Download as PDF, PPTX





![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
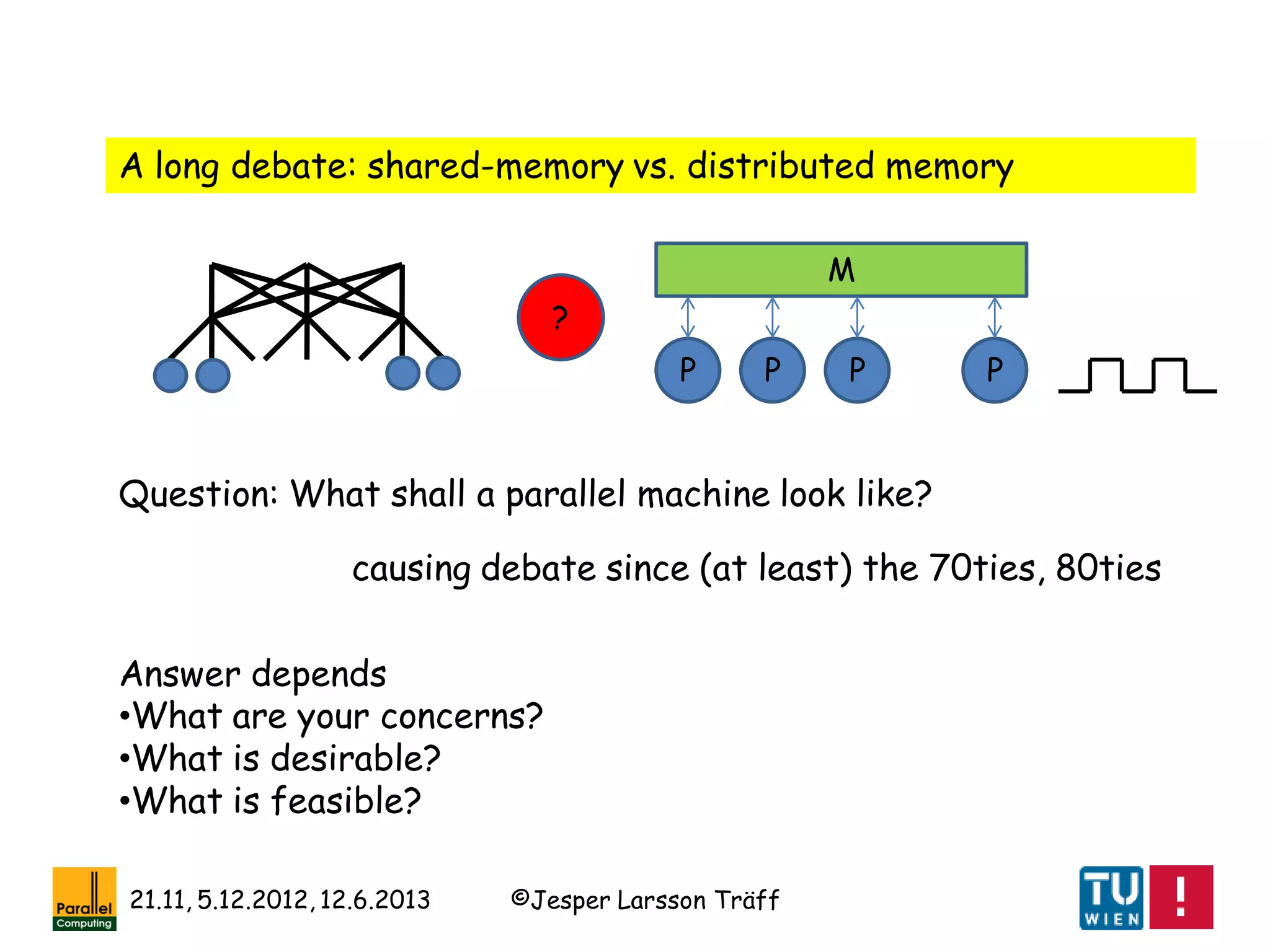
Hoare/Dijkstra:
Parallel programs shall be structured as collections of
communicating, sequential processes
Wyllie, Vishkin:
A parallel algorithm is like a collection of synchronized sequential
algorithms that access a common shared memory, and the machine
is a PRAM
[Fortune, Wyllie: Parallelism in Random Access Machines. STOC
1978: 114-118]
[Shiloach, Vishkin: Finding the Maximum, Merging, and Sorting in a
Parallel Computation Model. Jour. Algorithms 2(1): 88-102, 1981]
[C. A. R. Hoare: Communicating Sequential Processes. Comm. ACM
21(8): 666-677, 1978]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-7-2048.jpg)






![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
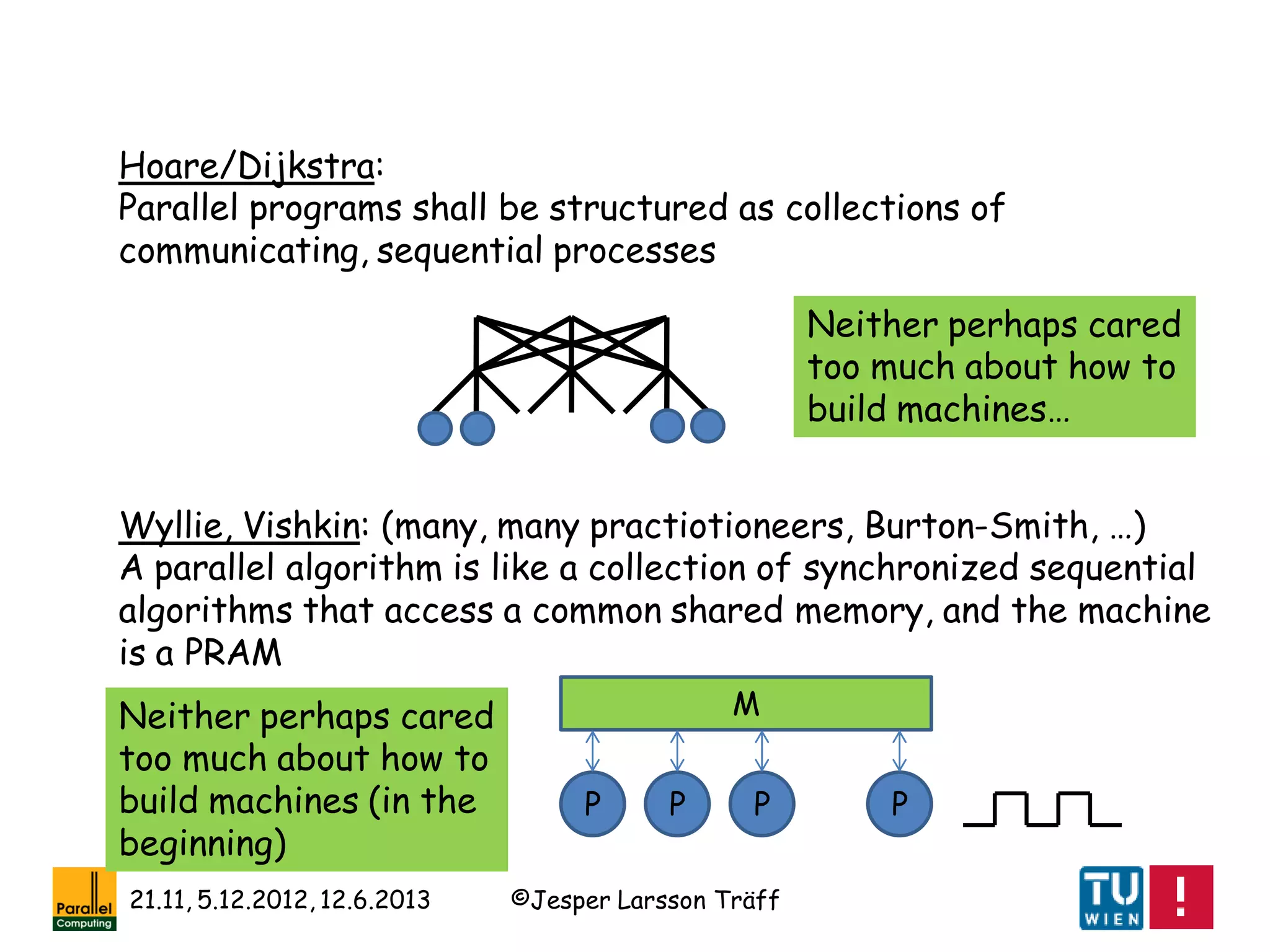
•Intel NX: send-receive message passing (non-blocking,
buffering?), tags(tag groups?), no group concept, some
collectives, weak encapsulation
•IBM EUI: point-to-point and collectives (more than in MPI),
group concept, high performance (??) [Snir et al.]
•IBM CCL: point-to-point and collectives, encapsulation
•Zipcode/Express: point-to-point, emphasis on library building
[Skjellum]
•PARMACS/Express: point-to-point, topological mapping [Hempel]
•PVM: point-to-point communication, some collective, virtual
machine abstraction, fault-tolerance
Message-passing interfaces/languages early 90ties](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-15-2048.jpg)
![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Some odd men out
•Linda: tuple space get/put – a first PGAS approach?
•Active messages; seems to presuppose an SPMD model?
•OCCAM: too strict CSP-based, synchronous message passing?
•PVM: heterogeneous systems, fault-tolerance, …
[Hempel, Hey, McBryan, Walker: Special Issue – Message Passing
Interfaces. Parallel Computing 29(4), 1994]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-16-2048.jpg)
![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Standardization: the MPI Forum and MPI 1.0
[Hempel, Walker: The emergence of the MPI message passing standard
for parallel computing. Computer Standards & Interfaces, 21: 51-62,
1999]
A standardization effort was started early 1992; key Dongarra,
Hempel, Hey, Walker
Goal: to come out within a few years time frame with a
standard for message-passing parallel programming; building on
lessons learned from existing interfaces/languages
•Not a research effort (as such)!
