Downloaded 58 times




![ExampleArray X is a pointer to an array of integers (4-bytes each) located at address 0x00001232A thread wants to access the data at X[0]inttmp = X[0];0x0000123200x0000123612X0x000012323...4560x000012487....4Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD © 2011](https://image.slidesharecdn.com/lec06memory-110829103051-phpapp02/85/Lec06-memory-4-320.jpg)


![Coalescing Memory AccessesTo fully utilize the bus, GPUs combine the accesses of multiple threads into fewer requests when possibleConsider the following OpenCL kernel code:Assuming that array X is the same array from the example, the first 16 threads will access addresses 0x00001232 through 0x00001272If each request was sent out individually, there would be 16 accesses total, with 64 useful bytes of data and 448 wasted bytesNotice that each access in the same 32-byte range would return exactly the same data inttmp = X[get_global_id(0)]; 7Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD © 2011](https://image.slidesharecdn.com/lec06memory-110829103051-phpapp02/85/Lec06-memory-7-320.jpg)







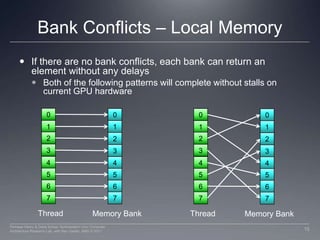
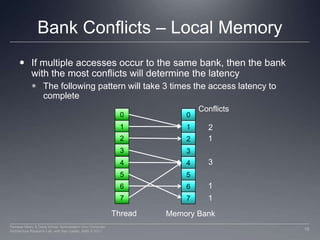




This document discusses GPU memory and how to optimize memory access patterns. It begins with an example of how a wide memory bus is used in GPUs. It describes the importance of coalescing memory accesses from multiple threads to fully utilize the bus bandwidth. It also discusses memory bank conflicts that can occur if multiple threads access the same memory bank, degrading performance. The key to high GPU memory bandwidth is coalescing accesses and avoiding bank conflicts.




































![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























