Download as PDF, PPTX






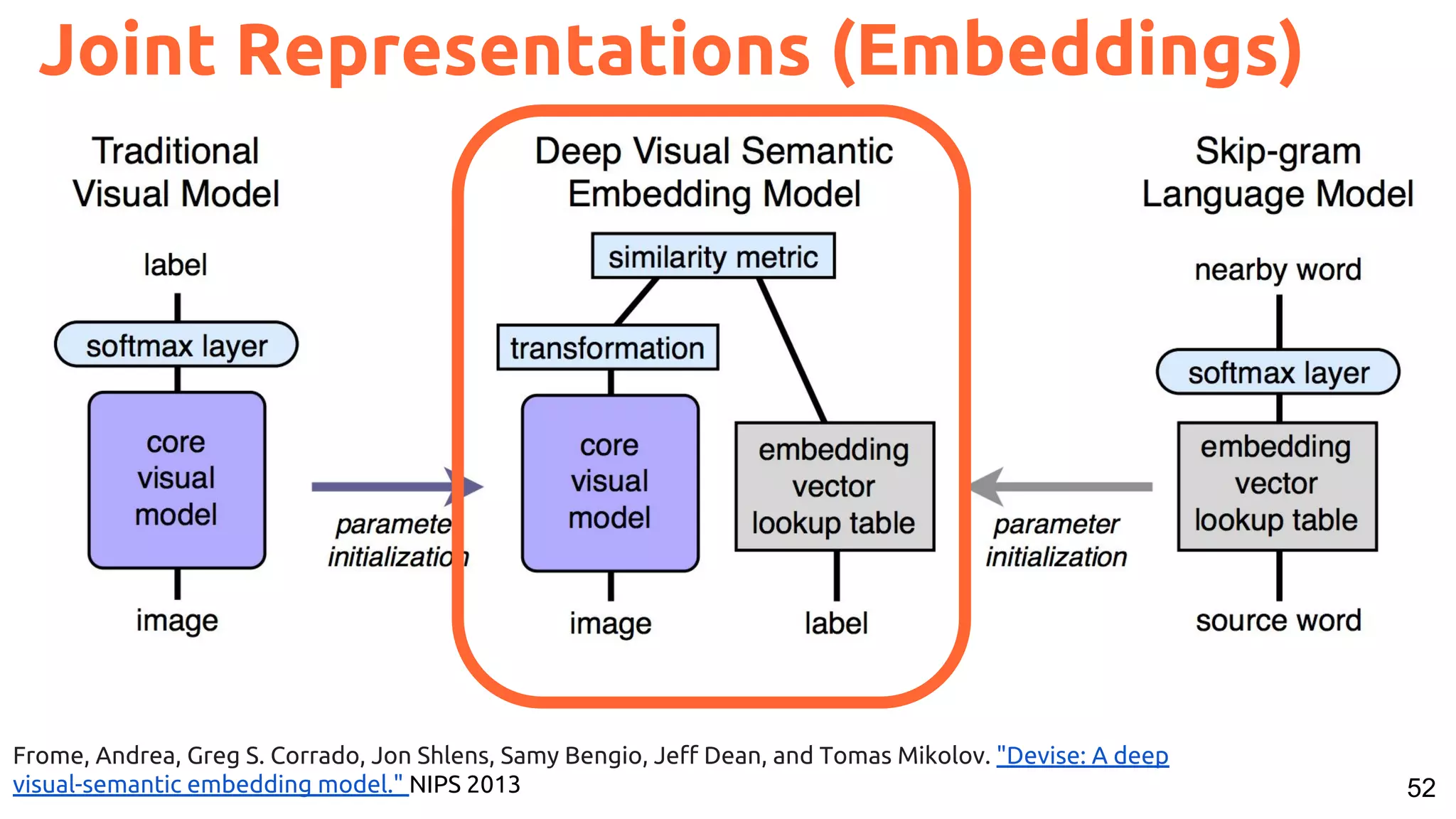
![11Slide concept: Perronin, F., Tutorial on LSVR @ CVPR’14, Output embedding for LSVR
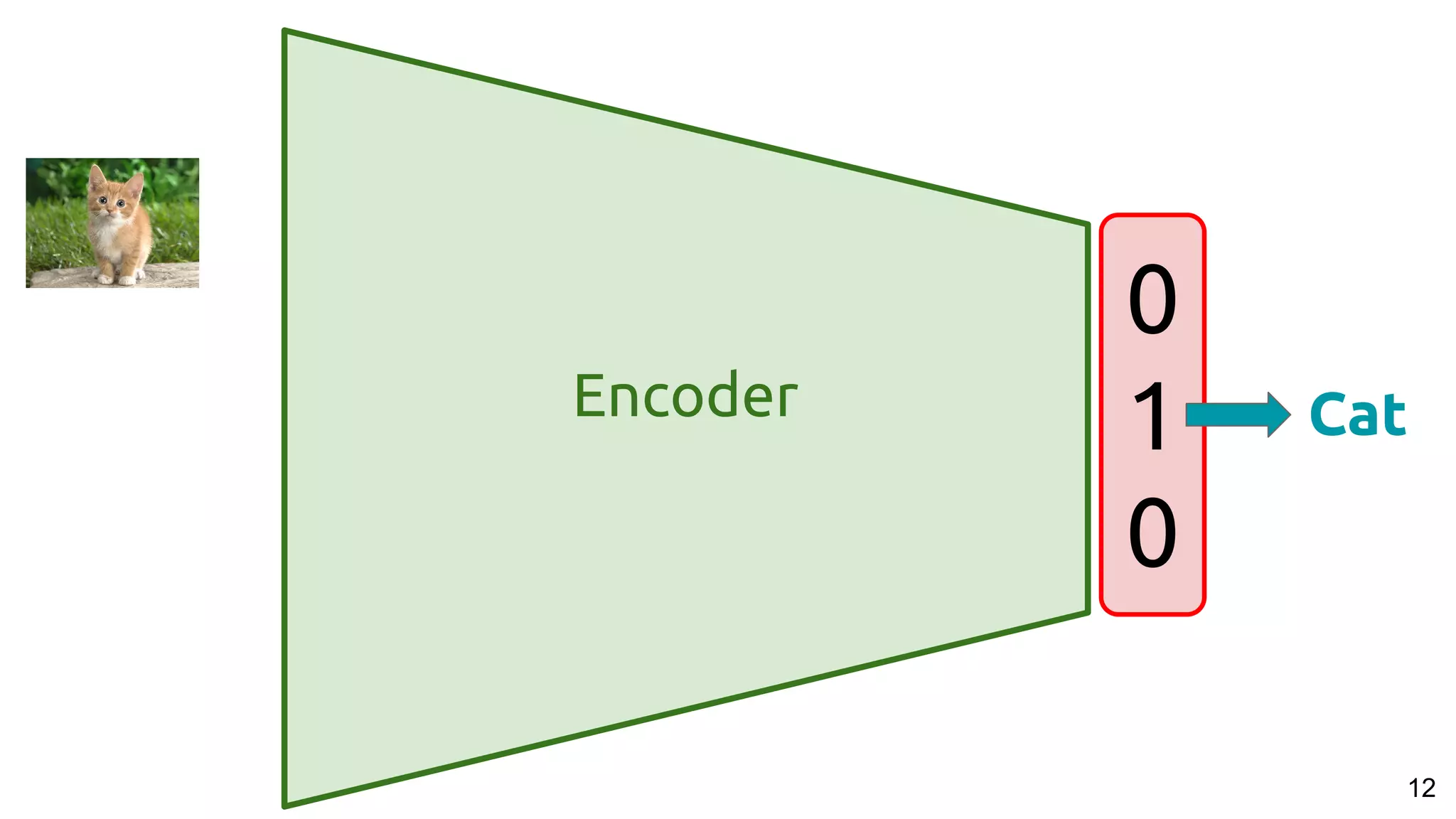
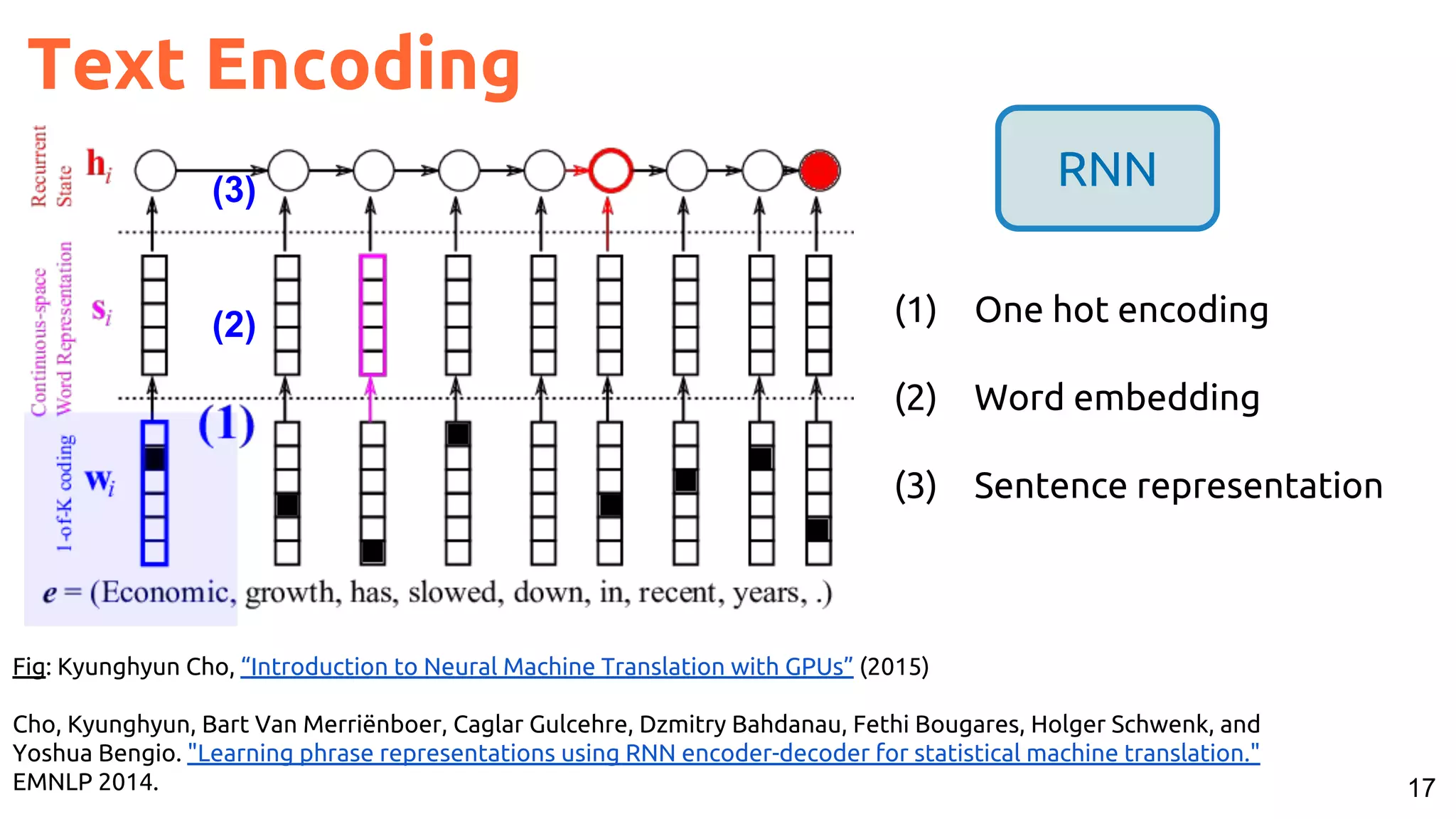
One-hot Representation (Embeddings)
[1,0,0]
[0,1,0]
[0,0,1]](https://image.slidesharecdn.com/a2ic2018oneperceptrontorulethemall1-181122151050/75/One-Perceptron-to-Rule-them-All-Deep-Learning-for-Multimedia-A2IC2018-11-2048.jpg)

