Downloaded 41 times


















![Two complimentary systems
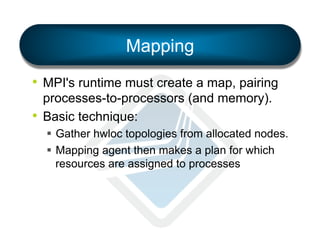
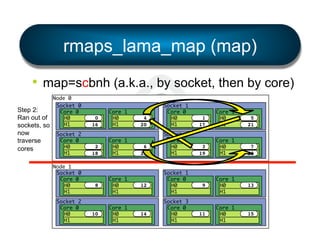
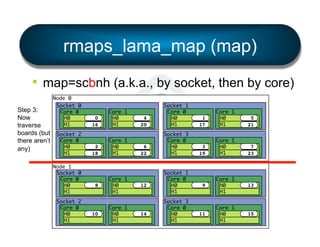
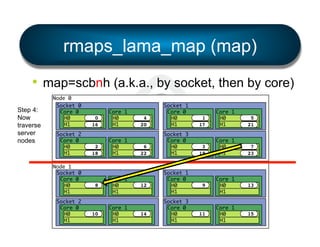
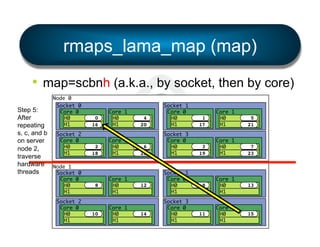
• Simple
§ mpirun --bind-to [ core | socket | … ] …
§ mpirun --by[ node | slot | … ] …
§ …etc.
• Flexible
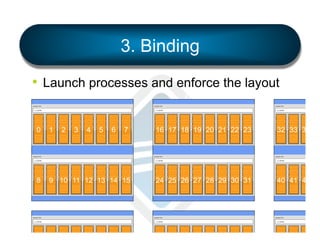
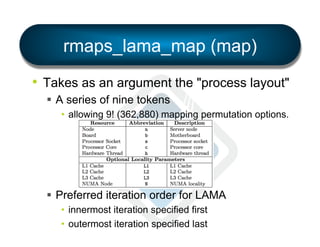
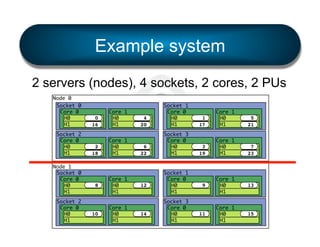
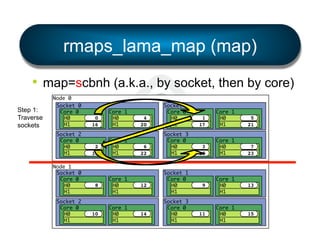
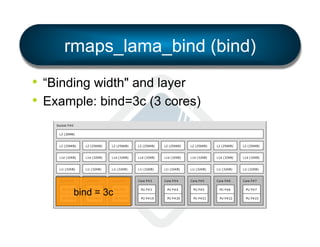
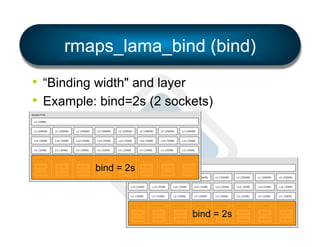
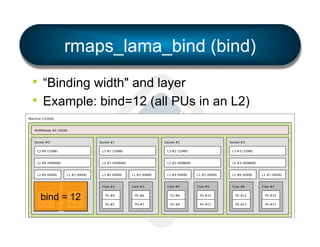
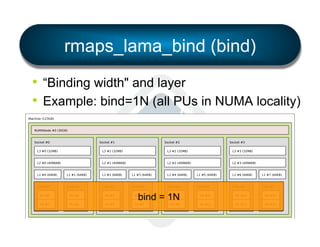
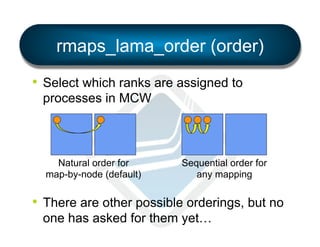
§ LAMA: Locality Aware Mapping Algorithm](https://image.slidesharecdn.com/general-ompi-talk-pdfable-131108104836-phpapp01/85/Open-MPI-Parallel-Computing-Life-the-Universe-and-Everything-27-320.jpg)