•Open to participation from all interested parties](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-17-2048.jpg)



![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Take note:
The MPI 1 standardization process was followed hand-in-hand
by a(n amazingly good) prototype implementation: mpich from
Argonne National Laboratory (Gropp, Lusk, …)
[W. Gropp, E. L. Lusk, N. E. Doss, A. Skjellum: A High-Performance,
Portable Implementation of the MPI Message Passing Interface
Standard. Parallel Computing 22(6): 789-828, 1996]
Other parties, vendors could build on this implementation (and
did!), so that MPI was quickly supported on many parallel
systems](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-21-2048.jpg)






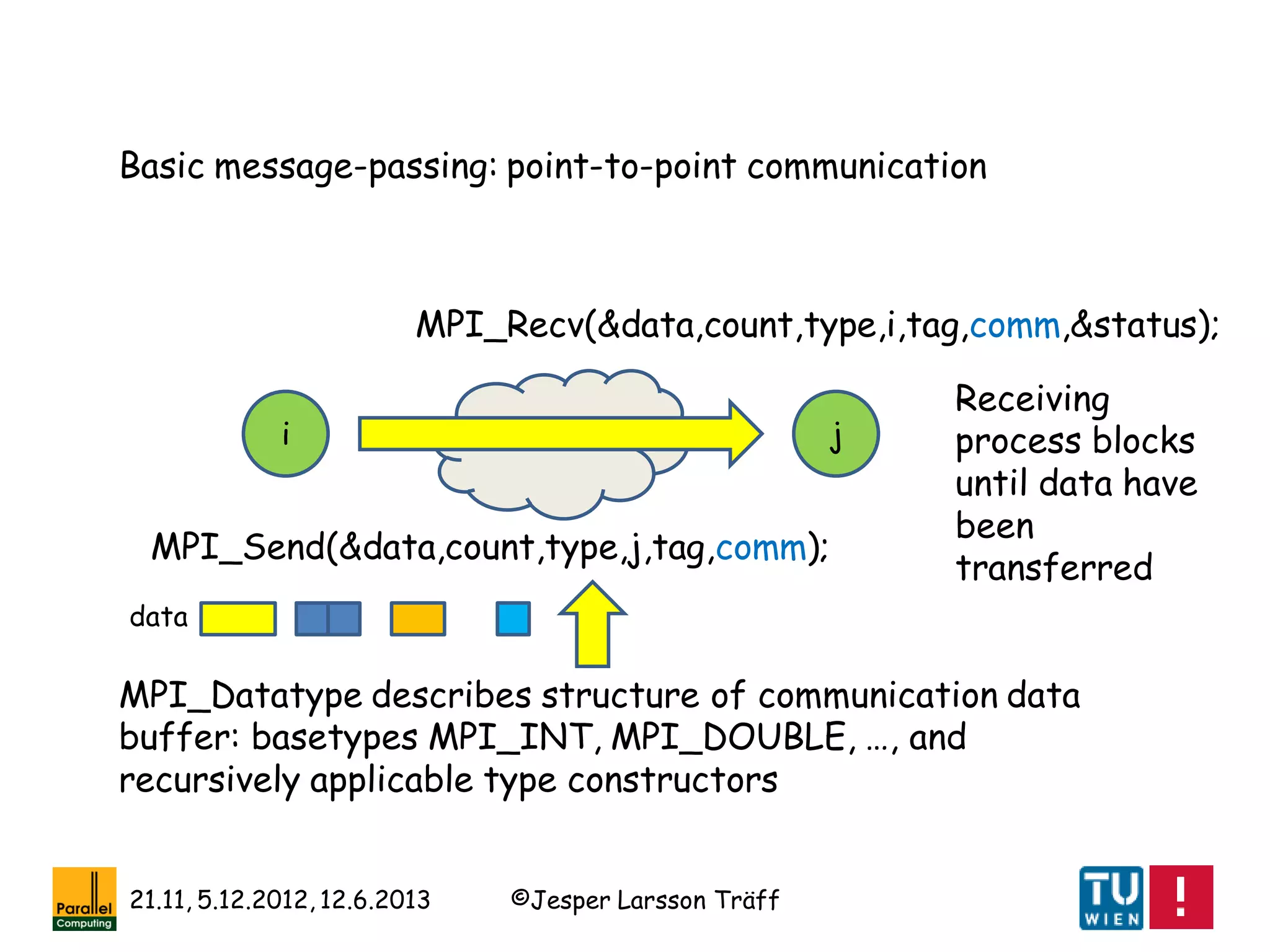








![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Collective communication: patterns of process communication
Fundamental, well-studied, and useful parallel communication
patterns captured in MPI 1.0 as socalled collective
operations
Collectives capture complex patterns, often with non-trivial
algorithms and implementations: delegate work to library
implementer, save work for the application programmer
Conjecture: well-implemented collective operations contributes
significantly towards application „performance portability“
[Träff, Gropp, Thakur: Self-Consistent MPI Performance Guidelines.