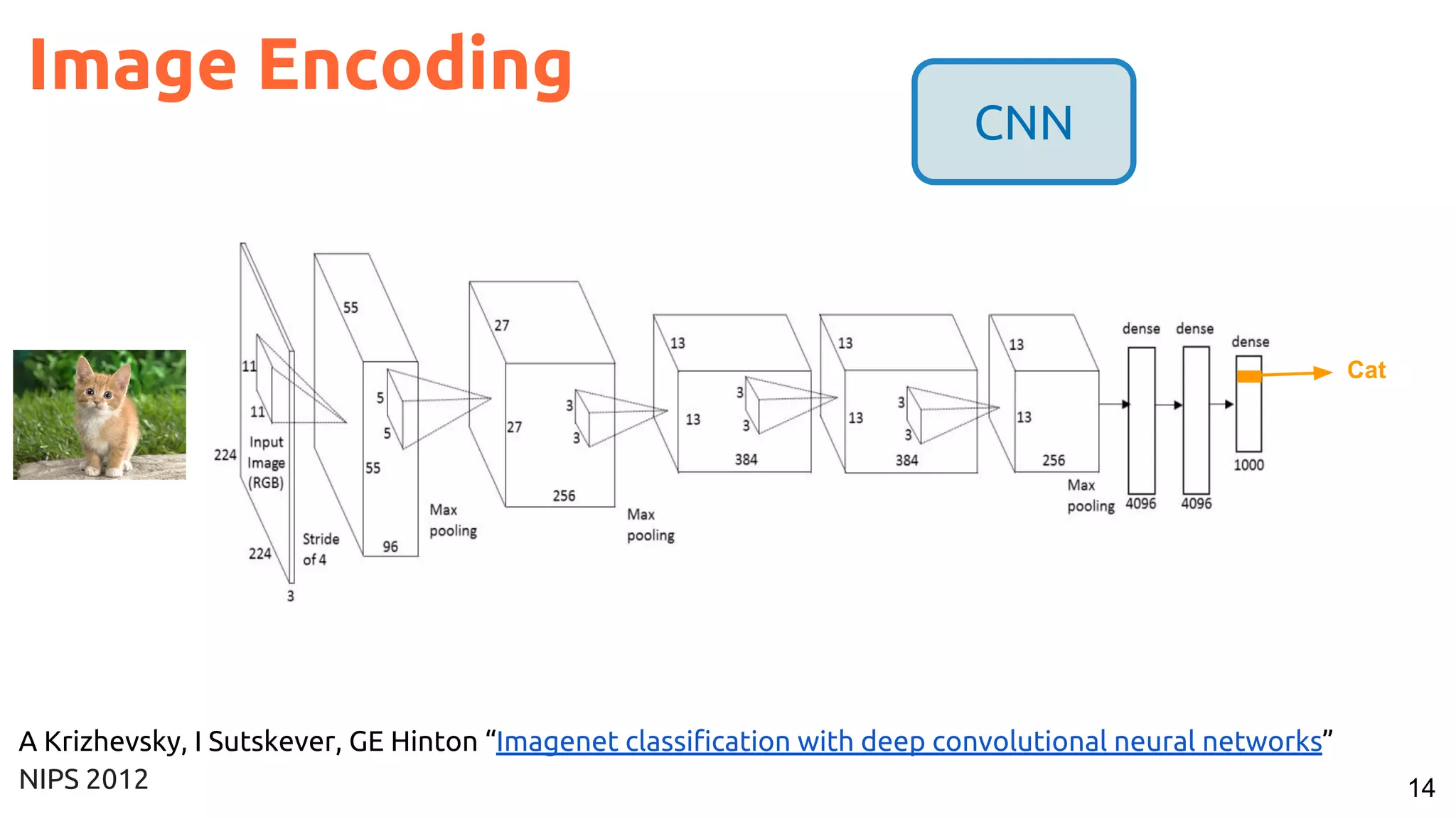
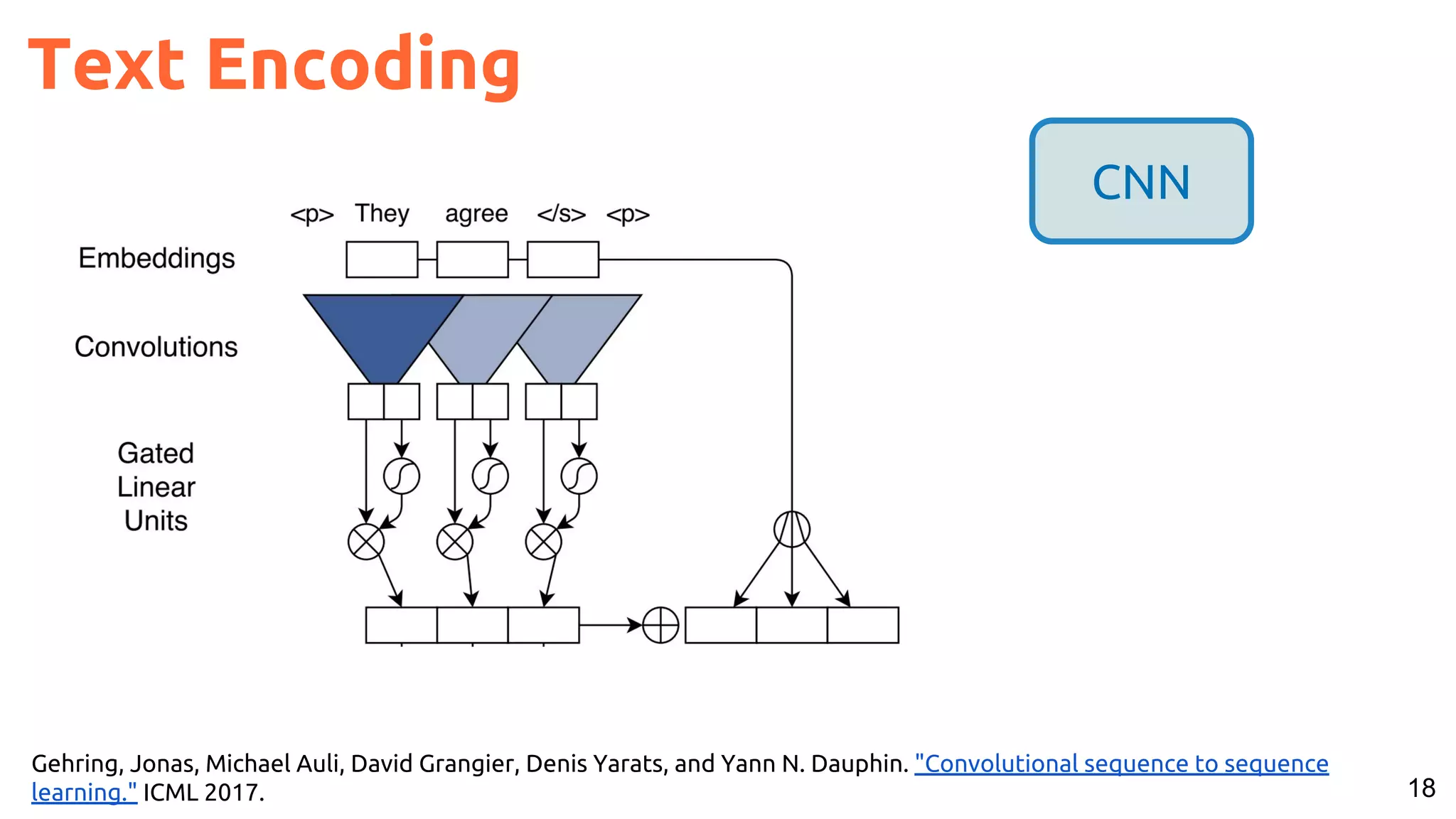
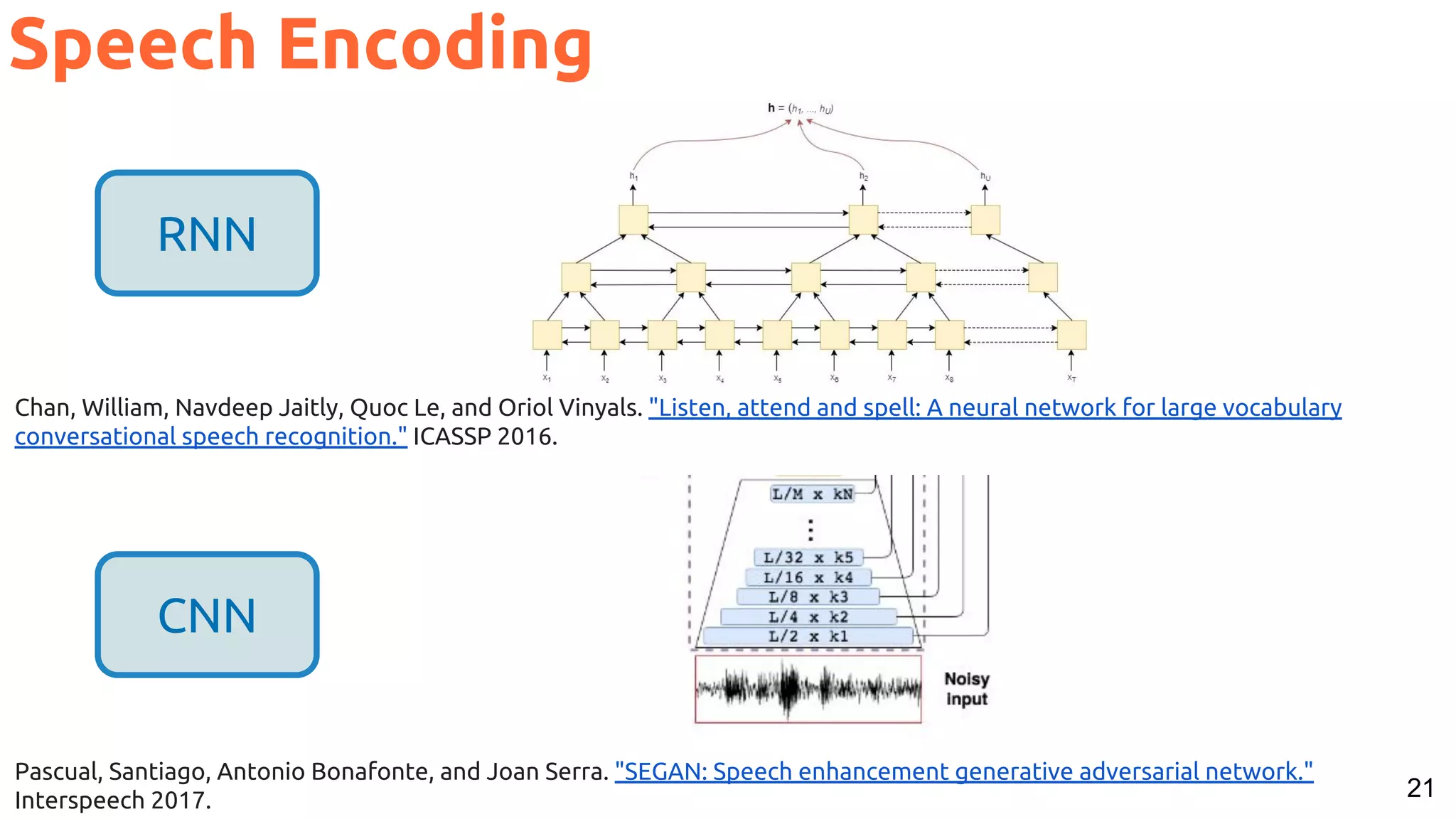
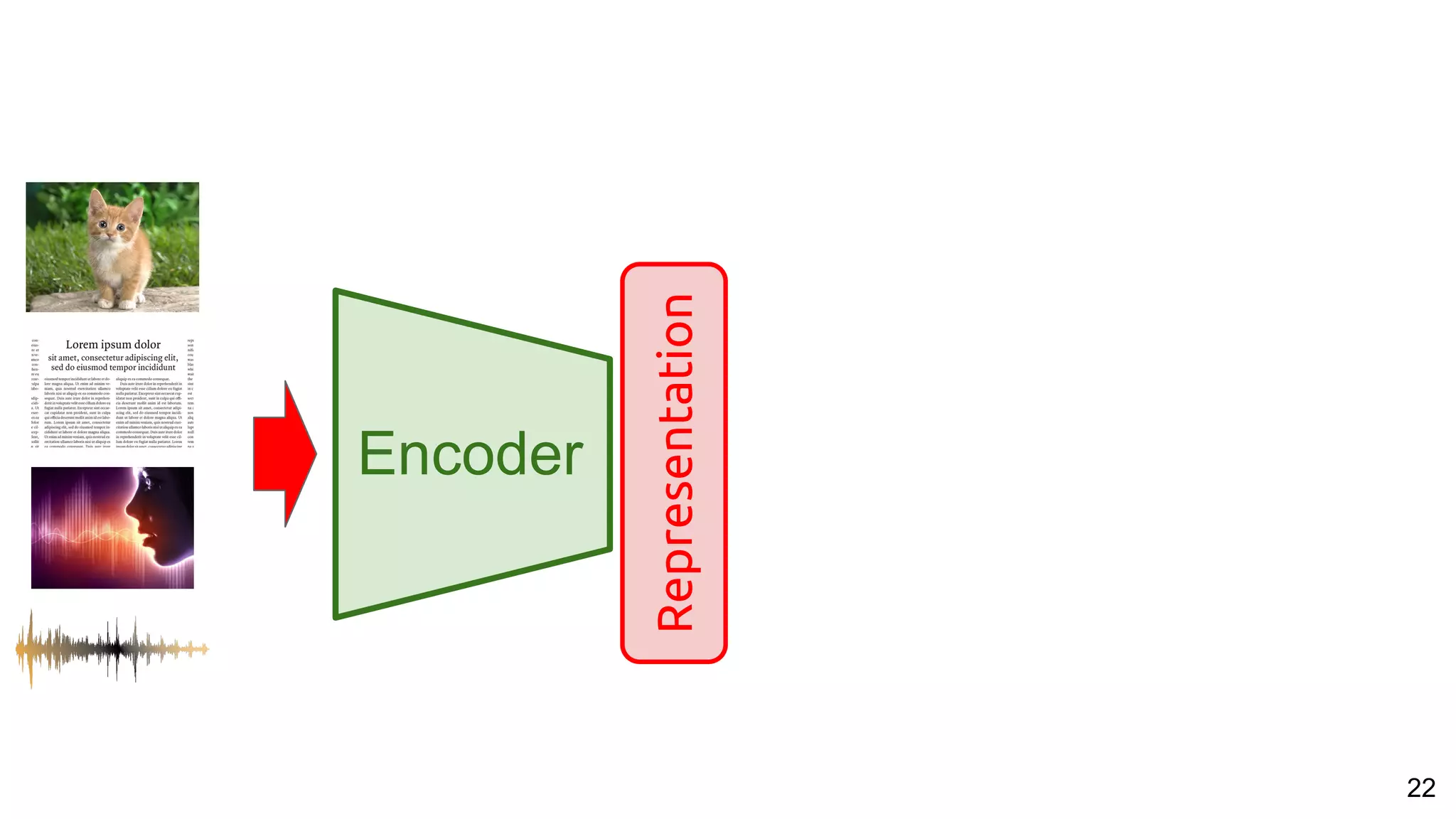
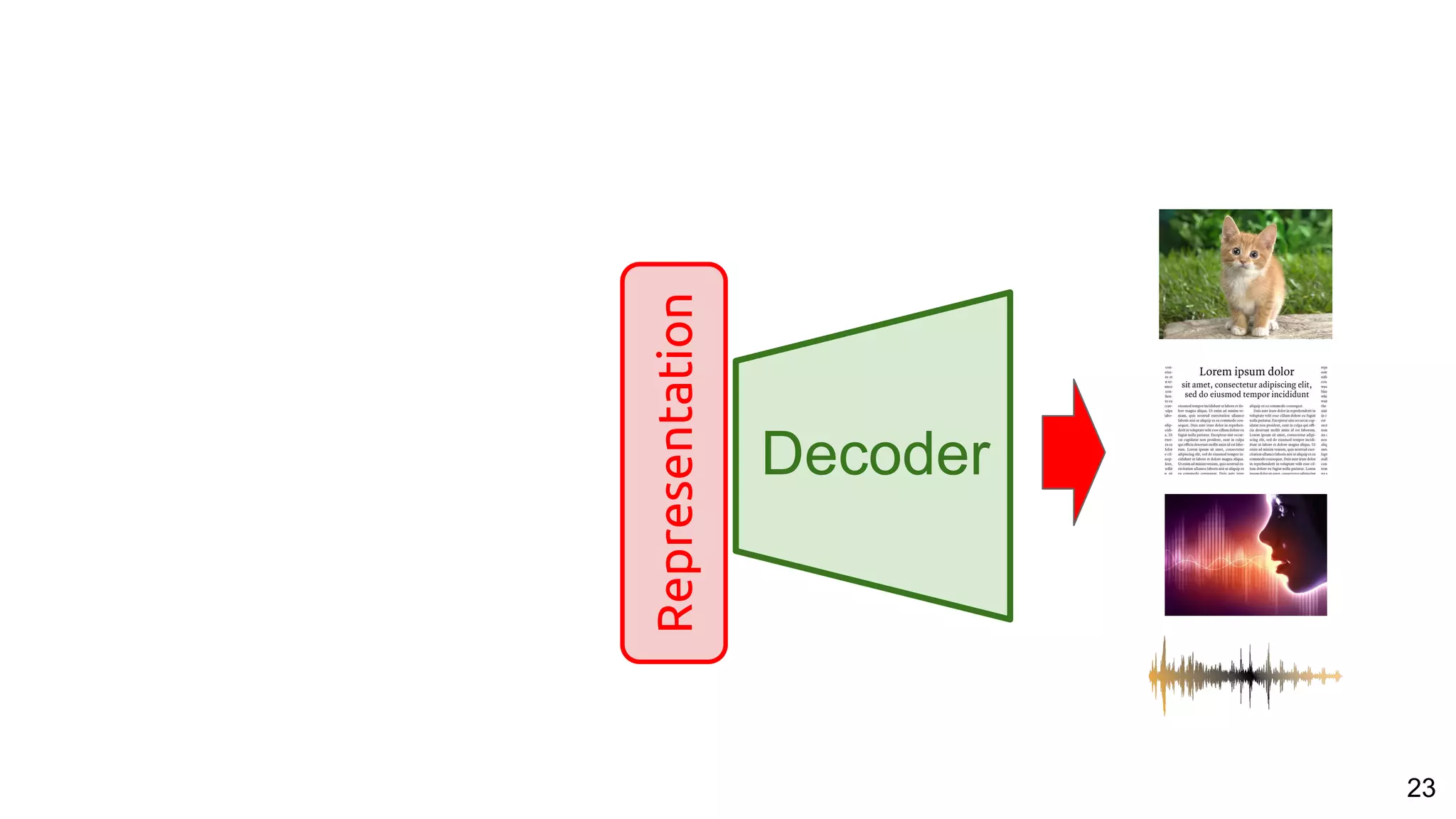
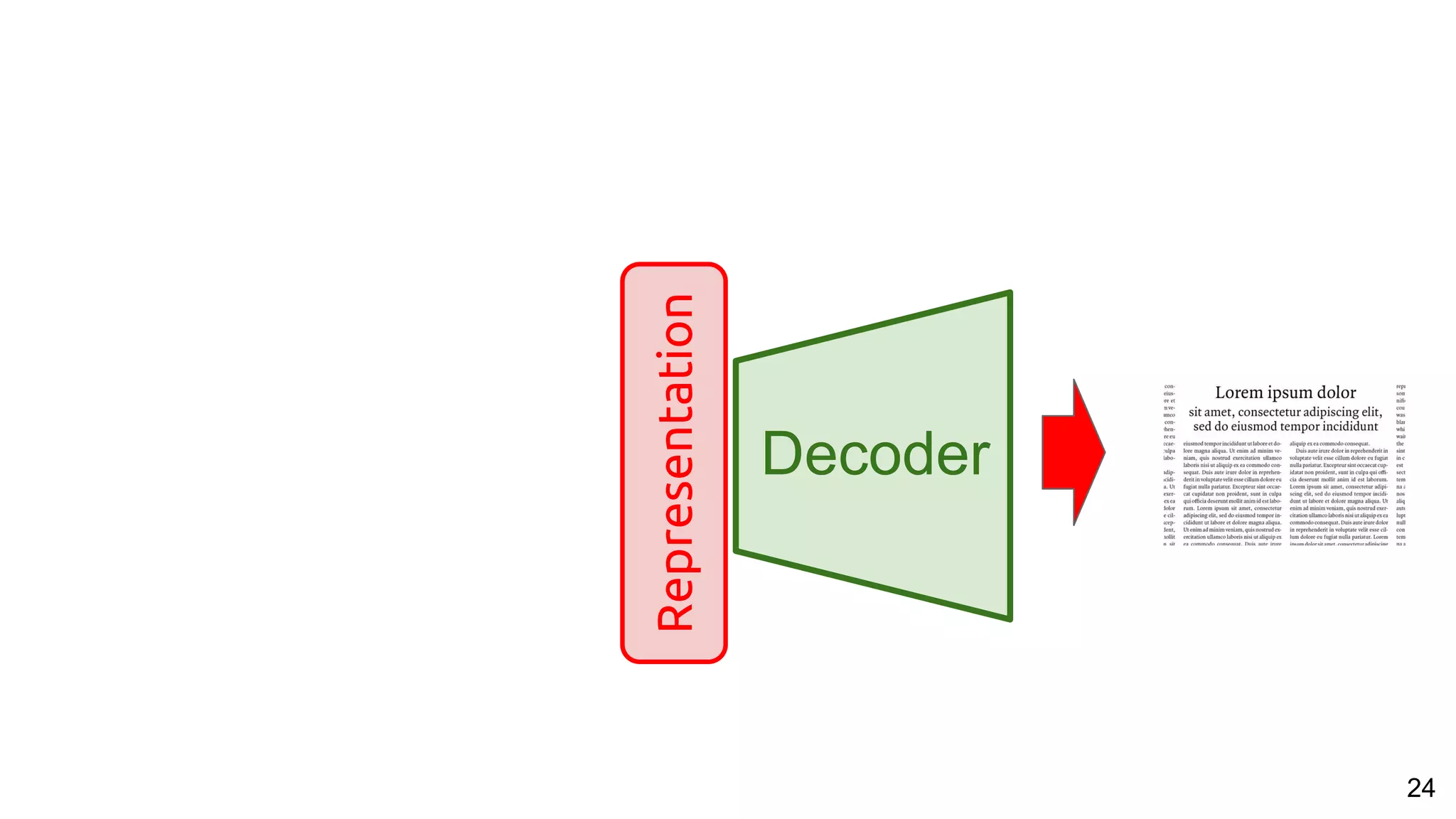
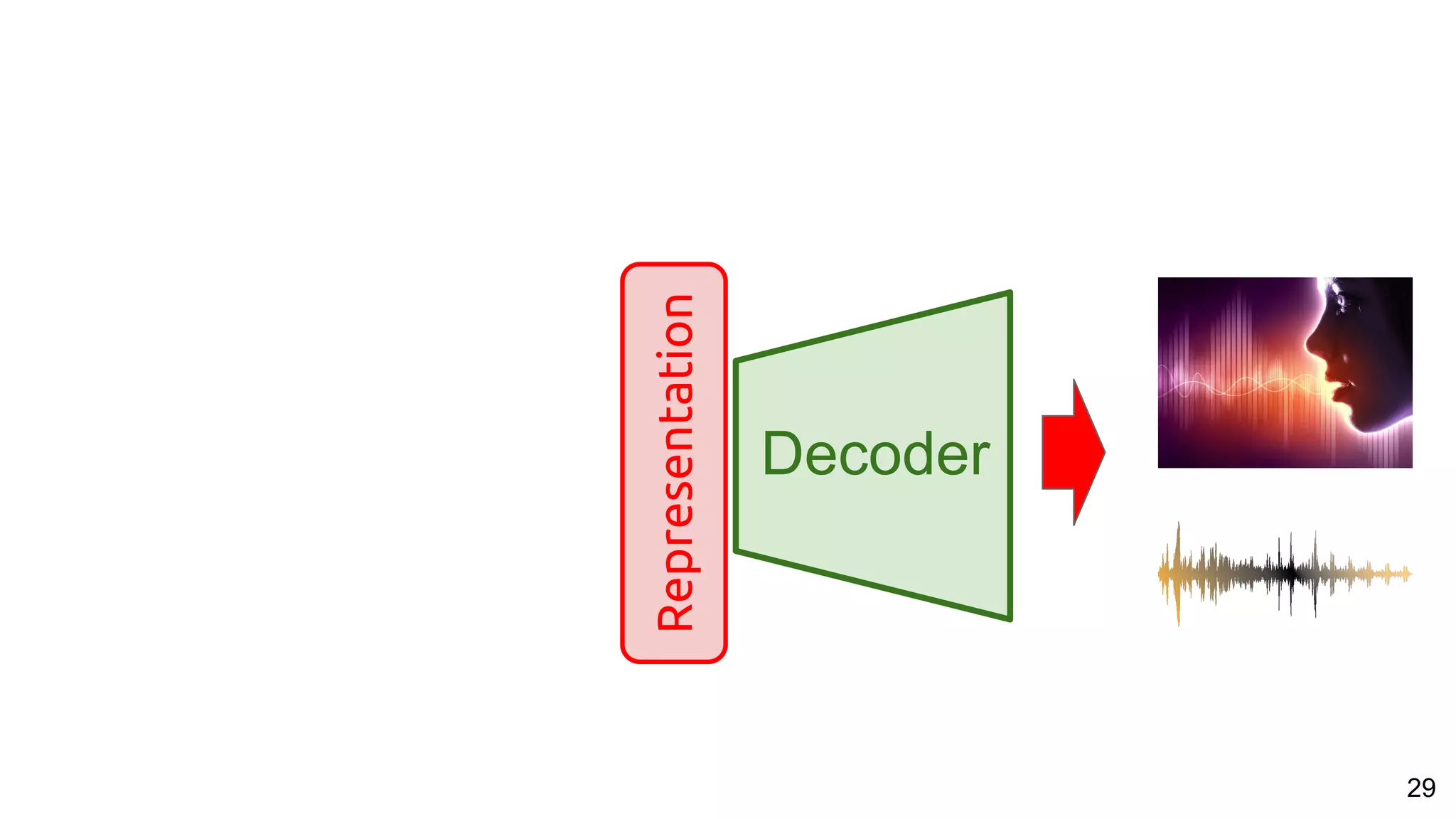

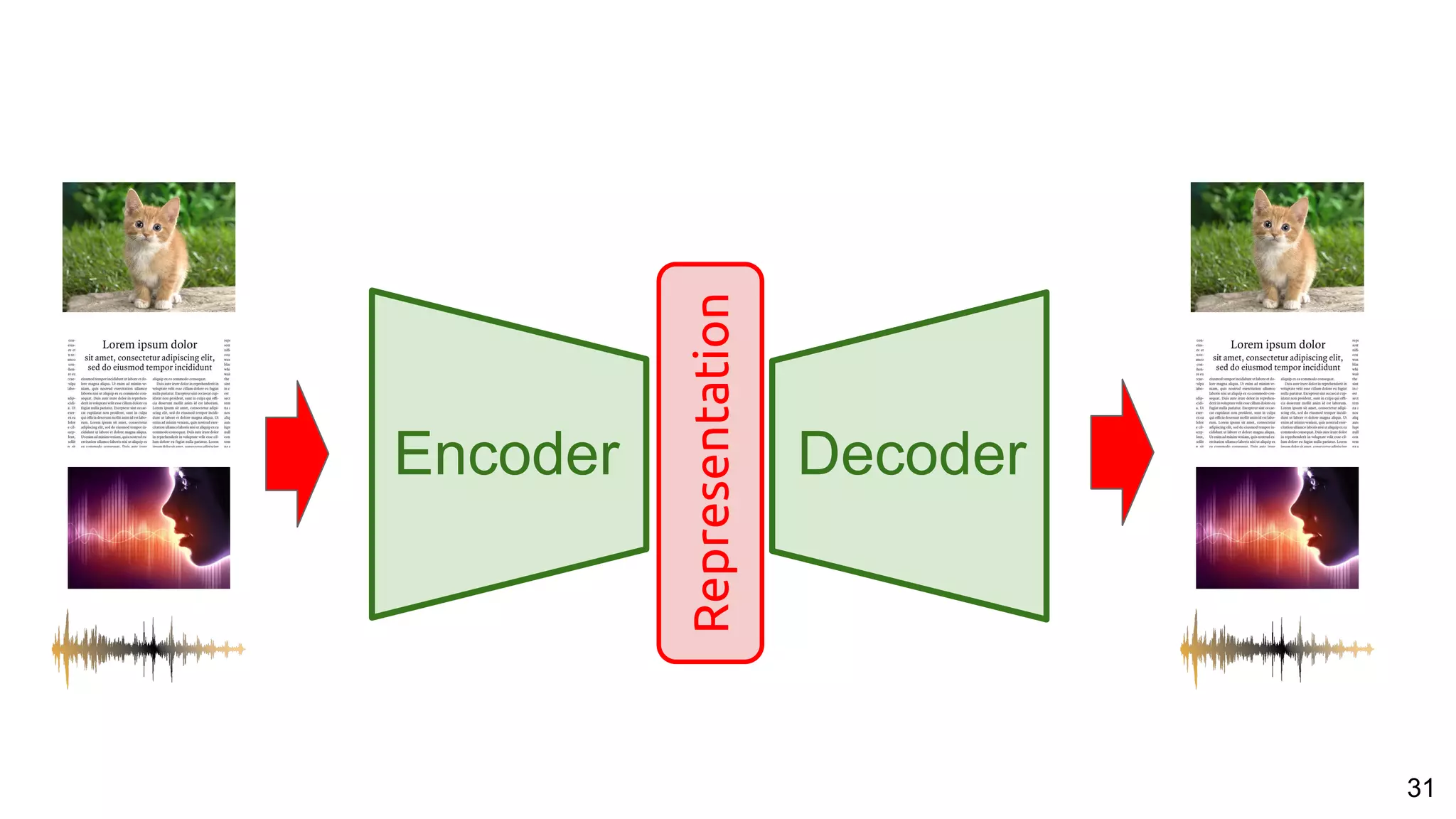
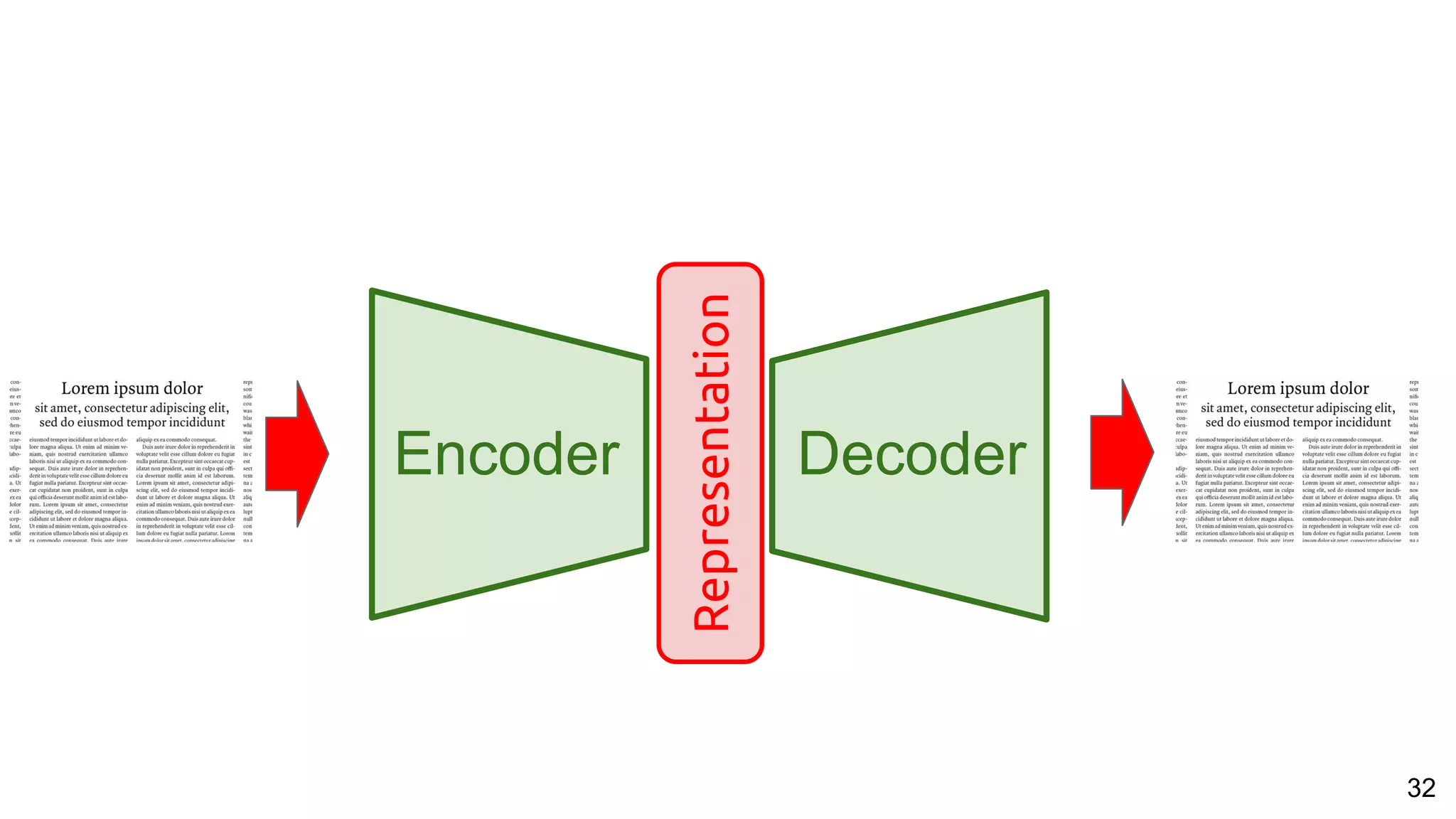
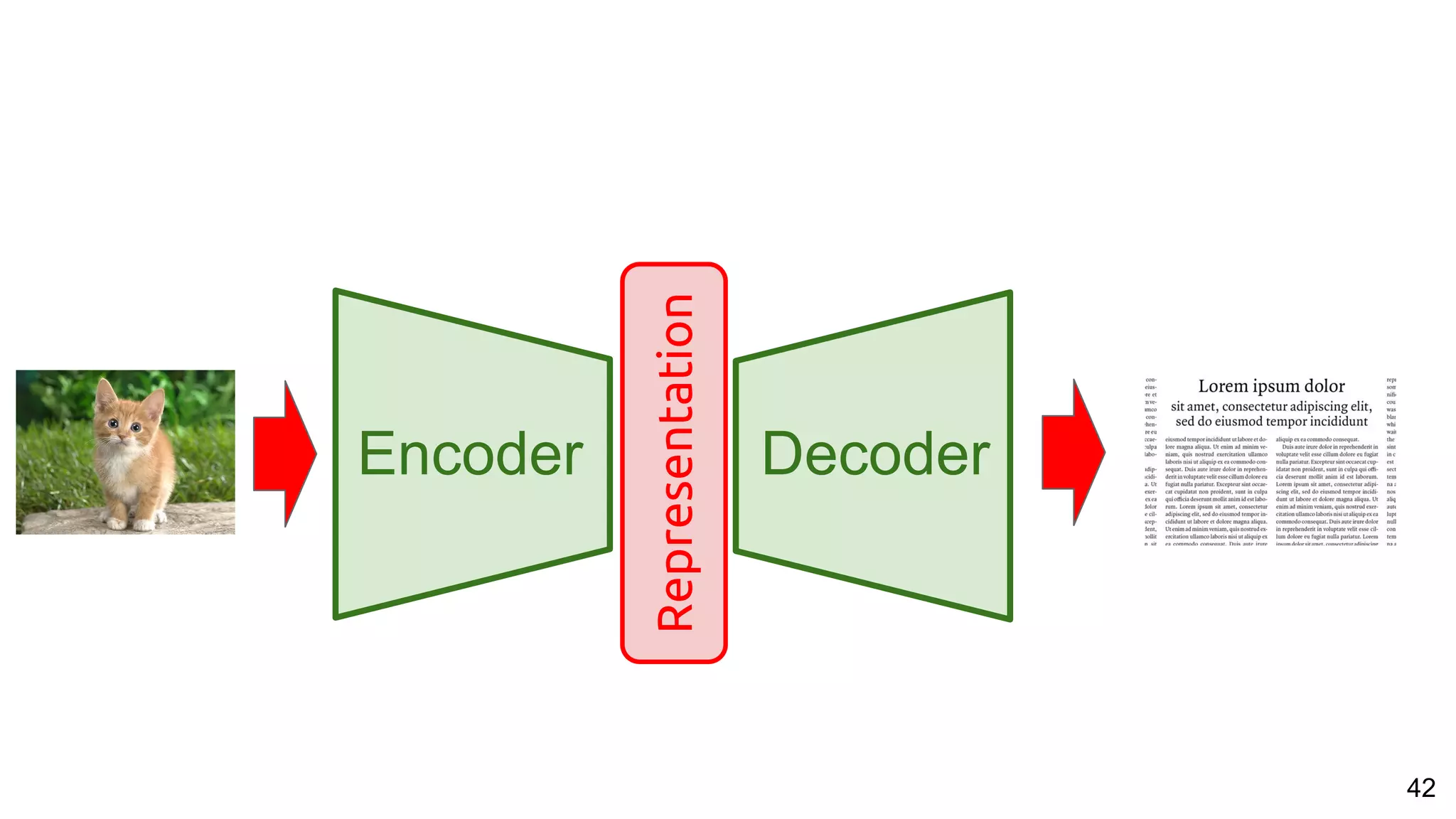
