Introduction
● The mostof encoder-decoder architectures are equipped
with attention mechanism.
● But, human translators don’t reread previously translated
source text words. (It’s shown by the eye-tracking test)
● They believe “it may be unnecessary to look back at the
entire original source sequence at each step.”
● They proposed an alternative attention mechanism
○ Smaller computational time
4.
Attention [Bahdanau+ ICLR2015,Luong+ EMNLP2015]
● Attention mechanism aims to make the context vectors c.
○ s: encoder state, h: decoder state
○
● Computational time: O(D2
|S||T|)
○ D: state size of the encoder and decoder
○ |S| and |T| represents the length of the source and target, respectively.
○ If we use the Luong’s dot attention, computational time is O(D|S||T|)
○ Luong’s dot attention: hi
T
sj
5.
Memory-Based Attention Model(Proposed method)
● During encoding, they computed an attention matrix C.
○ size of C and W: K×D
○ K: the number of attention vectors
○ computational time: O(KD|S|)
● C is regarded as compact fixed-length memory.
6.
Memory-Based Attention Model(Proposed method)
● During decoding, they computed the context vector c.
○ They used C for computing the attention instead of encoder states.
● Total computational time: O(KD(|S| + |T|))
○ They expected their model to be faster than (O(D2
|S||T|))
○ For long sequences (|S| is large), this model will be faster than dot attention
● They used a sigmoid function instead of softmax for
calculating the attention scores.
7.
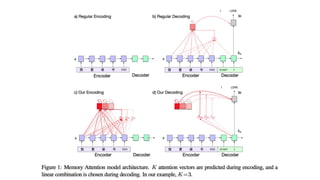
Position Encoding
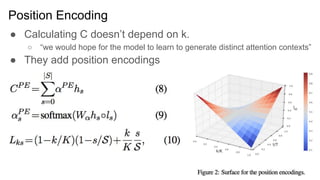
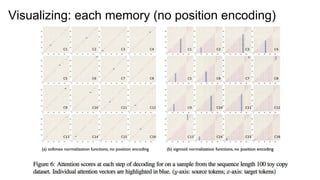
● CalculatingC doesn’t depend on k.
○ “we would hope for the model to learn to generate distinct attention contexts”
● They add position encodings
8.
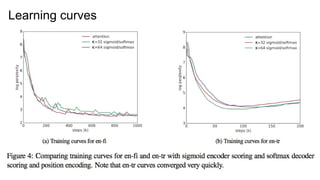
Experiment 1: Toycopying (like NTM[Graves+ 2014])
● Copying the random sequence.
○ Length: from 0 to {10, 50, 100, 200}
● Vocabulary: 20
● 2-layer, bi-directional LSTM (256 units)
● Dropout: 0.2
● Train : test = 100,000 : 1,000
○ batch size: 128
○ They trained for 200,000 steps.
● K40m × 1
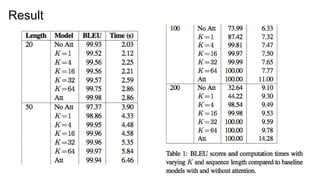
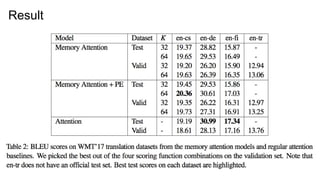
Result
● Vanilla enc-decis weak.
● The number of K depends on the data length.
● Decoding process becomes faster when the length of
sequence is larger.
● “Traditional attention may be representing the source with
redundancy and wasting computational resources.”
12.
Experiment 2: NeuralMachine Translation
● WMT’17
○ English-Czech (52M sentences)
○ English-German (5.9M sentences)
○ English-Finish (2.6M sentences)
○ English-Turkish (207K sentences)
○ Dev: newstest2015, Test: newstest2016 (not included en-tr)
○ Average length for the test data is 35.
● Hyperparameters
○ Vocabulary: 16,000 subwords (BPE)
○ hidden states: 512
○ Other parameters are the same as copy experiments’.
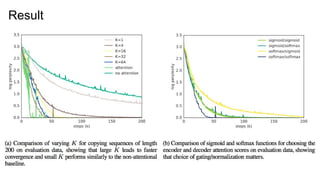
Discussion
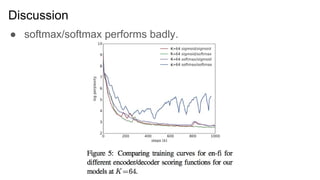
● “Our memoryattention model performs on-par with, or
slightly better, than the baseline model”
● Position encoding improves model performance.
● If we set the task to be K << T, we will get the good
performance by this model. (for example, summarization)
● Decoding time decreased.



![Attention [Bahdanau+ ICLR2015, Luong+ EMNLP2015]
● Attention mechanism aims to make the context vectors c.
○ s: encoder state, h: decoder state
○
● Computational time: O(D2
|S||T|)
○ D: state size of the encoder and decoder
○ |S| and |T| represents the length of the source and target, respectively.
○ If we use the Luong’s dot attention, computational time is O(D|S||T|)
○ Luong’s dot attention: hi
T
sj](https://image.slidesharecdn.com/emnlp2017-171122025333/85/EMNLP2017-Efficient-Attention-using-a-Fixed-Size-Memory-Representation-4-320.jpg)


![Experiment 1: Toy copying (like NTM[Graves+ 2014])
● Copying the random sequence.
○ Length: from 0 to {10, 50, 100, 200}
● Vocabulary: 20
● 2-layer, bi-directional LSTM (256 units)
● Dropout: 0.2
● Train : test = 100,000 : 1,000
○ batch size: 128
○ They trained for 200,000 steps.
● K40m × 1](https://image.slidesharecdn.com/emnlp2017-171122025333/85/EMNLP2017-Efficient-Attention-using-a-Fixed-Size-Memory-Representation-8-320.jpg)



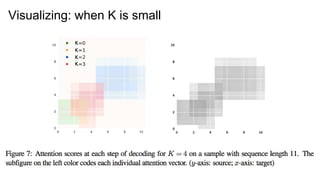


![所感(日本語ですみません)
● 性能がさほど変わらないのに速くなるのはいいこと
● [Luong+ EMNLP’15] のlocal attentionと比較してほしかった
○ local attention的なものを事前に計算しているようなもの?
○ Luongが共著なのに
● Position EncodingがないのにAttentionがばらけているのが謎
● 要約の方が向いていると思う](https://image.slidesharecdn.com/emnlp2017-171122025333/85/EMNLP2017-Efficient-Attention-using-a-Fixed-Size-Memory-Representation-21-320.jpg)























![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)

![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)








![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)








![[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...](https://cdn.slidesharecdn.com/ss_thumbnails/paclingpresen-191012011632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳](https://cdn.slidesharecdn.com/ss_thumbnails/shuronpresen-191012004831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading2018later-181107050738-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization](https://cdn.slidesharecdn.com/ss_thumbnails/naacl2018reading-180801082628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/reading0510-180511063343-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ACL2017読み会] What do Neural Machine Translation Models Learn about Morphology?](https://cdn.slidesharecdn.com/ss_thumbnails/acl2017-171011024754-thumbnail.jpg?width=640&height=640&fit=bounds)



![[EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp-170228052941-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...](https://cdn.slidesharecdn.com/ss_thumbnails/acl-161026074300-thumbnail.jpg?width=640&height=640&fit=bounds)















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



