Download as PDF, PPTX






![12
Step 1: One-hot encoding
Example: letters. |V| = 30
‘a’: xT
= [1,0,0, ..., 0]
‘b’: xT
= [0,1,0, ..., 0]
‘c’: xT
= [0,0,1, ..., 0]
.
.
.
‘.’: xT
= [0,0,0, ..., 1]](https://image.slidesharecdn.com/dlmmdcud2l10neuralmachinetranslation-170429103826/75/Neural-Machine-Translation-D2L10-Insight-DCU-Machine-Learning-Workshop-2017-12-2048.jpg)
![13
Step 1: One-hot encoding
Example: words.
cat: xT
= [1,0,0, ..., 0]
dog: xT
= [0,1,0, ..., 0]
.
.
house: xT
= [0,0,0, …,0,1,0,...,0]
.
.
.
Number of words, |V| ?
B2: 5K
C2: 18K
LVSR: 50-100K
Wikipedia (1.6B): 400K
Crawl data (42B): 2M](https://image.slidesharecdn.com/dlmmdcud2l10neuralmachinetranslation-170429103826/75/Neural-Machine-Translation-D2L10-Insight-DCU-Machine-Learning-Workshop-2017-13-2048.jpg)

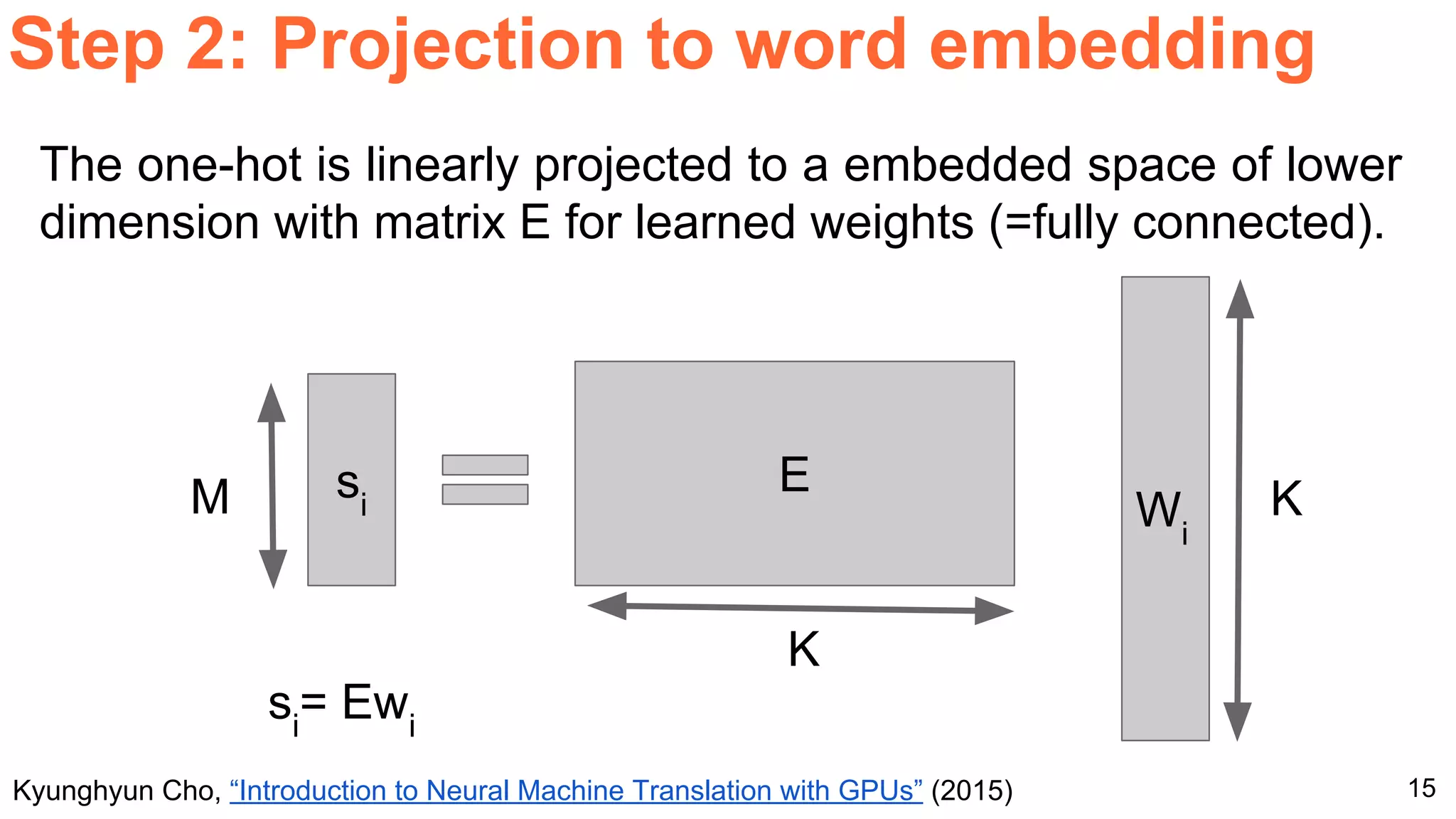
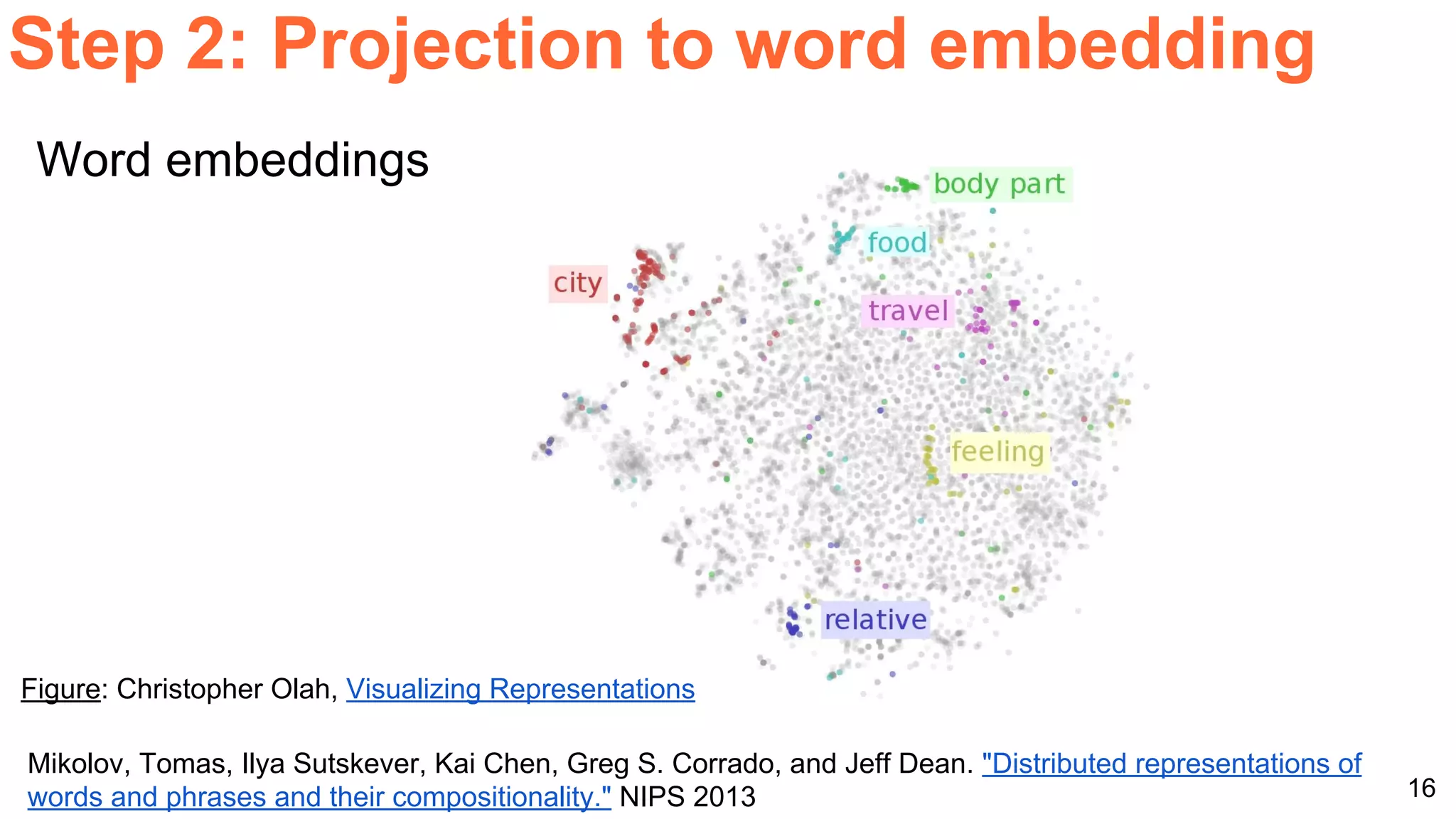
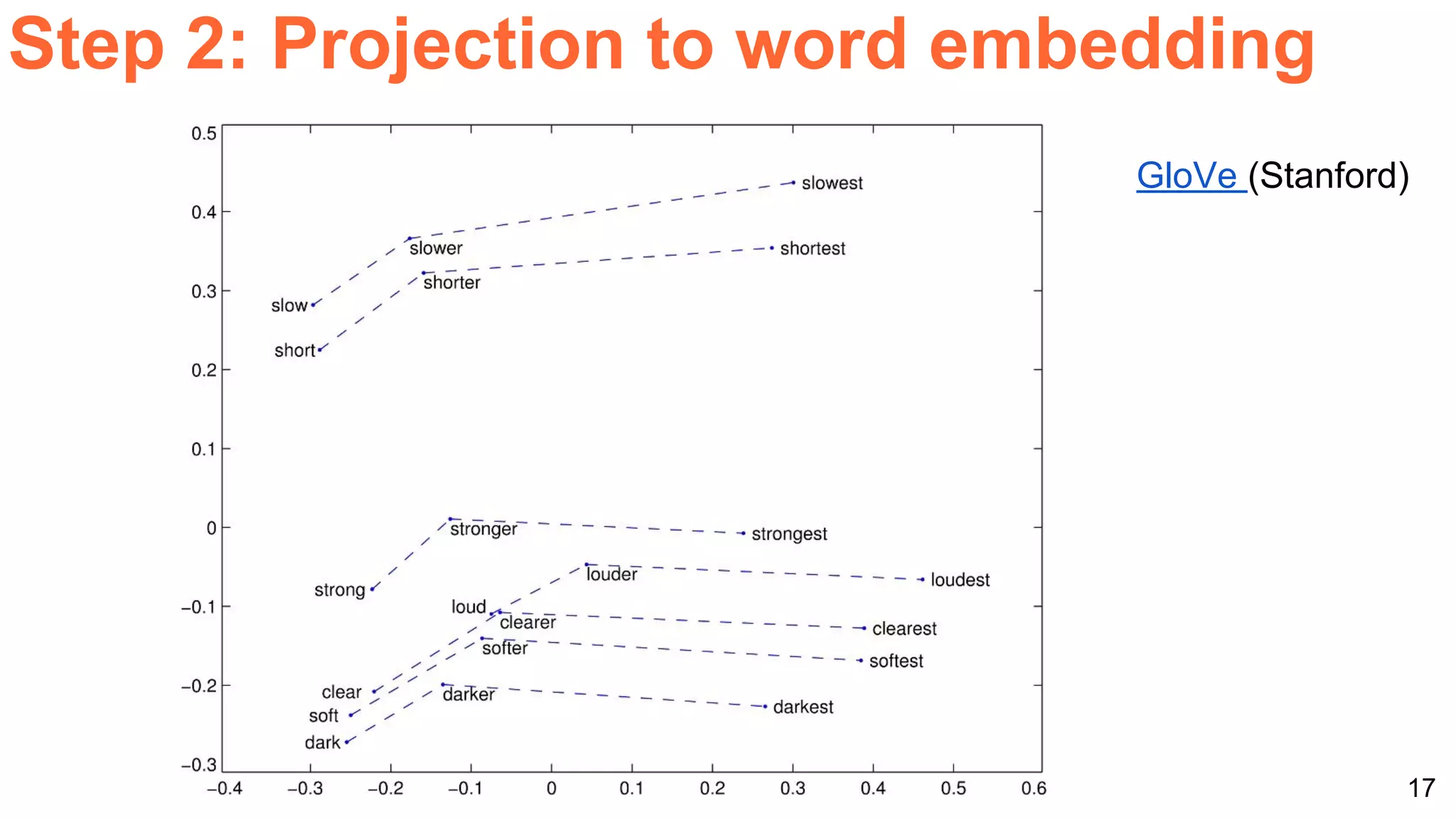
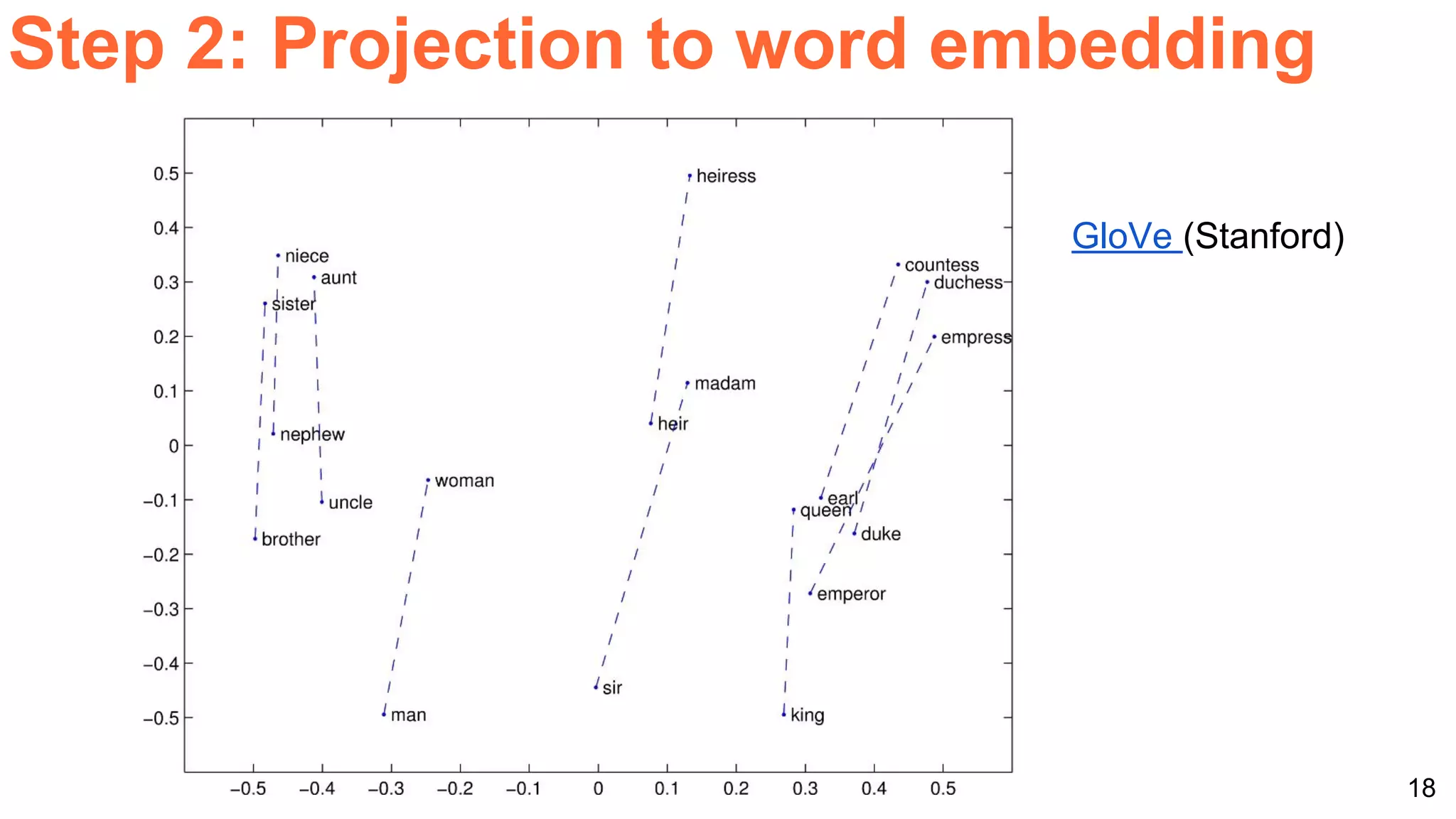
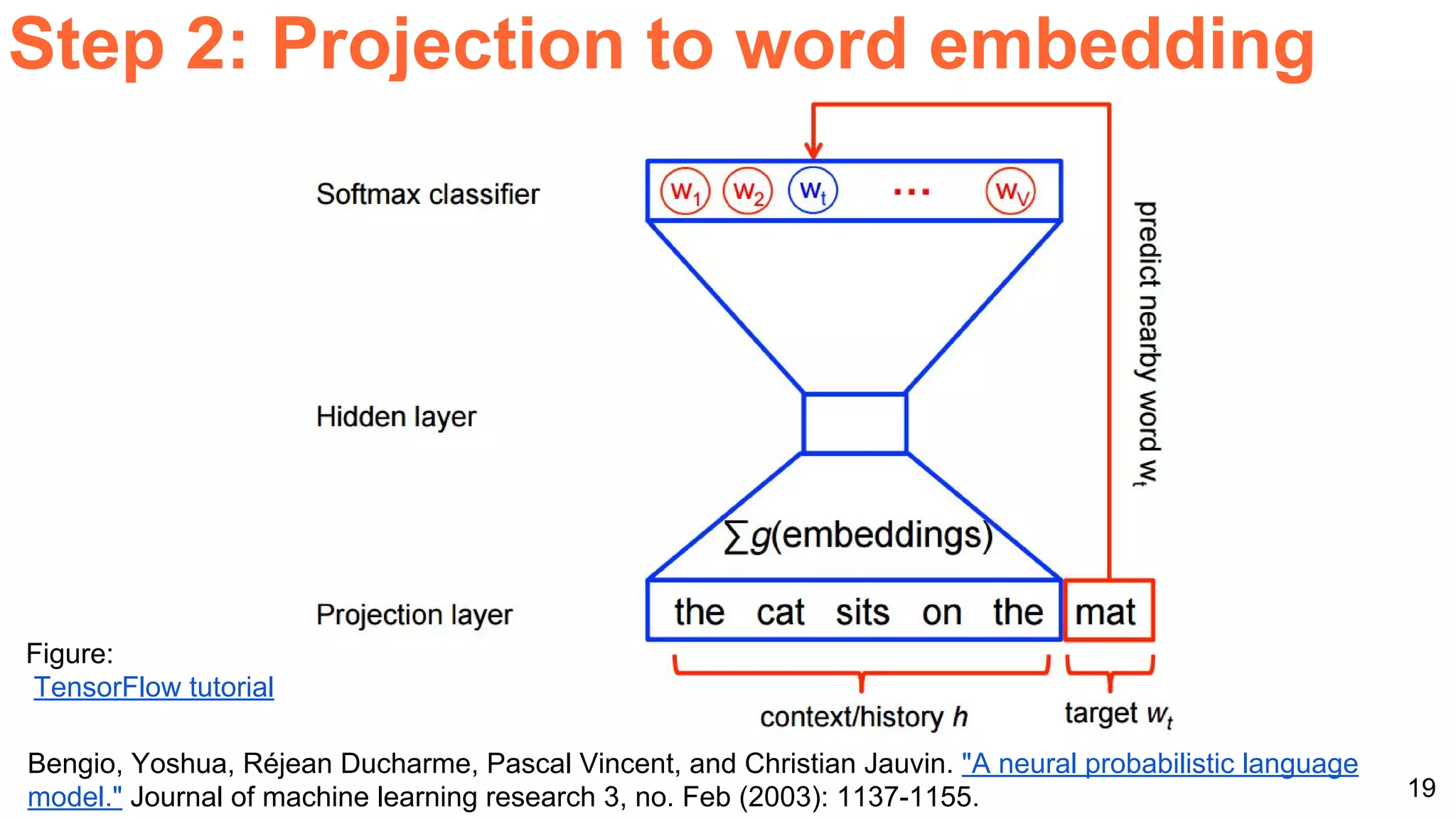