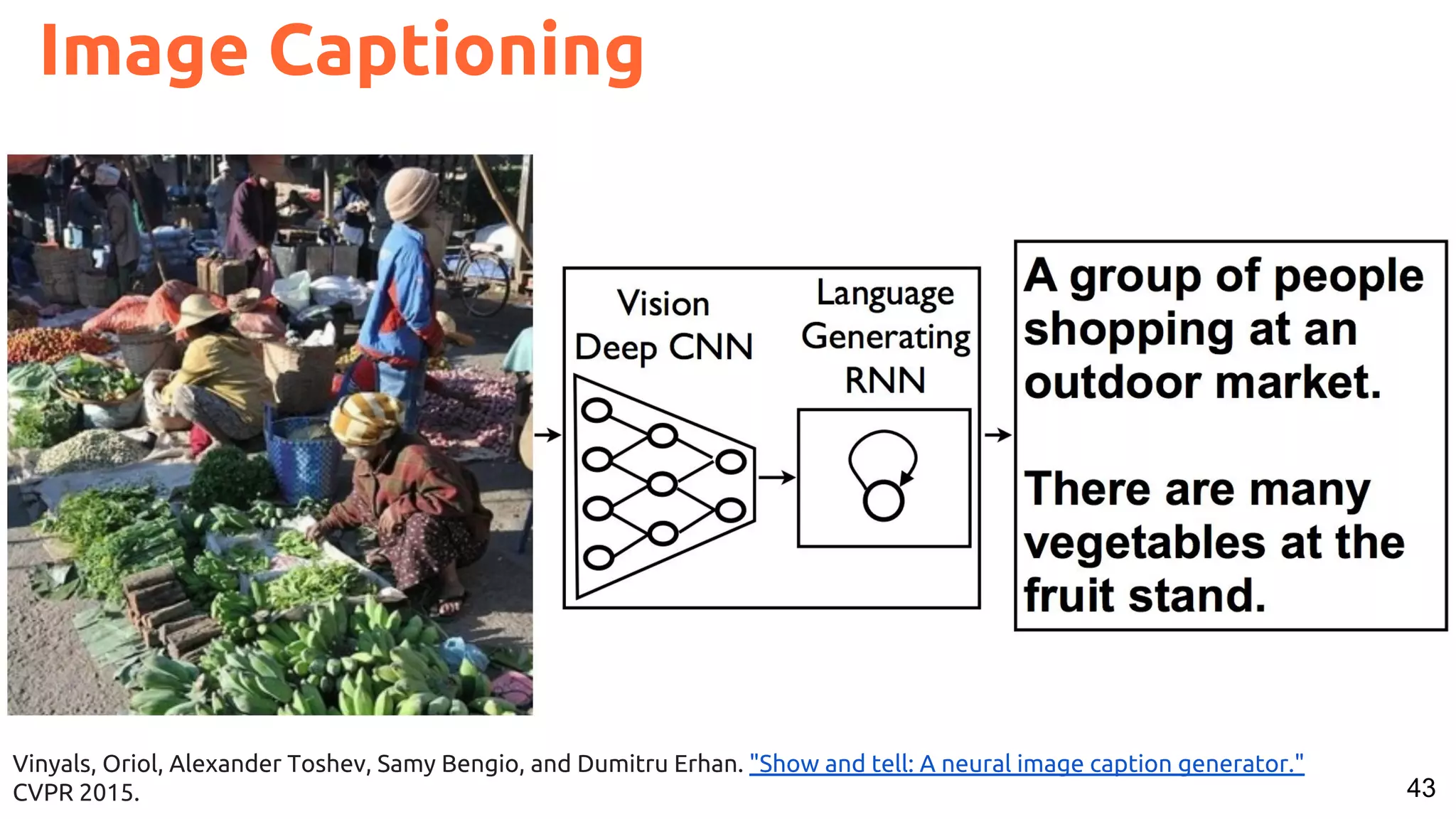
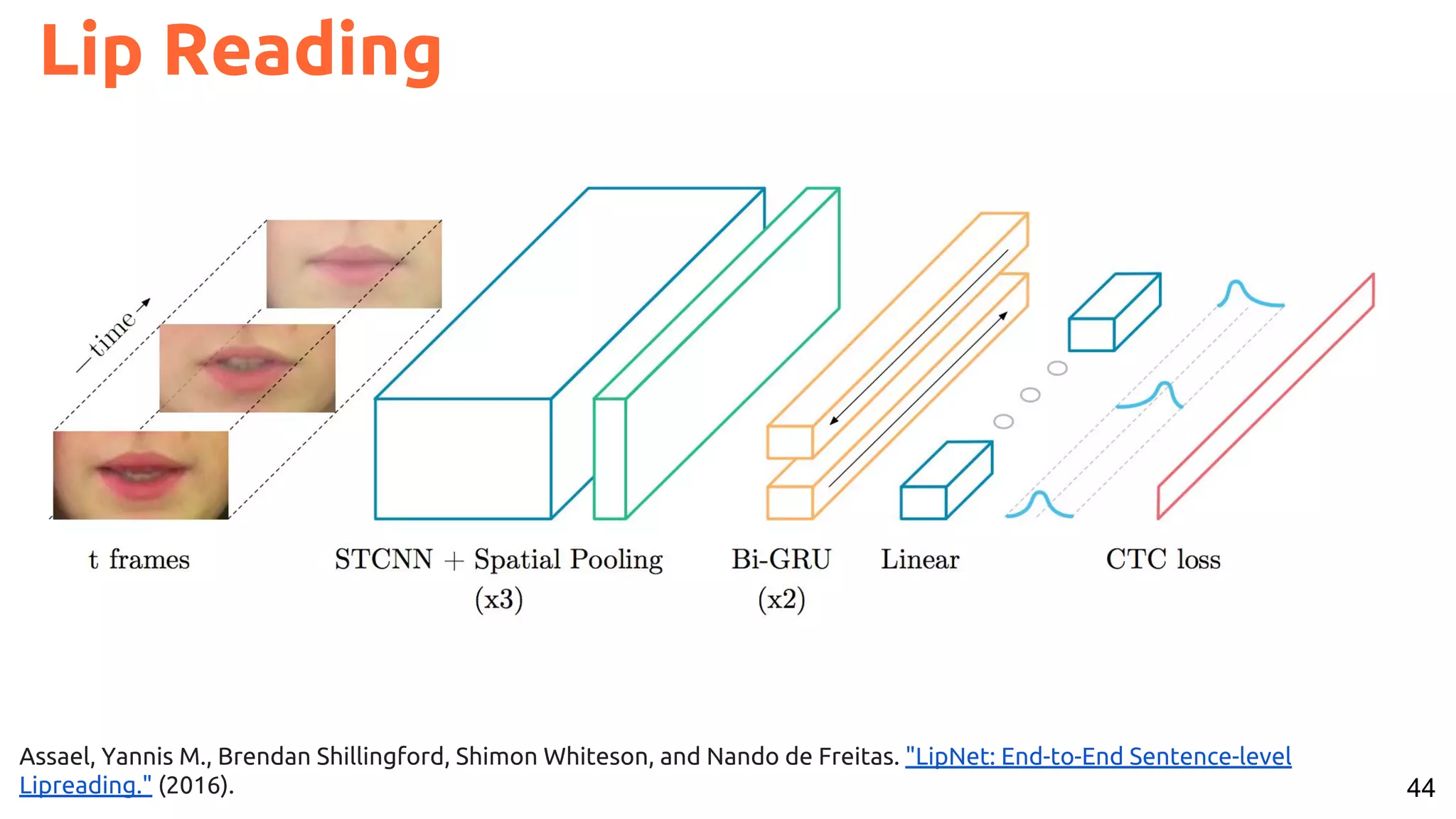
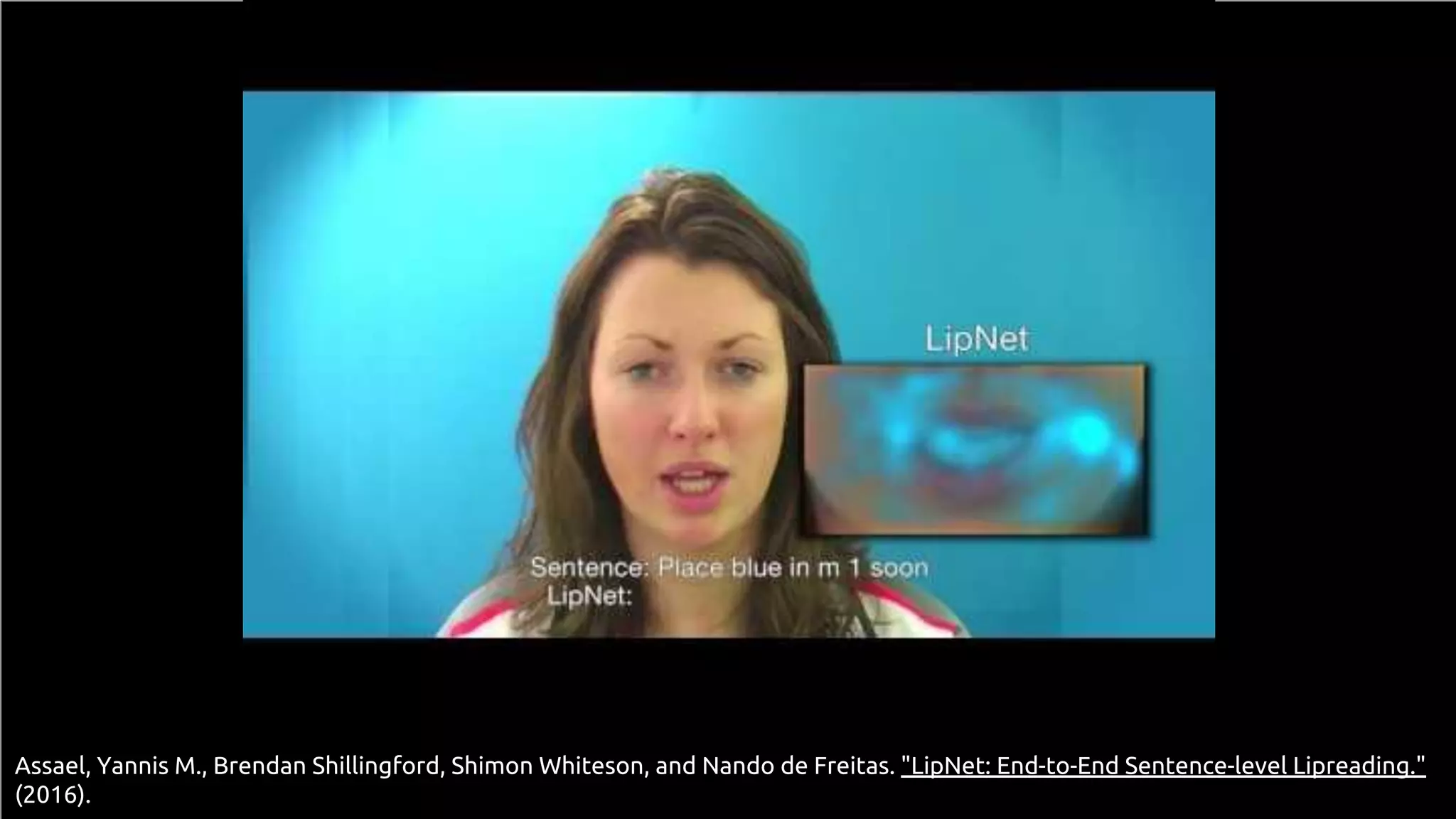

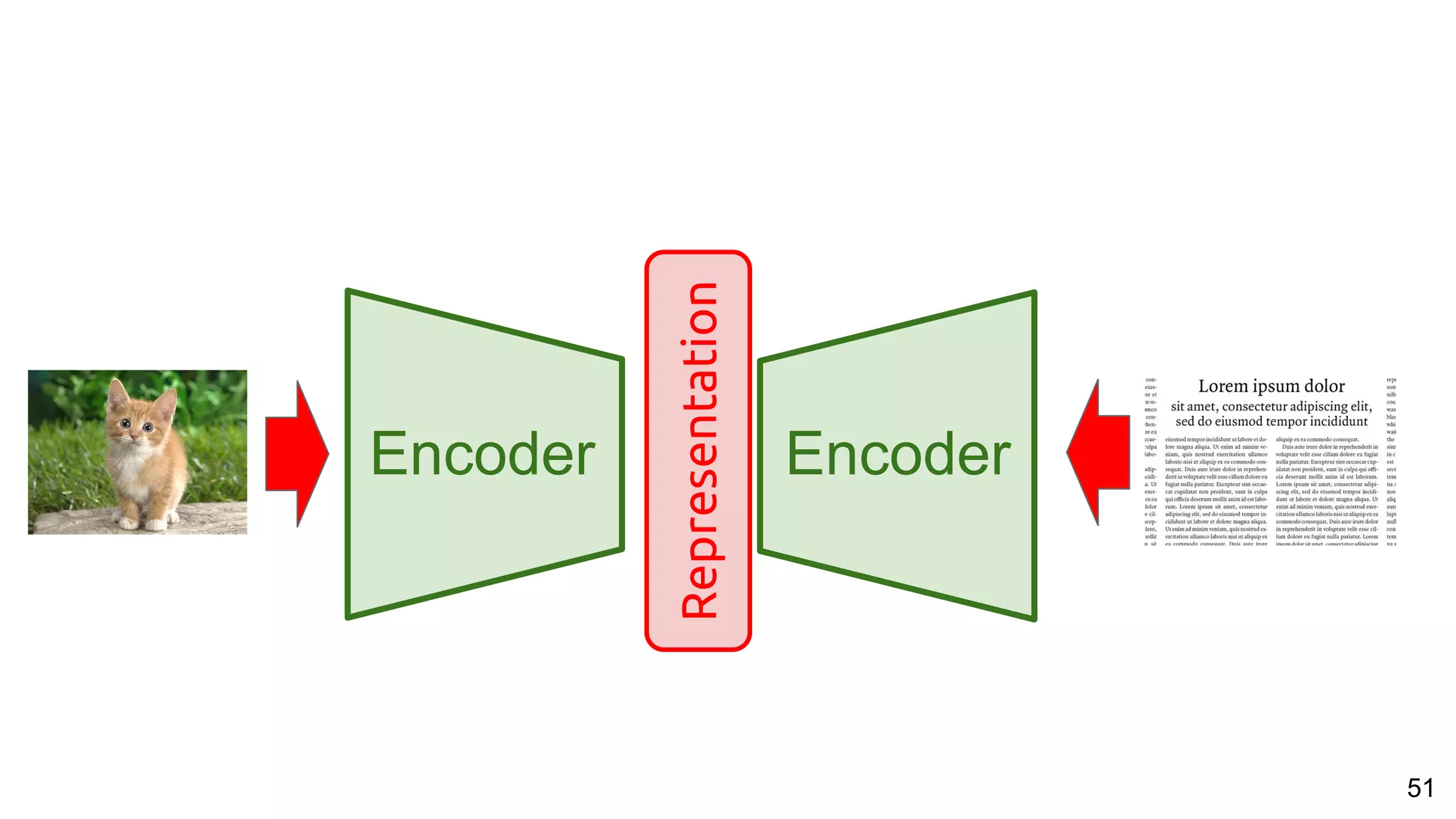
![53
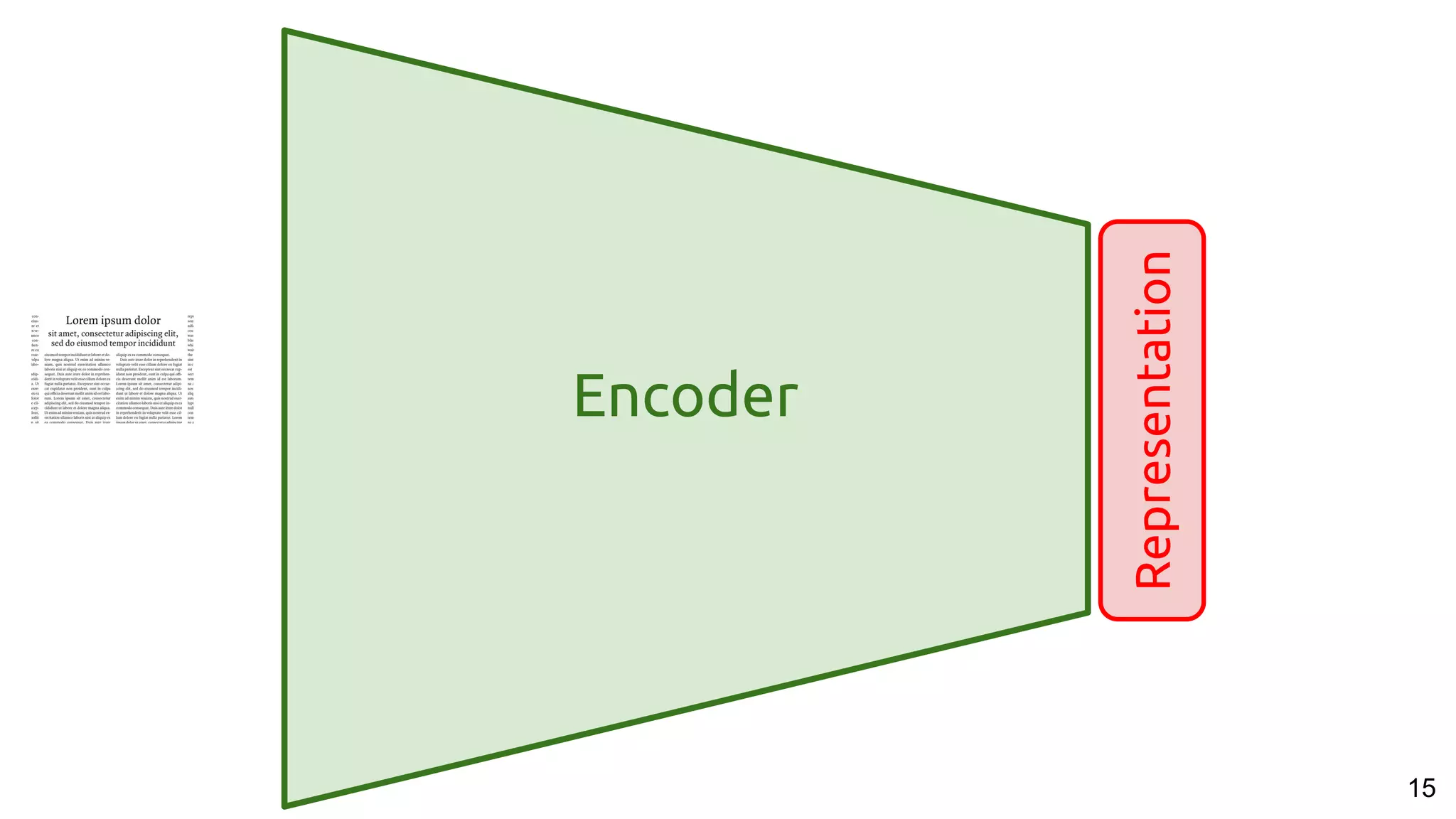
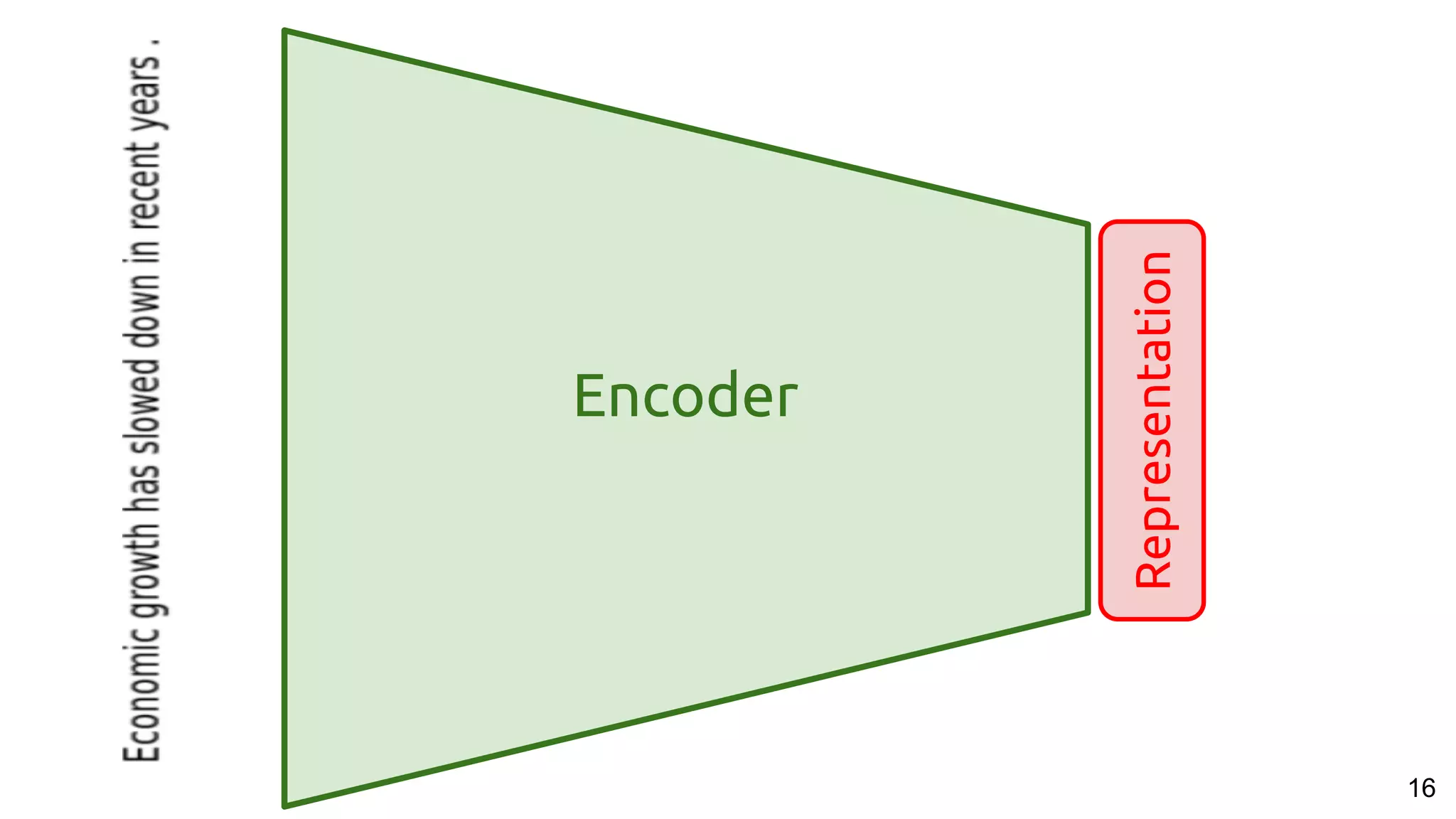
Zero-shot learning
Socher, R., Ganjoo, M., Manning, C. D., & Ng, A., Zero-shot learning through cross-modal transfer. NIPS 2013 [slides]
[code]
No images from “cat” in
the training set...
