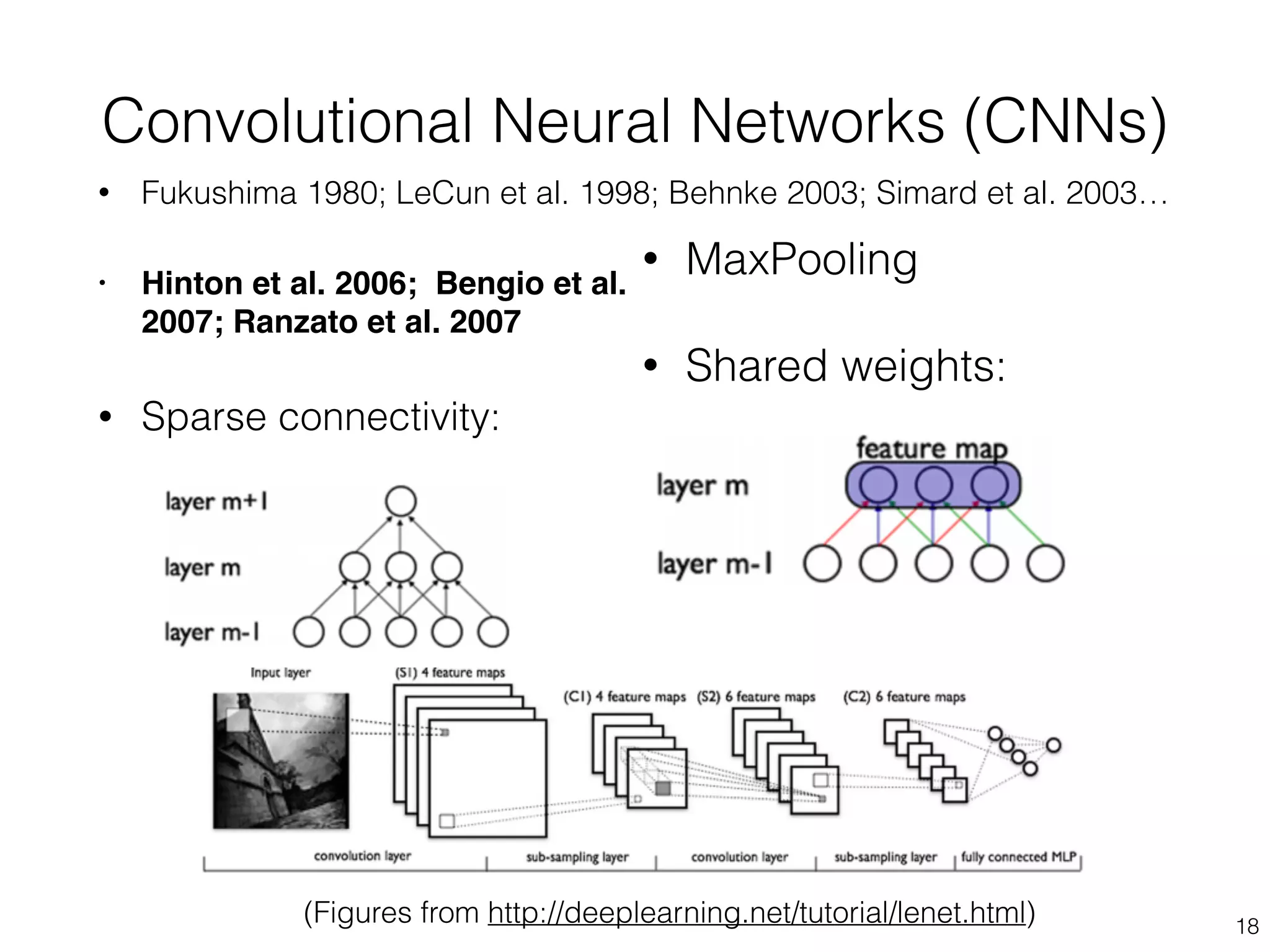
• (Stacked) Autoencoders
• Bengio, Y., Lamblin, P., Popovici, P., Larochelle, H. (2007).
