Download as PDF, PPTX





![[Kastens
1980,
Saraiva
2003]
[WWW
2010,
Step 2/2: Schema AttributePPOPP
2013]
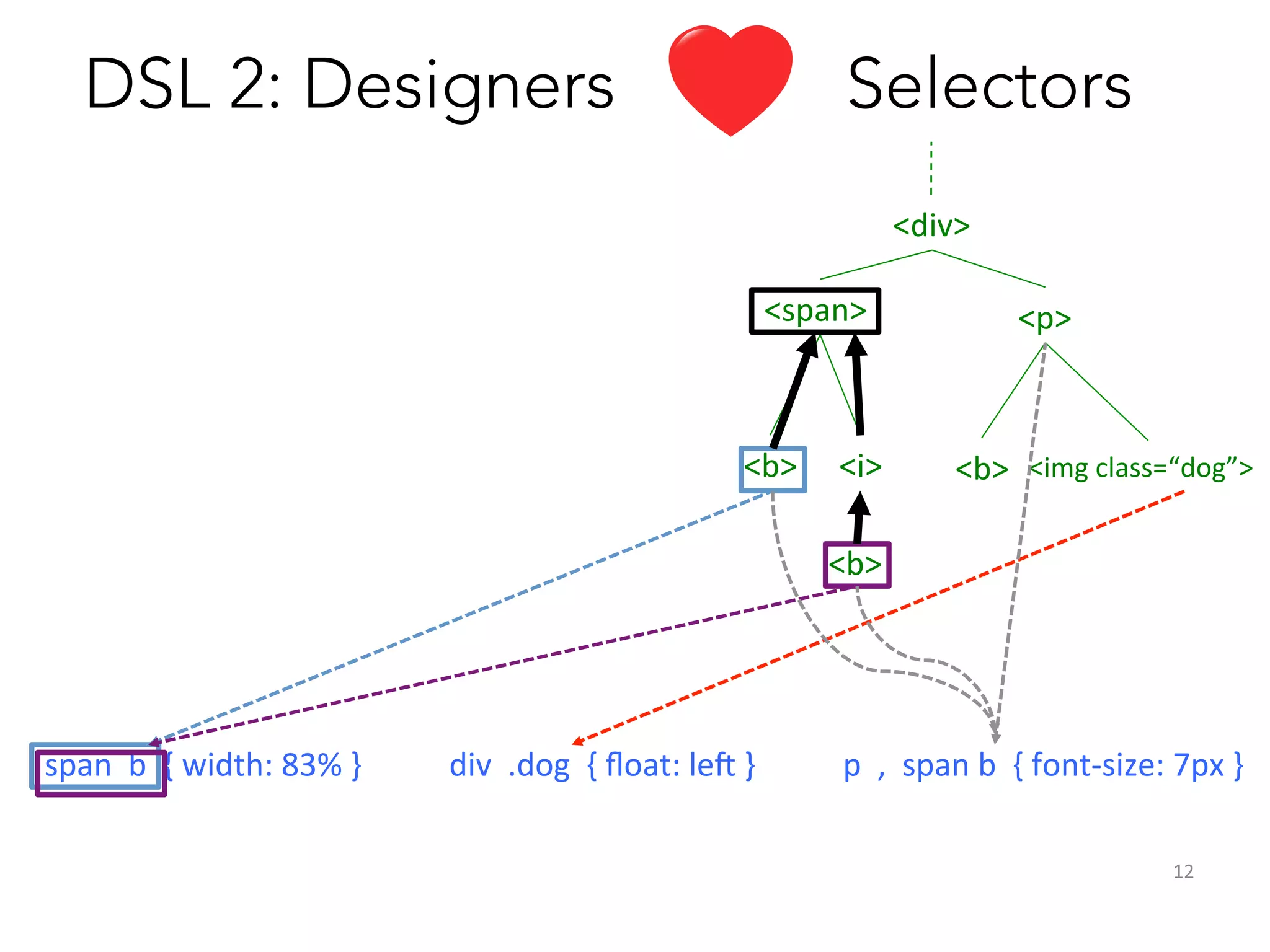
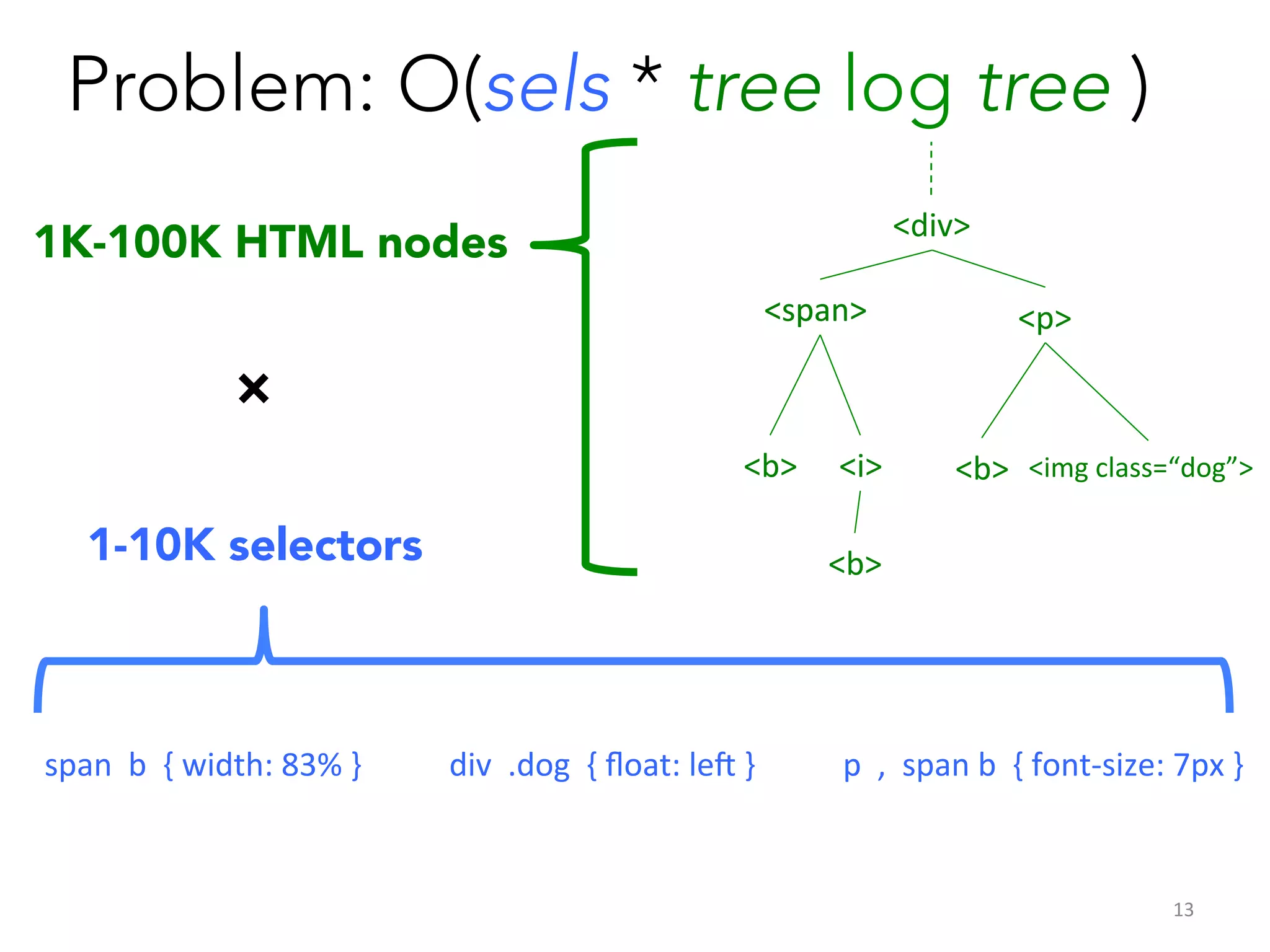
Constraints
1. Local
10px
5px
inputs
vars
2.