...but they can still be
recognised as “cats”
thanks to the
representations learned
from text .](https://image.slidesharecdn.com/a2ic2018oneperceptrontorulethemall1-181122151050/75/One-Perceptron-to-Rule-them-All-Deep-Learning-for-Multimedia-A2IC2018-53-2048.jpg)

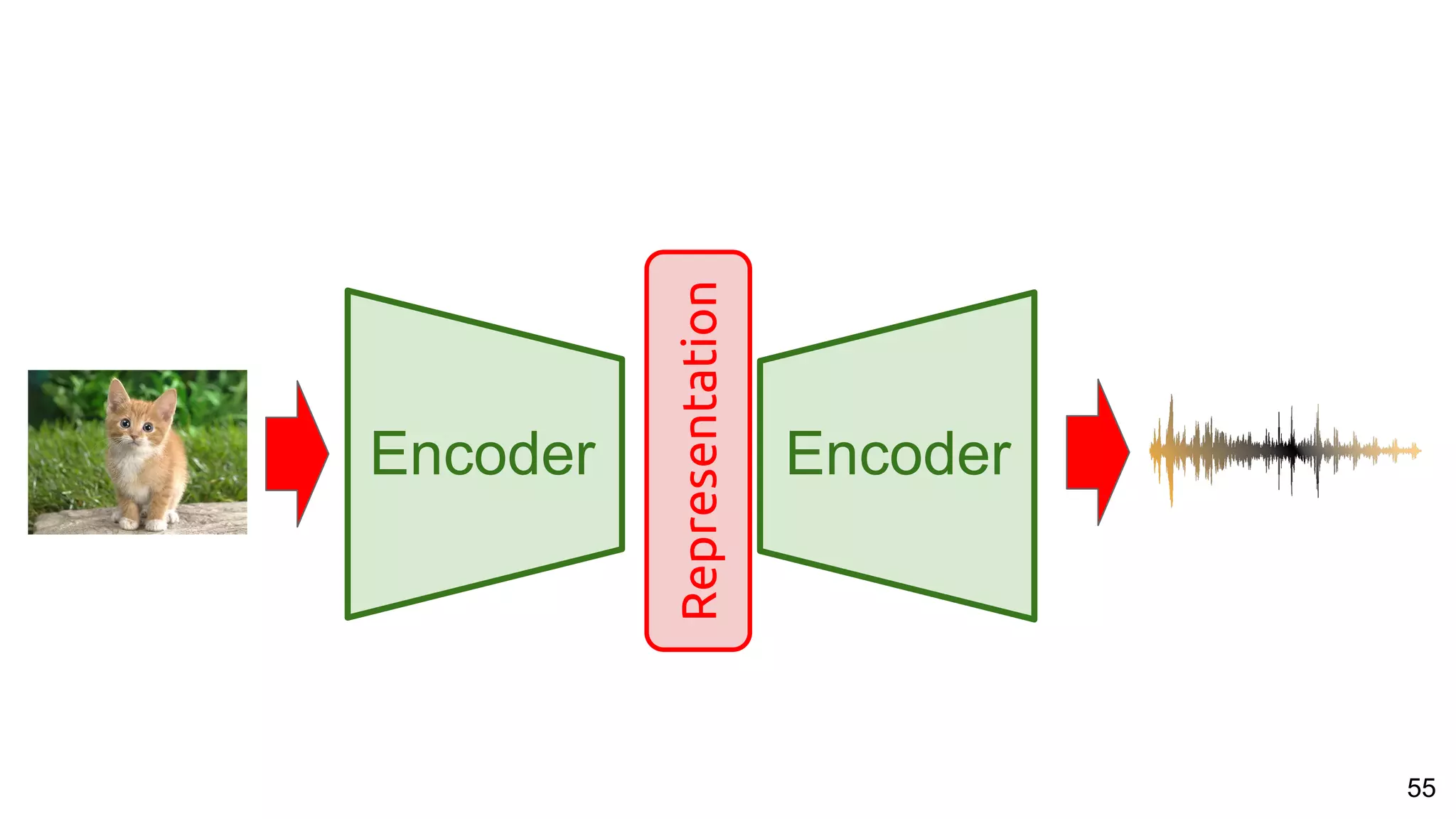




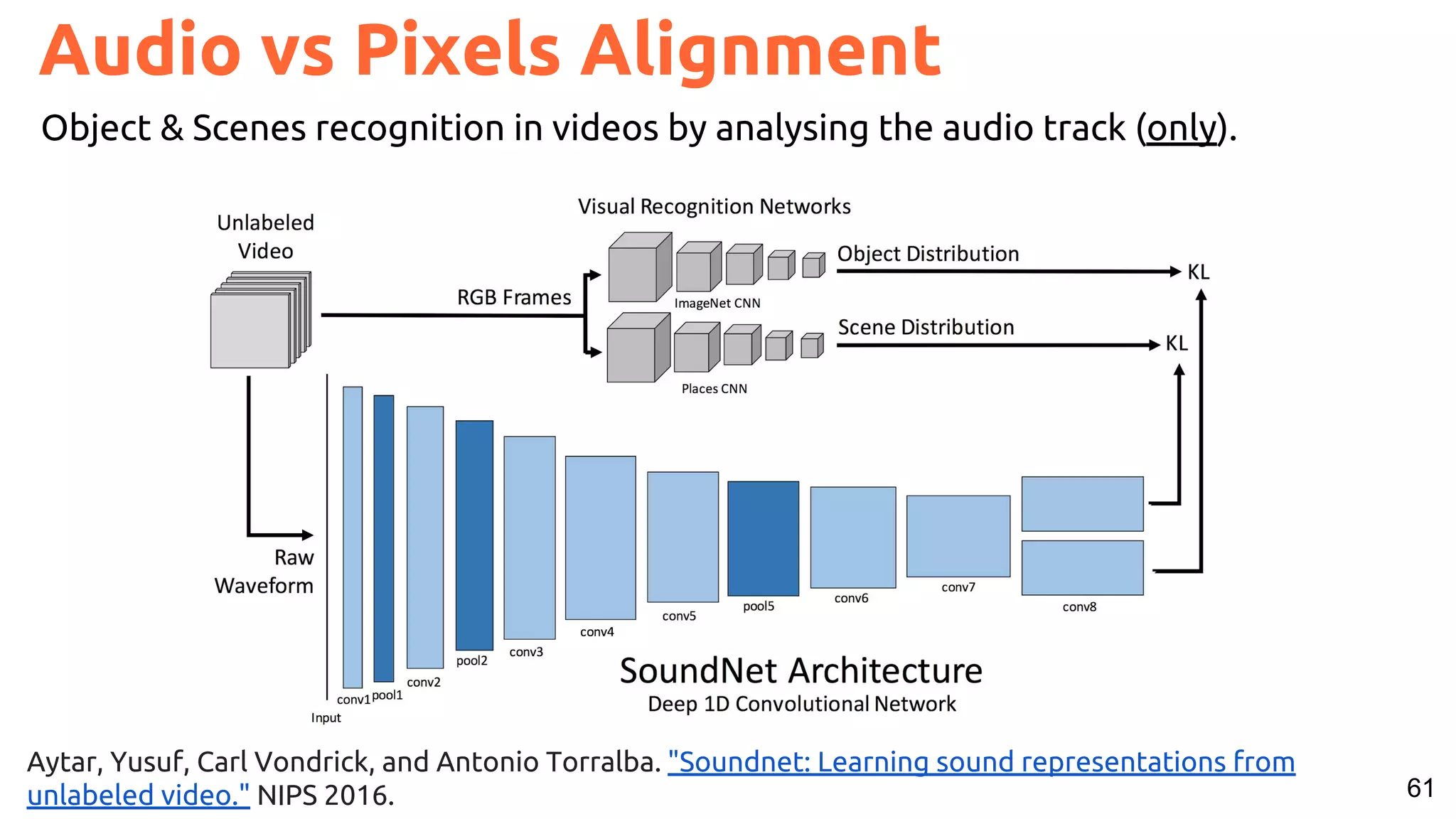
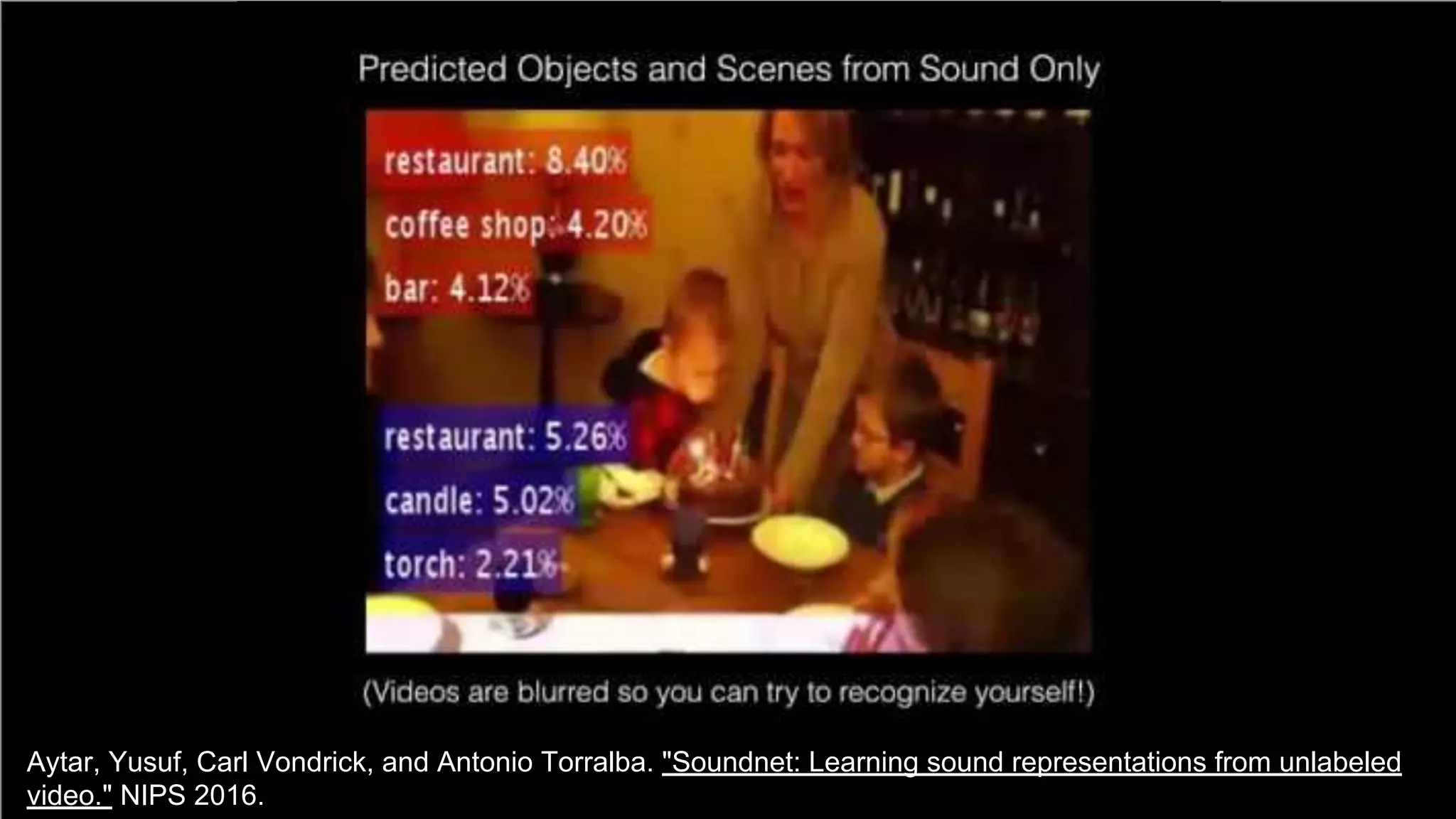
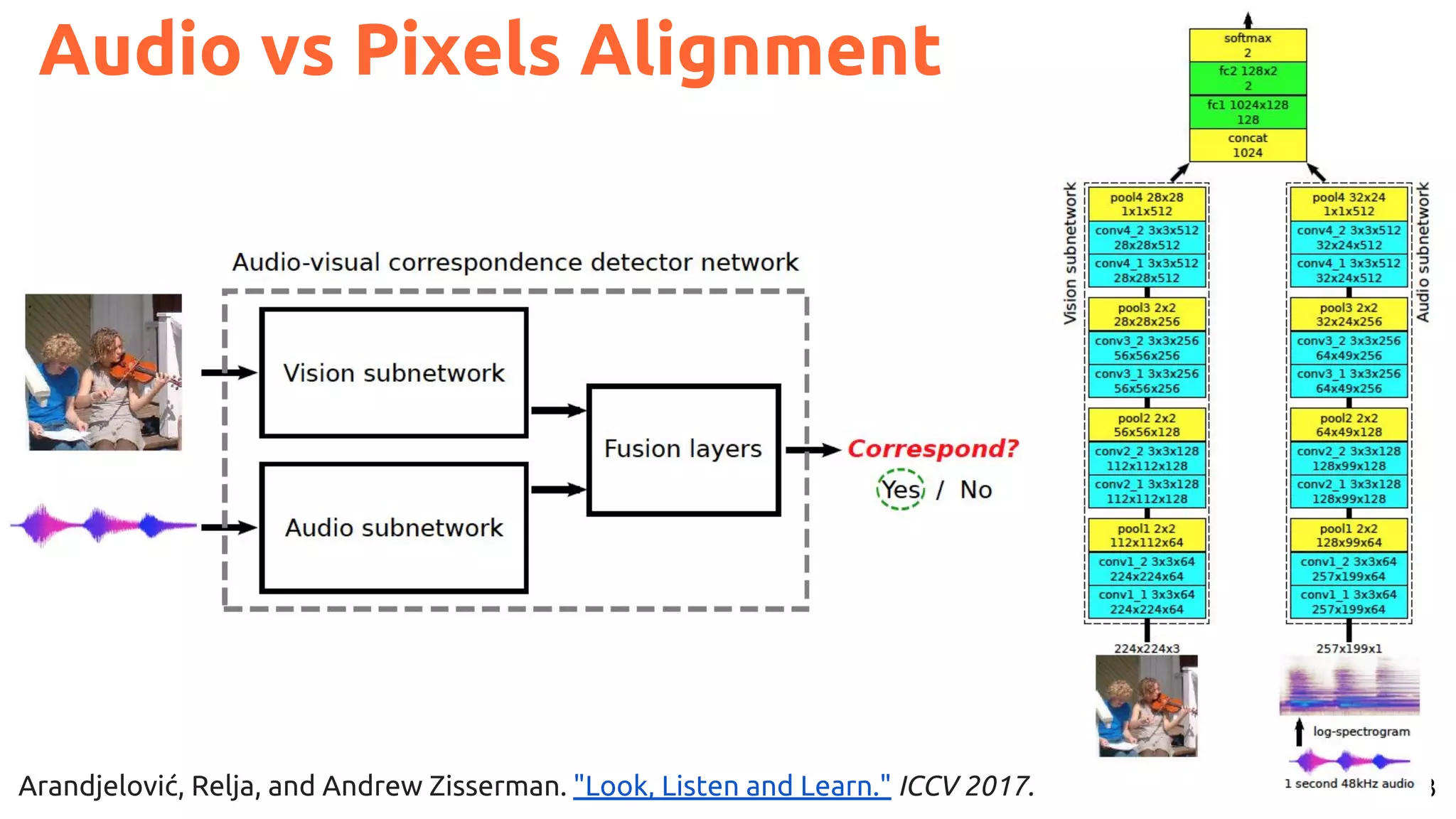

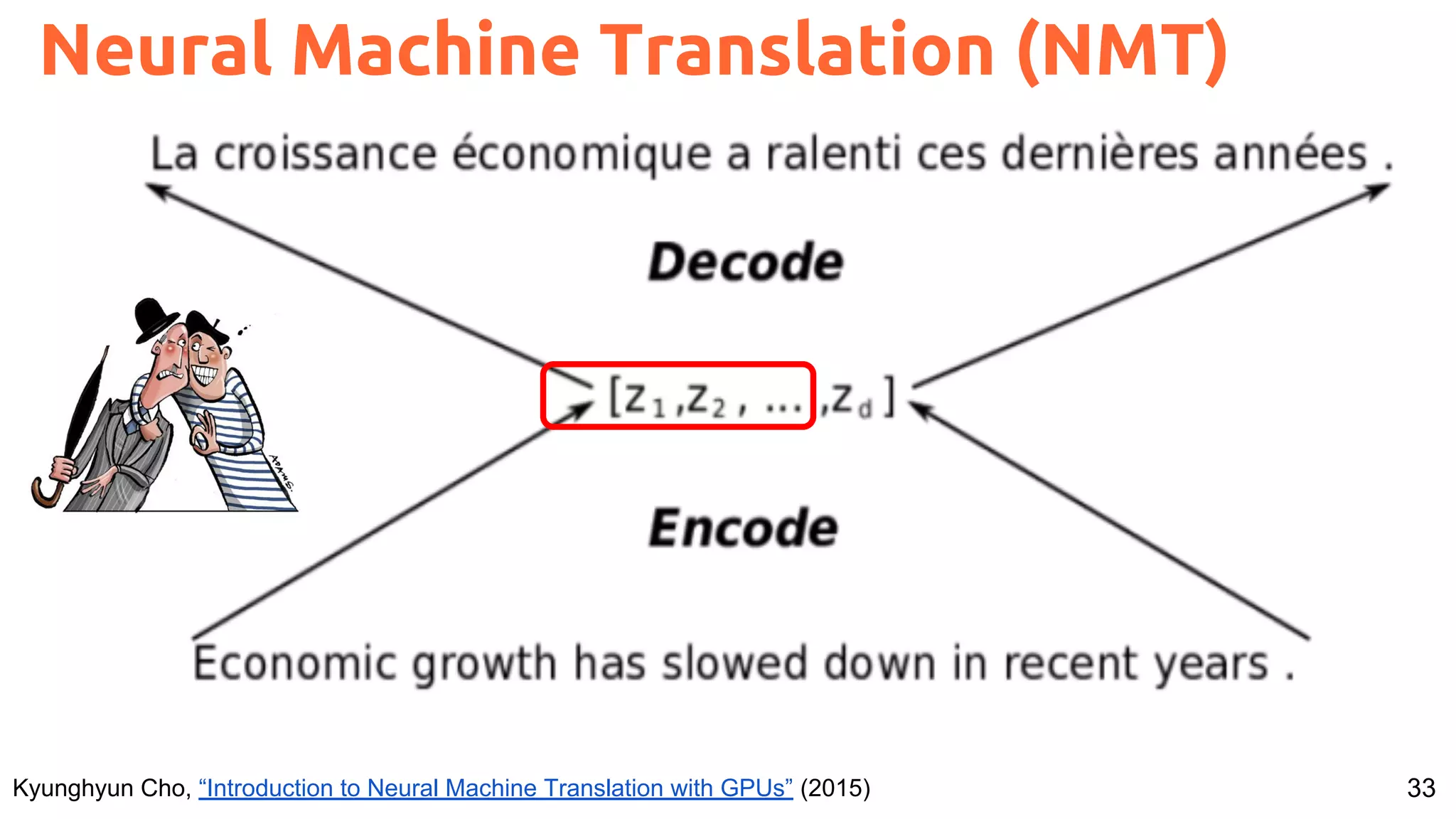
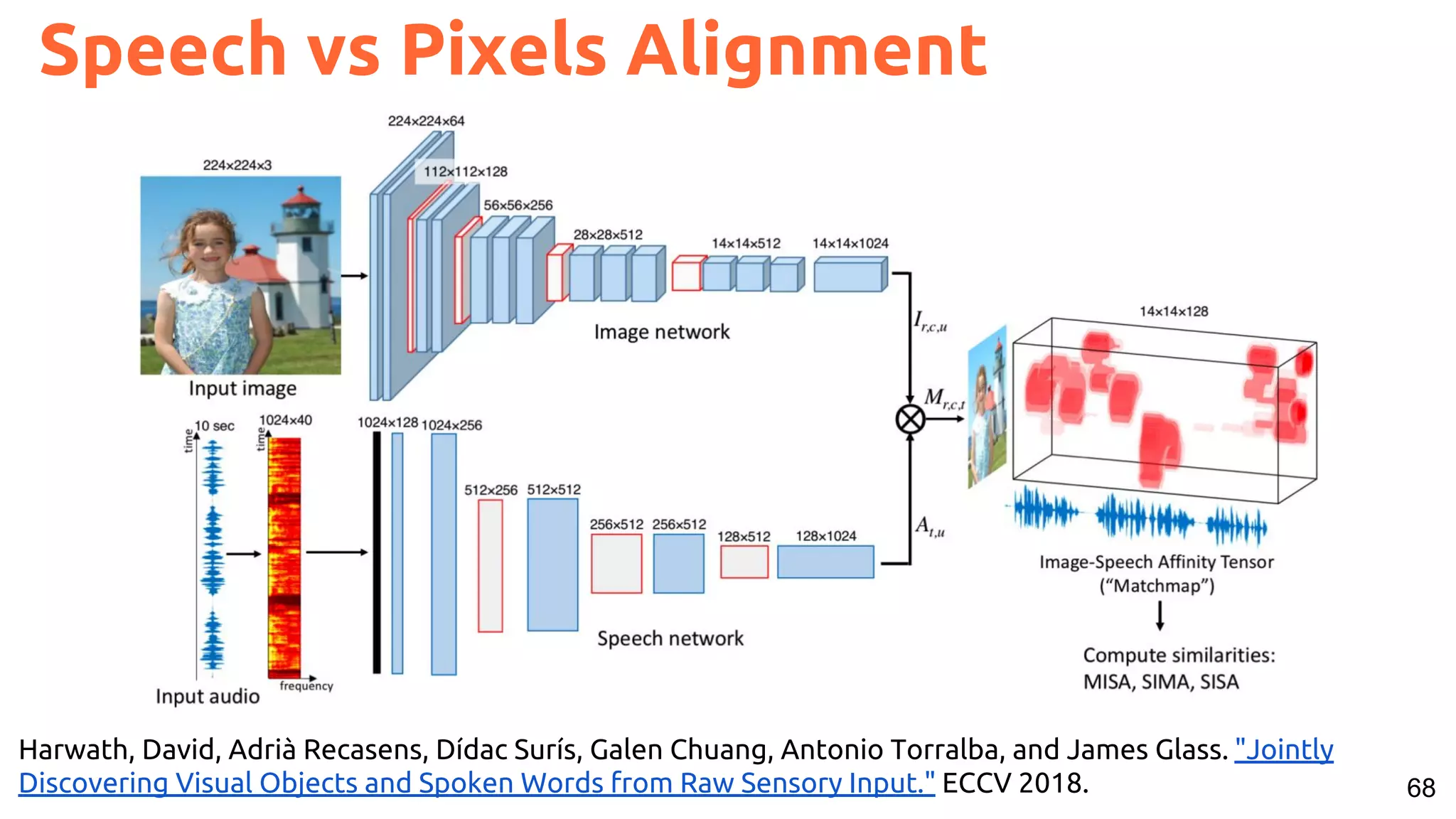
![66
Speech vs Pixels Alignment
Harwath, David, Antonio Torralba, and James Glass. "Unsupervised learning of spoken language with visual context." NIPS 2016.