Greedy Layer-Wise Training of Deep Networks, Advances in
Neural Information Processing Systems 19](https://image.slidesharecdn.com/2014-10-21sicsdlnlpg-141022031857-conversion-gate02/75/Deep-Learning-NLP-Graphs-to-the-Rescue-20-2048.jpg)






























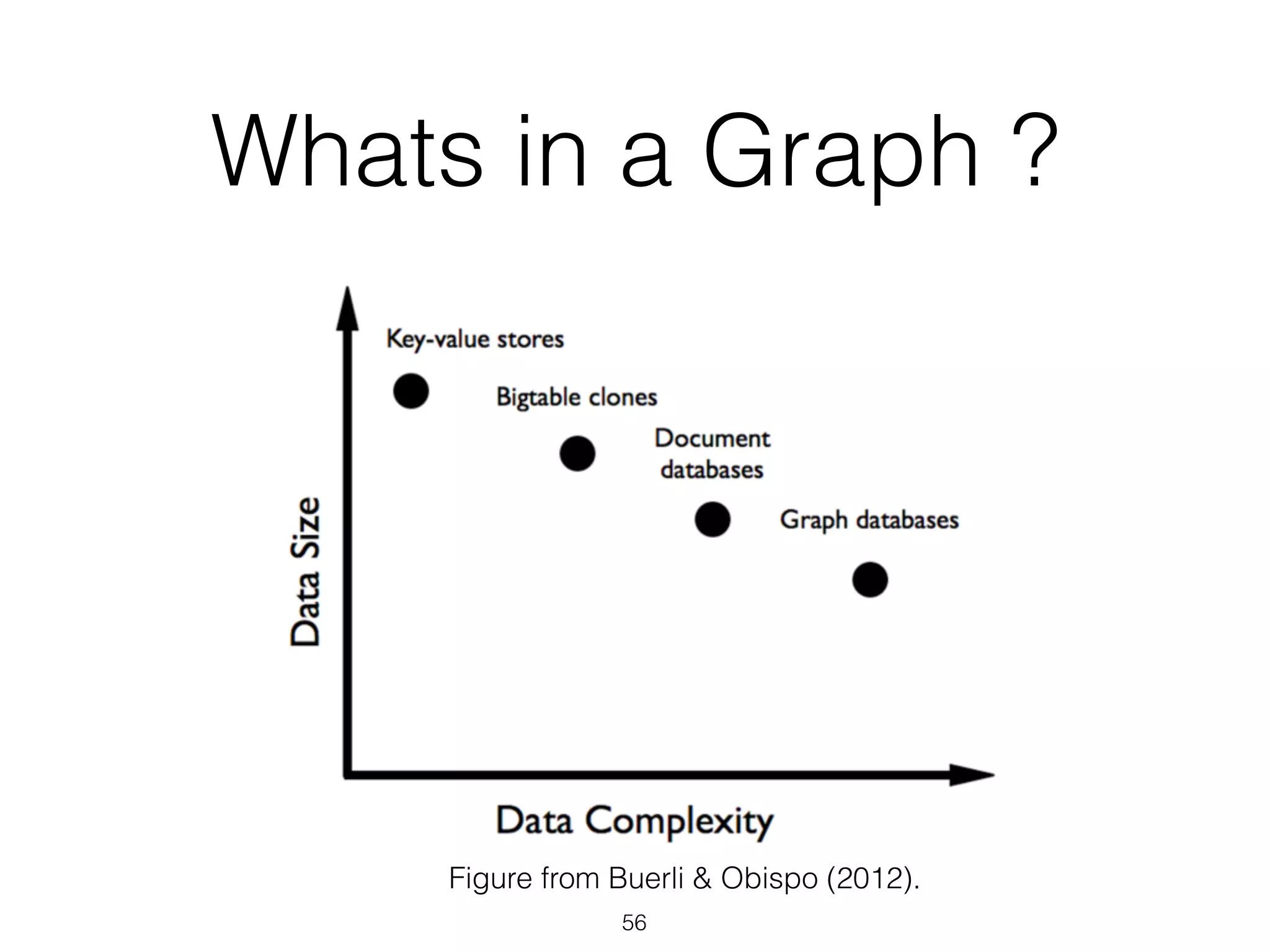
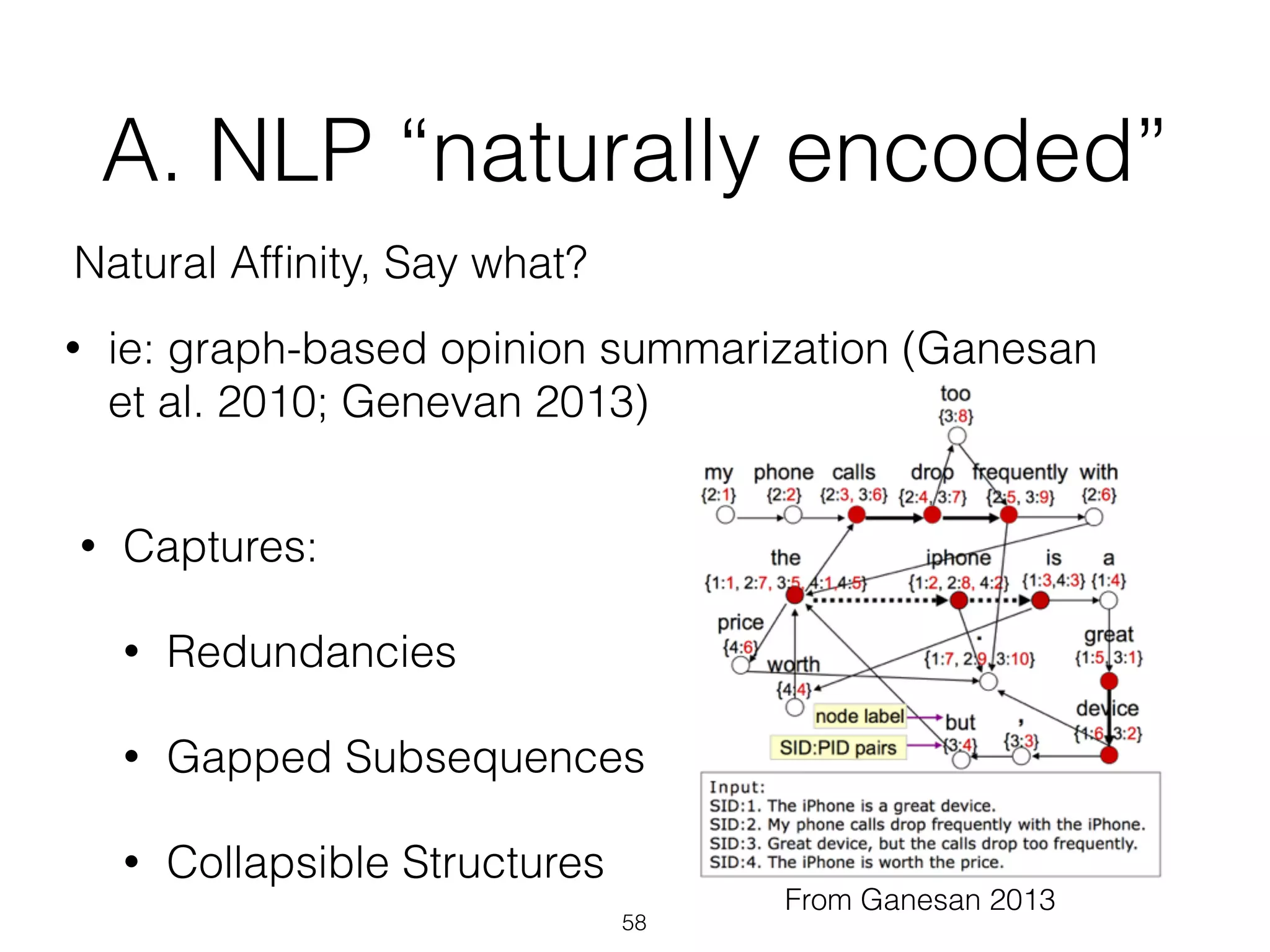
![Graph-Based NLP
• Graphs have a “natural affinity” with NLP [ feel free
to quote me on that ;) ]
• relation-oriented