IEEE TPDS 21(5): 698-709, 2010]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-39-2048.jpg)
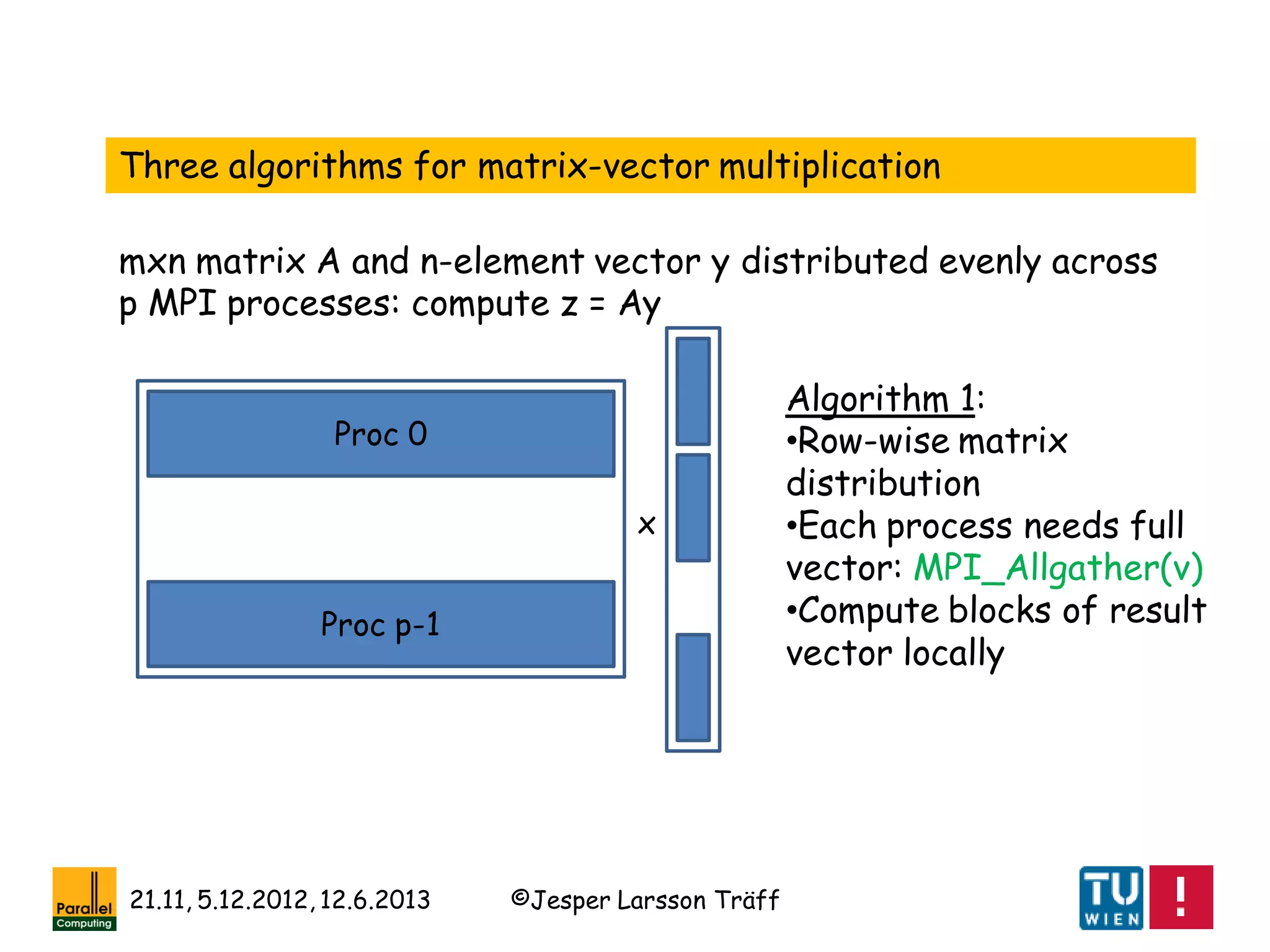
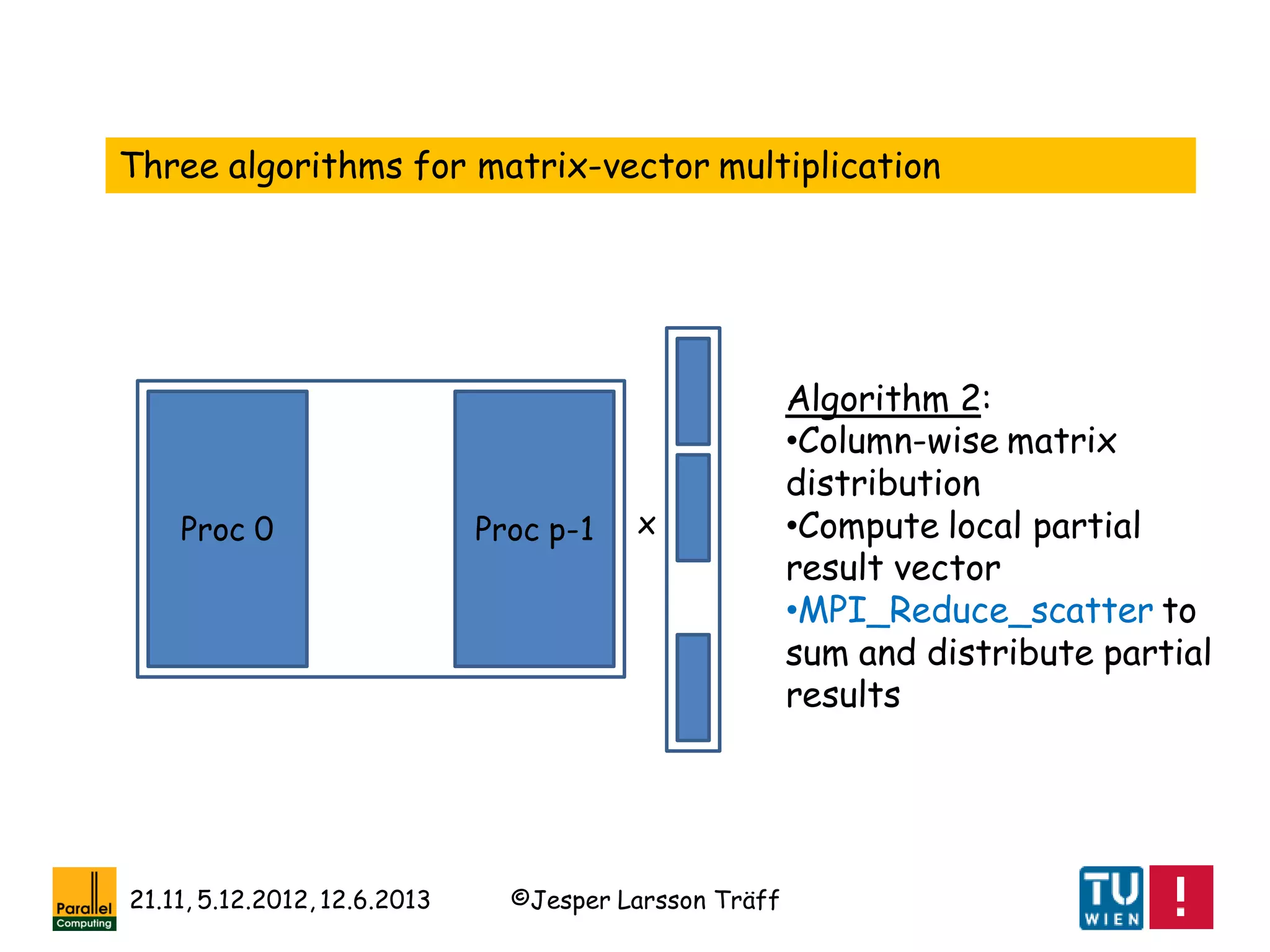
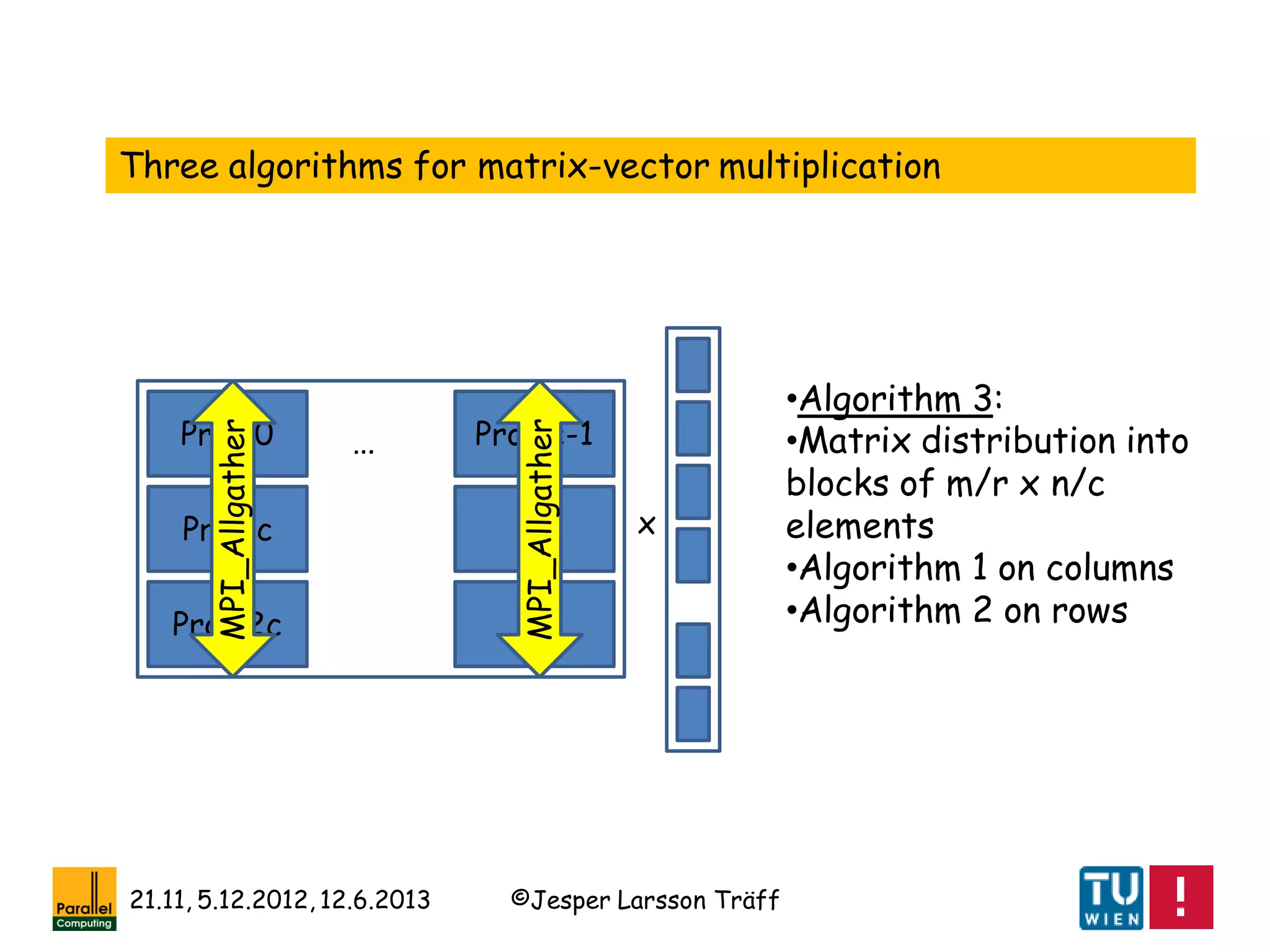

![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
[R. A. van de Geijn, J. Watts: SUMMA: scalable
universal matrix multiplication algorithm. Concurrency -
Practice and Experience 9(4): 255-274 (1997)]
[Ernie Chan, Marcel Heimlich, Avi Purkayastha, Robert A. van de Geijn:
Collective communication: theory, practice, and experience. Concurrency
and Computation: Practice and Experience 19(13): 1749-1783 (2007)]
[F. G. van Zee, E. Chan, R. A. van de Geijn, E. S.