Single-‐assignment
HBox
Leaf
y
w
h
x
Leaf
y
w
h
x
y
w
h
x
HBox
HBox ! left=IBox right=IBox
w := left.w + right.w
…
Root
y
w
h
x
Leaf
y
w
h
x
Leaf
y
w
h
x
18](https://image.slidesharecdn.com/wt-4065leomeyerovich-131122142732-phpapp01/75/WT-4065-Superconductor-GPU-Web-Programming-for-Big-Data-Visualization-by-Leo-Meyerovich-and-Matthew-Torok-18-2048.jpg)
![llel
ara
P
[WWW
2010]
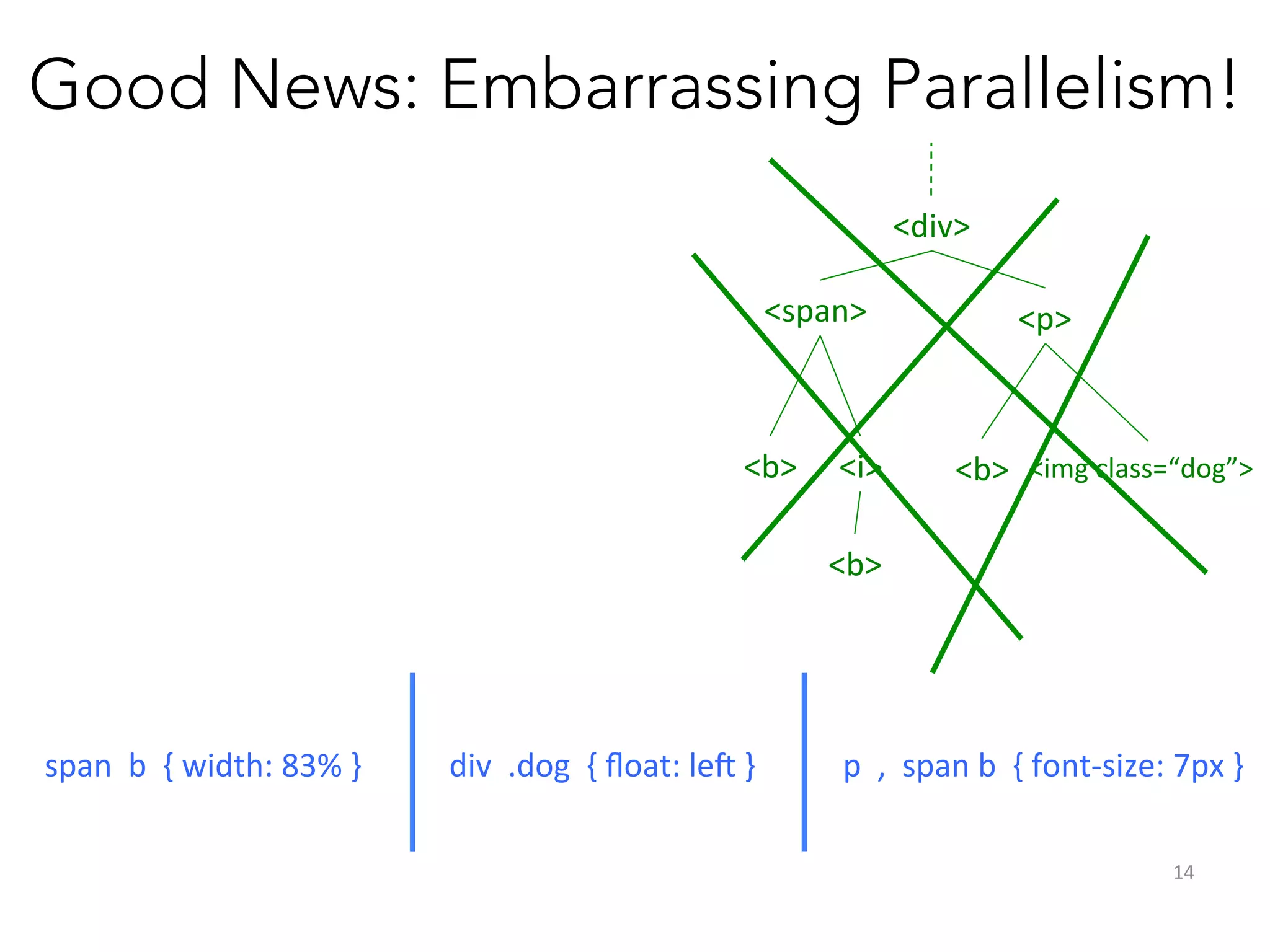
Compiler Output: Layout as Tree Traversals
logical
joins
w,h
w,h
w,h
Leaf
x,y
…
logical
spawns
w,h
w,h
w,h