[talk]
Train a visual & speech networks with pairs of (non-)corresponding images & speech.](https://image.slidesharecdn.com/a2ic2018oneperceptrontorulethemall1-181122151050/75/One-Perceptron-to-Rule-them-All-Deep-Learning-for-Multimedia-A2IC2018-66-2048.jpg)
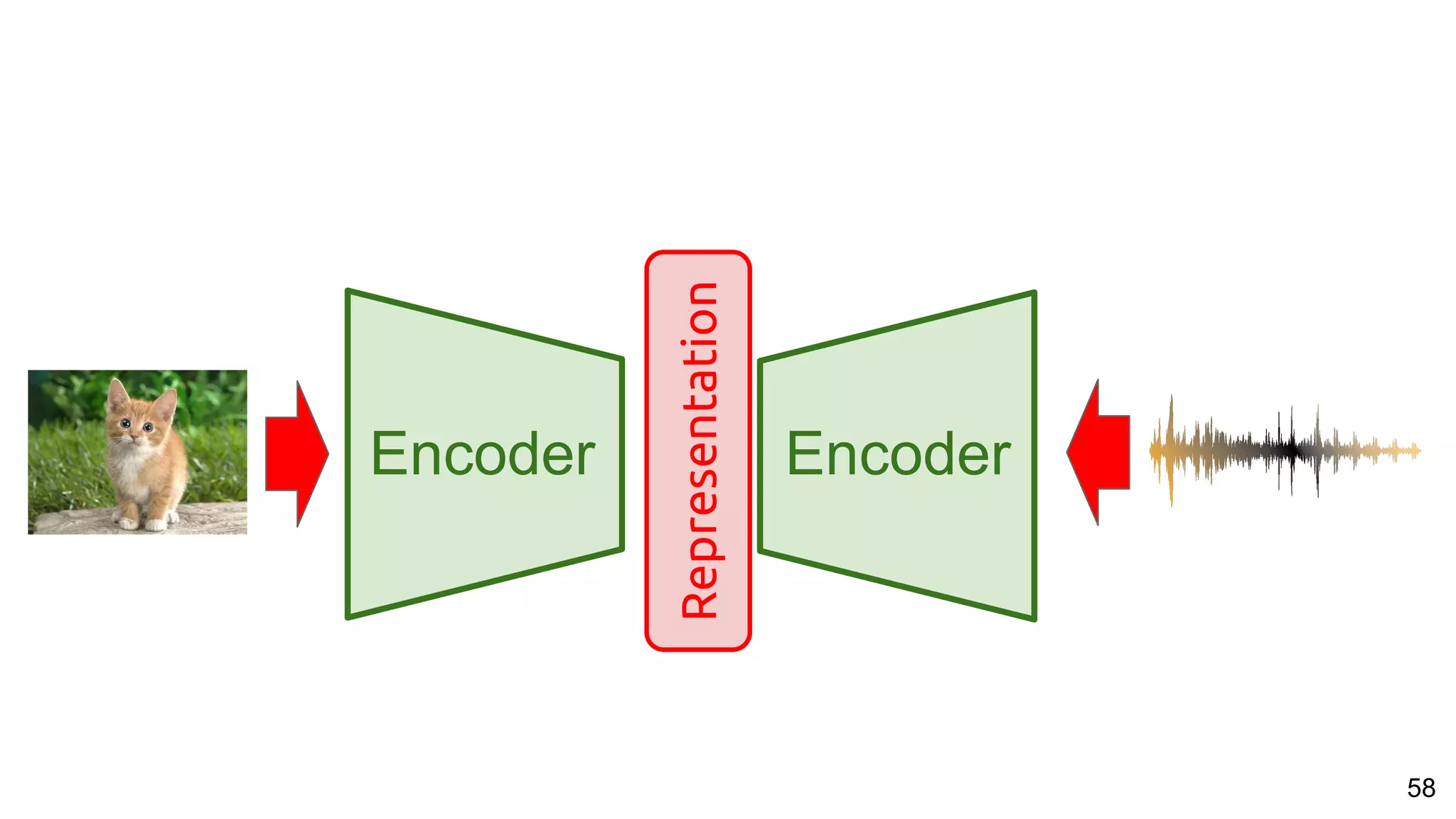
![67
Speech vs Pixels Alignment
Harwath, David, Antonio Torralba, and James Glass. "Unsupervised learning of spoken language with visual context." NIPS 2016.
[talk]
Similarity curve show which regions of the spectrogram are relevant for the image.