Quintana-Ortí, G. Quintana-Ortí: The libflame Library
for Dense Matrix Computations. Computing in Science
and Engineering 11(6): 56-63 (2009)]
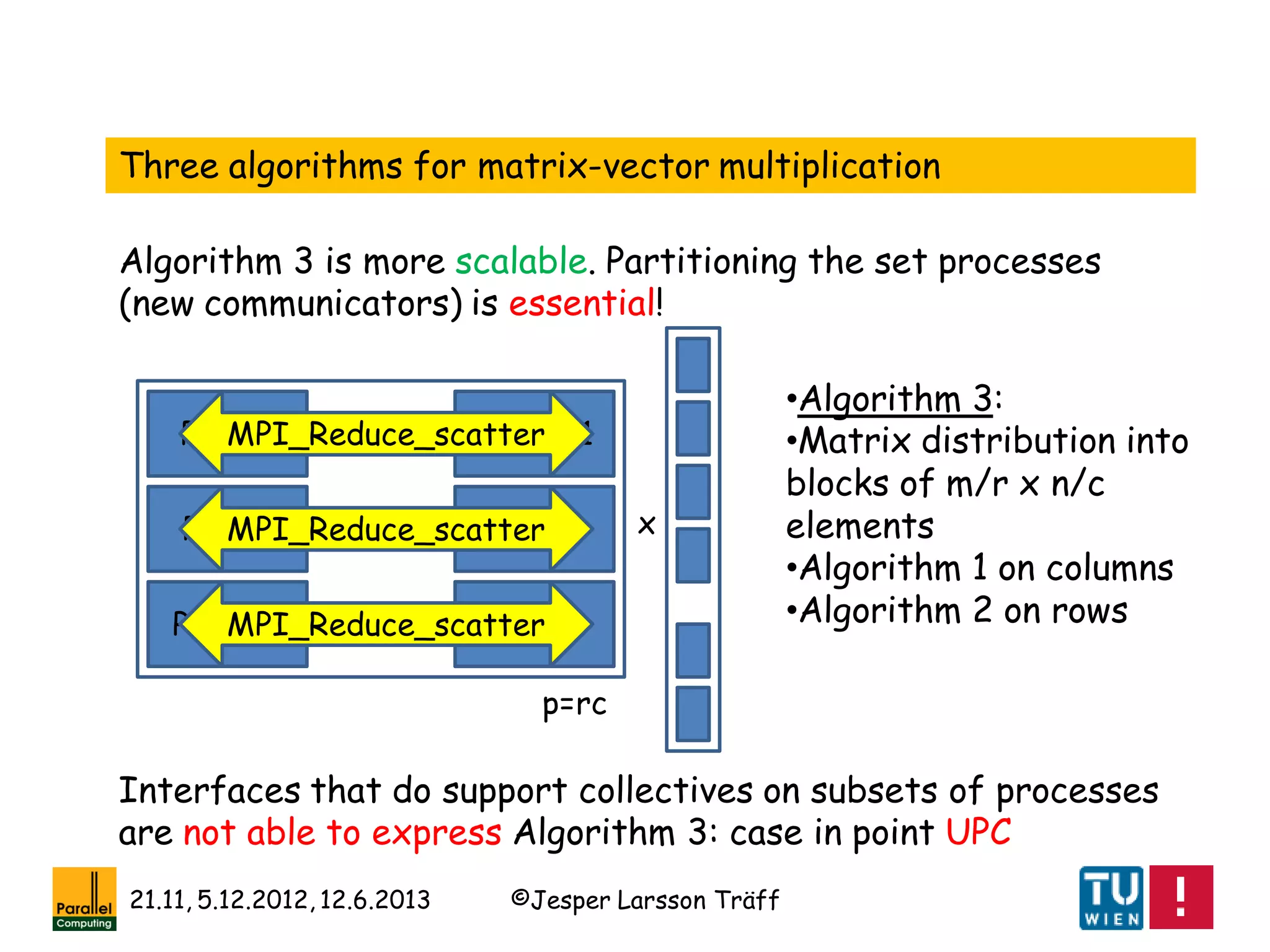
A lesson: Dense Linear Algebra and (regular) collective
communication as offered by MPI go hand in hand
Note: Most of these collective communication algorithms are a
factor 2 off from best possible](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-45-2048.jpg)
![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Another example: Integer (bucket) sort
n integers in a given range [0,R-1], distributed evenly across p
MPI processes: m= n/p integers per process
0 1 3 0 0 2 0 1 …
4
2
1
3
Step 1: bucket sort locally, let B[i] number of elements with key i
Step 2: MPI_Allreduce(B,AllB,R,MPI_INT,MPI_SUM,comm);
Step 3: MPI_Exscan(B,RelB,R,MPI_INT,MPI_SUM,comm);)
B =A =
Now: Element A[j] needs to go to position AllB[A[j]-1]+RelB[A[j]]+j’](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-46-2048.jpg)
![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Another example: Integer (bucket) sort
n integers in a given range [0,R-1], distributed evenly across p
MPI processes: m= n/p integers per process
0 1 3 0 0 2 0 1 …
4
2
1
3
Step 4: compute number of elements to be sent to each other
process, sendelts[i], i=0,…,p-1
B =A =
Step 5:
MPI_Alltoall(sendelts,1,MPI_INT,recvelts,1,MPI_INT,comm);
Step6: redistribute elements
MPI_Alltoallv(A,sendelts,sdispls,…,comm);](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-47-2048.jpg)





![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
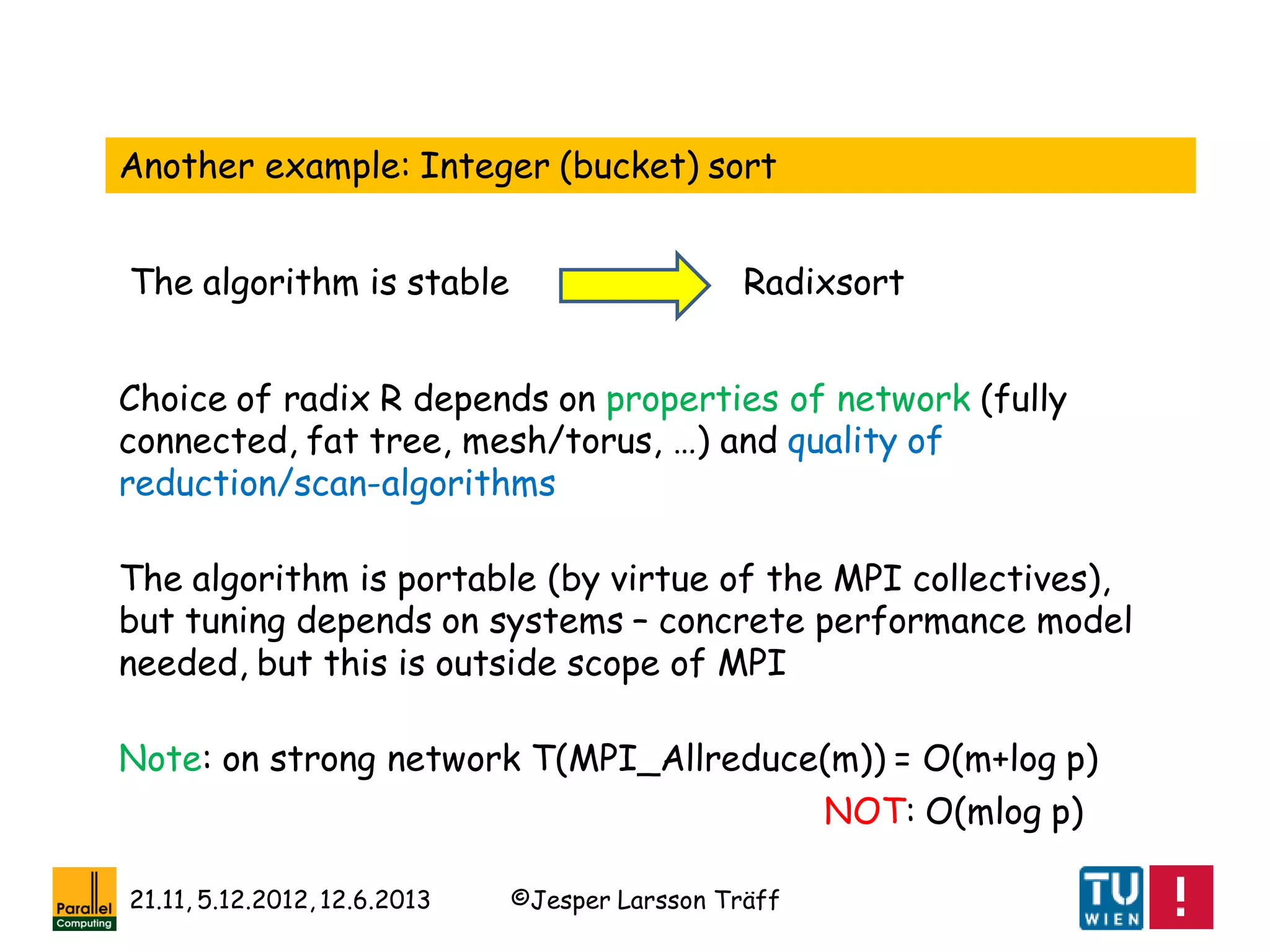
Answer is “yes” to both questions
Example:
Irregular collective alltoall communication (each process
exchange some data with each other process)
MPI_Alltoallw(sendbuf,sendcounts[],senddispl[],sendtypes[],
recvbuf,recvcounts[],recvdispls[],recvtypes[],…)
takes 6 p-sized arrays (4- or 8-byte integers) ~ 5MBytes, 10%
of memory on BlueGene/L
Sparse usage pattern: often each process exchanges with
only few neighbors, so most send/recvcounts[i]=0
MPI_Alltoallw is non-scalable
Pi](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-54-2048.jpg)
![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Experiment:
sendcounts[i]=0, recvcounts[i] =0 for all processes and all i
Argonne Natl. Lab
BlueGene/L
Entails no communication
[Balaji, …, Träff : MPI on millions of cores. Parallel Processing Letters
21(1): 45-60, 2011]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-55-2048.jpg)





![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
1. Dynamic process management:
MPI 1.0 was completely static: a communicator cannot change
(design principle: no MPI object can change; new objects can
be created and old ones destroyed), so the number of
processes in MPI_COMM_WORLD cannot change: therefore
not possible to add or remove processes from a running
application
What if a process (in a communicator) dies? The fault-
tolerance problem
If implementation does not die, it might be possible to
program around/isolate faults using MPI 1.0 error handlers
and inter-communicators
[W. Gropp, E. Lusk: Fault Tolerance in Message Passing Interface
Programs. IJHPCA 18(3): 363-372, 2004]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-61-2048.jpg)







![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Quiet years: 1997-2006
No standardization activity from 1997
MPI 2.0 implementations
•Fujitsu (claim) 1999
•NEC 2000
•mpich 2004
•OpenMPI 2005
•LAM/MPI 2005(?)
•…
Ca. 2006 most/many implementations support mostly full MPI 2.0
Implementations evolved and improved; MPI was an interesting
topic to work on, good MPI work was/is acceptable to all parallel
computing conferences (SC, IPDPS, ICPP, Euro-Par, PPoPP, SPAA)
[J. L.Träff, H. Ritzdorf, R. Hempel:
The Implementation of MPI-2 One-
Sided Communication for the NEC
SX-5. SC 2000]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-69-2048.jpg)

![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
[Thanks to Xavier Vigouroux, Vienna 2012]
Bonn 2006: discussions („Open Forum“)
on restarting MPI Forum starting](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-71-2048.jpg)

![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
Some MPI 2.2 features
•Addressing scalability problems: new topology interface,
application communication graph is specified in a distributed
fashion
•Library building: MPI_Reduce_local
•Missing function: regular MPI_Reduce_scatter_block
•More flexible MPI_Comm_create (more in MPI 3.0:
