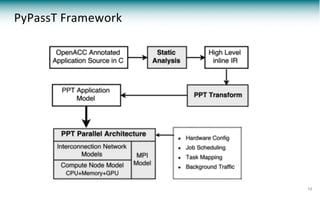
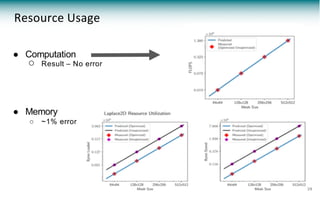
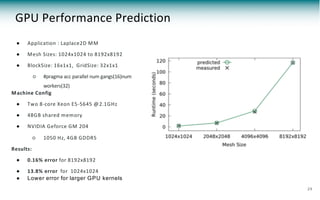
The document discusses a framework called pypasst for predicting performance in high-performance computing (HPC) applications using static analysis and modeling techniques. It highlights the challenges of performance prediction in the context of new applications and architectures while detailing existing modeling techniques and their pros and cons. Experimental results demonstrate pypasst's effectiveness in generating accurate performance predictions for various HPC applications while maintaining flexibility and scalability.





![1. Aspen [Spafford and Vetter, SC’12]
○ Domain specific language to describe application and machine
○ Features analytical communication model
2. Compass [Lee, Meredith, Vetter, ICS’15]
○ Static analysis based automated model construction for Aspen
○ Built on Cetus compiler and OpenARC source transformation framework
○ High level communication abstraction functionality
3. Durango [Carothers et al., SIGSIM-PADS’17]
○ Combines Aspen and CODES
○ Parameterized application model w/ computation events
○ Simulates Aspen generated models or traces on CODES
4. PPT-AMM [Chennupati et al., WSC’17]
○ Simulation based performance prediction
○ Uses static analysis of source code to build data availability models
Most Related to Our Work
6](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-6-320.jpg)





![OpenACC Annotated Program
#pragma acc data copy(A), create(Anew)
#pragma acc parallel num_gangs(16) num_workers(32) … private(j)
{
...
#pragma acc loop gang
for( j = 1; j < n-1; j++) {
#pragma acc loop worker ….
for( i = 1; i < m-1; i++ ) {
Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]);
….
}
….
}
}
13](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-13-320.jpg)
![Memory Hierarchy: PPT-AMM [Chennupati et al., WSC’17]
● A parameterized model for computation performance prediction
● Uses reuse distance and profiles to estimate data availability
○ Patterns of hardware architecture-independent virtual memory accesses
● The reuse profile models different cache hierarchies
We use PPT-AMM to model computation more accurately
15](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-15-320.jpg)
![#stack_dist probability_sd
#3.0 0.357978254355
#7.0 0.141925649545
#11.0 0.053872280264
#12.0 1.44216666613e-05
#15.0 0.0577797511131
#19.0 0.00610221191651
#23.0 0.00814826082
tasklist_example = [['iALU', 8469], ['fALU', 89800], ['fDIV',6400],
['MEM_ACCESS', 4, 10, 1, 1, 1, 10, 80, False,
stack_dist, probability_sd, block_size, total_bytes, data_bus_width]]
CPU Model Example
17](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-17-320.jpg)
![alloc [host] m em ory allocations (in # of bytes)
unalloc [host] m em ory de-allocate
DEVICE_ALLO C Device allocations
DEVICE_TRANSFER Device transfers
KERNEL_CALL Call a G PU kernel with block/grid
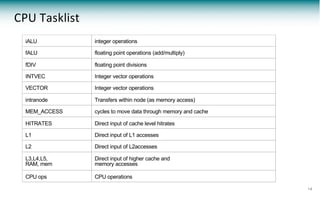
iALU Integer operations L1 Direct input of L1 accesses
diALU Double precision integer operations L2 Direct input of L2 accesses
fALU Floating point operations (add/m ultiply) G LO B_M EM _ACCESS Access G PU on-chip global
m em ory
dfALU Double precision flop DEVICE_SYNC Synchronize G PU threads
fDIV Floating point divisions THREAD_SYNC Synchronize G PU threads w/CPU
SFU Special function calls
18
GPU Tasklist](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-18-320.jpg)

![GPU Kernel Analysis
#pragma acc kernels loop gang(16) worker(32) copy(m, n)
present(A[0:4096][0:4096], Anew[0:4096][0:4096]) private(i_0, j_0)
#pragma aspen control label(block_main50) loop((-2+n)) parallelism((-2+n))
for (j_0=0; j_0<=(-3+n); j_0 ++ ){
#pragma acc loop gang(16) worker(32)
#pragma aspen control label(block_main51) loop((-2+m)) parallelism((-2+m))
for (i_0=0; i_0<=(-3+m); i_0 ++ ){
#pragma aspen control execute label(block_main52)
loads((1*aspen_param_sizeof_double):from(Anew):traits(stride(1)))
stores((1*aspen_param_sizeof_double):to(A):traits(stride(1)))
A[(1+j_0)][(1+i_0)]=Anew[(1+j_0)][(1+i_0)];
}
}
20](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-20-320.jpg)
![Computation (CPU+GPU)
# accelerator warp instructions
GPU_WARP = [['GLOB_MEM_ACCESS'],
['GLOB_MEM_ACCESS'], ['L1_ACCESS'],
['fALU'], ['GLOB_MEM_ACCESS'],
['GLOB_MEM_ACCESS'], ['L1_ACCESS'], ['dfALU']]
# calling the ward with block size and grid size
CPU_tasklist = [['KERNEL_CALL', 0, GPU_WARP,
blocksize, gridsize,regcount],['DEVICE_SYNC', 0]]
# evaluate with hardware model and collect statistics
now = mpi_wtime(mpi_comm_world)
(time, stats) = core.time_compute(CPU_tasklist, now, True)
# sleep for the duration
mpi_ext_sleep(time) 21](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-21-320.jpg)
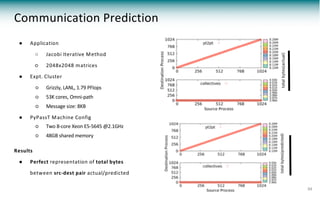
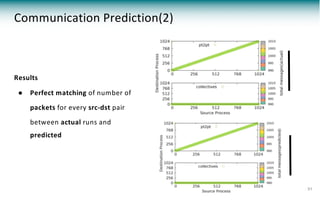
![Communication
● Convert IR of static analysis to PPT communication calls
● Source
○ MPI_Sendrecv( A[start], M, MPI_FLOAT, top , 0, A[end], M, MPI_FLOAT,
bottom, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE );
○ MPI_Barrier( MPI_COMM_WORLD );
● Target
if (my_rank==0) {
execute "block_stencil1d59" {
#mpi send/recv
messages [MAX_STRING] to (my_rank+1) as send
messages [MAX_STRING] from (my_rank+1) as recv
}
}
execute "block_stencil1d66" {
messages [MPI_COMM_WORLD] as barrier
} 22](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-22-320.jpg)


![PPT Overview
25
Open-sourced at: https://github.com /lanl/PPT
[ppt-torus] Kishwar Ahm ed, M oham m ad Obaida, Jason Liu, Stephan Eidenbenz, Nandakishore Santhi, Guillaum e Chapuis, An Integrated Interconnection Network
M odel for Large-Scale Perform ance Prediction, ACM SIGSIM Conference on Principles of Advanced Discrete Sim ulation (PADS 2016), M ay 2016.](https://image.slidesharecdn.com/20180523-pads18-pypasst-180621140903/85/Parallel-Application-Performance-Prediction-of-Using-Analysis-Based-Modeling-25-320.jpg)



































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