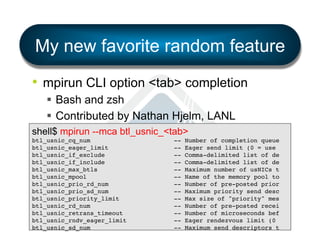
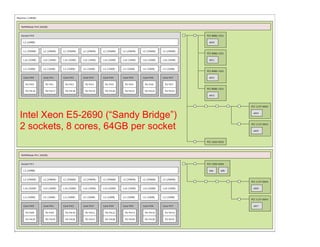
![Report bindings
• Displays prettyprint representation of the
binding actually used for each process.
§ Visual feedback = quite helpful when exploring
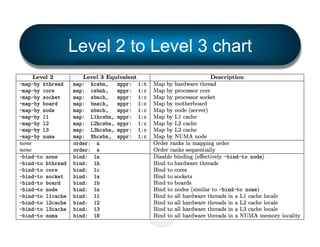
mpirun -np 4 --mca rmaps lama --mca rmaps_lama_bind
1c --mca rmaps_lama_map nbsch --mca rmaps_lama_mppr
1:c --report-bindings hello_world!
MCW
MCW
MCW
MCW
rank
rank
rank
rank
0
1
2
3
bound
bound
bound
bound
to
to
to
to
socket
socket
socket
socket
0[core
1[core
0[core
1[core
0[hwt
8[hwt
1[hwt
9[hwt
0-1]]:
0-1]]:
0-1]]:
0-1]]:
[BB/../../../../../../..][../../../../../../../..]!
[../../../../../../../..][BB/../../../../../../..]!
[../BB/../../../../../..][../../../../../../../..]!
[../../../../../../../..][../BB/../../../../../..]!](https://image.slidesharecdn.com/general-ompi-talk-pdfable-131108104836-phpapp01/85/Open-MPI-Parallel-Computing-Life-the-Universe-and-Everything-61-320.jpg)



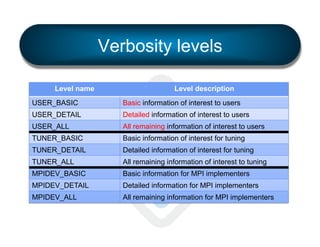
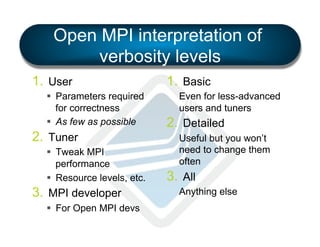
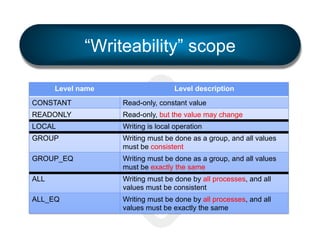
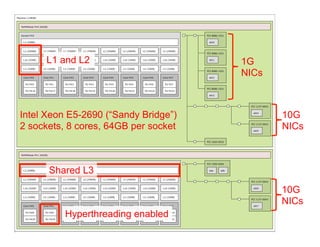
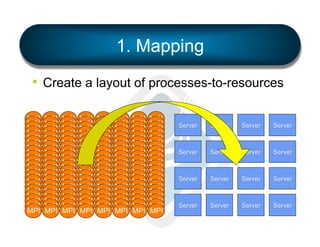
The document discusses the development and features of Open MPI, a parallel computing implementation founded in 2003. It highlights updates on releases, MPI conformances, and new features in the MPI-3 standard, focusing on process affinity, improved support for various runtime systems, and new interfaces for performance and control variables. Additionally, it addresses process placement strategies and launching frameworks for MPI applications.































![What is [Open] MPI?](https://cdn.slidesharecdn.com/ss_thumbnails/test-1230829557420508-1-thumbnail.jpg?width=640&height=640&fit=bounds)















