Important: no text transcriptions used during the training !!](https://image.slidesharecdn.com/a2ic2018oneperceptrontorulethemall1-181122151050/75/One-Perceptron-to-Rule-them-All-Deep-Learning-for-Multimedia-A2IC2018-67-2048.jpg)

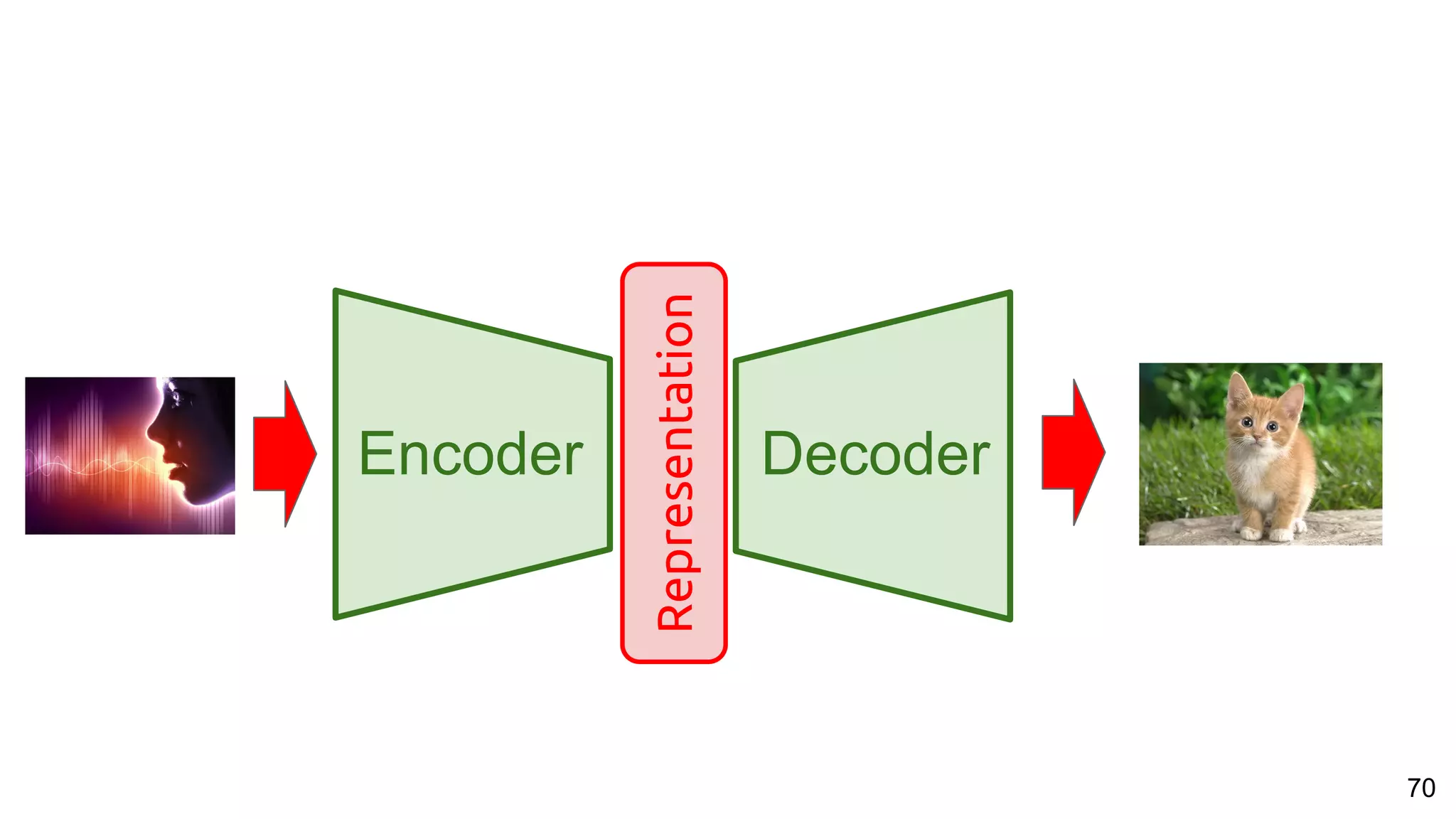

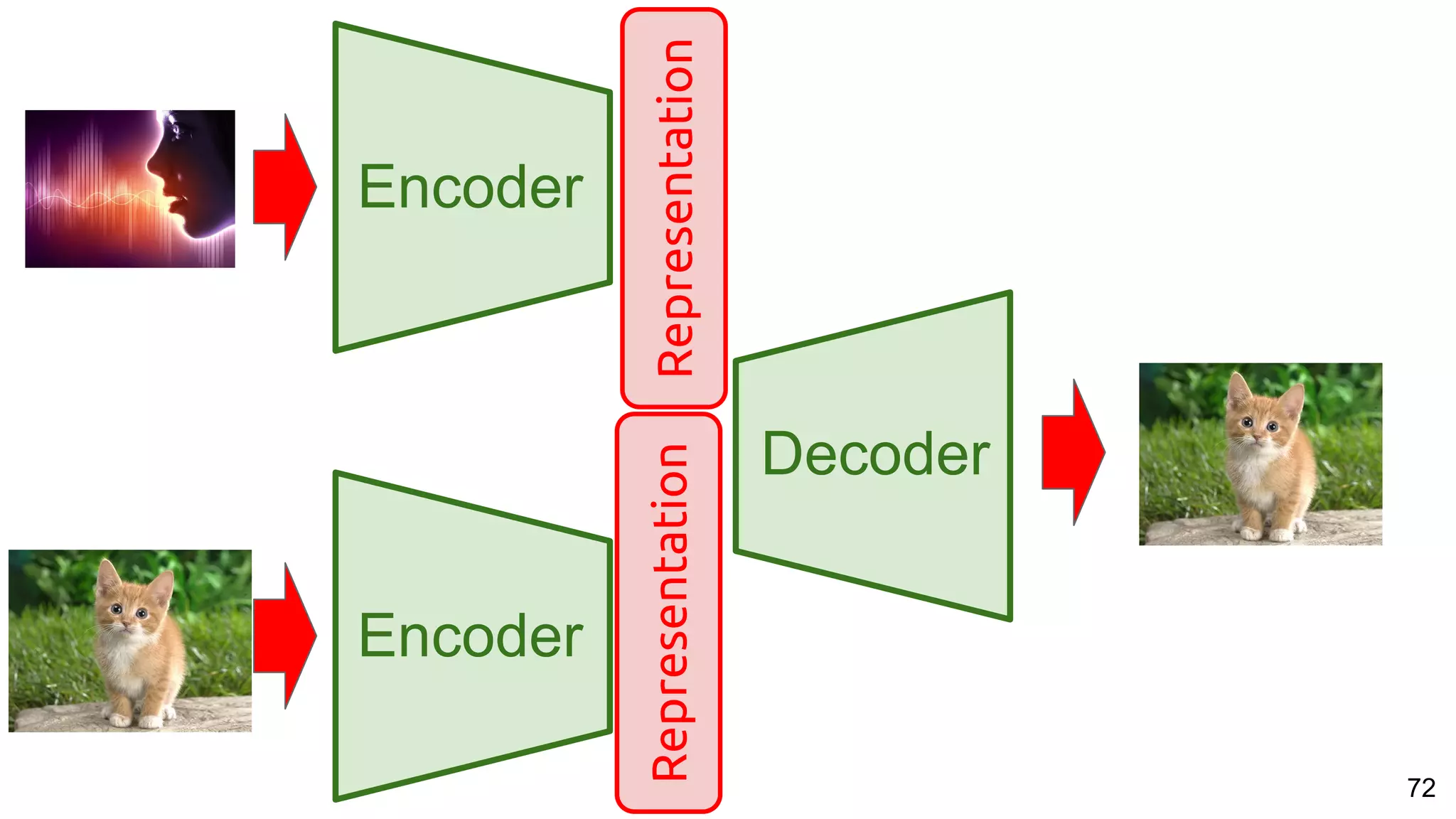
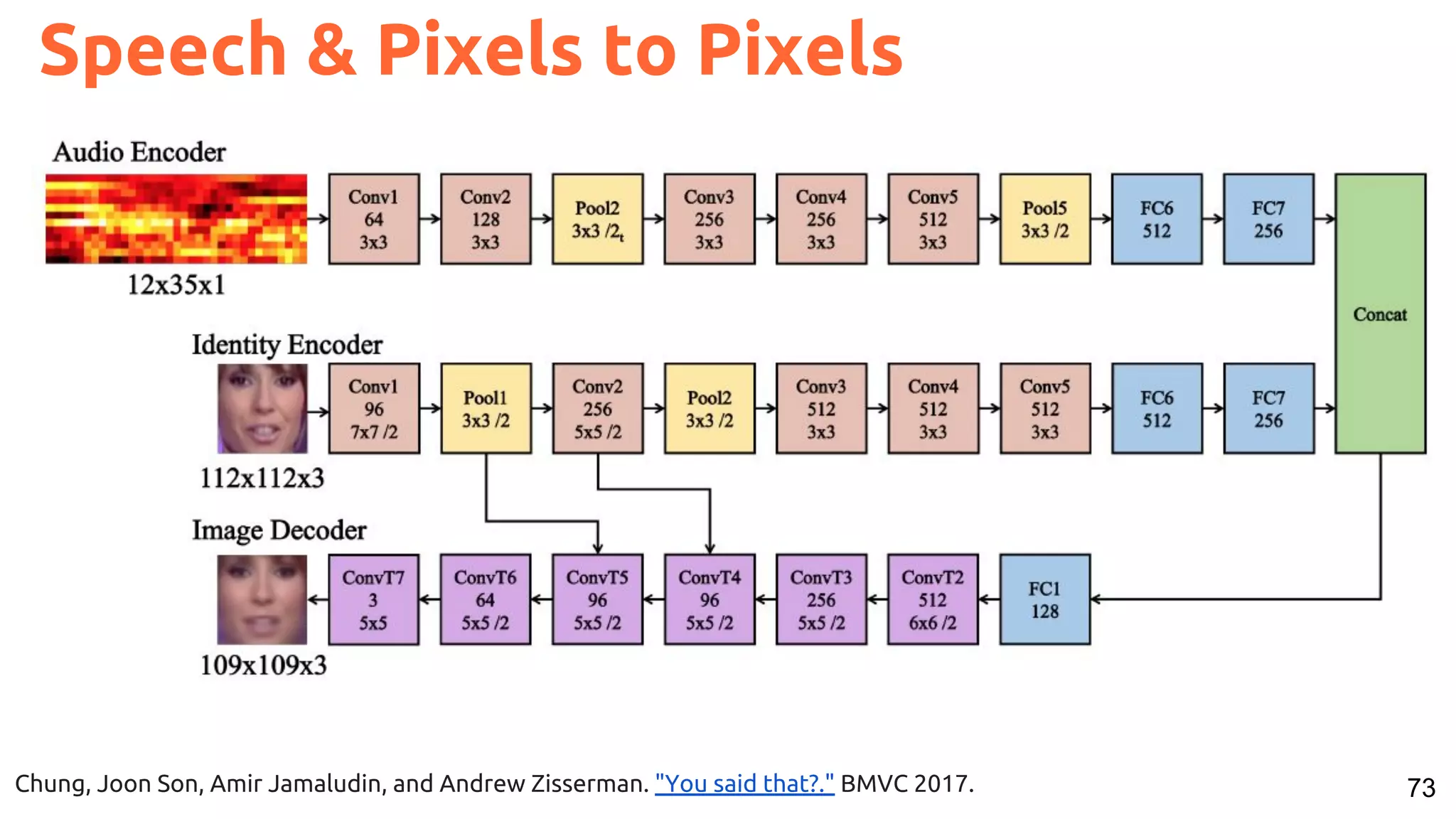

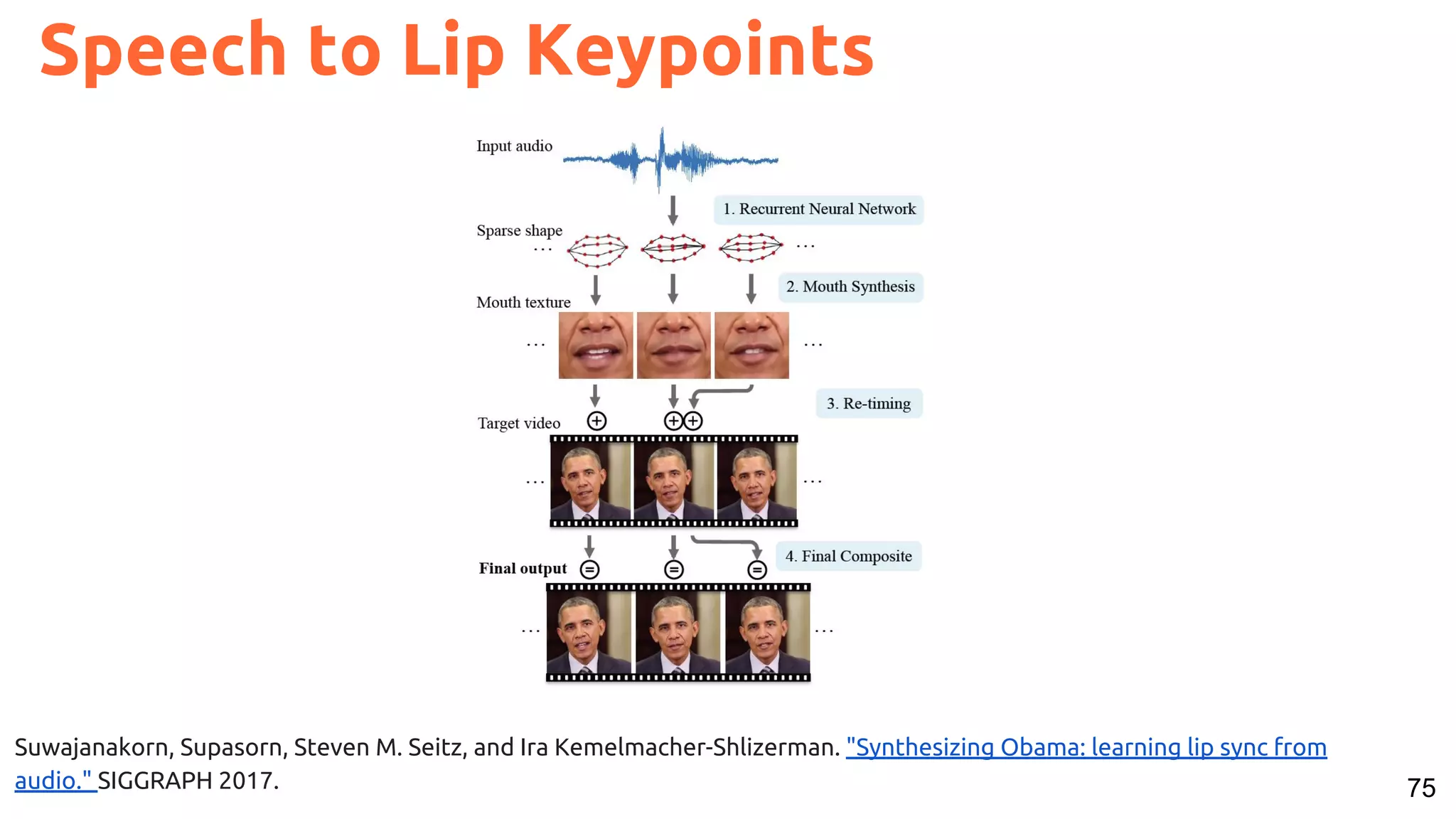
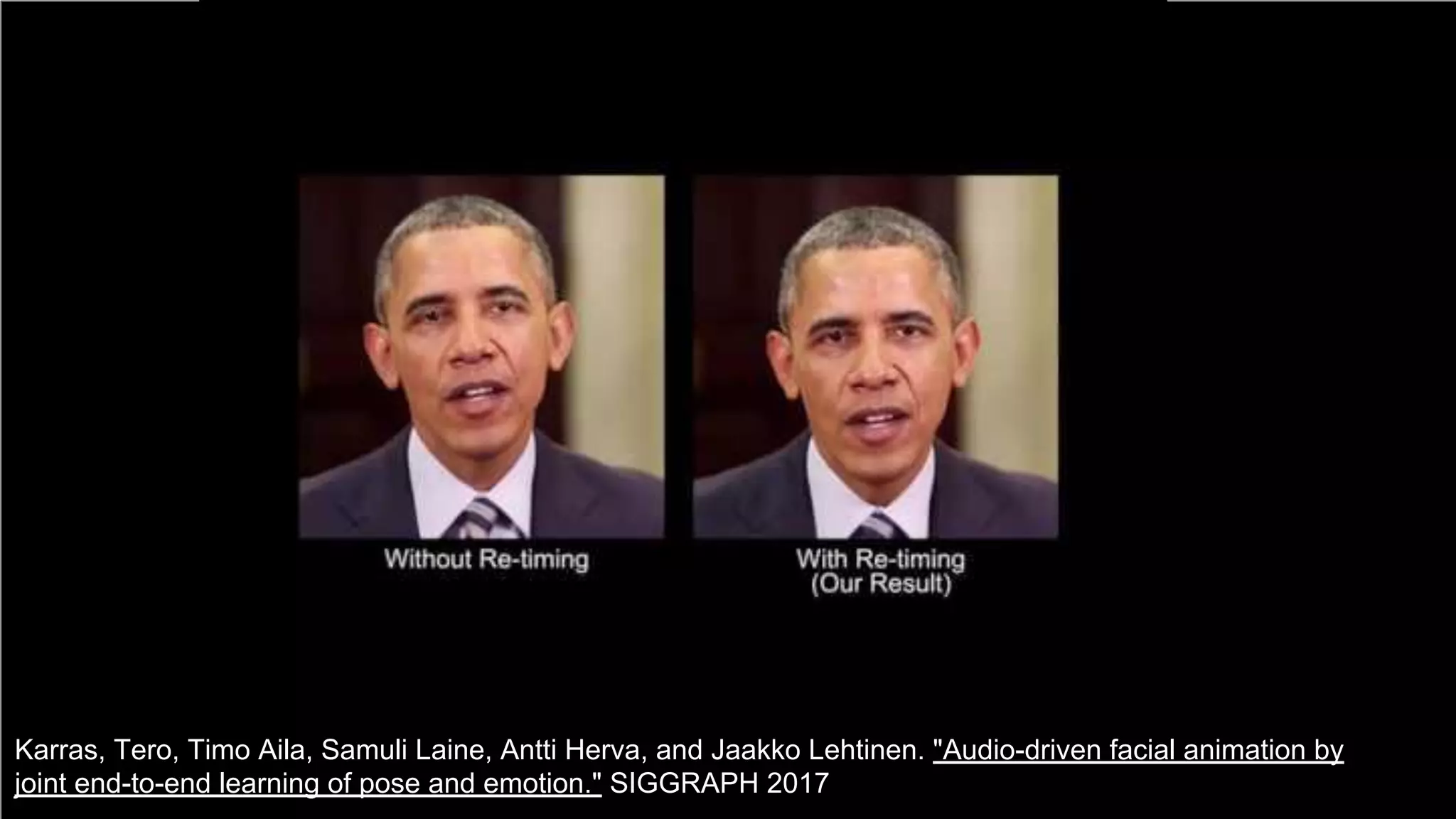
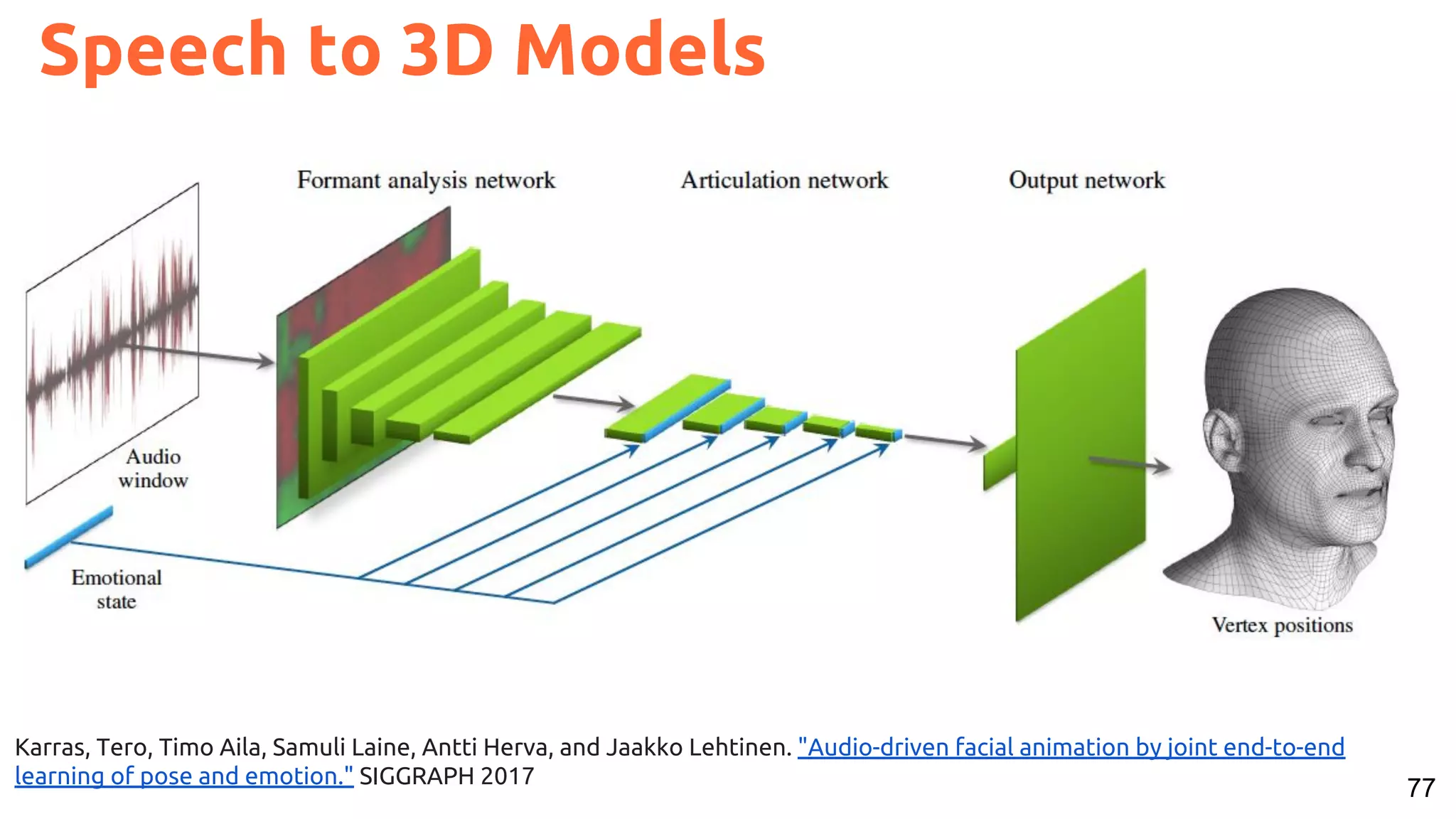

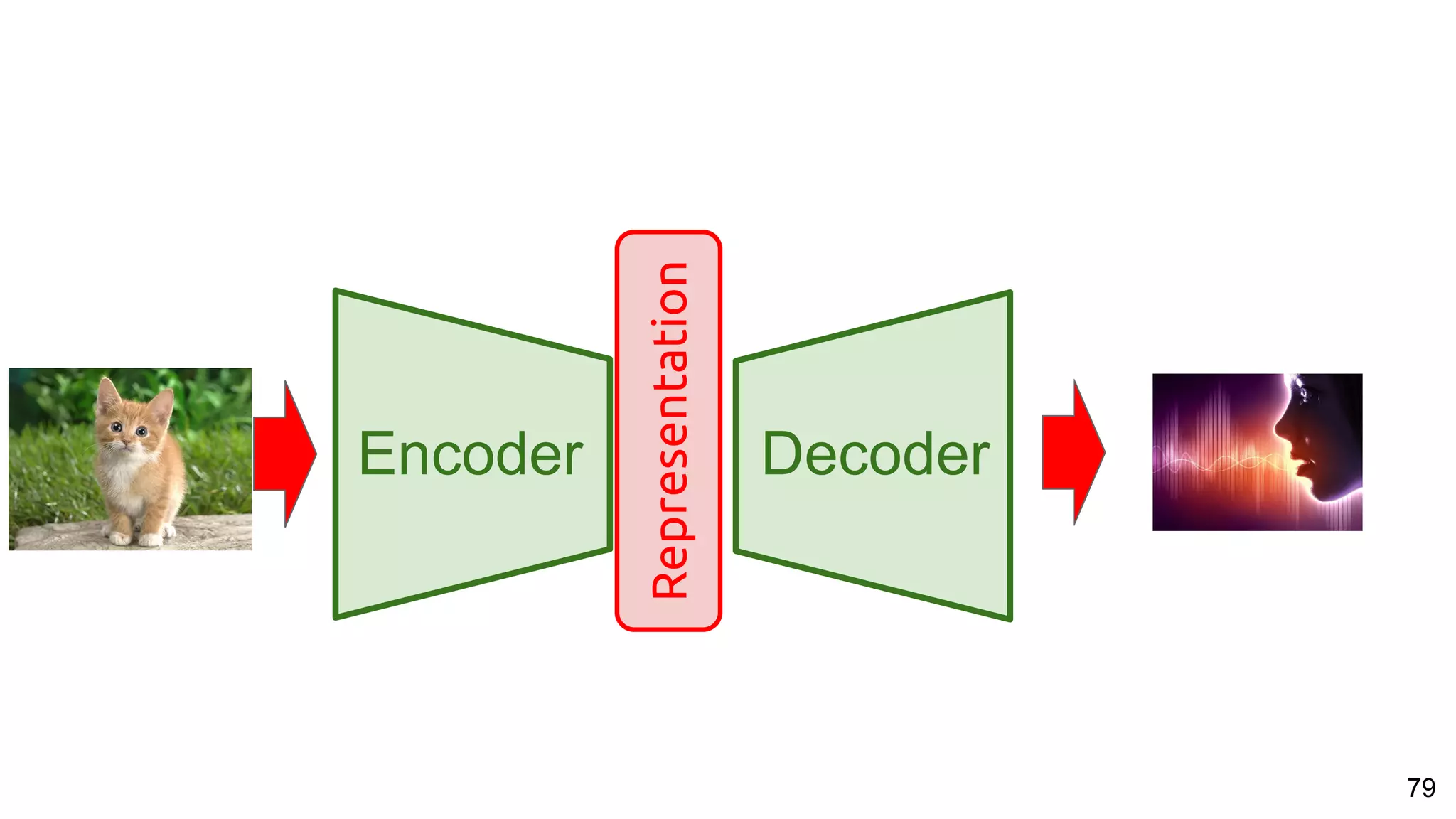


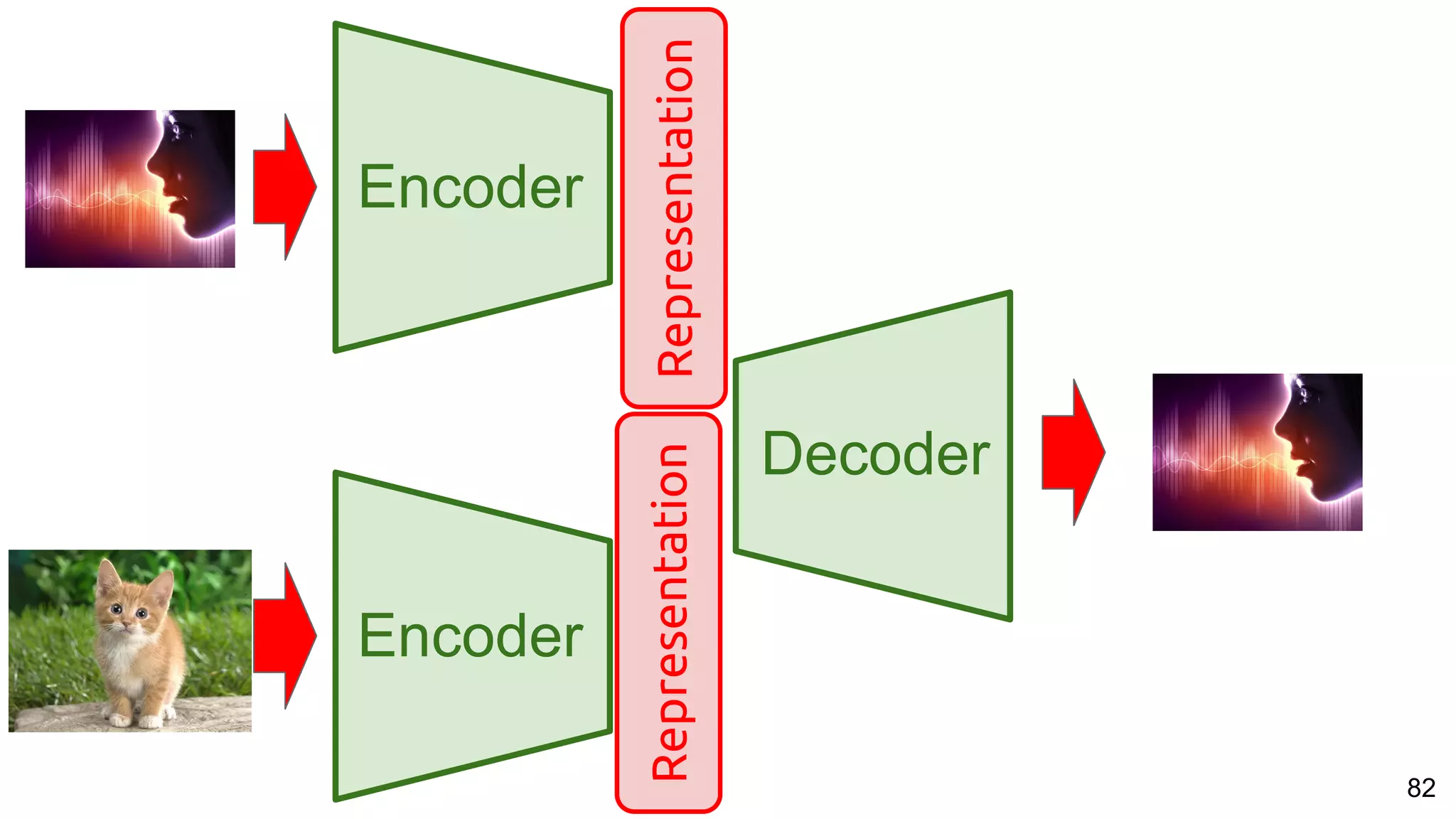
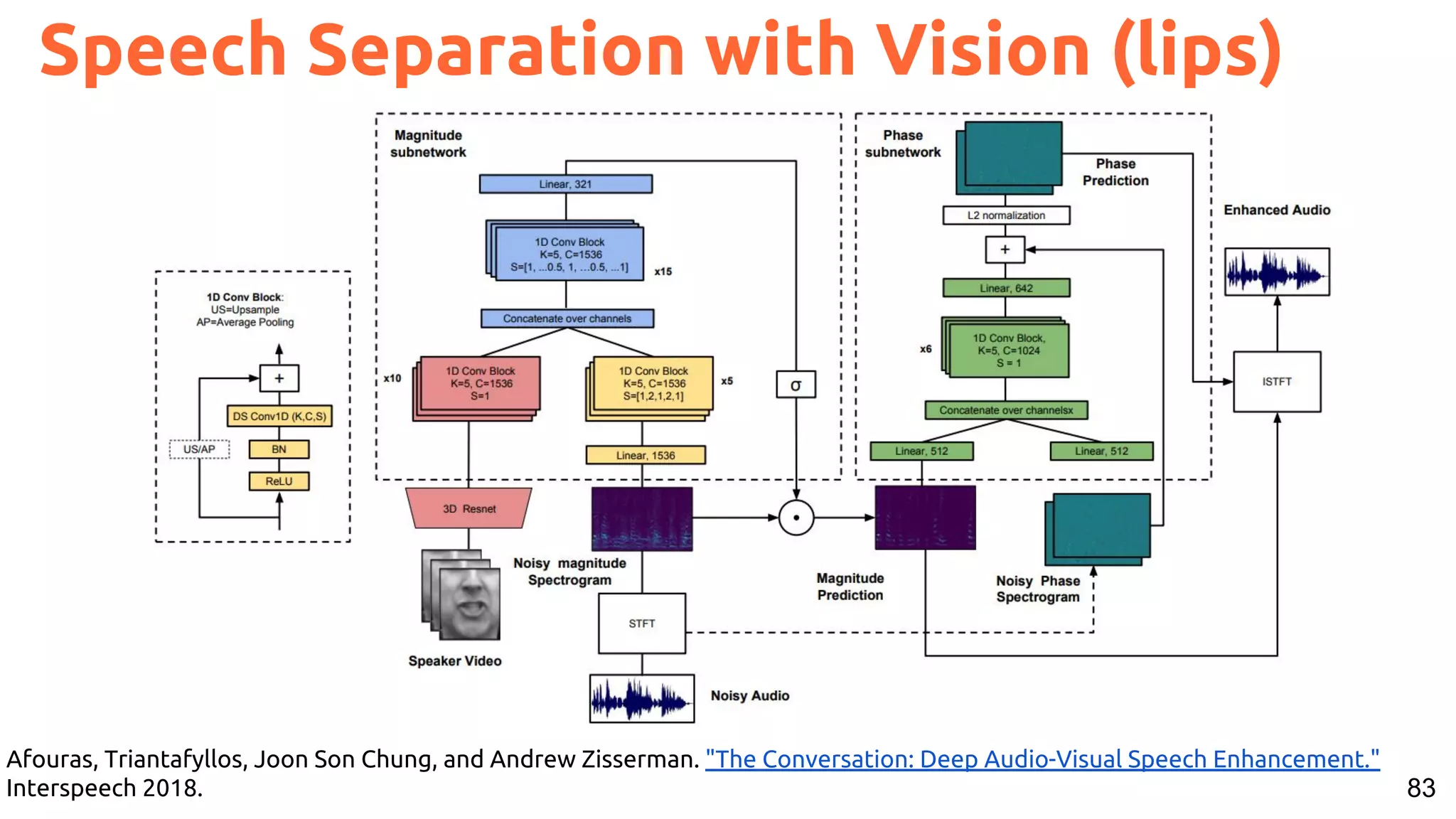