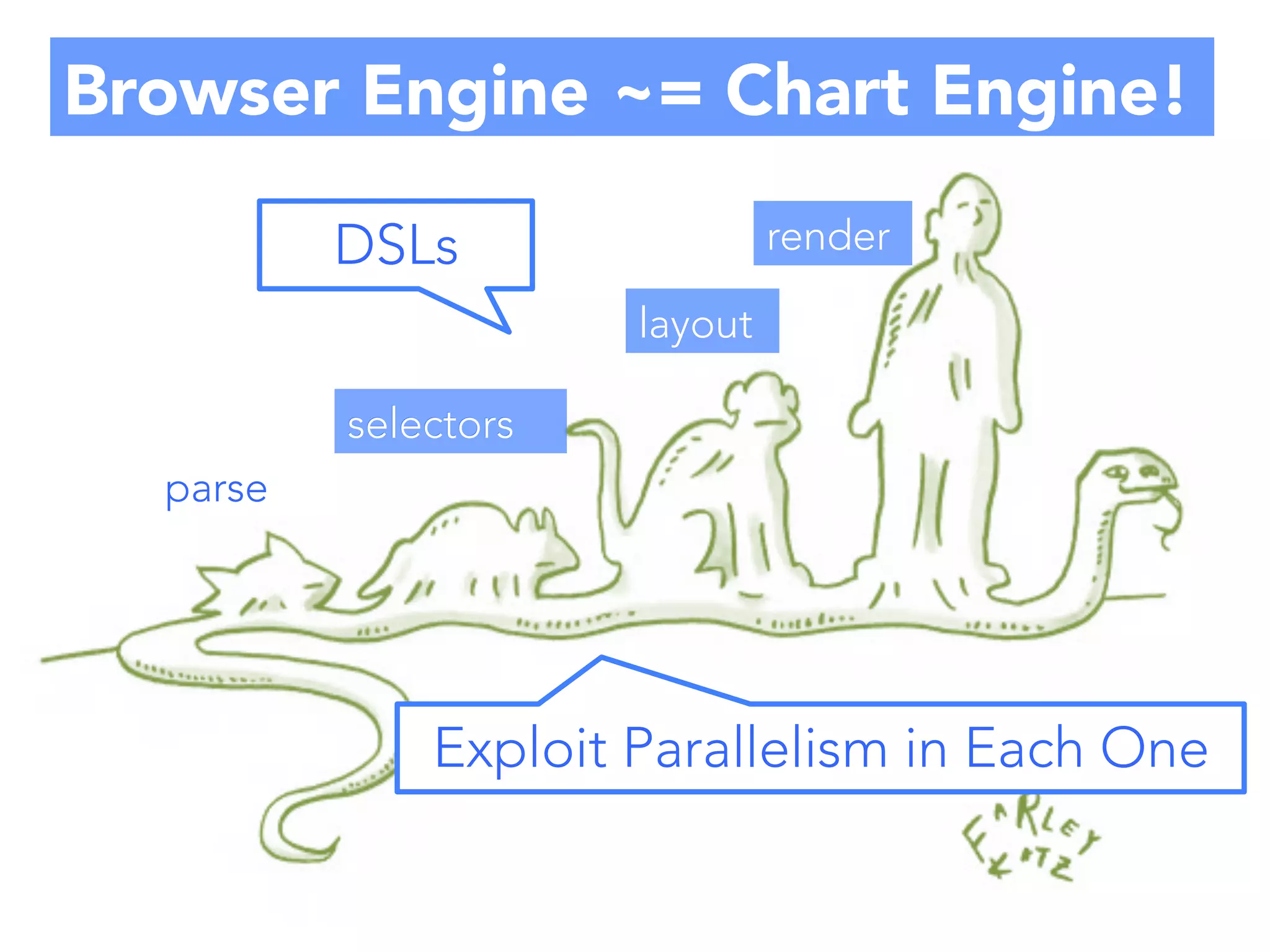
Parallelism in each traversal!
Mozilla, Microsoft
1. Works for all data sets
2. Compiler automatically parallelizes!
19](https://image.slidesharecdn.com/wt-4065leomeyerovich-131122142732-phpapp01/75/WT-4065-Superconductor-GPU-Web-Programming-for-Big-Data-Visualization-by-Leo-Meyerovich-and-Matthew-Torok-19-2048.jpg)

![[Blelloch
93]
Traversals: Flattened & Level-Synchronous
y
x
wh
Array per
attribute
level
1
Nodes in
arrays
parallel for loop
(level synchronous)
level
n
Tree
Compiler automates code + data
transformations.