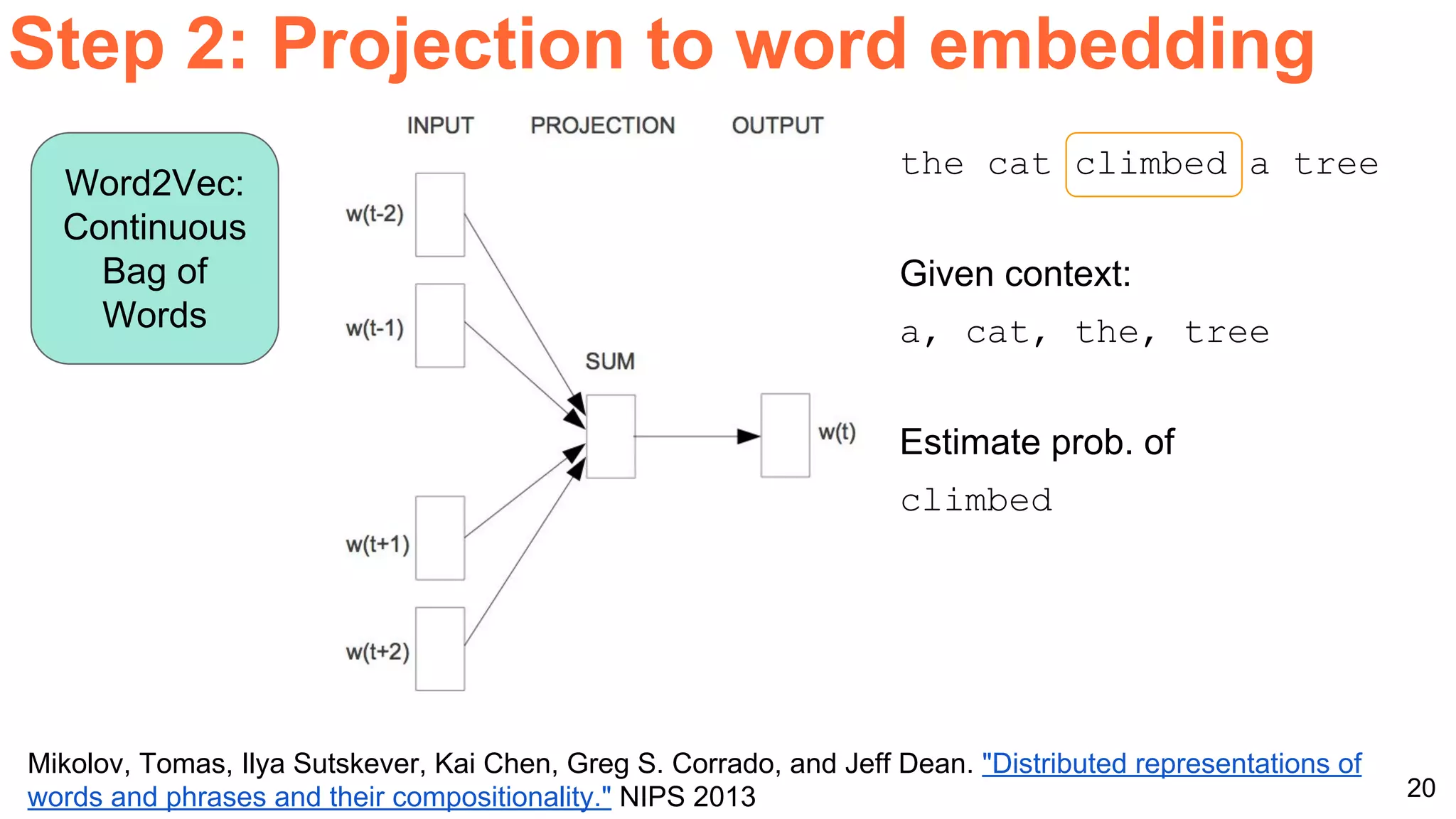
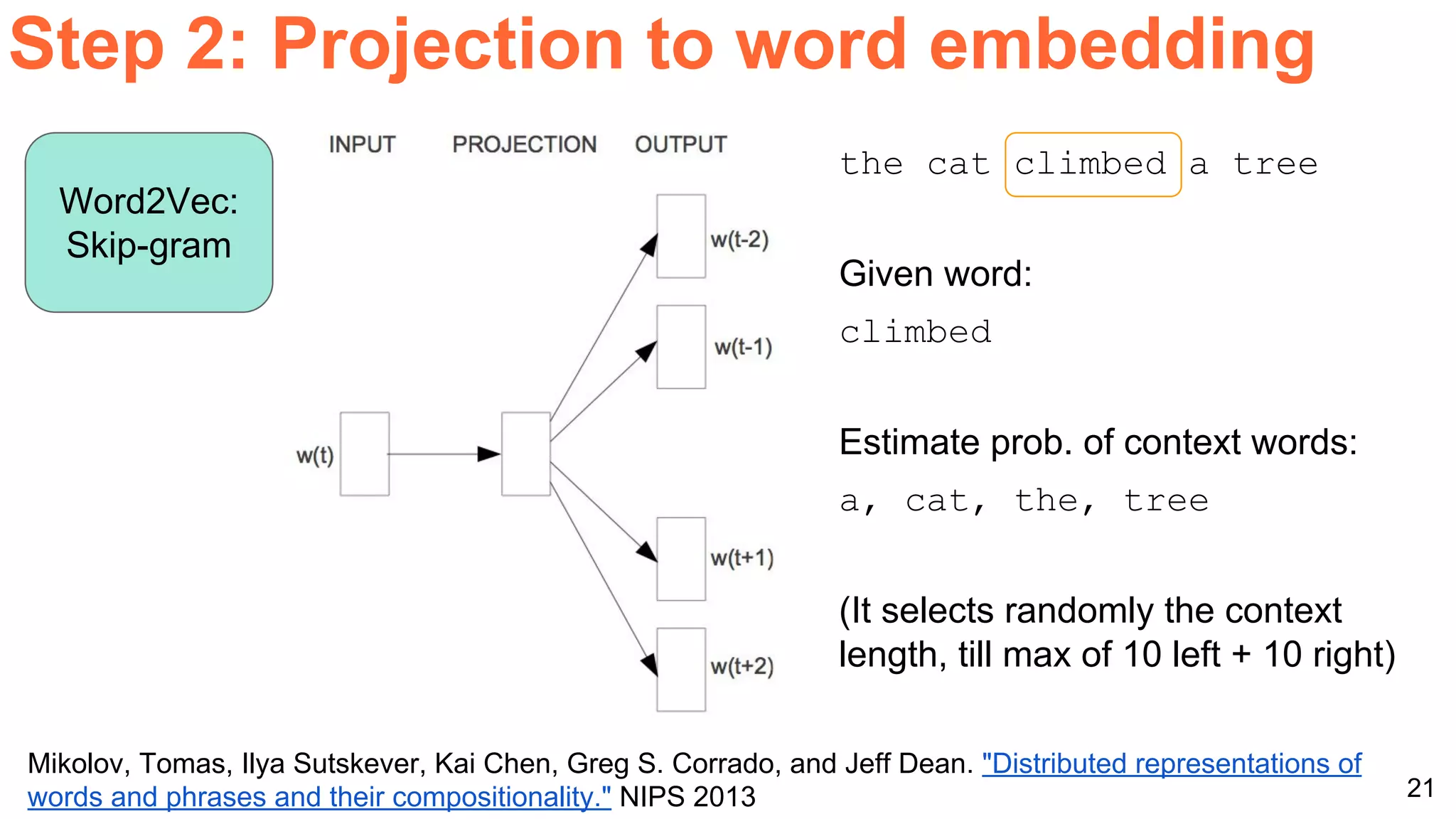


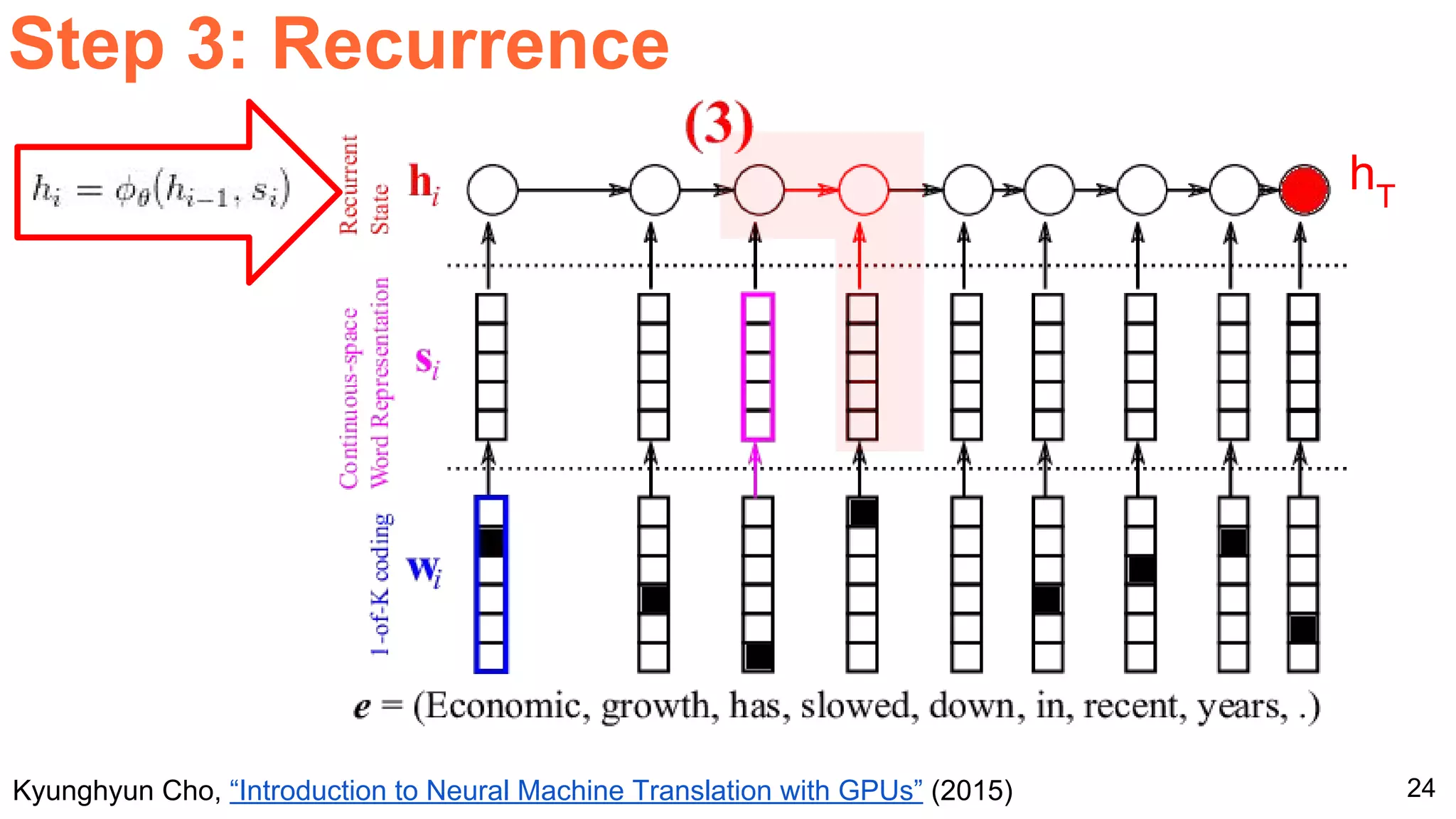
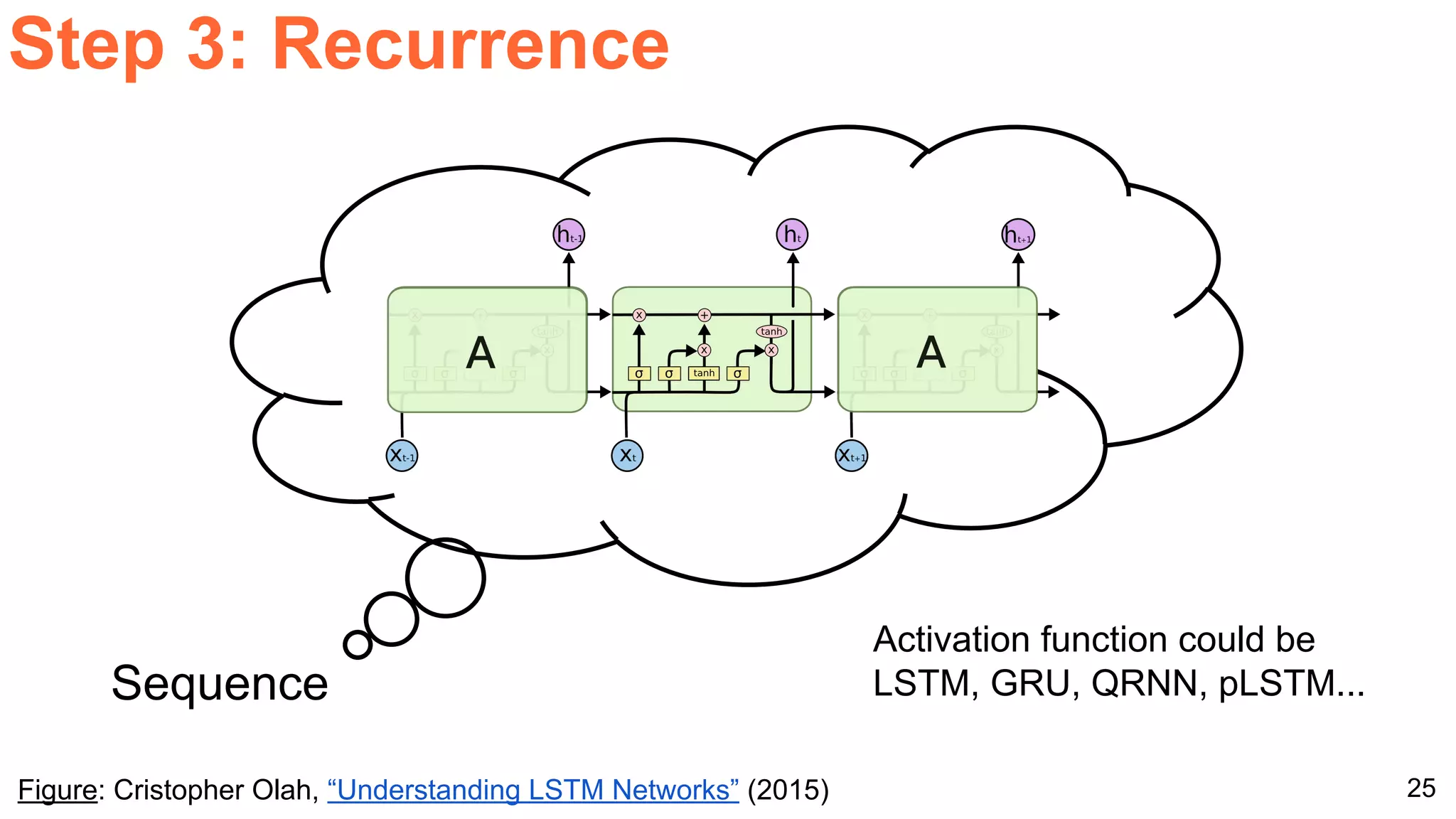

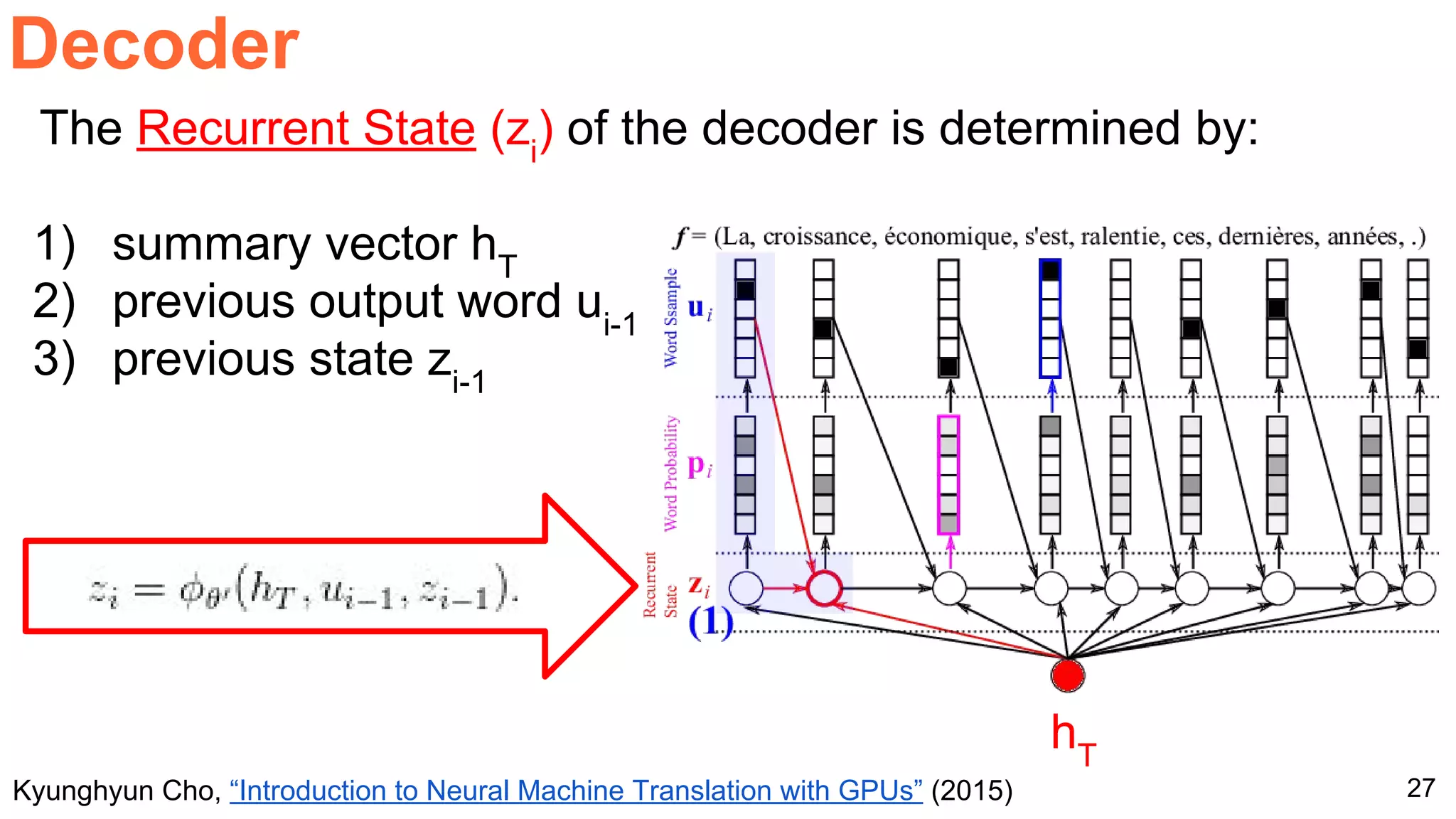
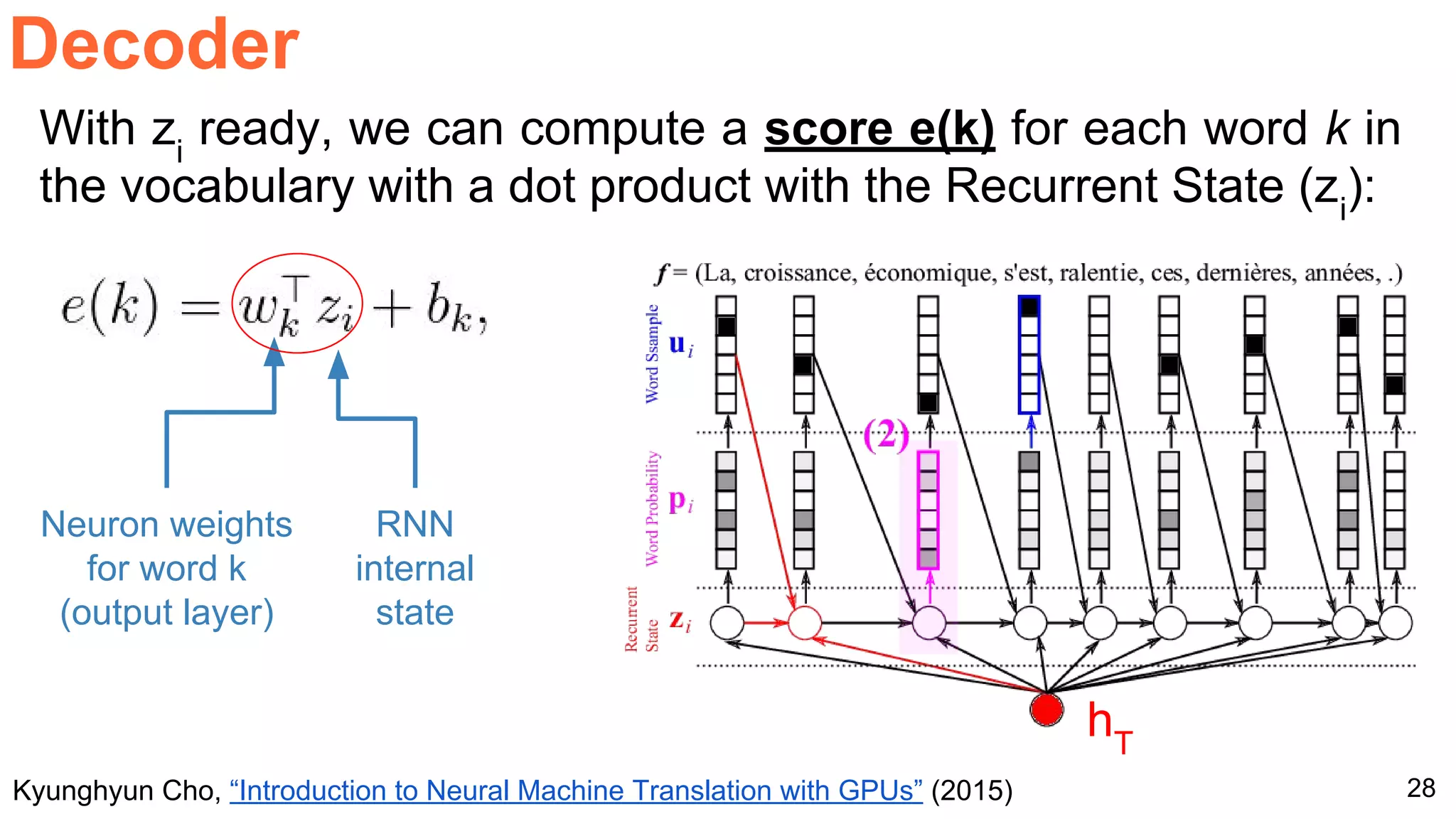