MPI_Comm_split_type)
•New datatypes, e.g. MPI_AINT
[T. Hoefler, R. Rabenseifner, H. Ritzdorf, B. R. de Supinski,
R. Thakur, J. L. Träff: The scalable process topology
interface of MPI 2.2. Concurrency and Computation: Practice
and Experience 23(4): 293-310, 2011]](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-73-2048.jpg)





![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
2. Sparse collectives
Addresses scalability problem of irregular collectives.
Neighborhood specified with topology functionality
MPI_Neighbor_allgather(…,comm);
MPI_Neighbor_allgatherv(…,comm);
MPI_Neighbor_alltoall(…,comm);
MPI_Neighbor_alltoallv(…,comm);
MPI_Neighbor_alltoallw(…,comm);
Pi
and corresponding non-blocking versions
[T. Hoefler, J. L. Träff: Sparse collective operations for MPI. IPDPS
2009]
Will users take up? Optimization potential?](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-80-2048.jpg)
![©Jesper Larsson Träff21.11, 5.12.2012, 12.6.2013
[Hoefler, Dinan, Buntinas, Balaji, Barrett, Brightwell, Gropp, Kale,
Thakur: Leveraging MPI‘s one-sided communication for shared-memory
programming. EuroMPI 2012, LNCS 7490, 133-141, 2012]
3. One-sided communication
Model extension for better performance on hybrid/shared
memory systems
Atomic operations (lacking in MPI 2.0 model)
Per operation local completion, MPI_Rget, MPI_Rput, … (but
only for passive synchronization)](https://image.slidesharecdn.com/mpihistory-1-130621122847-phpapp01/75/MPI-History-81-2048.jpg)





The document discusses the history and development of the MPI standard for parallel programming. It describes how MPI was developed in the early 1990s to create a common standard for message passing programming that could unite the various proprietary interfaces that existed at the time. The first MPI standard was released in 1994 after several years of development and input from vendors, national labs, and researchers. MPI was quickly adopted due to a reference implementation and its ability to provide a portable abstraction while allowing for high-performance implementations.


















![What is [Open] MPI?](https://cdn.slidesharecdn.com/ss_thumbnails/test-1230829557420508-1-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