21](https://image.slidesharecdn.com/wt-4065leomeyerovich-131122142732-phpapp01/75/WT-4065-Superconductor-GPU-Web-Programming-for-Big-Data-Visualization-by-Leo-Meyerovich-and-Matthew-Torok-21-2048.jpg)
![Problem: Dynamic Memory Allocation on GPU?
rect(…); …
oval(…)
square(…)
function circ(x,y,r) {
buffer = new
line(…); … Array(r*10)
for (i = 0; i < r * 10; i+
circ(…)
+)
buffer[i] =
dynamic
Math.cos(i) allocation"
rect(…); …}
1.0 0.8 0.5 0.2 0
0.2
22](https://image.slidesharecdn.com/wt-4065leomeyerovich-131122142732-phpapp01/75/WT-4065-Superconductor-GPU-Web-Programming-for-Big-Data-Visualization-by-Leo-Meyerovich-and-Matthew-Torok-22-2048.jpg)
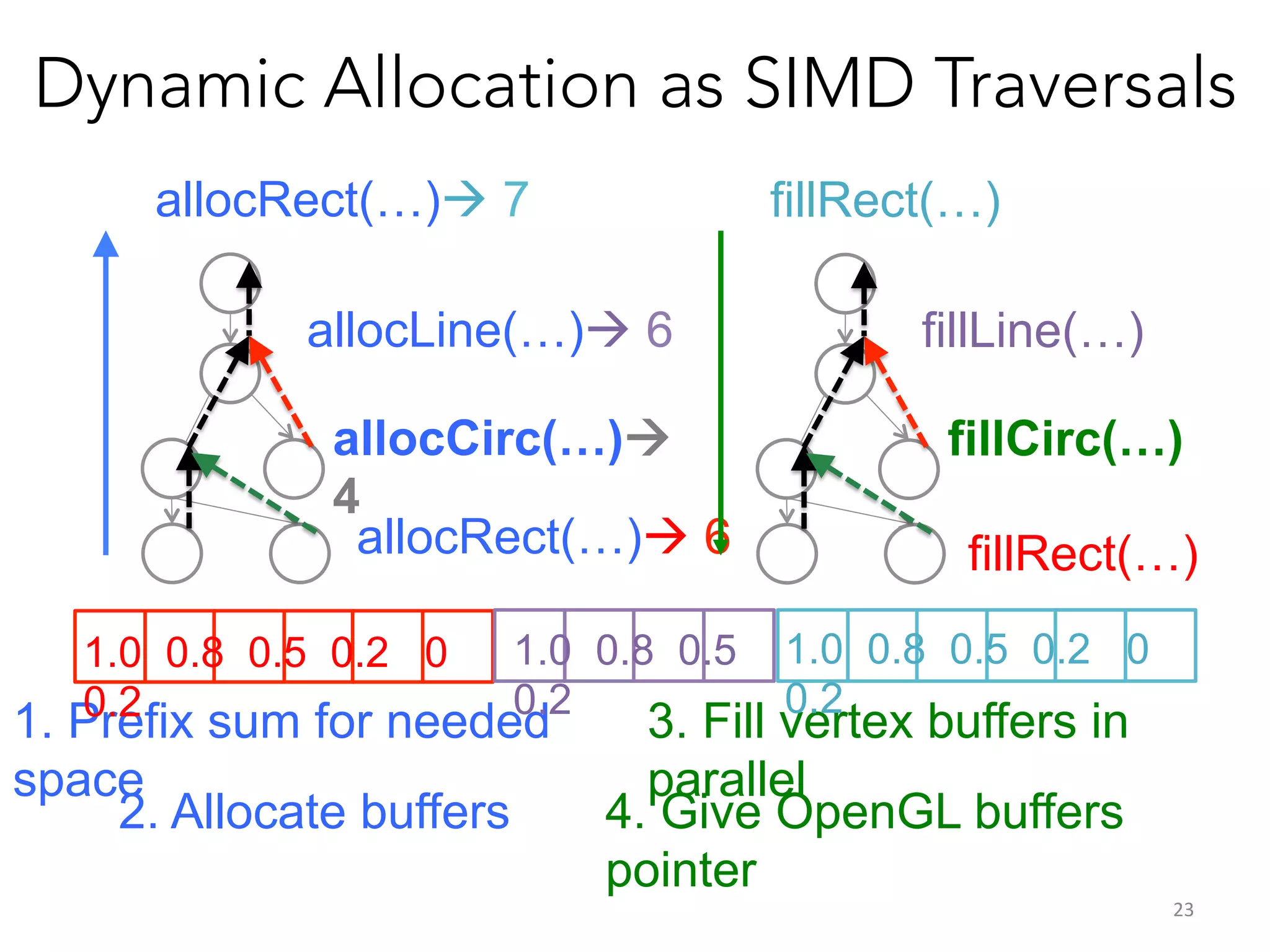