• index-free adjacency
55](https://image.slidesharecdn.com/2014-10-21sicsdlnlpg-141022031857-conversion-gate02/75/Deep-Learning-NLP-Graphs-to-the-Rescue-80-2048.jpg)




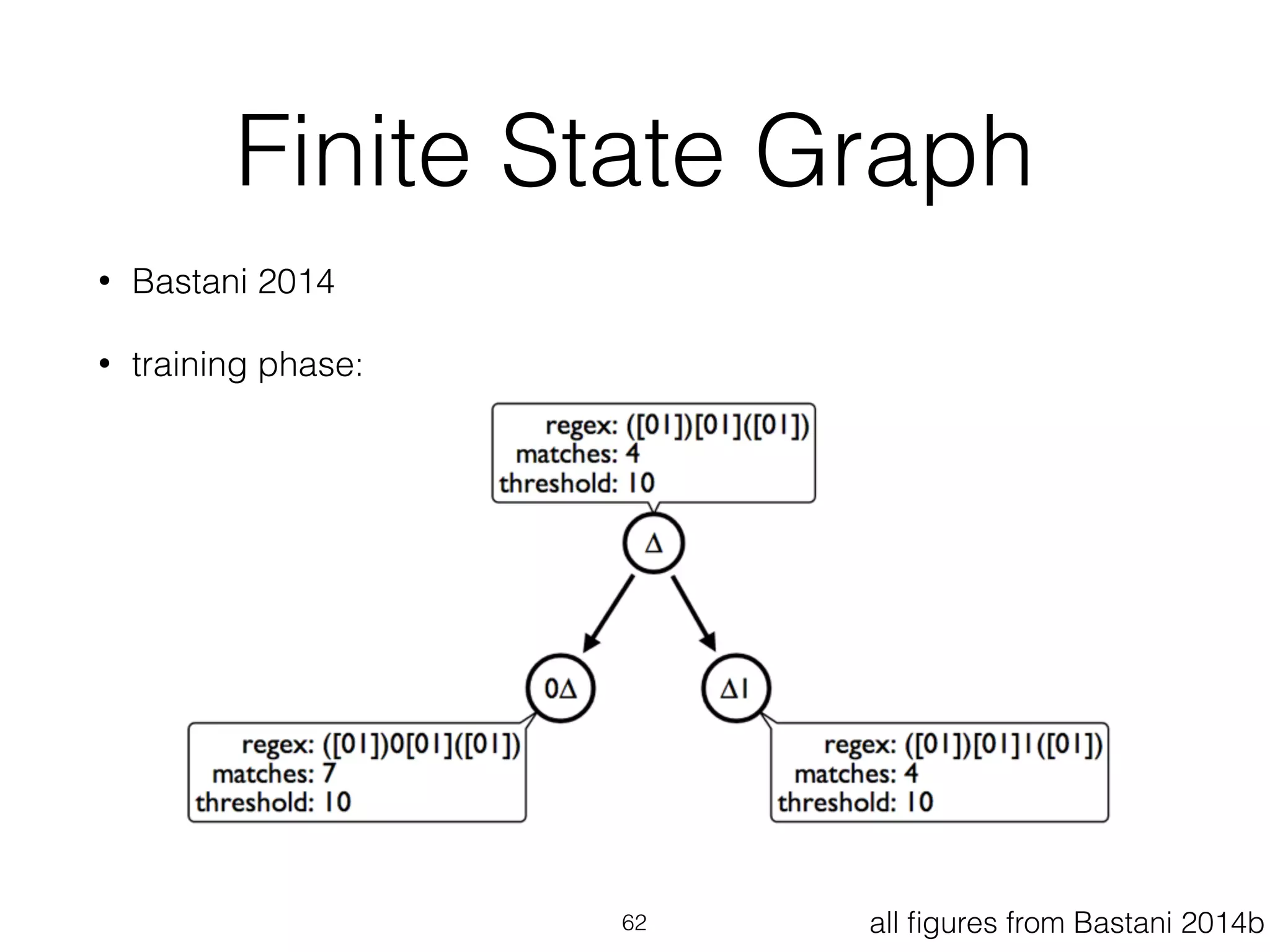