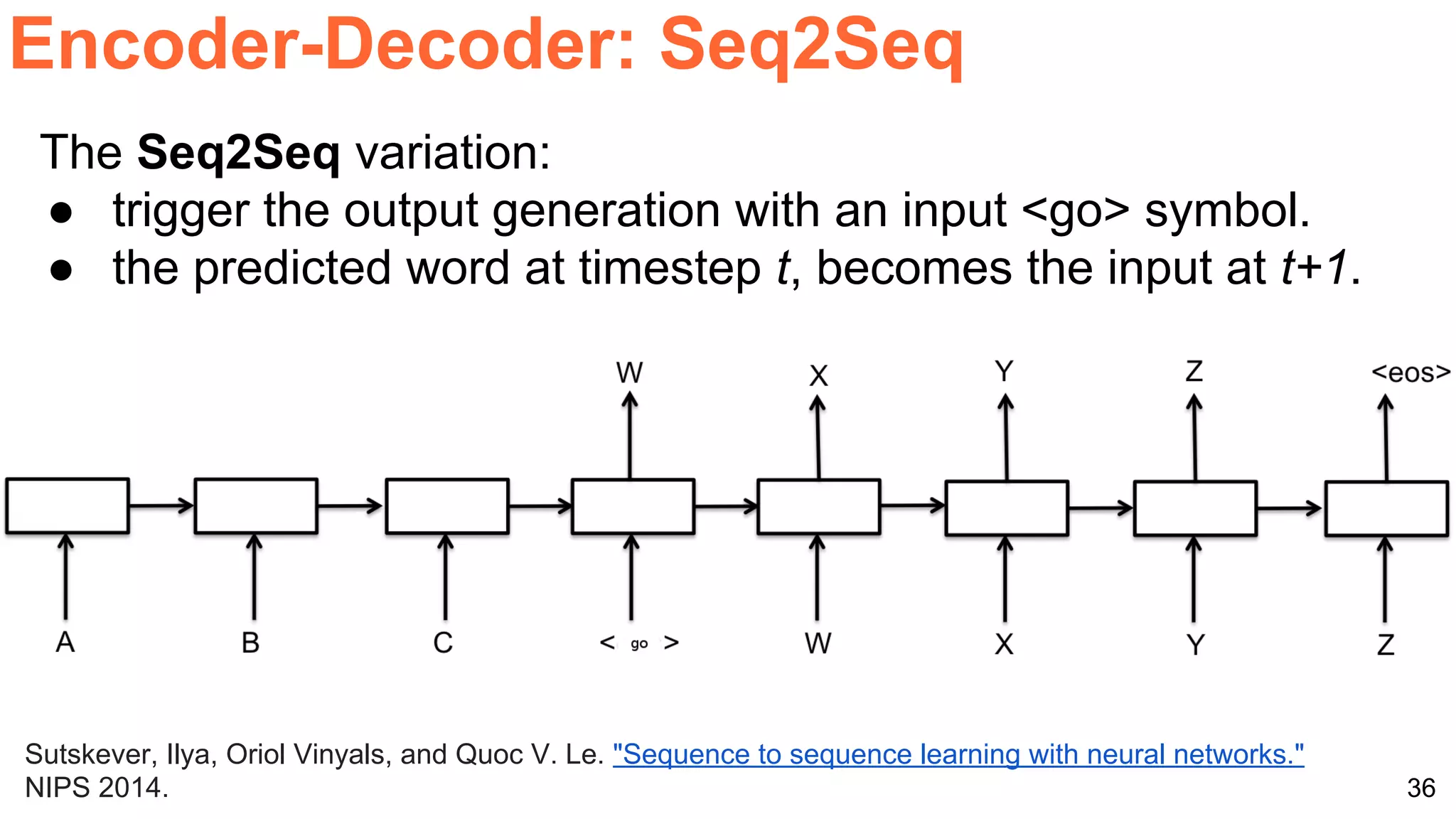



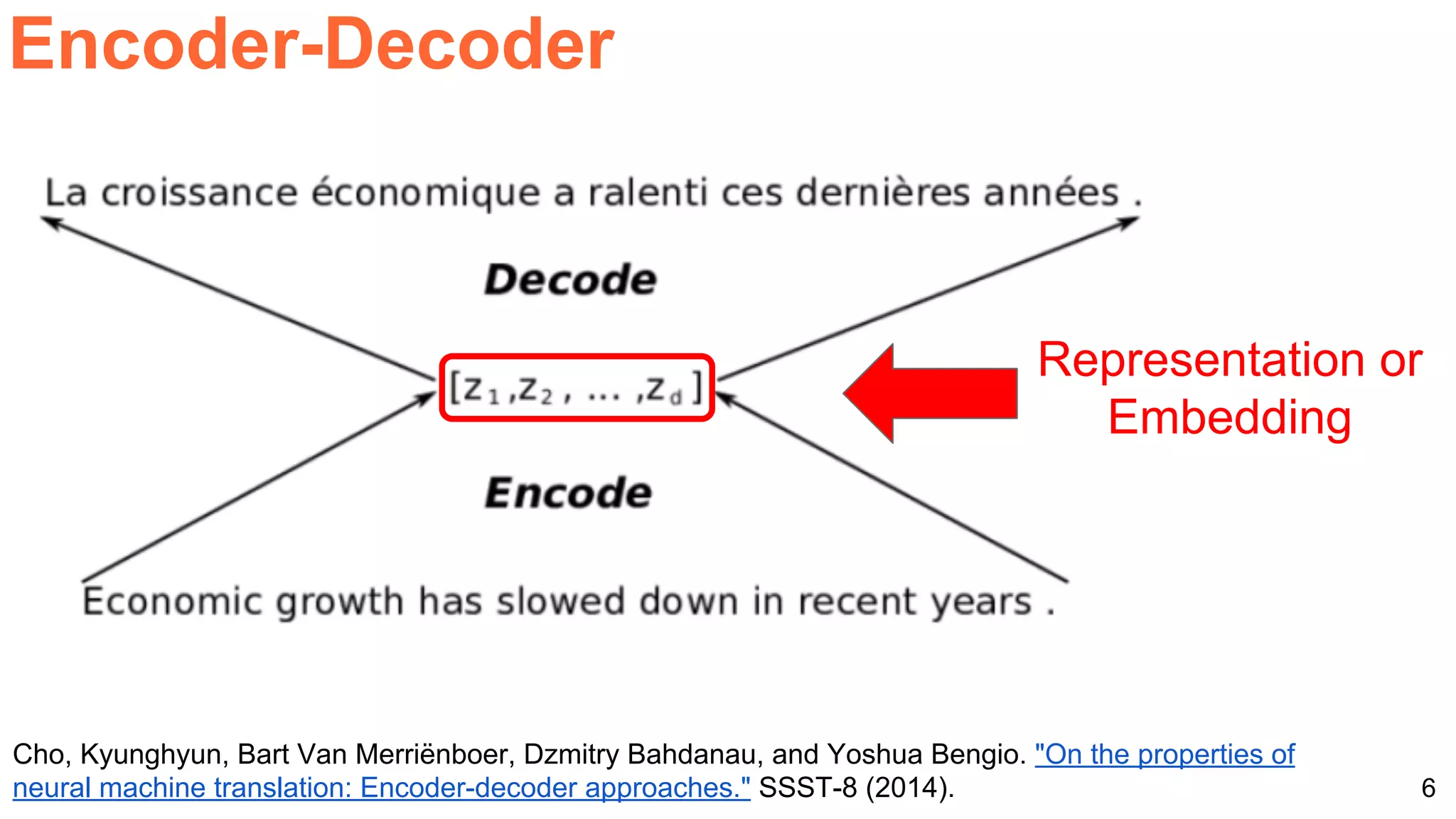
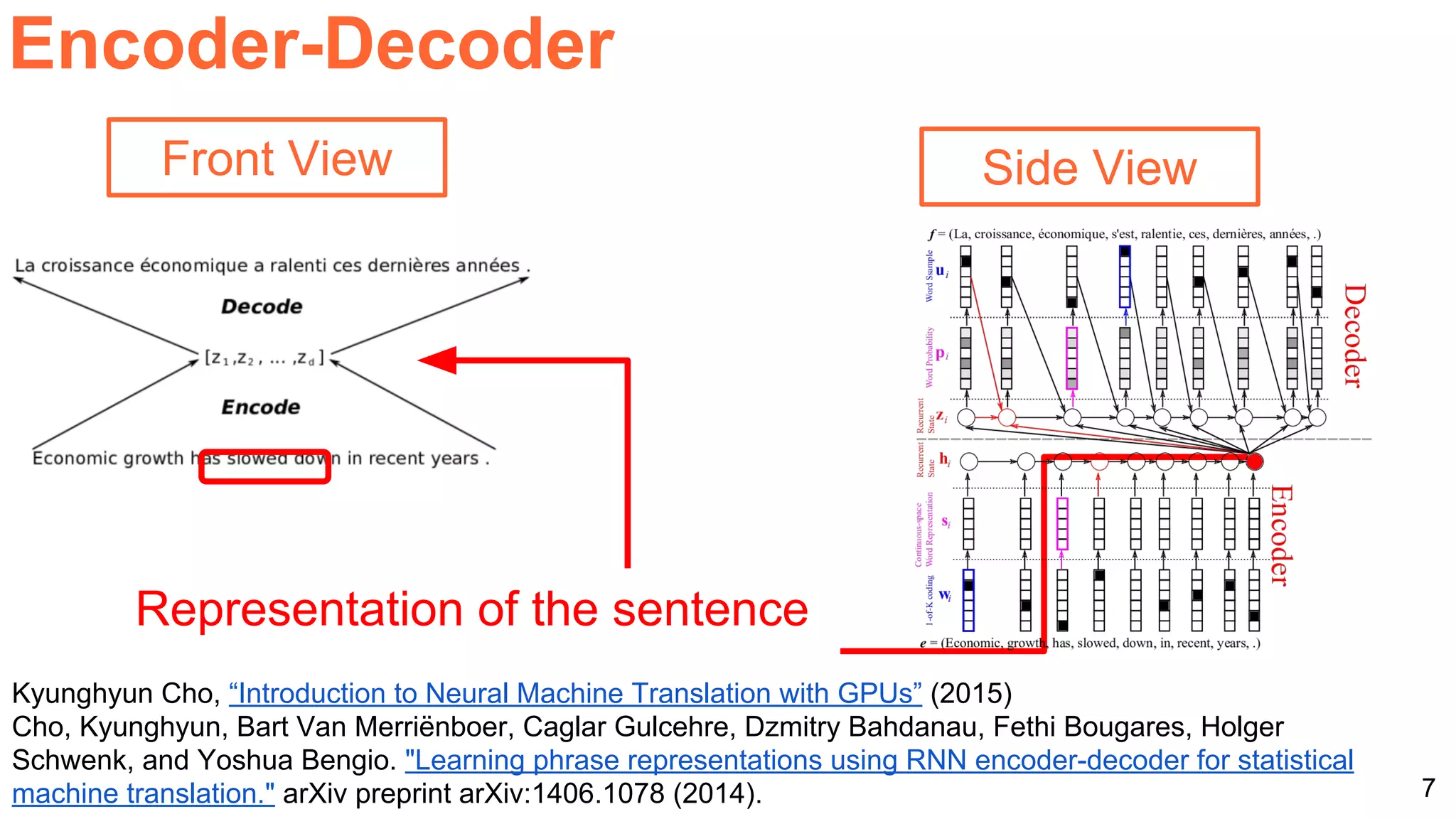
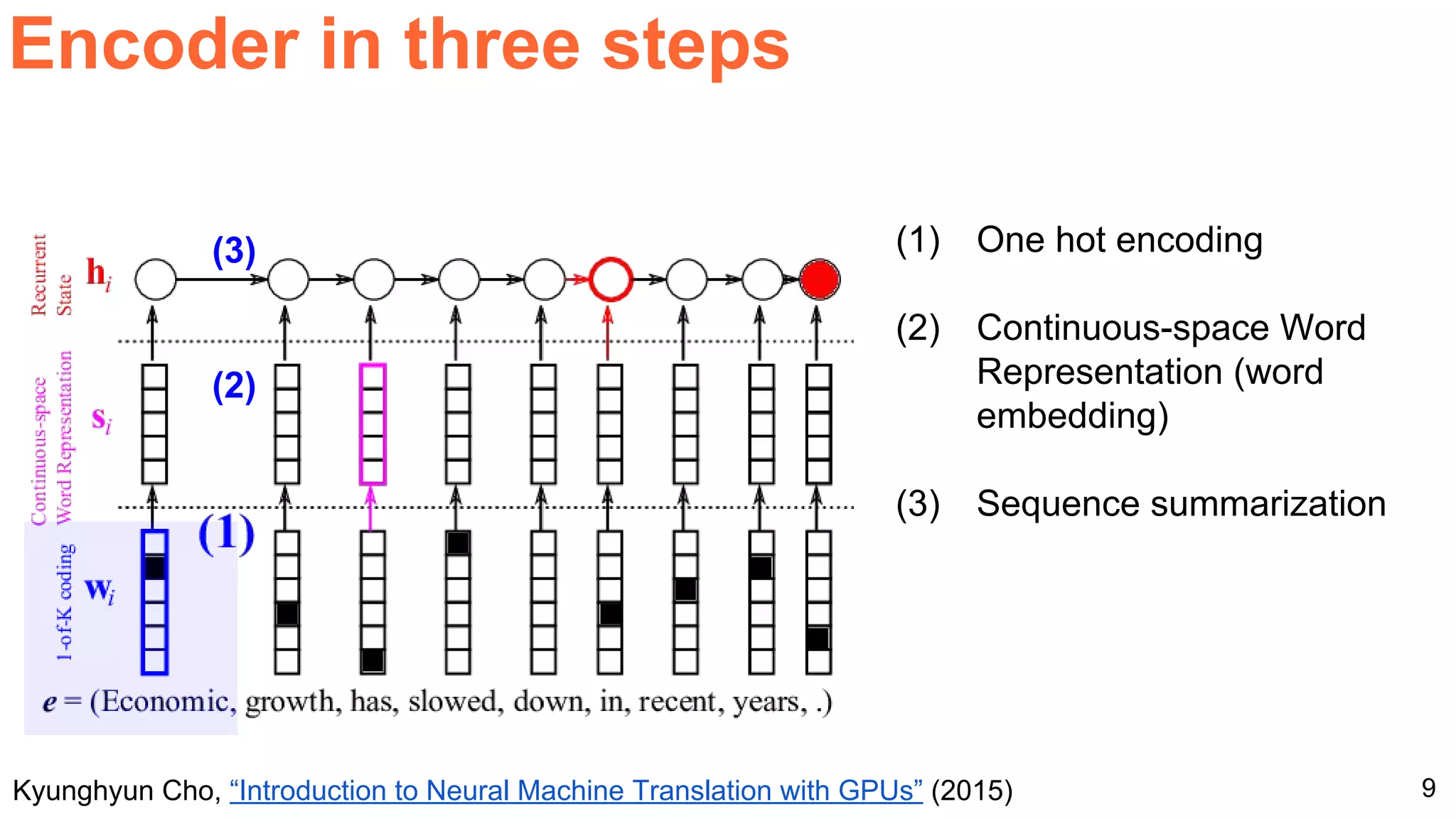
The document details a workshop presentation on neural machine translation at Dublin City University, focusing on the encoder-decoder model and its components. It discusses the stages of transforming input into output through one-hot encoding, word embeddings, and recurrent structures in neural networks. A sequence-to-sequence learning approach is emphasized, including the use of input triggers and how predicted outputs inform subsequent inputs.





































































![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