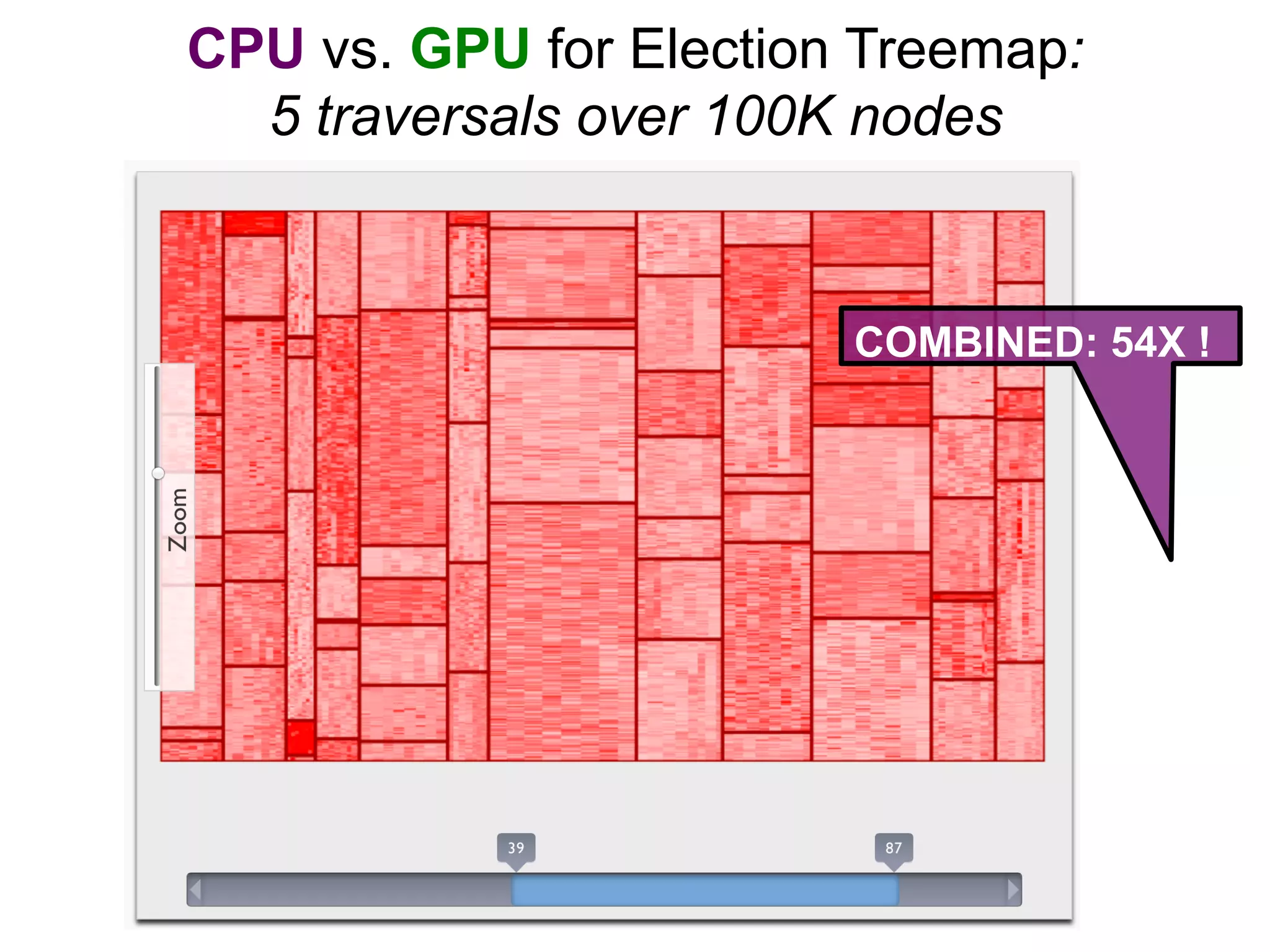



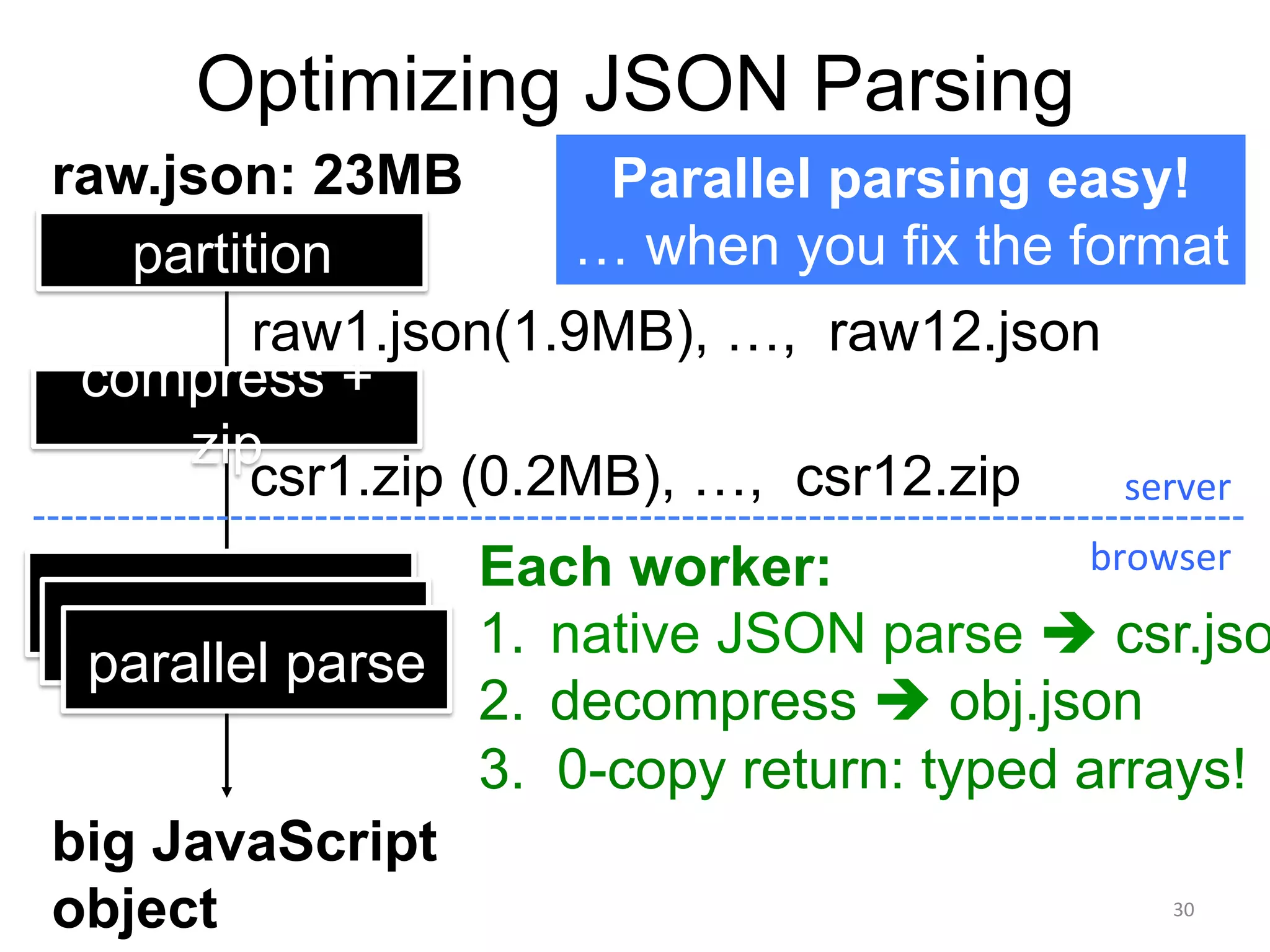

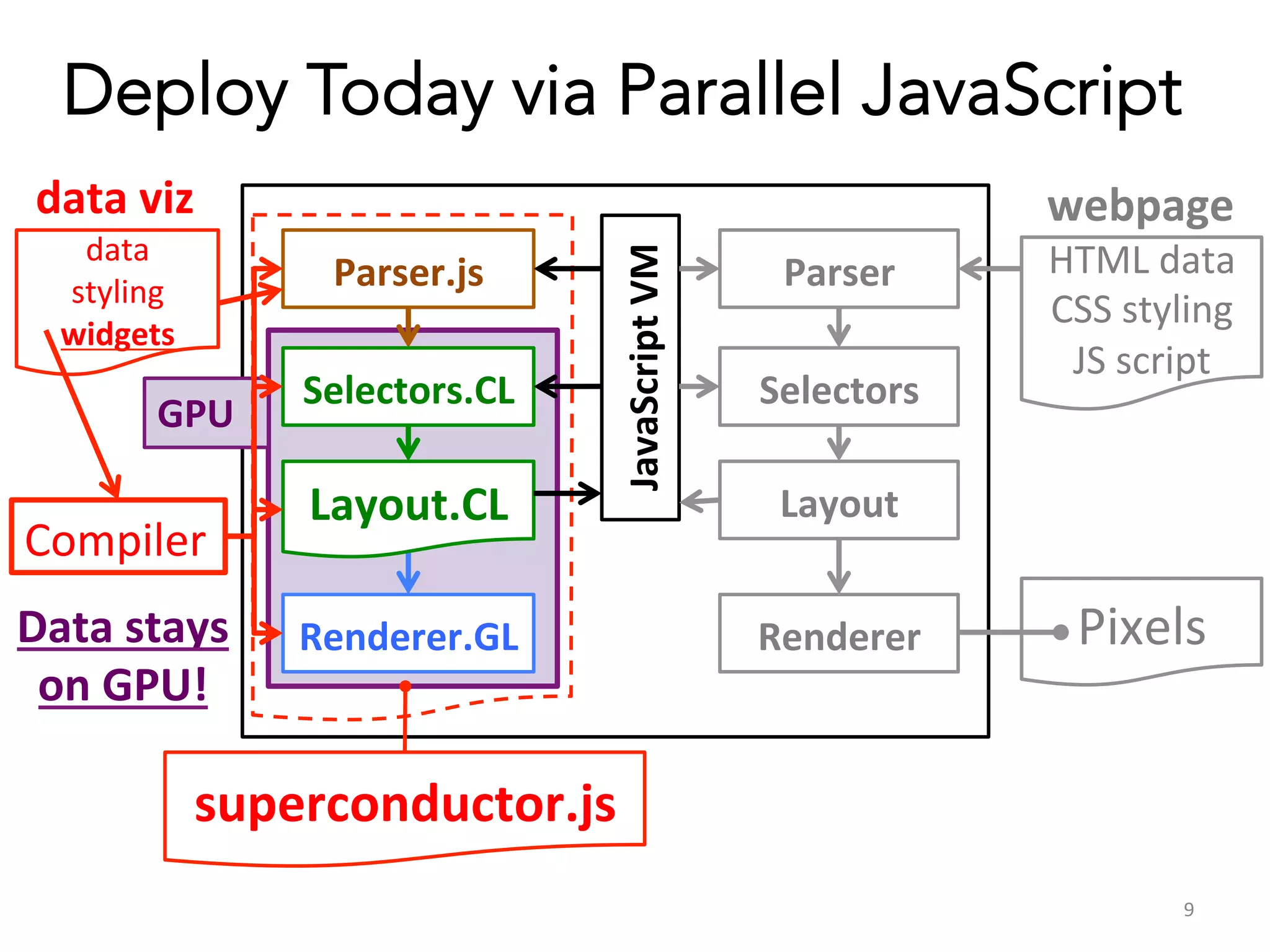
Superconductor is a browser framework designed for visualizing big data through various domain-specific languages (DSLs) that support hardware acceleration via WebCL. It enables interactive visualization and efficient data processing by leveraging parallelism for rendering and layout tasks. The framework aims to optimize data loading and parsing, allowing users to create complex visualizations similar to web page scripting.






















































































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