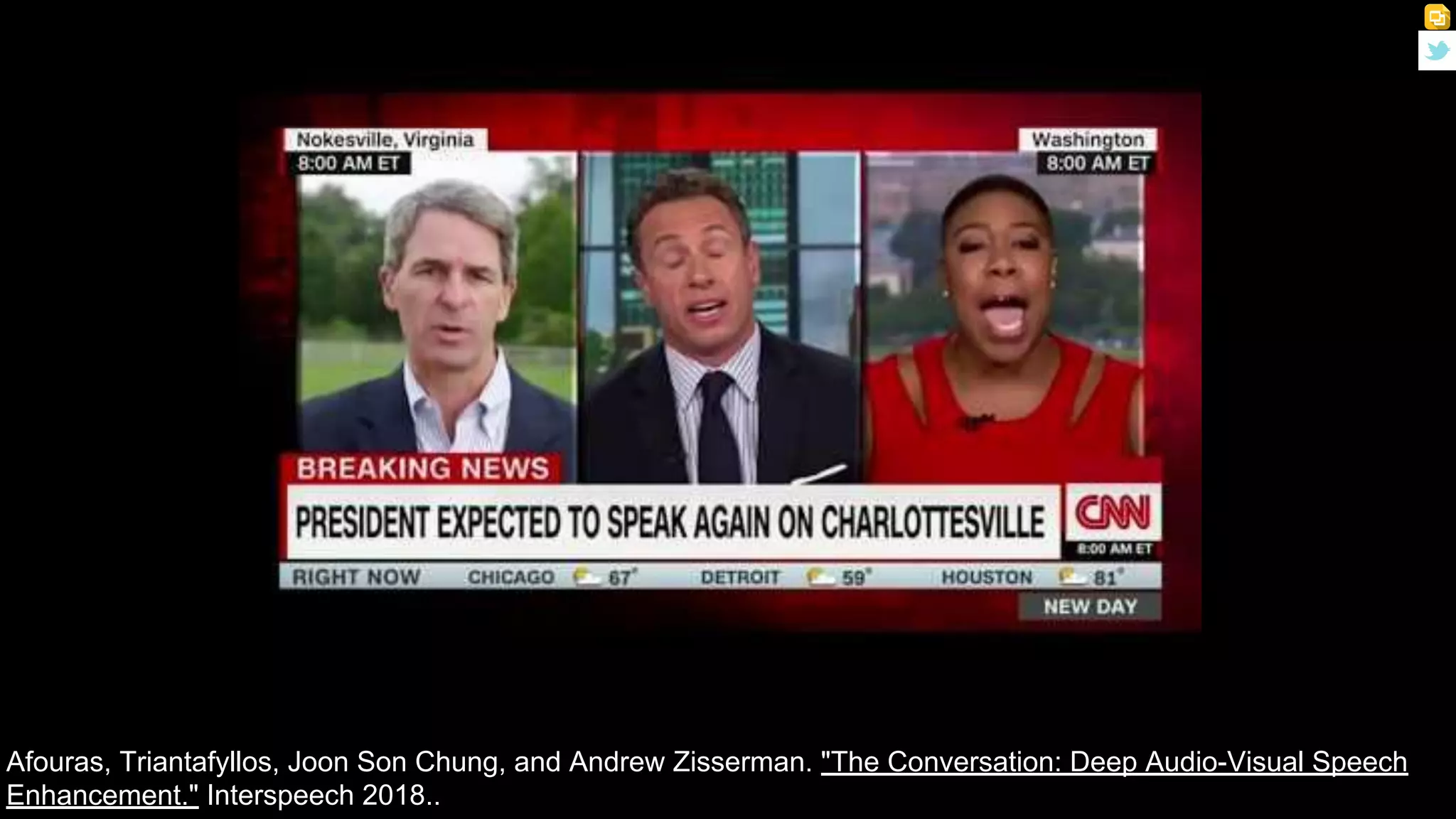
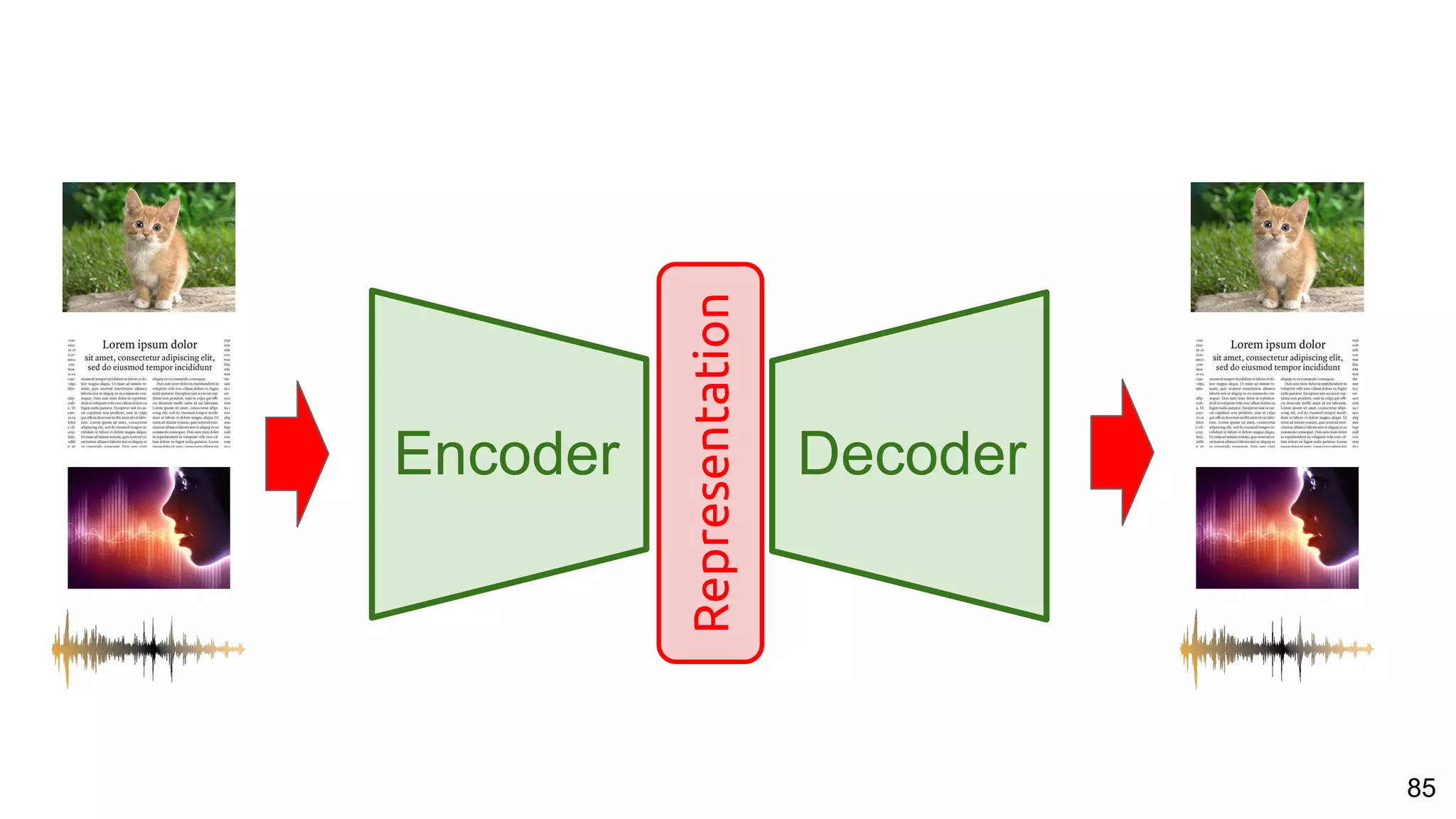



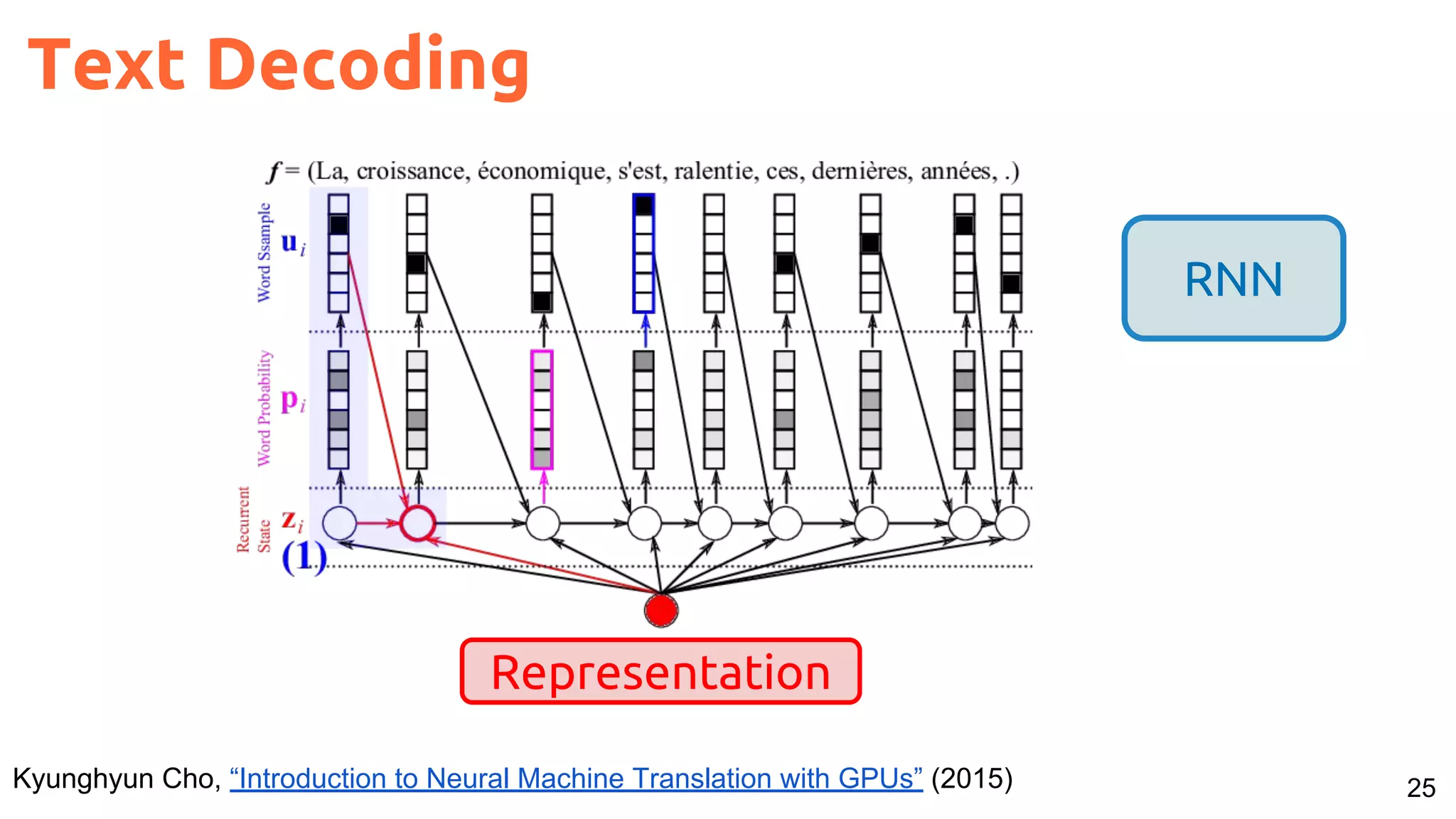
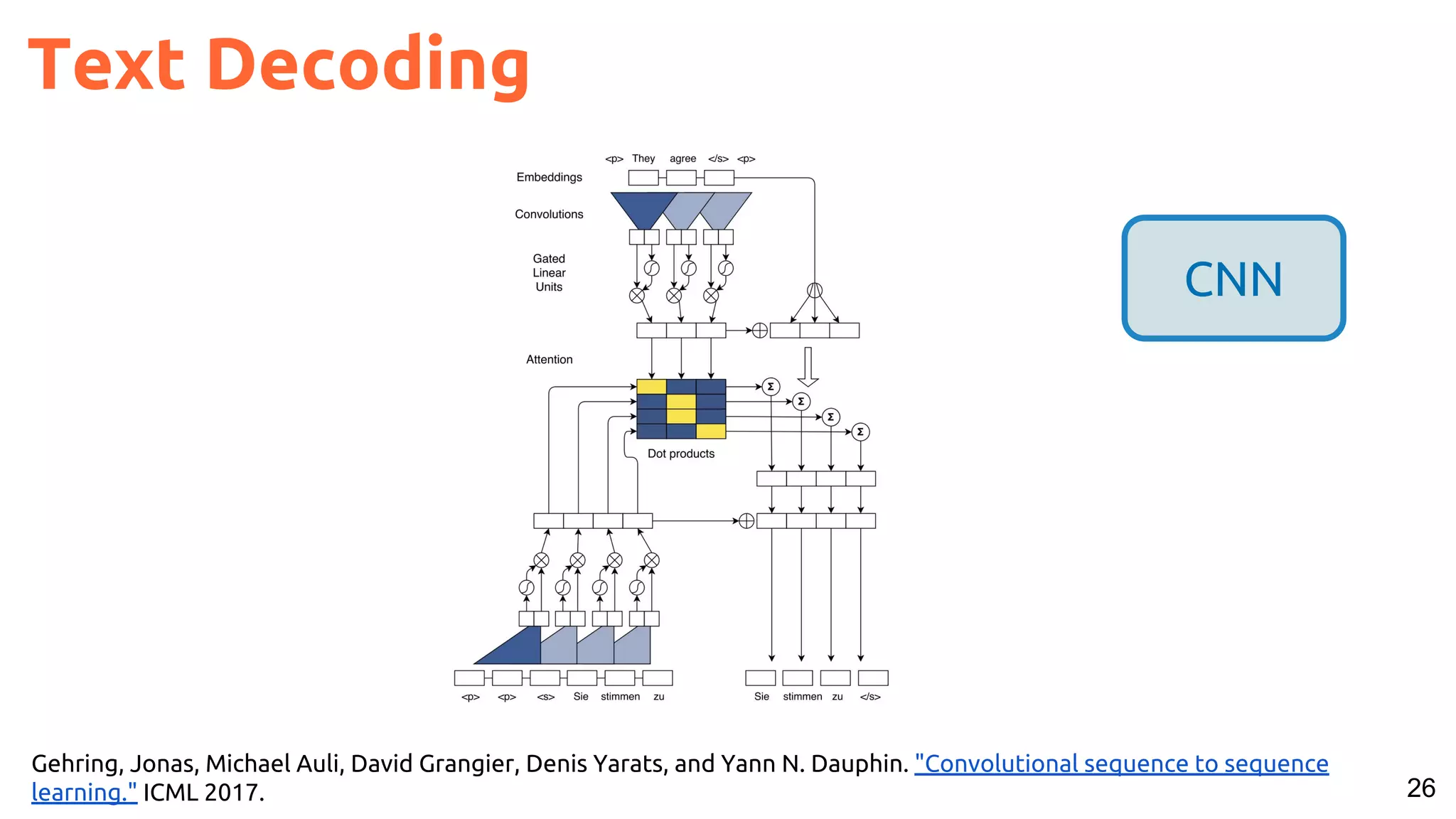
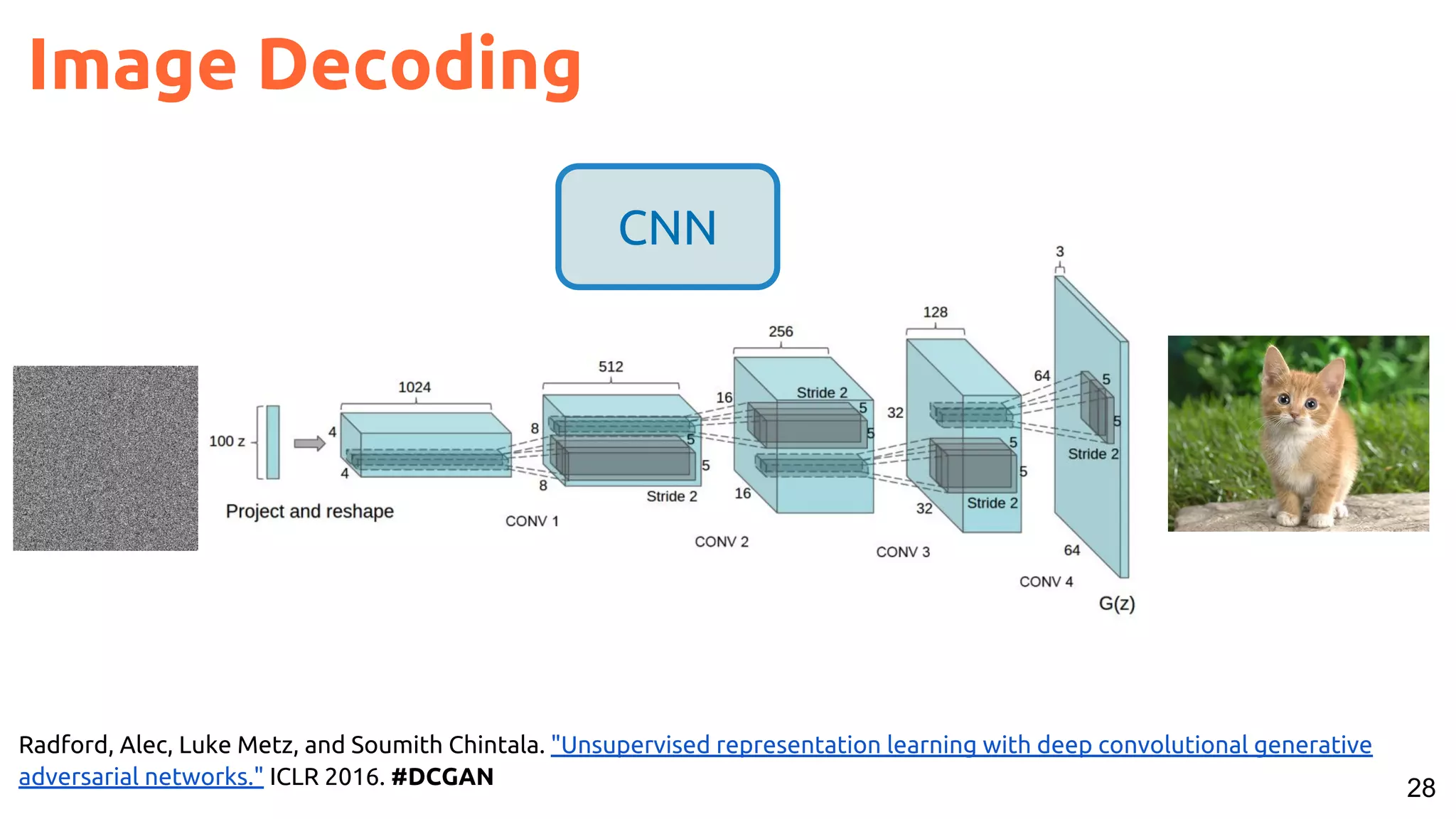
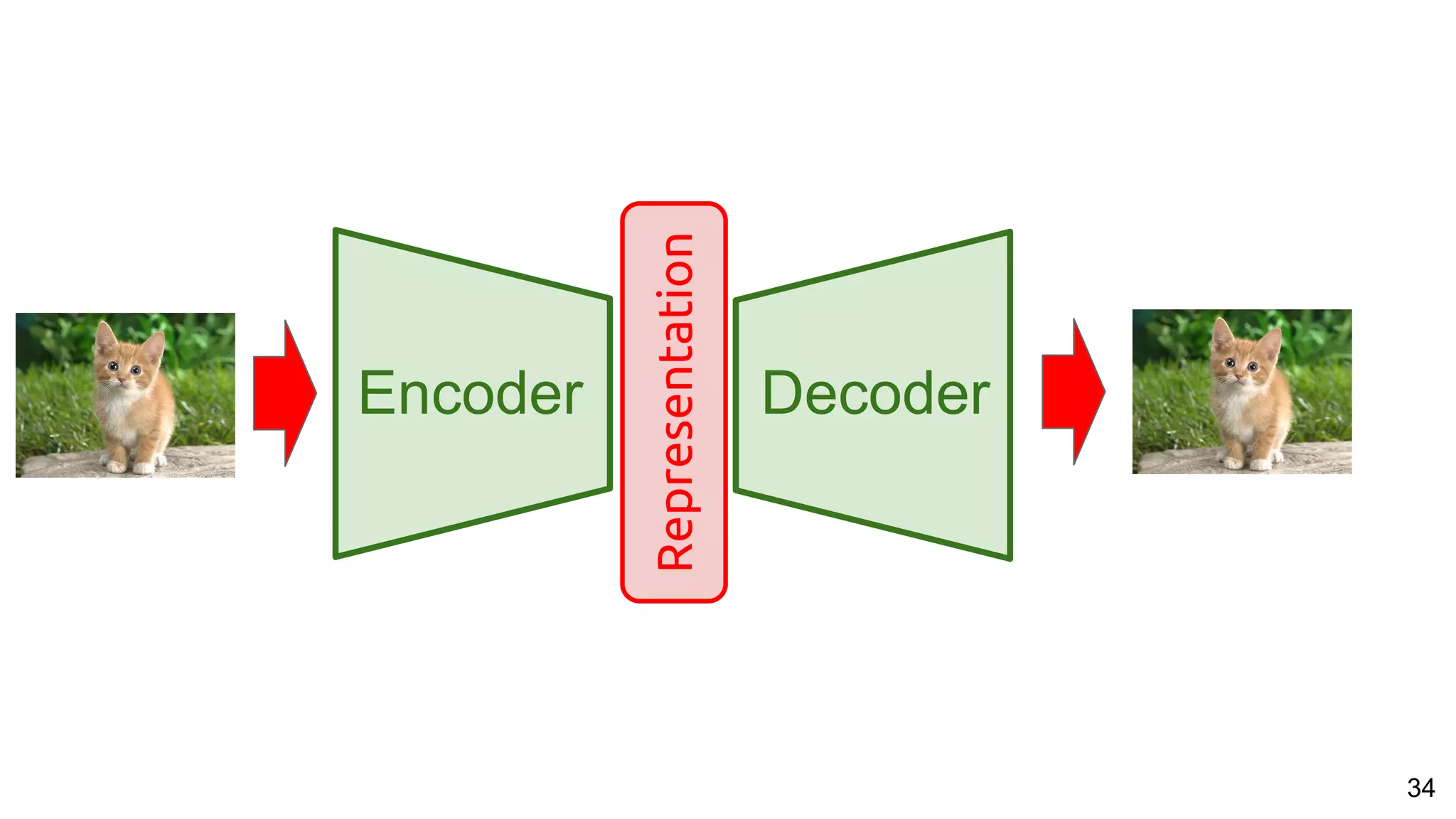
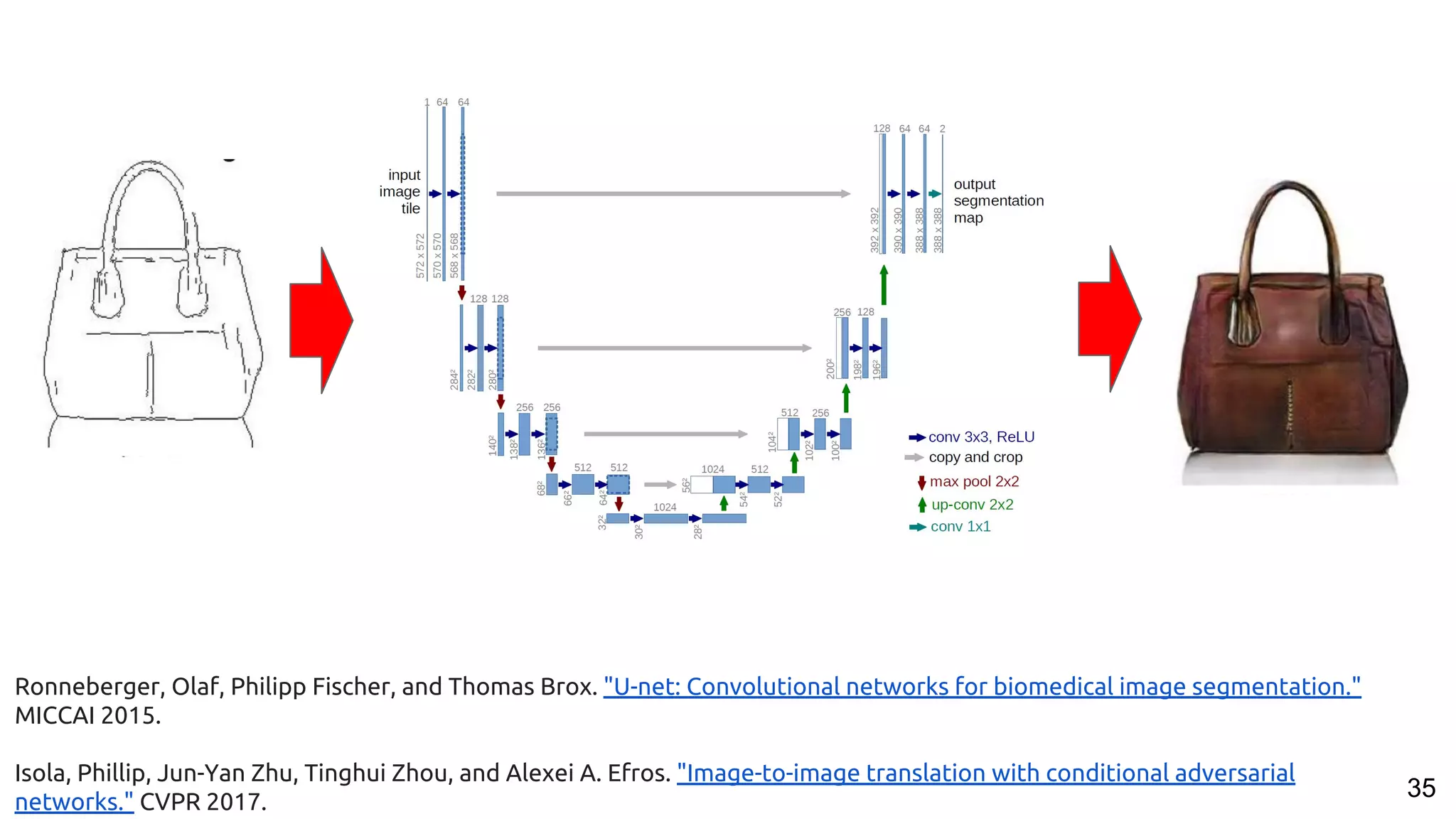
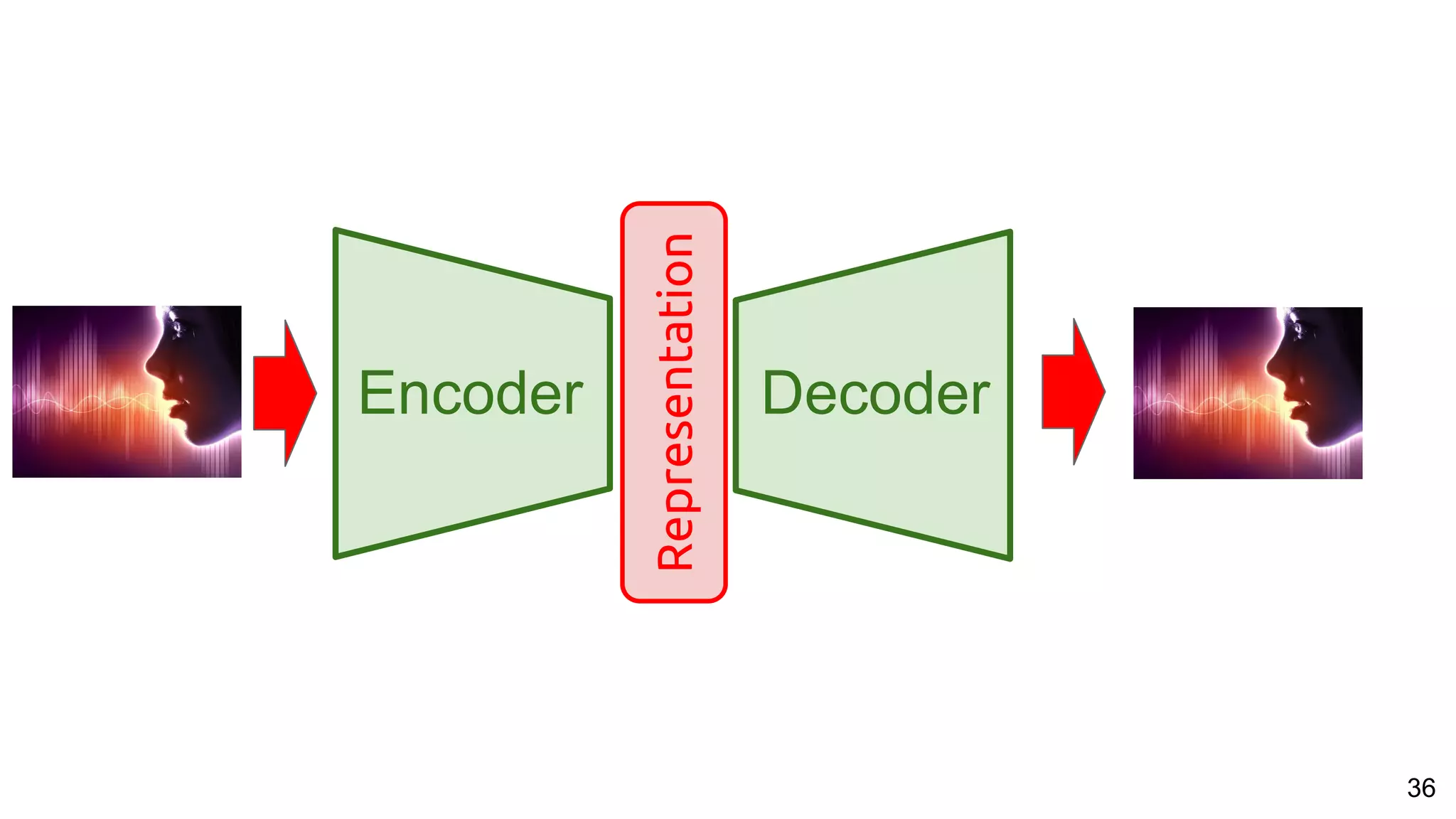
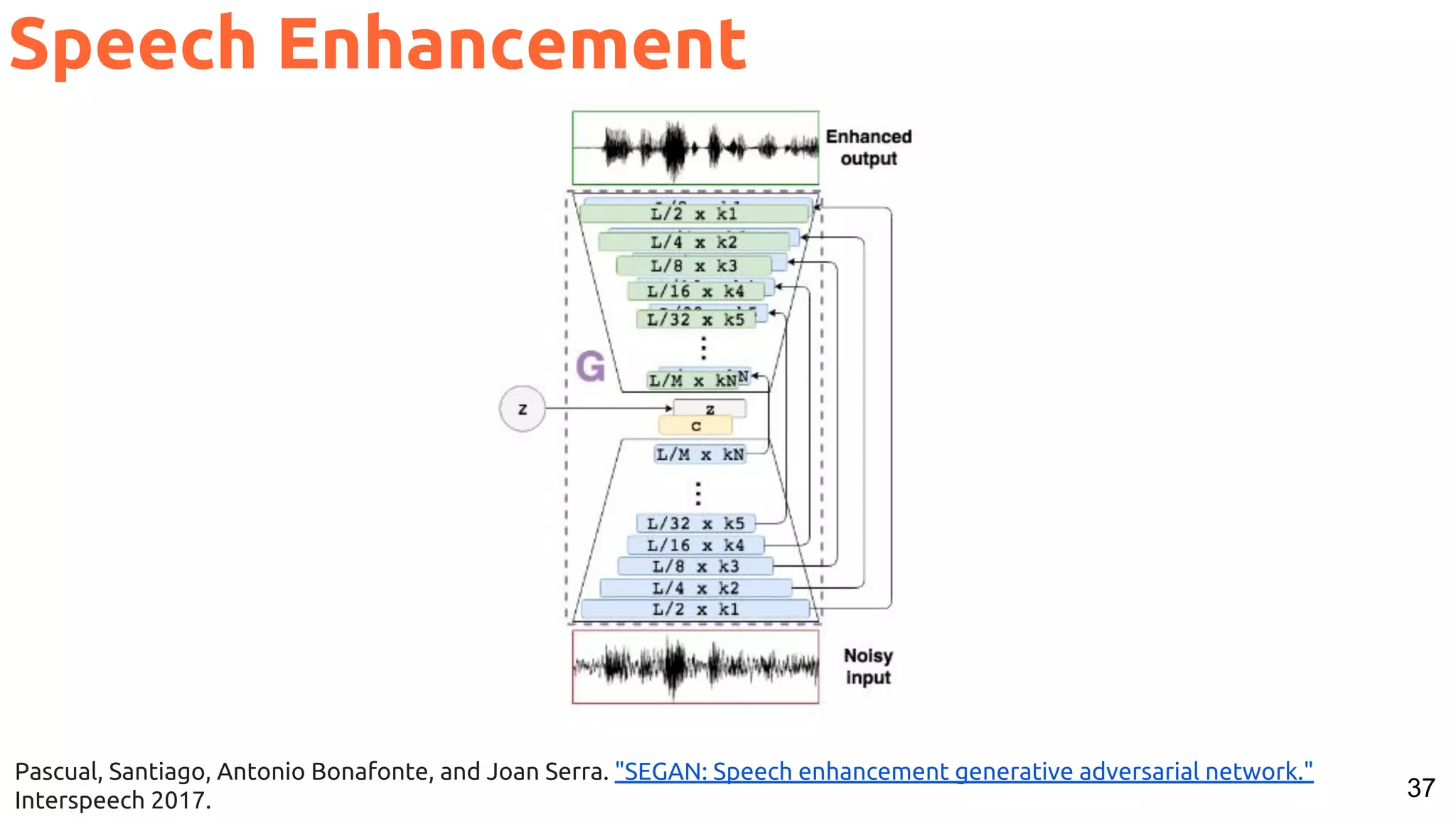
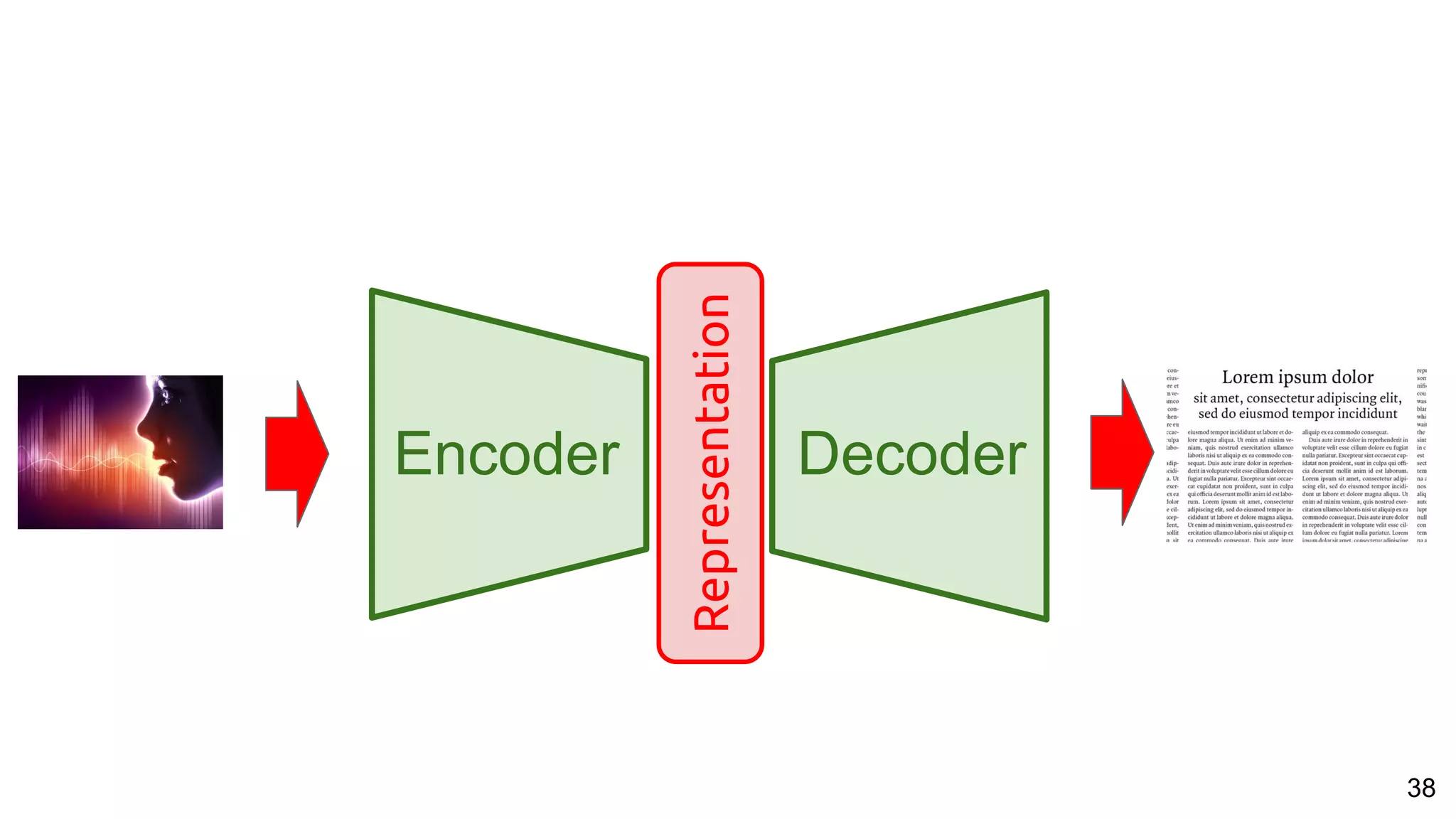
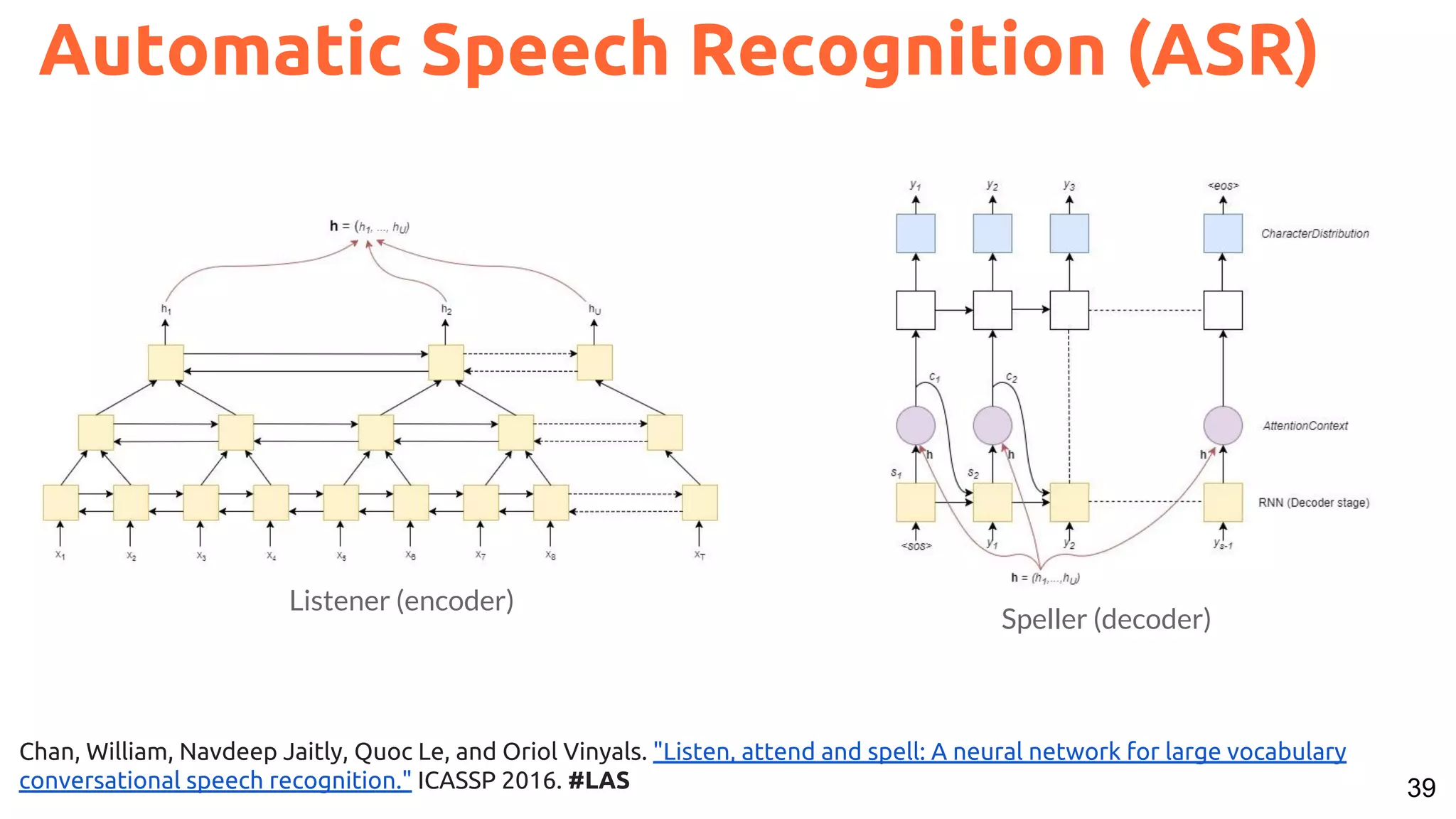
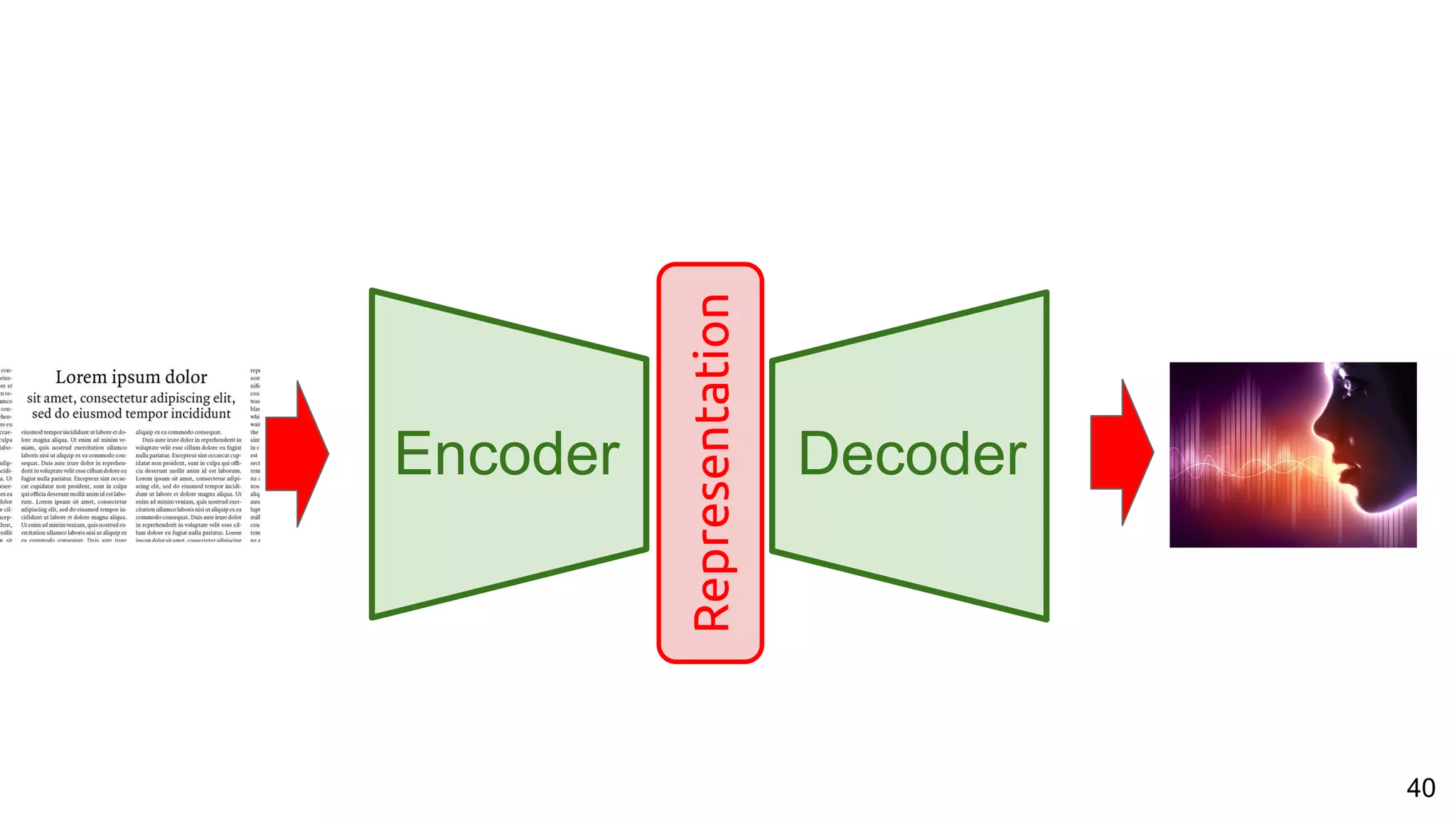
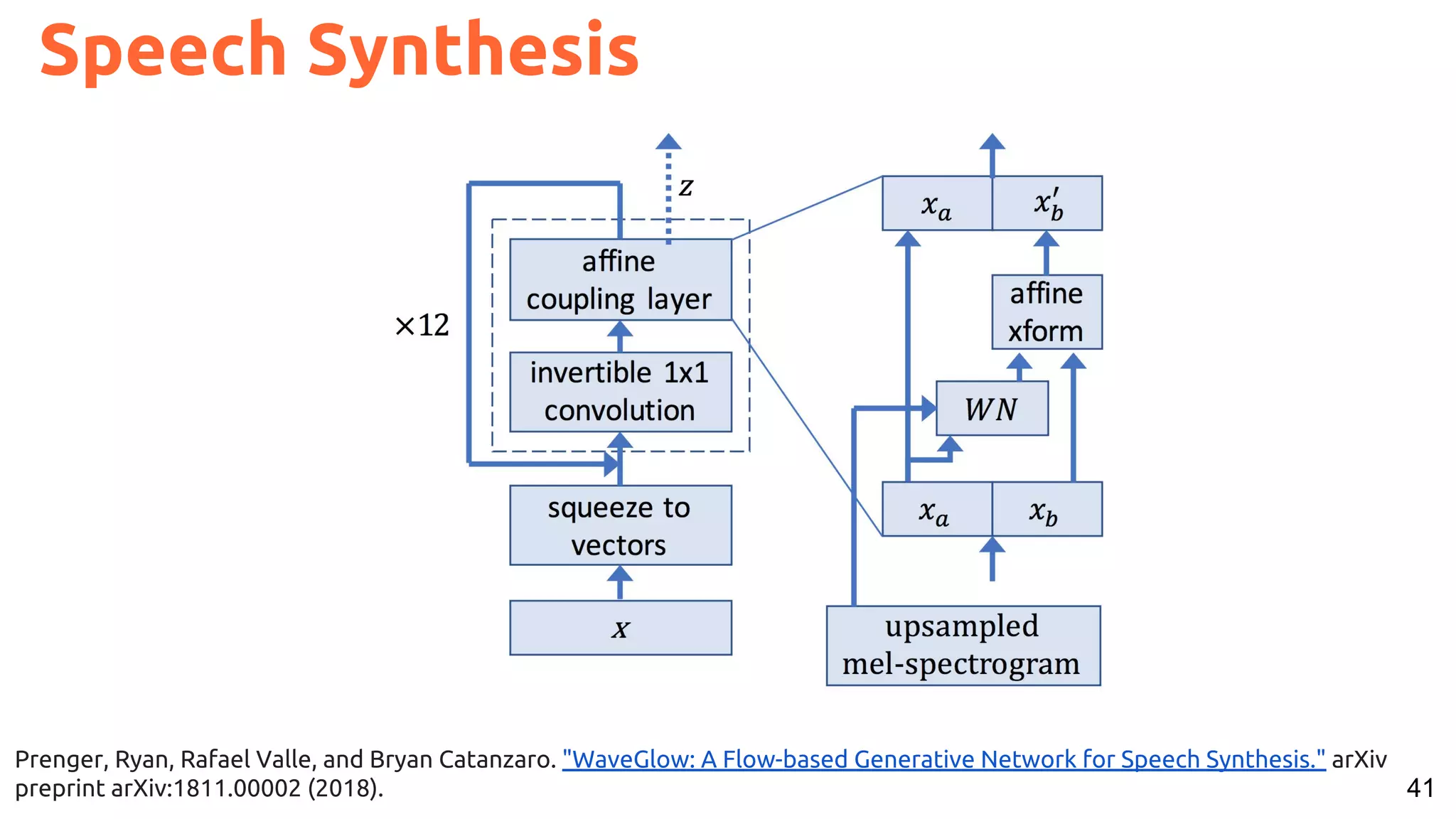
The document presents a talk on deep learning for multimedia by Xavier Giro-i-Nieto at an event in Barcelona, focusing on the integration of speech, vision, and text in various applications. It highlights different encoding and decoding techniques used in tasks like image classification, speech recognition, and translation, referencing significant research papers in the field. The talk emphasizes advances in cross-modal learning and representation for improving multimedia tasks.
































































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