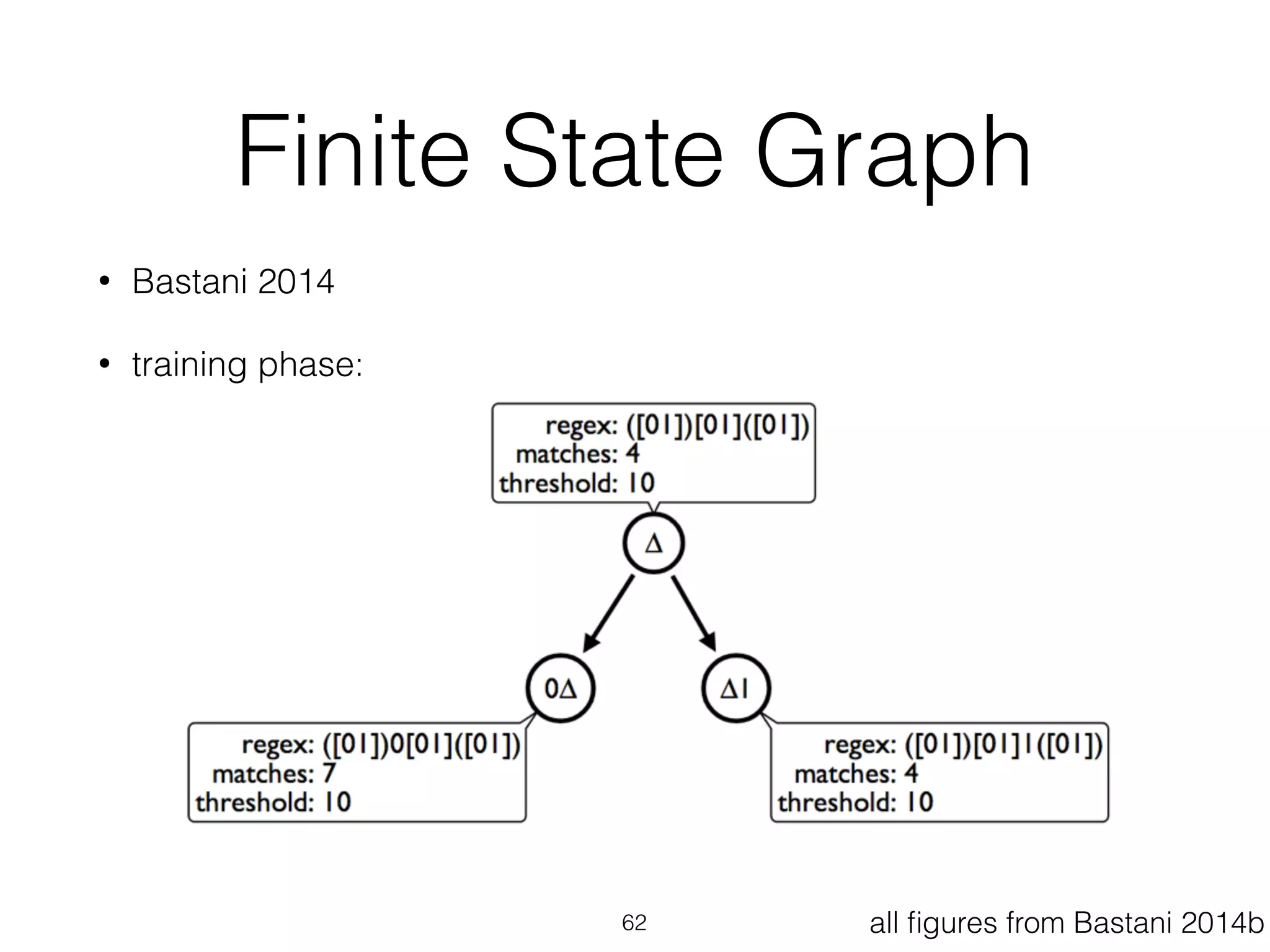



















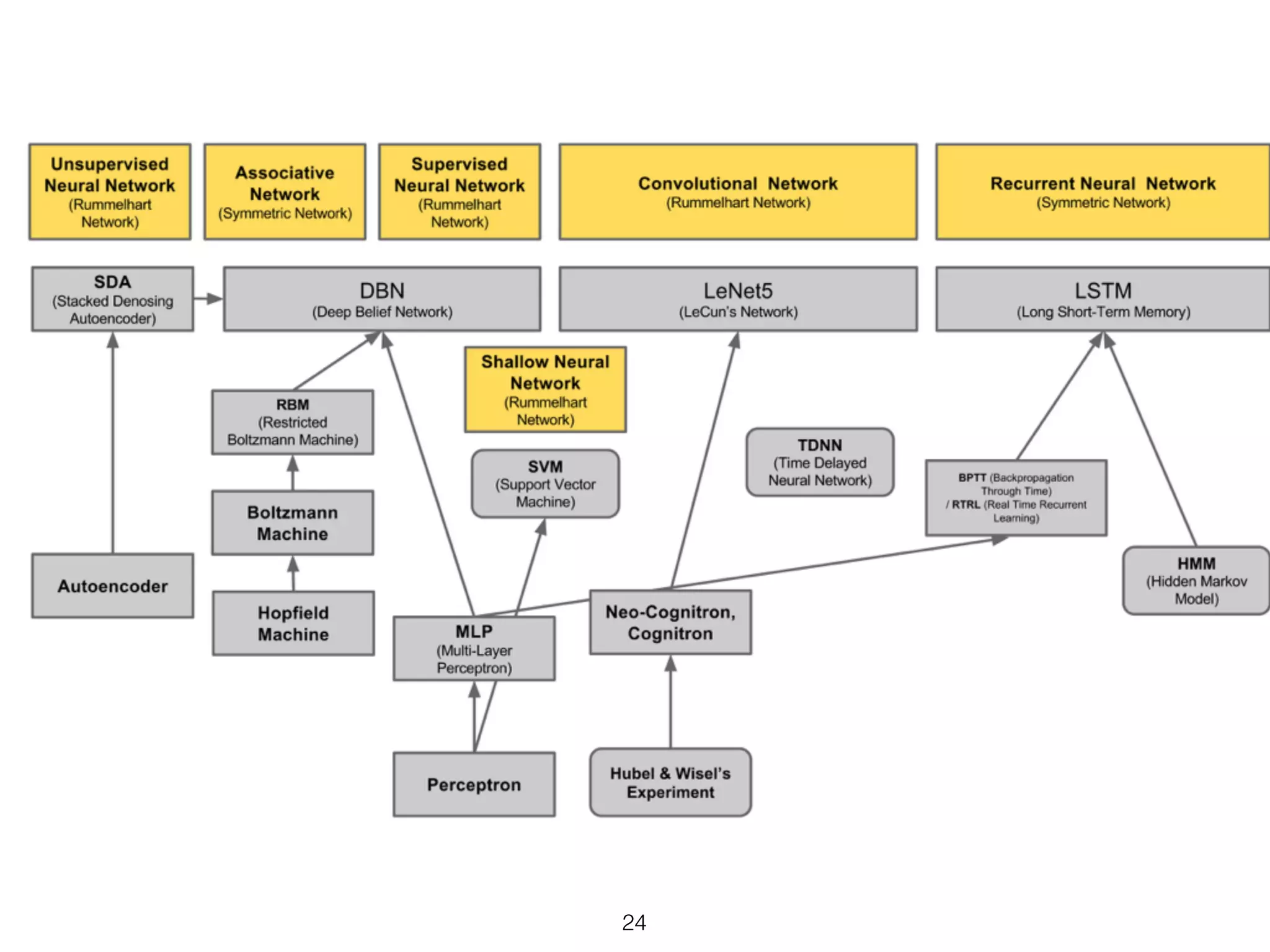
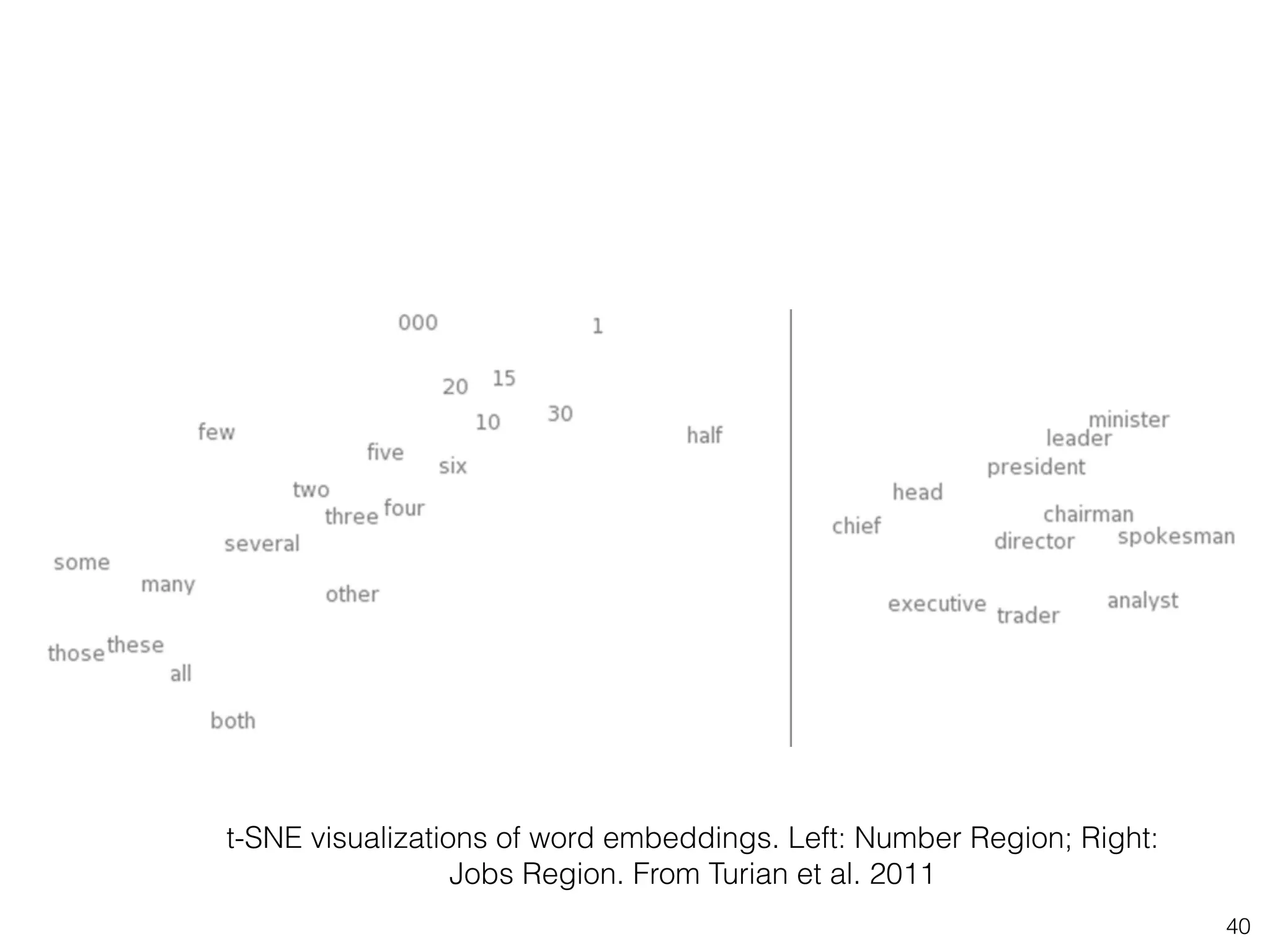
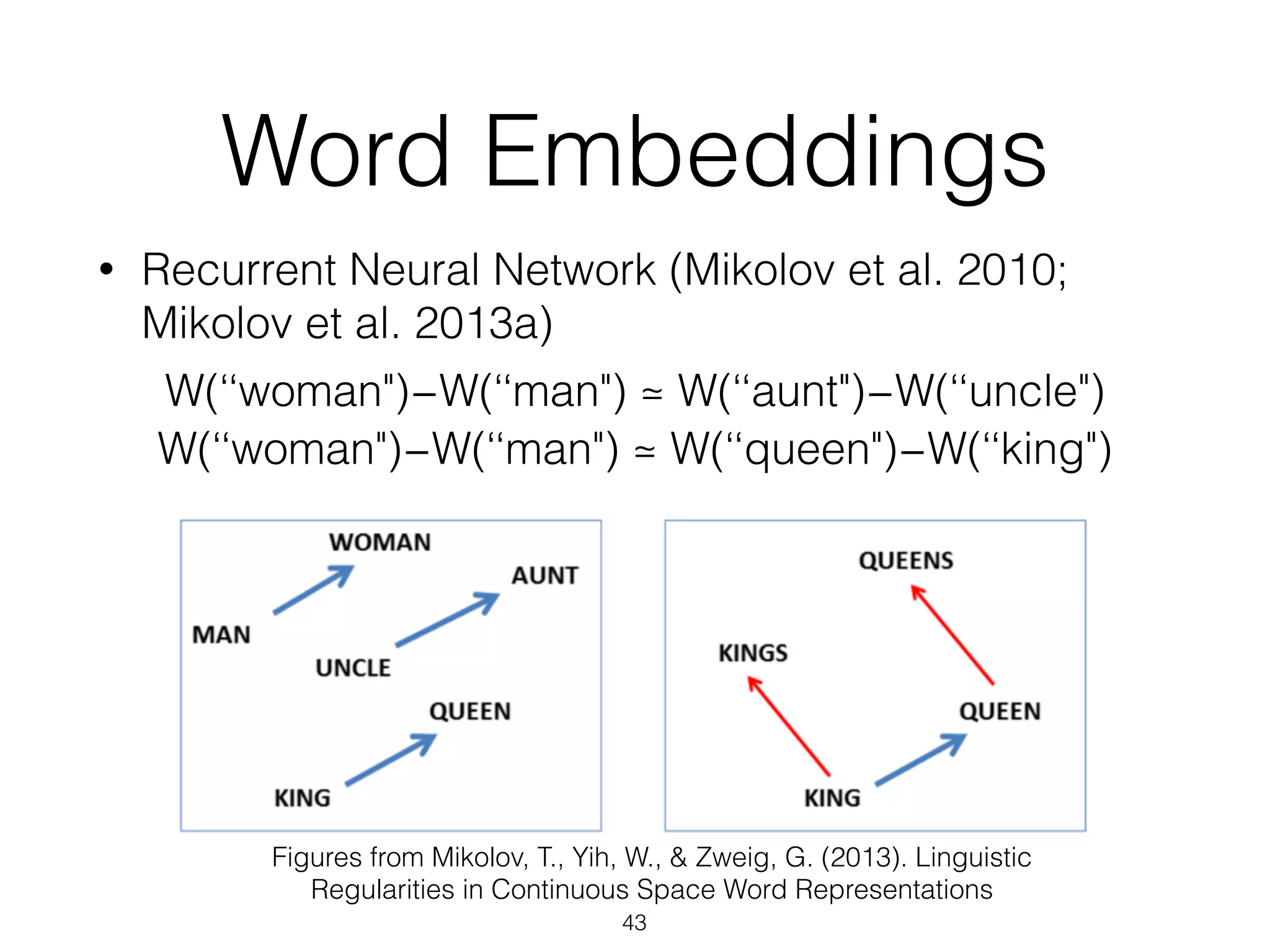
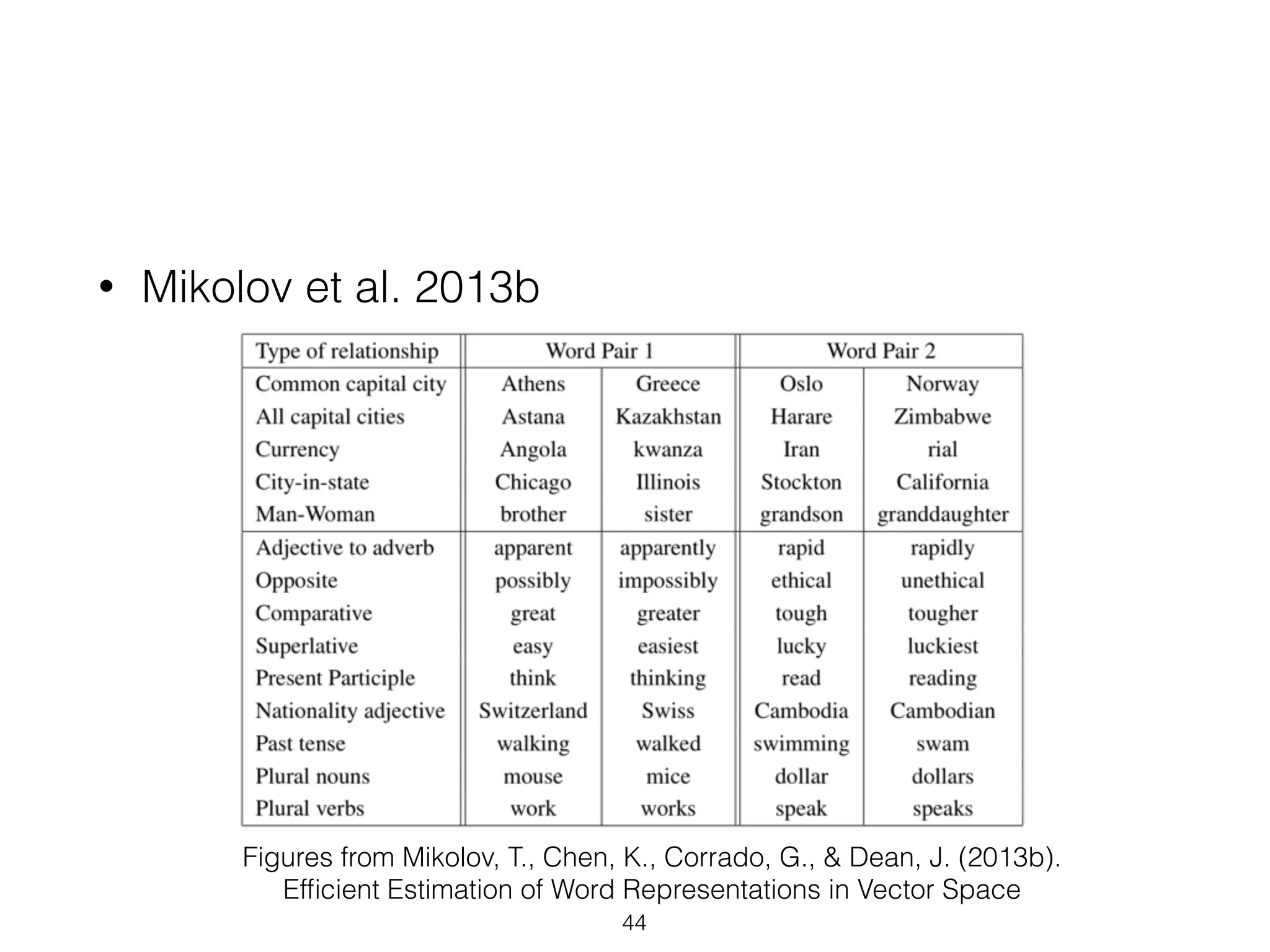
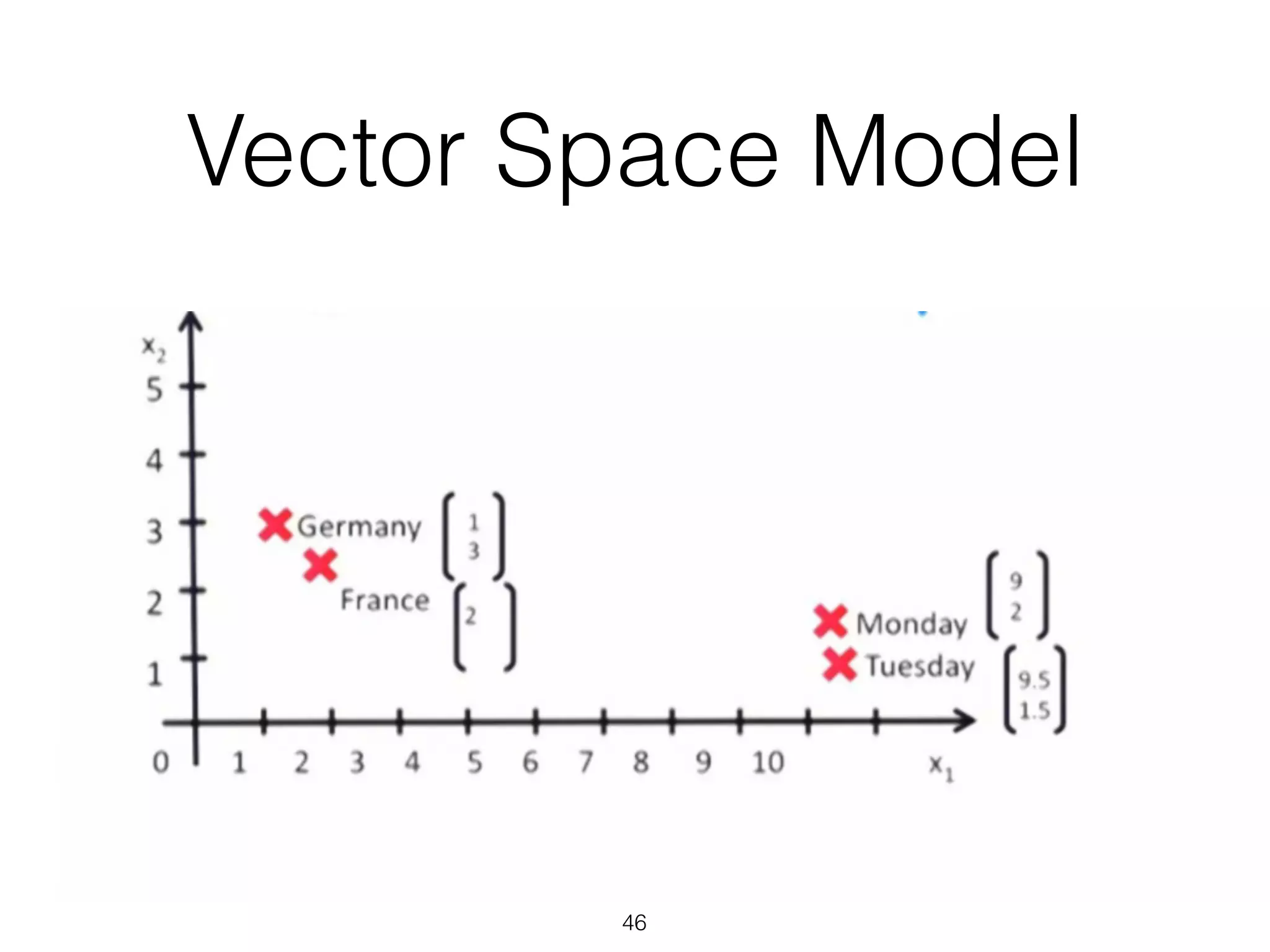
This document provides an overview of deep learning and natural language processing techniques. It begins with a history of machine learning and how deep learning advanced beyond early neural networks using methods like backpropagation. Deep learning methods like convolutional neural networks and word embeddings are discussed in the context of natural language processing tasks. Finally, the document proposes some graph-based approaches to combining deep learning with NLP, such as encoding language structures in graphs or using finite state graphs trained with genetic algorithms.








































































































